Overloaded fields, type safety, and you
Don't quote me on this
Posted by ekr on 19 Aug 2024

I recently learned that Southwest has a policy of giving passengers who don't fit in a single seat a free second seat. This isn't an issue for me personally, but I was curious how it worked and that lead me to Southwest's page on how to book a second seat:
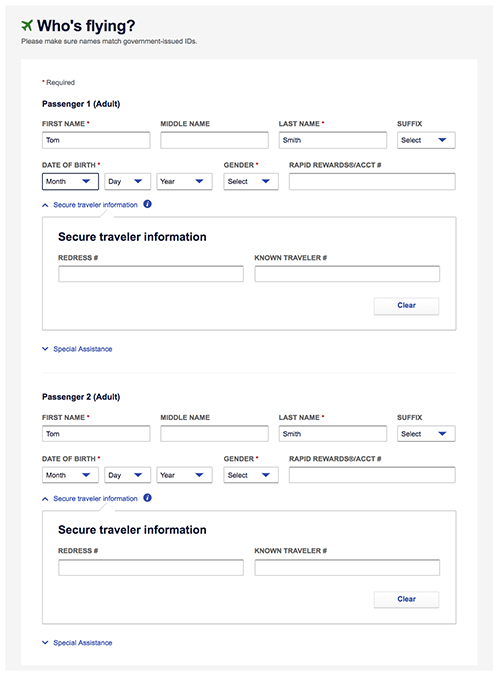
Here are the instructions:
Complete the "Who's Flying?" name fields for a Customer of size as follows:
- Without a middle name: A Passenger named Tom Smith would designate Passenger One as "Tom Smith," and Passenger Two as "Tom XS Smith" (first name Tom, middle name XS, and last name Smith).
- With a middle name: A Passenger named Tom James Smith would designate Passenger One as "Tom James Smith," and Passenger Two as "Tom James XS Smith" (first name Tom, middle name James XS, and last name Smith).
What's happening here will be instantly familiar to anyone with programming experience: Southwest's systems aren't set up to carry the information that someone wants a spare seat and so instead they have shoehorned the information into the passenger's middle name. This kind of thing happens all the time in software engineering, and is often necessary when you find yourself in a tricky situation, but can also lead to a number of different kinds of problems.
Some Examples #
In my experience the most common way to get yourself into this kind of situation is when you have to deal with some system you can't change, and especially when you have a sandwich like the figure below where you have two components you can change with a component you can't change in between.
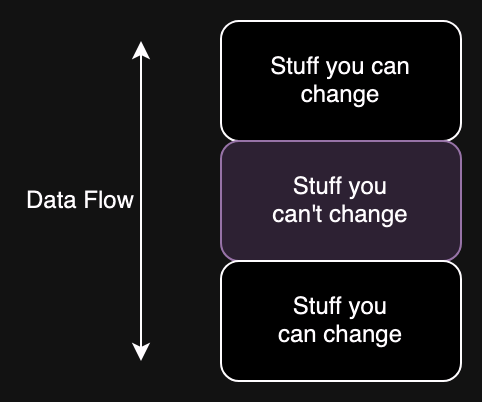
For example, in the case of Southwest, mostly likely the problem isn't the Web page itself; it's quite easy to modify the form to add an extra checkbox or something. Similarly, there is eventually some system that knows about the extra seat policy. But almost certainly there is some back-end system somewhere which doesn't know about the policy and doesn't have room for an extra field (e.g., some database with a fixed set of columns) and so the easiest thing to do is to smuggle the information in the middle name field and then have the system you have some other system which does know about the policy and is able to pick out names with "XS".
You don't have to look very far to find plenty of other examples, both in software and in the real world.
Hi, I'm Bob NLN #
The form above assumes that everyone has a first and last name (hence the red *s indicating it's mandatory) even if you don't have a middle name. However, many people only have one name (Afghans, Indonesians, Grimes, ...), so what do you do when the form insists you put something in both fields. Depending on the design of the form validation logic, there are various options, but the one commonly used on official forms is to use either:
- NFN for No First Name or FNU for First Name Unknown
- NLN for No Last Name or LNU for Last Name Unknown
Of course, if you just have one name, is it the first or the last name? For the US passport, at least, you provide single name as your surname and use FNU for your Given Name. As an aside, people sometime use "No Last Name", but then you occasionally fall afoul of form validation logic which won't allow embedded spaces. This is also bad news for people with multiple word non-hyphenated last names.
Credit Card PANs and Format-Preserving Encryption #
The next one is a little more complicated. Suppose you have a database which stores credit card numbers (technical term: Payer Account Number (PAN)) or social security numbers. It's good practice to have the database validate the number and lots of software that uses the database will also rely on the number having a given structure. For instance:
- The first digit of the PAN indicates the type of card (4 for visa, 5 for MasterCard, etc.)_
- Some of the next 5 digits indicate the issuing bank
- There is a check digit (the last digit in most cards, digit 13 for Visa).
Suppose you want to give access to the database to someone who you don't entirely trust but needs to do some analysis. You could just remove the card numbers, but maybe you want to be able to detect PANs which are duplicated across users (this is even more relevant for SSNs). One way to do this is to encrypt the PAN,[1] but here we run into a technical limitation in the design of our cryptographic algorithms.
The basic encryption primitive you have to work with here is what's called a "block cipher", which operates on binary blocks of size 2n, typically 64 bits or 128 bits. The way that a block cipher works is that it's a mapping from input blocks to output blocks, with each key producing a different mapping. In other words:
Encrypt(K, Plaintext) → Ciphertext
If the PAN is 16 digits long, then it's easy to map it into a 128-bit block, just use one digit per byte.[2] The problem is that the ciphertext is then evenly distributed over the space of binary blocks, which means that you're quite likely to end up with a value which isn't a valid PAN,[3] for instance, it might contain letters or unprintable characters. When you take that ciphertext and try to insert it into your database, it will fail the database validity checks, which creates an obvious problem.
The solution is something called format preserving encryption (FPE), which is effectively a block cipher which works on arbitrary-sized blocks instead of blocks that are powers of 2. This allows you to encrypt from inputs that look like PANs into outputs that also look like PANs, and therefore can be inserted into the database, just like regular PANs.
TLS Extensions and SCSVs #
This kind of hackery doesn't just happen in text files and databases;
we do it all the time in network protocols.
The way that TLS negotiation works is that the client sends an initial
ClientHello message to the server. In the predecessor protocol to
TLS, SSLv3, was
designed, ClientHello looked like this
struct {
ProtocolVersion client_version;
Random random;
SessionID session_id;
CipherSuite cipher_suites<2..2^16-1>;
CompressionMethod compression_methods<1..2^8-1>;
} ClientHello;
The important values here for our purposes are:
client_version- A two byte version number reflecting the highest version the client supports.
cipher_suites- A list of two byte values indicating which algorithms the client supports. Each suite reflects all the algorithms that will be used for the connection (e.g., signature, key exchange, encryption, etc.).
The server responds with a ServerHello message which selects a specific
version and cipher for the connection:
struct {
ProtocolVersion server_version;
Random random;
SessionID session_id;
CipherSuite cipher_suite;
CompressionMethod compression_method;
} ServerHello;
One thing to notice is that this is not a very flexible structure; for instance if you wanted to (for instance) say that you wanted the server to send packets no bigger than a certain size, there would be no place to do it. You'll notice the echoes here of the discussion above about having a format that is inflexible and then wanting to extend it.
When TLS 1.0 was standardized, however, the designers noticed that there actually was a place that had some flexibility. Each handshake message is carried in an outer wrapper which looks like this:
struct {
HandshakeType msg_type;
uint24 length;
... // The message itself
}
This wrapper servers two purposes:
- It lets you identify which message you are receiving, because there are parts of the handshake state machine where the peer can send more than one message and you need to know which one it is.
- It allows you to have a single function which reads the entire
handshake message (using
length) that works for every message type and then you can hand the whole message off to a different per-message function.
However, this also creates a situation in which the body of the
handshake message (i.e., the next length bytes on the wire)
can be inconsistent with what the message was supposed to be.
For example, imagine that the client sent a message which was
nominally a ClientHello but was only two bytes long. Obviously
that's not valid, and the server needs to detect it and fail.
On the other hand, it's also possible for the message to be too
long, which is to say that there are trailing bytes after you've
consumed everything in the handshake structure. This is also
an encoding error, but it's one that's survivable because you
already have the data you need. The TLS 1.0 designers
noticed this too and decided to make a special exception
for ClientHello:
In the interests of forward compatibility, it is permitted for a client hello message to include extra data after the compression methods. This data must be included in the handshake hashes, but must otherwise be ignored. This is the only handshake message for which this is legal; for all other messages, the amount of data in the message must match the description of the message precisely.
A subsequent specification provides some actual rules about what was allowed to go in this section, namely a list of "extensions" formatted in tag-length-value format:
struct {
ProtocolVersion client_version;
Random random;
SessionID session_id;
CipherSuite cipher_suites<2..2^16-1>;
CompressionMethod compression_methods<1..2^8-1>;
Extension client_hello_extension_list<0..2^16-1>;
} ClientHello;
struct {
ExtensionType extension_type;
opaque extension_data<0..2^16-1>;
} Extension;
Because extensions are typed, this is a general extensibility
mechanism and you can always add new stuff just by adding new
extension_type code points.[4]
Intolerance #
So everything is great, right? Well, not quite. SSLv3 was first
deployed in 1996 and TLS 1.0 was published in 1999 the definition of
extensions in 2003. This meant that by the time TLS 1.0 was deployed,
there were a lot of SSLv3 servers in the field and not all of them
accepted more modern ClientHello messages. There are at least two
sources of intolerance:
- Not liking any version number different from that for SSLv3 (which is
0x0030, as it happens) - Not liking trailing bytes in ClientHello (this actually isn't too surprising, as what to do in this case was a bit ambiguous in SSLv3).
In either case the server would generate an error (maybe a TLS Alert
or maybe just cling the connection). This creates a compatibility problem
when a client sends a modern ClientHello to one of these servers
and it rejects it.
Fallback and Downgrade Attacks #
In order to deal with this, some TLS clients used a technique called
fallback in which they reconnect with older version ClientHello after
a newer one fails, like so:
The problem here is that this process is insecure because the attacker can forge an error and force you to reconnect, like so:
If the newer version of TLS is more secure than the older version, then the attacker just forced you to use a less secure protocol. This is called a "downgrade attack". Of course clients could have just decided not to do any fallback, but that would have made it so they couldn't connect to those old server, which the client vendors didn't want to do.
SCSVs #
What you need is some way to distinguish attacks from extension- or
version-intolerant servers. The problem is that neither alerts nor TCP
closures are authenticated, and there's no straightforward way to
authenticate them. Instead, what we want is some way for
the client to safely signal that it supports modern TLS in a way
that doesn't trigger older servers. The options are fairly limited,
but there is a field that is safe to use, the cipher_suite
list.
Recall that the semantics of this list are that the client provides some ciphers and the server picks one, so servers are used to seeing ciphers they don't recognize them and just ignore them. All we have to do is define a new cipher that means "I am actually a modern client". TLS calls this a Signaling Cipher Suite Value (SCSV). The way this works is that when the client falls back to an older TLS version it also includes this value; if the server sees the SCSV cipher suite and it supports a newer version of TLS, it rejects the connection.
Note that this doesn't stop the attacker from blocking the connection from happening—that's not really possible if the attacker controls the network—it just prevents them from forcing the connection down to a weaker version.[5] This isn't a perfect defense because servers have to deploy the SCSV and not all of them have, but it's better than nothing. Even better, of course, would be not to fall back, which is what browser clients eventually did.
Random Signaling Values #
TLS 1.3 also does some other signaling shenanigans where
it overloads the Random value in the ServerHello in order to signal some
special conditions:
- That a
ServerHellois actually a special message calledHelloRetryRequest - That the
Serversupported TLS 1.3 even though it received a TLS 1.2ClientHello.
This is actually a case where these are technically valid Random values,
but are just extremely unlikely to be generated by accident.
When TLS 1.3 was being designed, we discovered that there was a nontrivial number of servers which didn't support version number 1.3 (despite accepting number 1.2). The TLS WG decided to address this by designing an entirely new version negotiation scheme, ironically based on extensions. The idea here was that as long as the server handled extensions properly it would be safe to offer the new version extension. Of course, if you don't handle extensions properly, you're back in the soup, but the normal process of upgrading eventually got the fraction of servers which didn't support extensions low enough that we were able to deprecate TLS versions below 1.2 and for browsers to disable the fallback mechanism.
Overloading #
The common thread in all of these cases is that we have taken a field that has one meaning and overloaded it with another meaning.
| Case | Original Meaning | Alternate Meeting |
|---|---|---|
| Name field | Actual name | No name |
| Credit cards | PAN | Encrypted PAN |
| TLS Cipher suites | Cipher suite | Fallback |
| TLS Random | Random nonce | Fallback, Alternate message |
The problem here is that the values associated with the alternate meaning would actually be valid for the original meaning (that's why the trick works in the first place). What you're relying on is that the values for the alternate meaning don't actually overlap with those for the original meaning, so, for instance, the SCSV cipher suite has actually been reserved, so there's actually no chance that it will happen accidentally, and the random values have a statistically very low chance of collision, but there are also real world cases where this kind of overloading causes serious problems.
NO PLATE #
Probably one of the best real-world examples here comes from license plates. Snopes has the full story of a guy named Robert Barbour who registered for a set of vanity plates providing the options "SAILING", "BOATING", and "NO PLATE" indicating that he didn't want a vanity plate if the first two options weren't available. Instead, the DMV sent him "NO PLATE" (ambiguity one). Even better, it turned out that San Francisco police officers used plate number "NO PLATE" to ticket cars which didn't have plates (ambiguity two), and he started getting tickets. The story doesn't end there, though:
couple of years later, the DMV finally caught on and sent a notice to law enforcement agencies requesting that they use the word NONE rather than NO PLATE to indicate a cited vehicle was missing its plates. This change slowed the flow of overdue notices Barbour received to a trickle, about five or six a month, but it also had an unintended side effect: Officers sometimes wrote MISSING instead of NONE to indicate cars with missing license plates, and suddenly a man named Andrew Burg in Marina del Rey started receiving parking tickets from places he hadn't visited either. Burg, of course, was the owner of a car with personalized plates reading "MISSING."
This turns out to happen fairly often, with different theoretically invalid values in the place of "NO PLATE", such as "VOID", "UNKNOWN", or "XXXXXX", because it turns out that they aren't actually invalid, or rather, they are regarded as invalid by one system (the police officers who are reporting the error) but not invalid by another system (the people requesting vanity plates and the order entry system that accepts their proposed plates).
It's tempting to think that the solution here is to have a single defined invalid value (as with the SCSV example above), and there are actually a number of systems which do have pre-determined invalid values. For example:
- No social security number can have a field that is all zeros (e.g., 123-00-1234)
- The phone number exchange "555" as in 415-555-1234 is reserved for demonstration values.
- The domains
.exampleand.invalidcannot be allocated and so are used for examples.
However, it turns out that this isn't enough.
malloc() return values #
In
C,
the way that you allocate memory on the heap is to use the malloc() function, as in:
Foo *tmp = malloc(sizeof Foo)
This allocates an object of the size of the object Foo and then
assigns it to tmp.[6] But what happens when there isn't enough memory so the call
to malloc() fails? The answer is that it returns a zero valued
pointer. The correct code here is:
Foo *tmp = malloc(sizeof Foo)
if (!tmp) {
error(...);
}This of course works fine, but nothing actually makes you check, so what happens if you forget. In that case you end up with what's called a "null pointer" and if you try to use it you get what's called a "null pointer dereference" (what Tony Hoare called a billion dollar mistake). In the best case, this will crash your program; in the worst case it's an exploitable vulnerability. The problem here is that even though the invalid value (0) is easily detectable, you have to actually check it. A better situation is one where it's not actually possible to end up with an invalid value.
Infallible allocation and new #
One approach is to have the function be what my Mozilla co-workers
used to call "infallible", which is to say that it can't return
an invalid value. Instead, the program crashes. For instance, you
could have a function called safe_malloc() which looks like this:
void *safe_malloc(size_t size) {
void *ptr = malloc(size);
if (!ptr) {
abort();
}
return ptr;
}In C++, malloc() (which allocates arbitrary memory)
is fallible, but the new operator (which creates
objects) is infallible: if it fails to allocate the
memory the program will crash.[7]
Union Types #
An alternate approach is to have the function return what's called a union type, which is a type that can contain multiple values, but not all at once. For instance, consider the following C code:
union {
int a;
char b;
} U;The way this works is that the union type is as big as the largest possible value it contains
(in this case a) but a and b share the same space in memory,
as shown below:
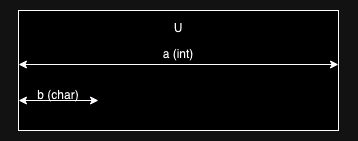
This isn't actually the solution to our problem, but instead
recreates the problem. Suppose that I give you a pointer to an
instance of U (the C notation is U *), with the memory region it
points to being the bytes [00, 01, 02, 03]. This could be either of
two things: the integer 0x00010203 (I'm assuming a big-endian
architecture) or the character 0x00. There's no way to tell from
context.
What you actually need here is what's sometimes called a discriminated union,
which also has a type field telling you what is inside it, like so:
struct {
enum { INT, CHAR } union_type;
union {
int a;
char b;
} u;
} U;The way this works is that the union_type field tells you what's
inside the value. If we think about this in the memory allocation
context, we would have something like:
struct {
enum { MEMORY, ERROR } union_type;
union {
void *result;
int error;
} u;
} MallocResult;If malloc succeeds, then it returns a MallocResult of type
MEMORY (i.e., union_type is set to MEMORY) and sets result to
the allocated memory. If it fails it returns a MallocResult of type
ERROR and sets error to the actual error value. To use this, you
would write code like this:
MallocResult r = malloc(sizeof Foo);
if (r->type == ERROR) {
error(r->u.error);
}
Foo *tmp = r->u.result;This solves the problem of knowing what the type of the result is, but still doesn't really solve your problem because you can just assume things are working, and have a null pointer dereference anyway:
MallocResult r = malloc(sizeof Foo);
Foo *tmp = r->u.result;This is about the best you can do in C, but more modern languages have a safer structure. For instance, here is what the same union looks like in Rust (where it's called an "enum"):[8]
enum {
Result(Memory),
Err(Error)
} Result;This looks pretty similar but the important difference between
C and Rust in this case is that you're not allowed to access the values
directly. The enum keeps track of what is inside it and
Rust won't let you access the wrong type. Instead, you do something
like this:
let result = malloc(); // Rust doesn't really have malloc
match result {
Result(memory) => {
// We have successful result in |memory|
},
Err(error) => {
// Things failed with error |error|
}
}The point here is that the language protects you from screwing up: you can only access the value that's actually in the union type, not the other alternate values.
The syntax above is a bit complicated and in practice, Rust has a
special type just for this called Result. Result is set up so you
don't have to use the match stuff above, but instead has
a function called unwrap(), which works like this:
let result = function().unwrap();The way this works is that malloc returns a Result that contains
either the result of the call to function(). If you call
Result.unwrap() then one of two things happens:
- If the function succeeded, then
unwrap()will return the function return value. - If the function failed, then
unwrap()will terminate the program (there is also a way to ask if it succeeded).
The technical term here for the property Rust is providing here is "type safety", with the compiler guaranteeing that you can't misinterpret one type (error) as another (a result).
Excel Date Translation #
Type safety isn't just about exceptional cases where we have one "main" meaning (e.g., the license plate) and one exceptional meaning (there is no valid plate). There are many situations where we have a field that can be of multiple types of actual data (union types can of course be used this way). This is conceptually powerful, but can lead to major problems, as in Excel.
Excel, like all spreadsheets, is structured as a set of cells.
Cells can contain freeform text data but can also contain other
more specific kinds of data (e.g., numbers, dates, etc.).
While you can specifically tell Excel what
type a field is (as with an option type), you usually don't,
because Excel can usually figure out what the field is from
what you type in. For instance, if you type in 1234, then
it's probably a number, and Excel will treat it accordingly;
If you type in ABCD, then it's proably just freeform text;
and if you type in 2024-01-01 then it's probably a date.
This last case is where things can go spectacularly wrong
because that Excel is quite aggressive about
converting things to dates if they can plausibly be interpreted
that way. For instance, if you type MARCH1 into Excel it will
convert it to Mar-1, which is to say "March 1st".[9]
Unfortunately,
it's quite common to name genes with strings that look
like dates, for instance one gene is named
"Membrane Associated Ring-CH-Type Finger 1" (MARCH1), which,
as noted above, Excel turns into "1-Mar". This turns out to
be quite a pervasive problem in genomics, as documented by
by Ziemann, Eren, and El-Osta
in 2016:
The problem of Excel software (Microsoft Corp., Redmond, WA, USA) inadvertently converting gene symbols to dates and floating-point numbers was originally described in 2004 [1]. For example, gene symbols such as SEPT2 (Septin 2) and MARCH1 [Membrane-Associated Ring Finger (C3HC4) 1, E3 Ubiquitin Protein Ligase] are converted by default to ‘2-Sep’ and ‘1-Mar’, respectively. Furthermore, RIKEN identifiers were described to be automatically converted to floating point numbers (i.e. from accession ‘2310009E13’ to ‘2.31E+13’). Since that report, we have uncovered further instances where gene symbols were converted to dates in supplementary data of recently published papers (e.g. ‘SEPT2’ converted to ‘2006/09/02’). This suggests that gene name errors continue to be a problem in supplementary files accompanying articles. Inadvertent gene symbol conversion is problematic because these supplementary files are an important resource in the genomics community that are frequently reused. Our aim here is to raise awareness of the problem.
The problem here, as so often happens in software, is that someone tried to be smart. Also that friends don't let friends use spreadsheets.[10]
Quoting #
I want to hit one more related topic: quoting, starting with a simple example, the comma separated value (CSV) file.
Comma Separated Values #
CSV is a format for tabular data, which is to say a table of rows and columns like a spreadsheet. A CSV file consists of a series of rows, with each row on its own line, separated by a newline character. Each row consists of a set of columns, with the columns separated by commas, like so:
first name,last name,age
John,Smith,20
Jane,Doe,23
Nicolas,Bourbaki,100This is a conceptually simple format, and you might think that it's simple to parse: just go line by line and then split on the commas.
But what happens if you want to have a field that itself contains a comma, like so:
first name,last name,age
John,Smith,20
Jane,Doe,23
Nicolas,Bourbaki,100
Robert,Kennedy, Jr.,70If you split this on commas the last row will consist of four columns rather than the three columns every other row has.
Robert, Kennedy, Jr., 70
Obviously, this is no good. The way you address this is by "quoting" fields that contain the separator character by wrapping them in quotes, like so:
Robert,"Kennedy, Jr.",70
So far so good. But what happens if you have a field that itself
contains a quote? The typical answer is that you escape it
by prefixing it with another character, such as backslash (\),
like so:
Elvis \"The King\",Presley,42
This is called "escaping" and the backslash is called the "escape character".
But this just pushes the problem around, because now we have the
problem of fields which contain backslash. The convention here
is that you represent those with a pair of backslashes (\\).
In other words:
A,A\\B,C
Represents the following three values:
AA\BC
When you put all of this together, you can unambiguously parse the file into fields and still represent any valid character inside each field, but at the source of a lot of complexity in the parser. It's not uncommon to see CSV parsing code just split on commas and hope there aren't any fields with embedded commas. The source of the problem is the same thing we've been fighting all along, namely that the comma has two meanings in this context:
- As a separator between fields
- As a character inside fields
We need some way to distinguish between those two contexts, which is what quoting does. But then we have to distinguish between quotes around fields and quotes within field, hence the backslash escape character. But now we have the same problem with the backslash, hence double backslash.[11] The easiest way out of this hole is to have a separator that isn't valid inside a field, in which case you can just split on the separator without any quoting, escaping, etc. Comma isn't a good choice here because it's very common to have data that has embedded commas, but what you'll often see used here is the tab character (character code 9), in what's called a tab separated value (TSV) file. This is easier to work with because most data won't have tabs in it at all and you can often replace tabs with spaces with no loss of meaning. An additional benefit is that the tabs help align the data so that columns will often line up properly.
SQL Injection #
If you incorrectly split up a CSV into fields, it's probably not that bad—you'll probably end up with the wrong number of columns, which is easily detectable—but there are cases where getting the quotes wrong can be much worse.
The most common tool for interacting with databases is a language called SQL. For instance, you might ask for every row in a database where someone had the first name "John" like so:[12]
SELECT * FROM Table WHERE FirstName='John';
Note the single quotes around 'John'. The reason for these is that
you're using spaces as separators and you might want to search
for a field value with embedded spaces, which you would do like
Jim Bob.
Now consider the case where you have a Web interface and you want to look up a user by name, as in the passenger entry field we started with at the top of this post: the user puts in their name and you want to look up their passenger record, like so:
SELECT * FROM Passengers WHERE FirstName='John' AND LastName='Smith'
AND DOB='1986-01-01';
Of course, if you're building a Web application, you're not really programming in SQL. Instead, you're working in some other language, such as Python, and then using it to execute SQL, like this:
cursor.execute("SELECT * FROM Passengers WHERE LastName='Smith'")Notice how I've wrapped the SQL command in double quotes to tell Python "this is all one string" and Smith in single quotes to tell SQL "this is all one field". This is an alternative to escaping for dealing with situations where you have embedded quotes in some field, at least in languages which allow both single and double quotes.
But of course I don't know the name that I want to search for in advance, as it's entered by the user. So instead what the Web app has to do is read the name the user entered in and then assemble it into an SQL command, something like this:
command = "SELECT * FROM Passengers WHERE LastName='" + name + "';"
cursor.execute(command)In this case, the name is in the variable name and we insert it into
the command template to form the actual SQL command we want to send to
the database to execute.
But now what happens if the name the user enters contains a quote, like, for instance d' Artagnan.[13] In that case we get this SQL command:
SELECT * FROM Passengers WHERE LastName='d' Artagnan'In this case the embedded quote in "d' Artagnan" gets interpreted as the end of the string to search for, which just becomes the letter "d" (as you can see from the syntax coloring) and the string "Artagnan" looks like the next bit of SQL, which (incorrectly) ends in single quote. This particular example will likely just create a syntax error in your SQL parser, because it's not a complete SQL statement, but that if the attacker deliberately crafts their name in order to be valid SQL. For instance they might enter the following name:
Smith'; DROP TABLES;'
This produces the following string:
SELECT * FROM Passengers WHERE LastName='Smith'; DROP TABLES;'';Which gets parsed as three SQL commands, namely a select from the database:
SELECT * FROM Passengers WHERE LastName='Smith';followed by a command which erases the entire Passengers table.
DROP TABLE Passengers;'Followed by some syntactically invalid SQL.
'';This last command is a syntax error
(though with some more cleverness we could make it valid)
but by this point the other commands
have executed and the Passengers database has been erased.
We've just
invented the SQL injection
attack, which is a major problem in database-backed Web systems.

From XKCD
The root cause here isn't so much quoting as inconsistent quoting. Specifically, the quote characters are special in SQL but get passed transparently through the Web form and Python APIs we are dealing with—though they are special in other contexts—as a result, the attacker is able to get them all the way through to the database where they can cause damage.
As it turns out, there is another attack in which the objective isn't to contaminate the database but rather the victim's Web browser. In this attack, called cross-site scripting (XSS), the attacker submits some data (e.g., in a comment on a Facebook post) that passes transparently through the site all the way to some other person's browser when the read the comment, but instead of displaying to the user, the browser instead interprets it as a piece of JavaScript and executes it in the victim's browser. As with SQL injection, XSS relies on constructing a special string that makes the browser think that the user-generated content (the comment) is over and that the rest of the text is JS, but in this case the attacker needs to construct the string in such a way that the database doesn't interpret it but the browser does. Describing how to do that is outside the scope of this post.
Final Thoughts #
We've come a long way from reserving an extra seat on the plane, so I wanted to try to see if I could pull things together. The underlying problem we are facing here with all these examples is the same: having the same set of bits which can mean two different things and needing some way to distinguish those two meanings. Failure to do so leads to ambiguity at best and serious defects at worst. That's why you see so much emphasis in modern systems on type safety and on strict domain separation between different meanings. In the best case, it would simply be impossible to treat data of type A as data of type B, but as a practical matter, you sometimes have to do so; it's those times when extreme caution is warranted.
You can also build a giant lookup table of random values to PANs, a process often called "tokenization". ↩︎
The situation is more complicated with 64-bit blocks, but it's obviously possible because there are many more 64 bit blocks than 16 bit credit card numbers. ↩︎
What I mean here is that it's not even properly formatted, as many properly formatted number strings are not valid PANs. ↩︎
People sometimes worry that the code point space might run out, but the type field is two bytes and we're nowhere near 65K extensions. Moreover, if we did get close we could always define a new extension which contained other extensions! ↩︎
Note that if the oldest version of is weak enough (imagine it wasn't authenticated at all) then this defense wouldn't work, but at least so far even SSLv3 is strong enough to prevent that bad an attack. ↩︎
Technical note:
malloc()returns an object of typevoid *. In C,void *is automatically cast to a type ofT *for any typeT, but in C++ it's not. In C++, the same code would beFoo *tmp = (Foo *)malloc(sizeof Foo). ↩︎Technically it throws an exception which you can catch, but I advise against this! ↩︎
In Rust you wouldn't actually be allowed to talk to raw memory, but let's ignore that for now. ↩︎
If you export to CSV you get 1-Mar. ↩︎
Google Sheets does some of the same stuff. ↩︎
The way to think about this is that there are really two backslashes, the backslash literal and the escape character. We're trying to map them onto one character in the text, but that flattening process inevitable means that one or the other variant has to be bigger. ↩︎
The
SELECT *means "Give me every column". I could get just one column by doingSELECT birthdate. ↩︎Yes, I know there is no space after the "d'" but the example works better this way. ↩︎