Overview of Apple's Client-side CSAM Scanning
Posted by ekr on 09 Aug 2021
Last week Apple announced a new function in iOS that will scan photos in order to detect images containing Child Sexual Abuse Material (CSAM). This post attempts to provide an overview of the functionality Apple has built and answer some questions about what it can and cannot do.
Overview #
The basic idea behind the system is to detect images on the device that match known CSAM images. What this means is that Apple has a database of hashes of CSAM images [Update: this originally said images, but actually Apple only needs the hashes and their writeup suggests they don't have the images.] provided by the National Center for Missing and Exploited Children (NCMEC, pronounced "nick-meck") and is trying to detect whether the images on the device are in that database. Although the system uses machine learning (ML), it is being used to account for small changes in the images (e.g., were they cropped, or compressed slightly differently, etc.) not to generically detect whether an unknown image is CSAM. If, for instance, someone sends or receives a CSAM image that is not already known to NCMEC, then this system will not detect it.
Although the scanning happens on the device, it is currently limited to photos which are being uploaded to iCloud. This is actually a little puzzling because, as EFF notes, photos on iCloud are not end-to-end encrypted[1] and therefore Apple could scan the photos on the server side, though it apparently does not do so. One possible theory here is that Apple is intending to introduce end-to-end encryption of iCloud data and wants to have an answer to how they are going to address CSAM for that data. It's important to realize that there's nothing in the system that prevents Apple from scanning photos that never leave the device; they've just chosen not to do so (see below for details). However you don't have to be sharing photos with anyone; just backing up photos to iCloud is enough to initiate the scanning process.
Design Objectives #
Here is what Apple describes as the privacy and security guarantees of the system (I've added some numbers to make it easier to follow).
- Apple does not learn anything about images that do not match the known CSAM database.
- Apple can’t access metadata or visual derivatives for matched CSAM images until a threshold of matches is exceeded for an iCloud Photos account.
- The risk of the system incorrectly flagging an account is extremely low. In addition, Apple manually reviews all reports made to NCMEC to ensure reporting accuracy.
- Users can’t access or view the database of known CSAM images.
- Users can’t identify which images were flagged as CSAM by the system.
These all seem pretty obvious, especially (1) and (3): nobody wants Apple learning about all the images on your phone or to get inaccurately accused of having CSAM.
(4) and (5) deserve a closer look. Obviously Apple doesn't want to actually send a database of CSAM images to the client, but the database actually contains image hashes which probably don't really let you reconstruct the image.[2] Rather, the main reason for (4) and (5) is to prevent people from learning which hashes are in the database because then they could avoid sharing those images or potentially perturb the images until they had a different hash. It would also allow an attacker to cause trouble for others by sending them innocuous images that match the hash, thus causing false positives that get them investigated.
System Description #
The system uses some quite fancy cryptography but I'll attempt to provide an overview that doesn't require that much cryptographic knowledge. As a disclaimer, I've read the paper and think I mostly understand it, but I haven't studied the proofs and even though it was designed by some well-known people, the system was just released and thus hasn't been widely analyzed, so there's of course some chance there's a mistake.
At a high level, the system works as follows:
- Apple builds an encrypted database of the hashes for each image and sends it to each device.
- The device hashes each image and uses the encrypted database to generate a "voucher" which gets sent to Apple. At this point, the device does not know which images matched.
- On the server side, Apple decrypts the vouchers, but is only able to do so for the matching images (hashes). The decrypted vouchers have another layer of encryption so aren't useful just yet.
- Once Apple has decrypted enough vouchers for a given device, they are able to put them together and remove the inner layer of encryption. This allows them to determine which images actually matched.
The Image Database #
The input to the system is a labeled database of images which are to be detected. Although the system is described as scanning for CSAM, from the perspective of the system they're just images. For instance, if Apple wanted to detect everyone who had made a copy of Beeple's Everydays (enforcing his NFT!), they could just insert that into the database.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/68948366/2021_NYR_20447_0001_001_beeple_everydays_the_first_5000_days034733_.0.jpg){kind=link}
The database is then processed with a perceptual hashing" system called NeuralHash.[3] NeuralHash takes an image and produces a short value (I believe on the order of 256 bits) which is characteristic of the image. The idea is supposed to be that:
-
If two images look "the same" then they will have the same hash, even if they are slightly different. For instance, Apple gives the example of a color and black-and-white version of the same image.
-
If two images are "different" then they will have different hashes with very high probability.
The rest of the system is all based on these hashes and is designed to detect if the images on a given device have a hash that is in the database. Importantly, if two images do -- due to bad luck or attack -- happen to have the same hash, then this behaves as if the images were the same.
Each image is run through NeuralHash to produce its corresponding hash value. Apple then takes each of those hash values and blinds it using a secret key known only to Apple, producing a blinded hash. These values are then stored at a table in a deterministic location in the table derived from the original hash. The figure below shows a trivial version of this in which we just use the last digit of the hash as the position in the table (remember, computer science people count from 0).
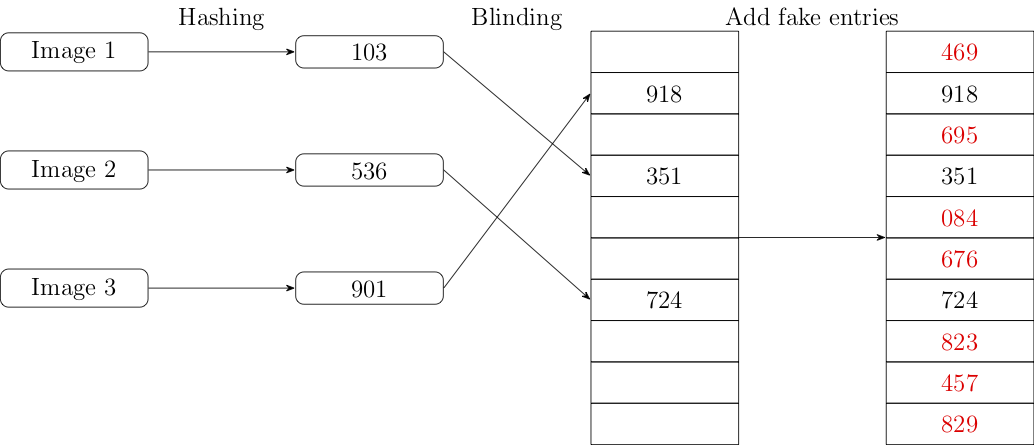
There are two subtleties in building the table. First, two hash values might happen to correspond to the same position in the table (in the example above, they might have the same last digit). This isn't that likely and can be dealt with in a number of ways that are outside the scope of this article: the easiest is just to make the table somewhat larger than the total number of hashes (so this doesn't happen often) and keep only the first or last matching hash (thus tolerating a small number of images not getting reported).[4] Second, not every entry in the table will be filled with a value: if we just sent an empty value, this would tell the client some of the hashes that were "safe" (i.e., had no corresponding images). Instead, Apple just fills these with random values (shown in red in the diagram above).
Once the table is built, Apple then sends a copy of the database to the device. Note that although each device has a copy of the database, it is unable to determine the set of hashes because it does not have the blinding key (objective #4)
The Scanning Process #
In the scanning process, the device goes through its images one at a time. It computes a hash for each image and then looks up the corresponding table entry in the database at the position indicated by the hash (again, in our example, using the last digit of the hash). As noted above, there are three possibilities:
- The images are the same and so have the same hash
- The images are different and so have different hashes, but are just at the same position in the table (in my example, because they have the same last digit).
- There is no image at this position in the database, in which case the value in the table is just random.
Importantly, the device can't distinguish these cases (objective #2) so it does the same thing in any case: It uses its own hash and the blinded database entry to compute an encryption key and a value Q (which we'll use in a moment).
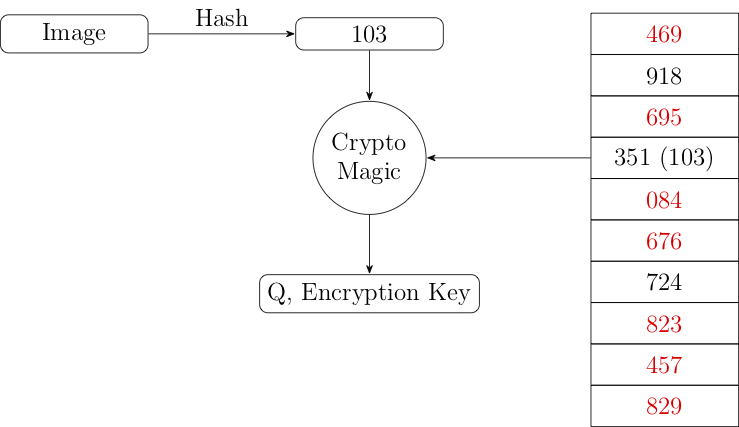
It then creates a voucher which contains the pair of:
- Q
- Some "associated data" encrypted with the encryption key (We'll get to what that means shortly.) but not the key itself.
It then sends the voucher up to the server along with the image (again, the server could have computed all this stuff itself from the image, but if the image was end-to-end encrypted then that would not be possible.)
Server-Side Processing #
When the server receives the voucher, it combines its blinding key with Q to compute its own encryption key and uses that key to decrypt the associated data. If the images were the same (and hence have the same hash) then the keys that the client and the server computed will be the same and the associated data will decrypt correctly. If the hashes are not the same or the database contained a random value at this position, then the key the server computes will be a random value and the associated data will not be decryptable.
The result here is that the server immediately learns which vouchers correspond to matching images and which do not, but learns nothing additional about non-matching images (objective #1). Moreover, it learns the "associated data" for those images. This would allow the server to immediately determine how many matching images the device has. In order to prevent this, the device also sends some "synthetic match vouchers" which always decrypt. I'll describe this feature below.
Threshold Decryption #
One of the design goals of the system is that the server not learn the details of single image matches (objective #2). Instead, the server only gets to learn which images matched once it has seen a certain number of matches. This is known as a threshold system.
In order to this, Apple makes use of a technique called Shamir secret sharing. Briefly, a secret sharing scheme is a system in which you take some secret S and break it up into a bunch of shared etc. in such a way that you need a minimum number of shares (the threshold, t) in order to reconstruct S. You can have an unlimited number of shares but any subset of size t will let you reconstruct the secret (this is called M out of N sharing.)
The associated data consists of two values:
-
An encrypted value that contains information about the image: the hash and a "visual derivative" (more on this later). This value is encrypted with device-specific key that is used for each encrypted value.
-
A single share for that device-specific key.
The net result is that the server collects all the vouchers and discards all the undecryptable ones. It waits until it has enough shares for a given device, then reconstructs the device-specific key. It can then decrypt the encrypted values for every matching voucher it has received, as well as for any voucher it receives in the future. However, until it has received t shares, it is not able to decrypt any of these encrypted values.
Synthetic Match Vouchers #
Even with threshold decryption, the server still learns the total number of single image matches. In order to prevent this, each client replaces some of its vouchers with "synthetic match vouchers. These vouchers are designed to decrypt properly but contain an invalid secret share value. Due to some crypto magic I won't get into, it is not possible for the server to distinguish synthetic match vouchers from real vouchers until it already has a threshold number of real vouchers. The result is that the server cannot precisely determine the number of actual matches before the threshold is reached.[5]
This is not the same as the server having no information about the number of matches. Specifically:
-
The server knows that there are no more matches than the total number of decryptable vouchers.
-
If the server knows the rate at which synthetic vouchers are introduced, it can estimate the total number of actual matches for a given user using Bayes's Theorem. This also allows the server to get a fairly precise estimate of the overall rate of CSAM (see: Randomized Response Technique) even for sub-threshold clients.[6]
Handling Matches #
Once Apple has collected enough vouchers to cross the threshold and decrypted the data, they get two pieces of information for each image:
- The hash
- A "visual derivative"
Apple is a bit unclear on what happens next. Here's what their white paper says:
The threshold is selected to provide an extremely low (1 in 1 trillion) probability of incorrectly flagging a given account. This is further mitigated by a manual review process wherein Apple reviews each report to confirm there is a match, disables the user’s account, and sends a report to NCMEC. If a user feels their account has been mistakenly flagged they can file an appeal to have their account reinstated.
We don't know what this manual review consists of, but there are a number of possibilities.
First, they could just look to see if the reported hashes to see if they really match hashes in the database. This is just a mechanical check in case there is some sort of bug in the system and you wouldn't expect to find much here. The main reason you would want a manual review is to see if you had just by chance an innocuous image had gotten a hash value which matches a piece of CSAM (i.e., a false positive) but this check won't detect that.
Second, they could check the image itself to see if it (1) it looks like the corresponding image in the database or (2) if it looks like CSAM. As noted above, this would only be possible because the images are being uploaded to iCloud and if they are not end-to-end encrypted In a system where the images just stayed on the client, this would obviously not be possible.
Finally, they could use the "visual derivative". I can't find a description of what this is (Apple: Call me!), so I'm just speculating, but one possibility is that it's some kind of thumbnail of the image that would allow you to see what the contents were without having to see the whole image. If so, then the Apple reviewers could look at the visual derivative to see if it was as expected, even if they whole image hadn't been uploaded.
Frequently Asked Questions #
Can't a device just lie? #
Yes. The threat model here is a bit odd because usually
we assume
endpoints are uncompromised, but in this case uncompromised
is kind of an ambiguous concept. In order for the system to work,
the device has to execute the protocol honestly, but
that's not necessarily what users want: presumably people who
are downloading CSAM images don't want a visit from NCMEC, let
alone the police.[Update: NCMEC isn't a law enforcement agency, so
they're probably not going to pay people a visit.] So, a basic assumption here is that even
though the device is in the user's hands, it's actually doing
what Apple wants. This is made possible by the fact that
Apple controls what software is able to run on their
devices and unless you jailbreak
the device you can't change those behaviors.
Can Apple read other images on my device? #
Sort of? The basic design of the system is that only images which have matching hashes get reported. Assuming that the hashing algorithm is operating as designed, then the hash value should be more or less evenly distributed across the output range. So Apple shouldn't be able to send you a database that will just let them read all your images. However, they can certainly send a database that has non-CSAM images, as well as fill in the empty rows in the table with real values and just hope to get lucky. Presumably Apple has some policy controls to prevent this, but that's not something that is technically enforced or that is readily publicly verifiable.
But again, this is just assuming the threat model in which the device is uncompromised (in this case from the user's perspective). In practice, Apple can just change the code on your device and make it do anything they want, including uploading copies of all your images whether you have iCloud on or not. Note that if iOS were an open source system (along with methods for people to verify that the code that was on the system was really built from the published source) then this threat would be significantly diminished. However, even though pieces of iOS are open source, the system as a whole is not.
Can't people change images to evade this system? #
Probably? Because of property #4 people don't know whether a given image hash is in the database, but the hash algorithm is known (well, sort of: it's not been published but someone could reverse engineer it out of the code), so it would be possible to take an image and just change it enough so that the hash changes. This would probably help evade the system, though of course Apple could also seed hashes for perturbed images or adjust the algorithm to make it insensitive to these particular perturbations.
What about end-to-end encryption? #
If Apple were to change iOS to do end-to-end encryption for photos, this would make things more complicated. They'd still learn about hashes but the process of manual review would become harder. It's possible they could try to use machine learning techniques to reverse the hash, but given that the question is precisely whether the hash is a false positive (i.e., matches an innocuous image) that's not that useful; you already know that it matches some known image. If the "visual derivatives" are thumbnails or the like, then it probably wouldn't make much of a difference because Apple could still review them. If they're not, then Apple would probably need to change the "additional data" to include the encryption keys for the images, in which case they could decrypt the image and review it directly.
What happens if people disable iCloud? #
For now, this means that their images don't get scanned, but Apple could change that in the future. However, in the system described above, they then wouldn't have a copy of the image at all, even an encrypted one, so this complicates the review process. Again, if the "visual derivative" includes a thumbnail, then things probably still work. But if not then they would presumably need to change the system to upload a thumbnail or the image itself.
What about Quantum Computers? #
Readers of my post on quantum computers might wonder what the impact of quantum computers is on this system. I'm not entirely sure, but I suspect that it would allow anyone to be able to extract Apple's blinding key and hence the original database. It would probably also allow someone -- and especially Apple -- to decrypt every voucher, not just matching ones. Neither of these seems great, but given that the original data was probably protected with a vulnerable algorithm, it's not clear exactly how much worse this would be in practice.
The table at this link indicates that photos are encrypted, but it seems likely that this means just that they're encrypted with keys known to Apple, which might protect you from external attack, but not from Apple. ↩︎
It seems like it's possible to synthesize something that might look vaguely like the original image from a perceptual hash, but the results probably are never going to be that accurate. ↩︎
The ML in the system comes in in the training of the NeuralHash algorithm. ↩︎
The actual protocol seems to use a variant of Cuckoo Hashing ↩︎
Assuming I understand the situation correctly, synthetic matches also make the system slightly less sensitive because there is some chance that a synthetic match will overwrite a real match (recall that clients have no information about whether a match is real or not). However, unless the rate of synthetic matches is set very high, this shouldn't have much of an impact, perhaps effectively moving the (already arbitrary) threshold up by a match or two. ↩︎
If the clients randomize the frequency at which they generate synthetic matches, then this will significantly decrease the information the server learns about an individual client, while still allowing the server to estimate the overall match rate. Thanks to Kevin Dick for this observation. ↩︎