On Blockchains/Ledgers and Identity Systems
Posted by ekr on 06 Jun 2022
OK, so I managed to get through my post on identity while only using the word "blockchain" twice. However, the story of self-sovereign identity/decentralized identity is inextricably intertwined with blockchains: much of the interest in decentralized identity comes out of the blockchain/Web3 quarter and a very large fraction of the proposals in this space involve blockchain in one way or another. This post tries to explain the role of the ledger in these systems, which, as we'll see, is surprisingly limited.
Background: DID #
The main specification in this space
is something called (unsurprisingly)
Decentralized Identifiers (DID).
You don't actually need to know about DIDs to talk about decentralized
identity, but most of the mechanisms are now defined in terms
of DID, so it's most convenient to use DID terminology.
The DID specification isn't actually a type of identifier but rather a
generic framework for identifiers. A DID is a kind of URI that
has the scheme did:, like so:

[Source: DID Core specification]
Each DID has a method and then a method-specific identifier. The method describes how you use the method-specific identifier to look up what's called a DID document which contains the actual identity information you are interested in in a JSON-LD structure, for instance:
{
"@context": [
"https://www.w3.org/ns/did/v1",
"https://w3id.org/security/suites/ed25519-2020/v1"
]
"id": "did:example:123456789abcdefghi",
"authentication": [{
"id": "did:example:123456789abcdefghi#keys-1",
"type": "Ed25519VerificationKey2020",
"controller": "did:example:123456789abcdefghi",
"publicKeyMultibase": "zH3C2AVvLMv6gmMNam3uVAjZpfkcJCwDwnZn6z3wXmqPV"
}]
}[Source: DID Core specification]
What's sort of unusual about DID is that the specification defines the
format of the DID document but not the methods. So, for instance,
in the example above, if you know the method example then
you can obtain (technical term: resolve) the DID document,
but if you don't know that method, then you can't do anything with
the DID.
did:key #
Pretty much the simplest kind of identifier here is just a bare public
key, which is approximately what did:key
provides. did:key DIDs look like this:
did:key:z6LSeu9HkTHSfLLeUs2nnzUSNedgDUevfNQgQjQC23ZCit6F
Keys vs. Hashes #
Note that for authentication purposes, it's not necessary to have the key; you could just carry a digest of the key and then have the signer supply the key along with their signature. However, DIDs also allow you carry keys for encryption, where this trick doesn't work. Of course, for modern elliptic curve algorithms, the public key is essentially the same size as the hash would be, so this is less useful. Of course, for post-quantum algorithms, the keys may be bigger.
This is basically just a type specifier that indicates
what algorithm the key is associated with (z6Mk means X25519) followed by
the public key. Because the concept of DIDs is that you resolve the
DID into a DID document, there is a (somewhat hazily defined)[1]
way to expand the key into a DID document. However, for our purposes we can
just think of this as a public key.
As described previously, this kind of explicit key system isn't very flexible. Because it binds your identity to your public key, it doesn't easily allow to to (for instance) update your keys.
did:web #
At the other end of the spectrum we have did:web
in which the DID is effectively a URI that points to the DID document,
as in:
did:web:example.com:user:alice
For some reason the slashes in the path are converted to colons, so this refers to:
https://example.com/user/alice/did.json
In order to resolve the DID, the RP connects to the server and retrieves the indicated document. This document can of course be arbitrarily rich and contain not only keying material but also other assertions about the user, including third party assertions such as "the State of California asserts that this user's personal name is Alan Smithee." This is all left kind of vague in the specs, but I think the idea is that if you were to obtain such an assertion, you would add it to your DID document and upload it to the server. Incidentally, this has horrifying privacy properties, but maybe you could find some way to encrypt them or have some other kind of access control.
It's important to realize at this point that the server is actually doing two things: authenticating the identity document and publishing it. That's sort of natural in the Web context, but there's nothing inherent about it, and it's quite possible to have systems in which authentication and publication are totally separate; you just need some way to distribute the data. Because Web servers exist to serve data, it feels natural to combine them into one service, but, as we'll see below, it's not as good an idea when the identity is rooted in a different system.
did:web and similar Web-based have effectively the opposite properties from
did:key and other key-based identifiers. If you want to replace your key all you
need to do is update the DID document. Regrettably, the did:web specification
punts this issue
but presumably one could invent something, whether it's a Web page
that one could update manually, a Web API, or a standardized protocol
like WebDAV. On the other
hand, like an e-mail address, the identifier is completely controlled by the operator of
the Web site it's being served off of. For instance, if you have the
identifier did:web:example.com:users:fuzzy-dunlop, and the operator
of example.com decides to change your public key, they can just do
so, whenever they want.
This isn't really an issue for identifiers that are supposed to represent
the domain operator, as in a vaccine passport
system, but if you are a user of a system operated by someone else
it means you don't control your own identity.
Of course, in principle you could register your own domain and host
your identity there, but few people do; as a practical matter if
did:web was ever to be popular with ordinary users we'd expect
most of the identifiers to be did:gmail.com:<username> or the like,
with Google (or Yahoo or whoever) controlling the identities for
those users.
Even for users who do register their own domain, at the end of the day
did:web identities are just bootstrapping off the existing
DNS namespace and the WebPKI, which asserts identities within it.
Because the namespace is hierarchical, this means that your
identity can be taken away by someone who can control the relevant part
of the DNS, for instance if a government
seizes your domain.
If what you
want is "self-sovereign
identities"
in which "A person’s digital existence is now independent of any
organization: no-one can take their identity away." then this isn't
it.
Online vs. Offline Authentication #
It's worth noting that even if we ignore these inherent structural issues in a system like this, it's somewhat odd to have an identity assertion require access to an online resource, in this case the Web server. By contrast, WebPKI certificates can be verified offline, which means you don't need to contact the certificate authority in order to validate them.[2] The reason for this is that the certificates are digitally signed by the CA and that signature can be verified by anyone. Operationally, this means that if you send someone a message signed with the key corresponding to your DID, that person can't verify it without contacting the Web server; if that server—or the relying party—is offline, the relying party will have to wait.
did:web assertions aren't just online: because of the specific way
in which TLS works, they are also deniable.[3]
What I mean by that is that if I connect to a Web server—any
Web server—and retrieve some data, I have no way of proving
the contents of that data (depending on the
protocol details I may be able to prove
that I made the connection). The reason for this is that
the data is protected with a symmetric key which is jointly
known both to me and the server and so either side can produce
the same protocol messages (technical term: protocol trace).
There's no way to to prove that the Web server made a specific
identity assertion, so, for instance, if you send me a document signed
with a did:web identity and then change your key pair, you
can just deny that the key that signed the document was yours
and I can't prove otherwise. This is an attractive property
in some situations, but limits the use of this kind of identity.
A related property is that it makes it harder to detect malfeasance by the Web server. Suppose that the Web server occasionally lies about the public key of a given identity (e.g., so that the attacker can impersonate Alice). How would you detect this? In a certificate system like the WebPKI you can use a transparency log which—at least in theory—allows you to detect this, but the problem is much harder when the data is retrieved from the Web. In principle you could have transparency just for the keys, but without a way to prove that the server actually sent you a given key, anyone can frame the server for sending a bogus key, which means that malfeasance is deniable. The transparency log is still of some value, but it needs to be checked in real time and it's still unclear what you do if a key isn't in the log.
Even if we discount malice by the server operator, we also have to deal with server compromise: if the Web server is compromised the attacker can serve any DID responses it wants. By contrast, if the DIDs were signed then the signature key could be kept offline and not be subject to online attack. For obvious reasons the Web server's authentication key cannot be kept offline, as it must be used with more or less every transaction.[4]
Ledger-Based DID Methods #
With the above as background, it's useful to look at the
systems we now see being proposed, and see what's going on.
As I mentioned above, the DID specification is really a framework
for different methods, each of which has their own way of
resolving the DID document from the identifier. Quite a few
of these are tied to some blockchain or another and while
the details differ, the general concepts seem to be fairly
similar. The following description is sort of a mashup
of did:v1 and
did:indy that
hopefully captures the general flavor.
The main idea is that the ledger—however that's implemented— some set of functions, such as:
- Creating an identity document
- Updating a given identity document
- Reading an identity document
Effectively, what this does is take did:web, cross-out web, and
write <insert-ledger-here> in its place; it's kind of a rough fit.
As with did:key, each identity document is associated with a given
cryptographic key and so the identifier is derived from the key,
for instance by hashing it. The ledger is supposed to enforce this
requirement.
Once a document has been created, it is possible to update it using the update function. Updates are authorized by the current key, which, again, is enforced by the ledger. Importantly, you can change the current key but this doesn't change the identifier, so it's possible for the public key to become totally decoupled from the identifier in such a way there's no relationship.
You can resolve an identifier by doing a read operation, which returns the identity document.
In any system like this, it's important to understand what the ledger is doing for us, because there is a tendency to think of ledgers/blockchains as magic. At a high level, then, the ledger is providing three services:
- Storing the user's identity document(s)
- Authenticating the user's identity document(s) to the RP
- Providing a consensus timeline for changes to the identity document(s)
Arguably, the first of these is largely unnecessary, the second is bad, but the third is essential.
Let's start with storing the user's identity document(s). In the majority of authentication contexts, whether online authentication like login or messaging applications, the entity being authenticated is sending some set of data to the RP and that data is then signed with the appropriate key. The straightforward thing to do, then, is to provide the identity document(s) at the same time; this is how both channel security systems like TLS and messaging systems like OpenPGP or S/MIME work. Aside from being self-contained, this also has privacy advantages because it doesn't require the RP to query some service for the authenticating identity, which would leak who was talking to who.
There are, of course, some applications in which you want to send an asynchronous encrypted message to someone you haven't talked to before, in which case it's useful to have some way to look up their key. However, those systems typically already have some kind of key lookup service that's a lot more efficient than a blockchain, and there's no good reason to have that data on a permanent public ledger; instead you'd just publish the relevant encryption keys on the key lookup system and sign them with the authentication key, in which case you can bundle the identity documents along with the signed object. Even if there wasn't an existing key lookup service, it would be better to store this data in some kind of high performance non-ledger system like IPFS, because you don't need the ledger to attest to it (recall that the date is self-validating). Moreover, this has better privacy properties than the ledger, which is inherently public.
To understand why I say that authenticating the identity document in the ledger is bad, you have to think about the problem of updating your keys. This is special because unlike other kinds of metadata you can't just sign it yourself.
How to update your keys #
If you never allow anyone to update their keys, then life is very simple because the key is self-authenticating and you can sign any updates to the identity documents with that key. However, there are good reasons to want to update keys. For instance, you might have started with a 2048-bit RSA key A and move to an 256-bit Elliptic Curve key B. The secure way to update a key in a system like this is to have the old key sign the new one. This creates a chain of identities, like so:
A → B
When you want to authenticate with identity A you then present something like:
- The original identity which points to key A
- The signature using A over key B
The semantics of this is that the RP accepts key B as representing identity A even though it's a totally different key. You then use B for whatever you would use A for, for instance to sign a document or authenticate your login.
This can obviously be extended to have B sign C, in which case you have:
A → B → C
When the RP receives something like this, it needs to verify the chain of assertions going back to A. Note that the original key need not be online: you just use it to make the delegation to the next key and then you may never need to use it again—indeed in a true replacement you may want to destroy A so it can't be stolen. I say may because you might have some kind of limited delegation in which you aren't actually replacing A with B but instead authorizing B to be used in some contexts, or for a limited time, as in TLS delegated credentials. For this reason[5] you probably won't be signing the bare key but some data structure (e.g., a JSON document) that describes the semantics of the delegation. This is effectively the same structure as a WebPKI certificate chain, except for a single identity.
Compromise of the Original Key #
This all seems fine, but what happens if key A is compromised (I'll get to the compromise of key B in a moment)? The attacker can then mint a new key X which he knows and sign it with key A, thus creating:
A → X
This is just as good an assertion as the actual one over B, so the attacker has just taken over your identity. Of course, this doesn't invalidate your delegation to B; it's just that you and the attacker now jointly control identity A.
One way of analyzing this situation is that the source of the problem is that you didn't actually replace A with B, because A is still valid. By this way of thinking, what we need to do is memorialize that transaction, which is where ledgers/blockchains come in.[6] The idea is that when you delegate to another key, you record the transaction on the ledger, which thus provides a (partial) ordering of operations. I'll leave the details of how a blockchain-type distributed ledger works for another day, but briefly a ledger is a cryptographic data structure that's constructed in such a way that everyone agrees on what events occurred and the order in which they happened. So, in this case, we would have a situation like this:
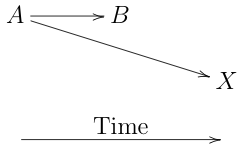
The RP would then consult the ledger—either directly or perhaps would be provided with the relevant portions as part of the authentication transaction—and verify that each delegation that it was following was the first one chronologically. Note that the key must specify which ledger will be used to prevent confusion about which timeline is authoritative. Because the delegation from A → B happens first, then it is the right one and A → X would be rejected. Note that unlike many blockchain applications, you actually need to verify that there are no future blocks that contain new delegations; otherwise you might miss that a key had been deprecated.
It's important that the actual delegation signatures be recorded on the ledger and then checked by the RP (this seems to be a point of some confusion in existing designs). You do want the ledger to check the signatures on the delegation to avoid spam, but the critical service the ledger is providing is temporal ordering. It's not possible for even a compromised ledger to make a fake delegation unless the currently valid key has been compromised. Of course, if RPs don't check the delegation signatures then they're just trusting the ledger to behave correctly. More on this shortly.
Compromise of Current Keys #
However if the currently valid key is compromised, the attacker can redelegate the key to themselves and there's nothing you can do in this system, because that delegation will be chronologically first and so your redelegation will be perceived as an attack. Some systems, such as KERI attempt to address this by pre-committing to key K_{i+1} when delegating to key K_i. In the example above, when A was first registered it would come with a commitment to B in the form of a hash. Similarly, when B delegates to C, it publishes a hash of D, as below:
(A, H(B)) → (B, H(C)) → (C, H(D))
This provides protection against cryptographic attack under the assumption that the hash is irreversible: the attacker can break the current key but can't attack the next one because it only has the hash. However, it does not provide security against compromise of whatever device holds the next key, so it's only a partial solution, especially if users—as many users will—store all of their keys in one place.
Another approach is to have some sort of recovery key which can be used to override other transactions. Presumably that key is then kept in some super secure location. This key can then be used to recover your identity if the currently valid key is compromised. Note that this is semantically the same as a partial delegation to the new key which can then be revoked by the original key.
Signature Chain Verification #
We now have enough background to understand why I said above that we don't want the ledger to authenticate the identity documents to the RP: the validity of those documents is being defined by there being an unbroken chain of signatures from the original key, which is itself cryptographically bound to the identifier. If the RP doesn't check those signatures, then it's relying on correct behavior by the ledger, and you have no way of knowing if the nodes that added the latest entries actually went to the trouble of checking the signatures.
Worse yet, if it doesn't validate the correctness of the ledger (e.g.,
by authenticating the current state from multiple nodes), then it's
just trusting whatever ledger node it queried. This is even worse than
the situation with did:web because at least with did:web the
server you are querying is nominally responsible for the identity.
With a blockchain-based ledger you're just asking some random node
you've never heard of.
If the RP is going to validate the signature chain anyway, then there's no security reason for the ledger to do so, though there may be a performance reason. It's probably useful if the ledger does some basic checking—especially before creating documents—in order to prevent DoS attacks on the ledger, but there may be other potential mechanisms for doing that, such as charging for ledger updates (this is what Bitcoin does).
Temporal Ordering #
What we do need the ledger to do, however, is guarantee the temporal ordering of events, because that's what prevents redelegation by the attacker in case of key compromise. Ideally, the RP would check the ledger for every transaction associated with a given identity and verify that each delegation was correctly constructed based on the chronology. However, as a practical matter this requires having access to a very large portion of the transactions on the ledger (naively, all of them!) which may run to tens of millions, so this presents a scaling problem.
In practice, it's common for clients to just trust that the ledger enforced consistency for a given transaction. For payment applications this means that the ledger accepted the payment transaction. In this case, it would presumably mean that the ledger had checked the chain of apparent delegations and gave you the latest valid document. In this case, it is necessary that the ledger verify the signature chain because otherwise an attacker could inject a bogus delegation, which is then sent to the client. As long as the client checks the signature itself, this won't cause the client to get the wrong key, but it will cause it to be unable to get the right key because it will get the bogus delegation and then reject it. Effectively, this is a DoS attack on the valid user.
Even so, it's probably better for the ledger node you are communicating with directly to do the checks on read rather than having the checks be done on write. The reason for this is extensibility: if ledger nodes check the signature chain on write/update, then you can't roll out a new signature algorithm until you are guaranteed that every ledger node that is checking accepts it, which precludes incremental deployment. By contrast, if checks are done on read, then full clients which have the whole ledger will be fine as long as they have the new algorithm, and even "light" nodes which don't have the whole ledger will be OK if they pick a ledger node which supports the new algorithm.
As described above, as long as the client verifies the signature chain, if the ledger cheats, then it can cause you to accept the wrong version of history but it can't cause you to accept the wrong key unless the keys are compromised.
Lost Keys #
Of course, none of this addresses the case where the user loses their keying material. The conventional response to this problem in the decentralized identity world is that users should make arrangements in advance, for instance by keeping your recovery key in a really safe place or maybe by sharing your recovery key with your friends via something like Shamir Secret Sharing. However, as I mentioned previously, we know that in practice many users do not do a good job of managing their keys, even when a lot is at stake (e.g., millions of dollars in Bitcoin), so while surely some users will in fact follow this kind of practice, many will just store all their keys in one place and may lose them.
As with blockchain-based name systems, if you want to have a system which lets you recover your identity even if you've lost all your keying material—for instance you dropped your phone in the toilet and you don't have a backup—you need some mechanism for recovery that ultimately depends on human discretion not technology.
The Bigger Picture #
To go back to the question I asked at the beginning, what is the ledger doing here?
The primary value proposition of these designs is, as in the passage I quoted above, that you're not dependent on others for your identity:
This is called “self-sovereign” identity because each person is now in control of their own identity—they are their own sovereign nation. People can control their own information and relationships. A person’s digital existence is now independent of any organization: no-one can take their identity away.
The technical feature that provides this property is not the ledger.[7]
Rather, it's that your identity is bound to—indeed, defined by—a cryptographic
key pair. Similarly, if there are assertions bound to the key,
as people seem to expect, then what makes that work is that
those assertions include signatures over your identity (in this
case the key). None of this requires any kind of ledger; you
could just do it with did:key.
The main necessary function of a ledger in this kind of system is that it allows you to verifiably transfer control of an identity from one key to another in a way that is secure even if the initial key is later compromised. In practice, the ledger also seems to being used as a publication mechanism for identity information, but that's actually something that is better done by other mechanisms to the extent to which it's necessary at all. Publishing data in ledgers is super-expensive and so should be a last resort, not a first one.
Unfortunately, the ledger only provides a partial solution to recovering from key compromise and loss: if you lose all of your keys and/or the attacker gains control of them, then this is still unrecoverable without some mechanism external to the system that allows you to assign a new key to a given identity without any signature chain from the original key, which, of course, violates the value proposition stated above.
But once you have such a mechanism, then why not just use it all the time? What I mean here is to assign people human-readable identifiers (e.g., e-mail address or phone number) rather than random high-entropy ones and then have a mechanism to bind those identifiers to keys, a la the WebPKI or DNSSEC. If someone wants to change keys, you issue a new credential and invalidate the old one. This lets you avoid the bad ergonomics of key-based identities and the scaling (and privacy) issues of the ledger. My point here is not that whoever is empowered to issue those credentials isn't a weak point in the system; of course it is. But it's also a necessary one unless you're willing to accept having people be occasionally—or maybe not so occasionally—locked out of the system entirely.
By which I mean that there is an example that presumably you're supposed to imitate, but no actual specification for how to do it as far as I can tell. A number of the DID specs are like this. ↩︎
Yes, I know about revocation and OCSP, but I think this story mostly holds up in the face of OCSP stapling, CRLite, and CRLSets ↩︎
The classic term here is "non-repudiation" but that comes with a lot of philosophical baggage. ↩︎
Ignore TLS session resumption for now. ↩︎
And for others, such as cross-protocol attacks. ↩︎
I owe this observation to Manu Sporny. ↩︎
Yes, there are systems where the ledger is used to establish the original identity in a FCFS fashion, like the various proposed DNS replacements, but that's not what I'm talking about here. ↩︎
Keep Reading
- Next: First impressions of Web5
- Previous: Understanding Online Identity