Understanding The Web Security Model, Part II: Web Applications
Posted by ekr on 08 Mar 2022
Note: This is one of those posts that is going to be best read on the Web, especially if you read your email using GMail or the like, as it will tend to mangle some of the HTML features.
This is Part II of my series on the Web security model. In Part I, I talked about the basic structure of the Web and how Web publishing works. However, quite early in the lifetime of the Web people started to want to do more than just publish information. In particular, they wanted to sell stuff. Of course, you could just publish your catalog on the Web and then have people email you their order, but this is obviously pretty clunky; what you want is a Web storefront (yeah, I know this is obvious now, but we're talking 1994!).
It's possible to build even fancier applications like Facebook or Slack with not much more than the primitives I introduced in the previous post; it's mostly a matter of combining them in the right way. That's the topic of this post.
How to build a Web store #
As I said, much of the initial work around Web applications was in building shopping sites. Your basic shopping site was pretty simple, with just a few functions:
-
Showing the catalog of items.
-
Adding selected items to the shopping cart.
-
Checking out, buying the items in the cart.
Let's go through these one at a time.
Catalog #
If you have a relatively small number of items, then you can build a catalog entirely with technologies we saw in the last post. There are two main options here:
-
If you have a very small number of items you can just make a static Web page that shows them.
-
If you have a somewhat larger number of items—especially if they go in or out of stock, or you have different prices in different regions—then you can dynamically generate the Web page.
The first option is straightforward. The way that the second option works is that you have some database that is basically a list of every item (the jargon here is stock keeping unit (SKU)), its description, maybe a picture or two, and the price or prices. Then when the user's browser requests a given catalog page, some code on your server goes through the database and renders it into an HTML page and serves it back to the browser.
It's important to realize that these two methods are interchangeable from the perspective of the browser; the server can switch between static and dynamically generated pages at will. It can also cache the dynamically generated pages—that is, temporarily store the output of what was generated—and serve that back to clients, thus saving run time and computing resources.
I know I keep making this point, but it really can't be overemphasized—as long as the data sent to the client is valid HTML, the browser doesn't care how it was generated. The point of having standardized network protocols is so that you can detach the implementation on each side from the messages they send to each other. This creates important implementation flexibility and allows new functionality to be added on either end without consulting the other. Part of what makes the Web so powerful is the combination of these standardized protocols with the ability to move implementation logic onto the client via JavaScript, as we'll see below.
This is great if you are a small site, but if your store
is the size of Amazon (or even the LCBO),
you obviously need people to be able to search. Fortunately,
HTML has a feature that makes this straightforward, the
<form> element.
At a high level, a form element is a container for one or
more input controls (text fields, buttons, pull-down
menus, etc.). The form element also has an "action" which
causes the client to send the values of these elements
to the server.
For instance, here is the form element that represents the subscription box at the bottom of this page:
<form class="email-form" action="https://educatedguesswork-subscribe.herokuapp.com/subscribe" method="post">
<input class="subscribe-email" type="email" placeholder="Your e-mail address..." id="email" name="email">
<input class="subscribe-button" type="submit" value="Subscribe"/>
</form>Ignore the class attributes; they are just labels that are used to attach
CSS styles to the form. The key things to look at here are the action tag on
the first line. What this says is that when you "submit" the form the browser
will navigate to https://educatedguesswork-subscribe.herokuapp.com/subscribe.
The first input field type=email creates a text field that you can put
your email address into. You submit by clicking on the "Subscribe" button which is generated
by the second input field, of type submit.
This produces the following result, which you can actually use to subscribe to my newsletter. Take a minute to do it now.
All done? Great.
When you fill in the form and click submit, the client sends the server an HTTP request that looks like this:
POST /subscribe HTTP/1.1
Host: educatedguesswork-subscribe.herokuapp.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
[other headers deleted]
email=ekr%40rtfm.com
To orient yourself, the first line is called the "request line", the next lines are
called "headers", and the stuff after the blank line is called the "body".
The Host header and the second field of the first line (/subscribe)
together match the URL in the action attribute of the form element
defined above. The body of the submission contains the value of the form,
in this case the email field and the value of [email protected].[1]
Even though this comes from a form submission, it's conceptually like a link click, and the result is that the browser is navigating to a new page. Therefore, the server is expected to respond with a new HTML page. As noted above, it can generate this page however it wants, but the idea is that it will do some processing on the form submission input, in this case subscribing you to the list. The response is just an HTML page indicating (hopefully) success.
It should be obvious at this point how to use an HTML form to build
a search interface: you use almost exactly the same HTML as above, except
with different text labels and probably input type search
rather than email.
The user would type the product search term in the box and click submit;
the server would respond with the products that match the search
term. That's all there is to it.
Statelessness #
In the early days of the Web, there was a lot of emphasis on how HTTP was stateless, which is to say that each request by the client was independent of every other client and that the protocol had no way of linking them up. This property extended down to the network layer: each request was carried over a new TCP connection, with the connection being closed after the server sent the response (in fact, closure of the connection was often used to indicate the end of the response).
Statelessness turns out to be a fairly inconvenient property for several reasons. The first is the one we are seeing here, which is that lots of things the server wants to do require creating continuity between client requests and so it was necessary to retrofit a state-keeping mechanism.
The second reason is performance: because of the way that network protocols are designed, there is a significant amount of startup overhead each time a connection is created (see slow start, so having a new connection for each request add significant delays. Much of the history of the development of HTTP is concerned with removing the legacy of this initial decision, first by adding multiple requests on the same connection and then by adding multiplexing of multiple simultaneous requests.
Shopping Carts #
Our next job is to let the user select some products and add them to their shopping cart. Unfortunately, this presents us with a problem, which is remembering which items the user has selected. The problem is that the HTTP requests to the server don't contain any kind of user identifier, so when your browser sends a request asking to add an item to your shopping cart, how does the server know whether to add it to your cart or to my cart?
The solution to this problem that eventually emerged is what's called a "cookie". The idea behind a cookie is simple: the server sends the client a cookie in the header of one HTTP response and the client stores it. The client then sends the cookie to the server in subsequent requests. The cookie is just an opaque string to the client and the server can construct it any way it pleases, but there are two main options:
-
An opaque identifier for this user or session. This identifier is then used as an index into some database that stores the user's state.
-
An actual representation of the user's state (e.g., a list of items in its cart).
Because the cookie is opaque, the server is, of course, free to use either of these techniques or a combination of the two.
The diagram below shows an example of how cookies can be used to build a shopping cart:
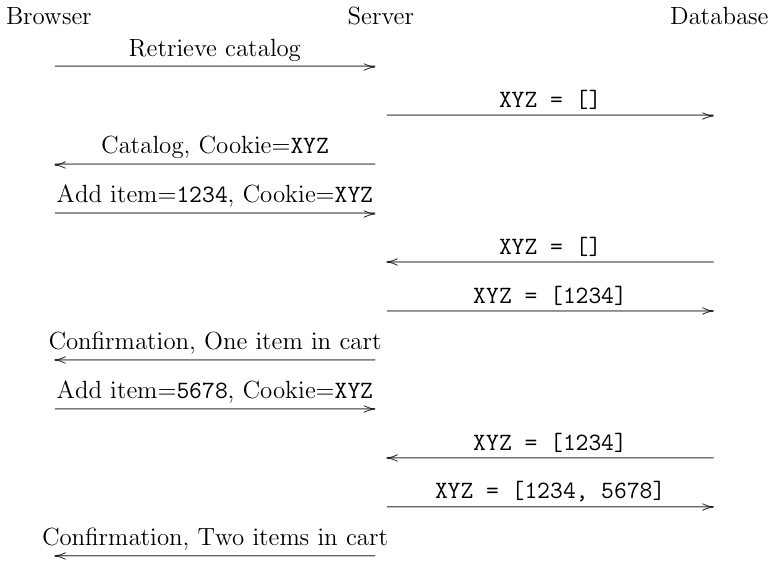
In this case, the server has chosen to use a back-end database, so the
cookie is just an opaque identifier (XYZ). Initially, the client contacts the
server and requests the catalog. The client and the server have never talked
before so the client doesn't have a cookie. The server creates a new
cookie with value XYZ and stores an empty shopping cart []
in the database associated with that cookie.
It then returns the catalog to the
client along with the cookie.
The user browses through the catalog and selects item 1234. When
they click to add it to the shopping cart, the browser sends a request
to the server with the item id and the cookie. The server then uses
the cookie to retrieve the shopping cart. Seeing it's empty, it adds
the item to the cart and stores that in the database. Finally, it
returns a confirmation to the user. The user browses the catalog some more and decides to buy item 5678.
This transaction proceeds the same way, except that this time
the server adds it to the already non-empty shopping cart, ending up
with two items.
Checkout #
At this point, we have all the tools we need to do checkout. When the user presses the checkout button, the server uses the cookie to collect all the items in the shopping cart and compute the final price. It then provides a Web form which lets the user enter their name, address, payment information, etc. The user submits that form (with the cookie, of course), and the server processes the transaction. It then can clear the shopping cart (so that the user can start shopping again) and send back the confirmation page.
Client-Side Applications #
In principle you can build just about any application you want with the techniques described above. In practice, though, loading a new page whenever you want to change anything is painfully slow.[2] It's certainly too slow to give a smooth app-like experience. Moreover, it's ugly because the page flashes as it rerenders and so it's anything but smooth. The resulting system isn't really viable for anything significantly interactive like Google Maps, Slack, etc.
Fortunately, we already have the solution: JavaScript. Recall that in Part I I said that JavaScript could change the DOM and that this would cause the page to change as well. The key thing is that unlike a page reload, small changes to the DOM mostly don't cause the entire page to rerender (only the elements that need to be updated).
Here's a simple example of what I'm talking about. The box below is a list of entries. If you enter a new entry in the box at the bottom and hit return, it will be added to the list without the page reloading.
| Shopping List |
|---|
| Apples |
| Bananas |
The way this works is just that I have a tiny piece of JavaScript that watches for you to hit return in the entry box and adds the value of the box into the list:
const tbodyEl = document.getElementById("entries-list");
const textboxEl = document.getElementById("list-addition-entry");
const formEl = document.getElementById("list-addition-form");
formEl.addEventListener("submit", function(event) {
event.preventDefault();
const row = tbodyEl.insertRow(-1);
const cell = row.insertCell(0);
cell.appendChild(document.createTextNode(textboxEl.value));
textboxEl.value = "";
});We don't need to go through this in detail, but at a high level, the
first three lines select the relevant elements (the table, the textbox, and the form),
and the rest of the code is a JavaScript function that retrieves the
value from the textbox and adds it to the list. Attaching it
to the "submit" event ensures it will run whenever the form is submitted,
which is when you press return.
Obviously this is a trivial example, but trivial examples are the stepping
stones to real programs. Suppose we wanted to make something like Slack.
The most basic version really only needs two small changes:
-
When you type into the window, it needs to send a message to the other people in the chat.
-
When someone sends you a message, it needs to receive it and add it to the list of messages.
These are both done with the same basic technique: a Web Service API.
Web Service APIs #
So far, all the examples of requests made to Web servers are for content which will then be consumed by the browser (e.g., HTML, JavaScript, etc.) A Web service API is different: it serves data that is intended to be consumed by JavaScript running in the browser.[3] For instance, in our chat application, the server would have (minimally) two functions:
- Send a message to a channel.
- Receive any new messages on a given channel.
Each function requires defining a few things:
- The URL (path) for the API function. It's conventional to refer to URL, and by extension the function, as an "API endpoint".
- A definition for the data that the client sends to the server (both format and semantics)
- A definition for the data that the server sends to the client
For instance, here's the API that Slack uses to post a message.
The Client Side #
On the client side, the JavaScript uses the
fetch API or the
older XmlHttpRequest (XHR)
API to talk to the server. These Web APIs let it make arbitrary (within some limits I'll cover later)
HTTP requests to the server, which means that they can use the endpoints provided by the server.[4]
To continue our chat example above, whenever the user types a message
into the compose window and hit enter, the JavaScript function that
gets activated would use fetch to tell the server
that a new message had been added to the chat. This might look
something like:
POST /send-message HTTP/1.1
Host: chat-server.example.com
message=Hello World!
Obviously, this could be fancier and include a channel identifier, or, if it were a direct message, the recipient identifier, but you get the idea. Depending on the way the application was written, that same function might add the message to the local window or the server might handle this with the same code it uses for incoming messages (see below).
This brings us to incoming messages. The simplest way for this to work is for the server to have an endpoint that allows the client to ask for new messages. For instance, it might look something like this:
GET /get-message?lastmessage=105 HTTP/1.1
Host: chat-server.example.com
The semantics of this request would be something like "Send me a copy
of every message with a sequence number greater than 105". That way,
the client can just ask for new messages without the server having
to remember which ones the client already knows. And a new client
can get all the messages by sending lastmessage=0 (or maybe -1,
if you started counting from 0). The server would then respond
with a list of new messages, which would be empty if there were
no new messages. Once those messages are received, the client
side JavaScript can just add them to the message window.
This style of application was originally known as Asynchronous JavaScript and XML (AJAX)). Asynchronous because you could be using the Web application while it talked to the server. JavaScript for obvious reasons. XML because at the time most servers used XML to send messages around (XML is just a structured data format). In recent years, however, fashions have changed and increasingly people structure their data in JavaScript Object Notation (JSON) instead.[5] "AJAJ" just doesn't have the same ring to it, though. Whatever the name, this is now the dominant style of Web application, for sites as diverse as Google Maps, Facebook, Slack, and Kayak. You still see old-style Web applications, but if you want to do something fancy—which people often do—then it's likely to have some sort of AJAX-y component.
Just to keep emphasizing this point: the only new piece of technology here is the existence of the client-side HTTP APIs. Everything else is just done server-side by adding new server-side endpoints and writing new JavaScript which the server sends to the client.
Notifications #
With that said, there is one kind of inconvenient property of this system: We've just shown how the client can find out what messages are available, but how does the client know when to ask? The obvious approach is to just poll the server constantly, but then you're adding a lot of load to the server as well as a lot of network traffic. You can also poll less frequently, like every 10 seconds or so; but while this might be fine for e-mail, it's really not fast enough for instant messaging, because it means that on average each message will be delayed by 5 seconds.
Paving the Cowpaths #
The story of long polling and WebSockets is a common pattern on the Web. The Web is now powerful enough that you can usually get the job done, though perhaps in a hacky and inefficient way. But people have product requirements so they do it anyway. Once some technique gets common enough, then it becomes attractive to build a better version into the platform ("paving the cowpaths") but application developers don't need to wait for that to happen. Moreover, there is usually a long period where only some browsers support the new technology, so application developers will check to see if it's available on a given browser and if so use it, and otherwise fall back to the old hack.
The fundamental problem is that HTTP requests are initiated by the client and there's no way for the server to talk back without the client saying something first. And then someone clever realized that instead of having the server respond immediately when there were no new messages, it could instead wait to respond until there were new messages. This is called a "long poll" and lets the client gets the information right away, without constantly polling the server.
Long polling works, but it's not ideal. Due to various timeouts at different parts of the system, you can't have an HTTP request outstanding indefinitely, so as a practical matter the request times out after some tens of seconds and then you have to reissue it. Also, it's just kind of a hack. Back in 2011 the IETF standardized a protocol called WebSocket that provided a bidirectional channel over top of HTTP to replace long polling.[6] This is a new—well not so new now—API, but fundamentally it's an optimization over long polling and if WebSockets isn't available you can always fall back to long polling.
Post-Standardization #
Up to now I've been focusing on how Web applications are built, but now I want to zoom out and talk about the bigger picture.
Traditionally, client-server applications relied on standardized protocols. This means that there is some document which describes what messages the client can send the server and how the server will behave in response and vice versa. For instance, if you are reading mail on your iPhone, you are probably using a standardized protocol (likely IMAP) to talk to the server. This is why the iOS mail client can talk to any mail server; you just need to give it the address of the server and your username and password. All of the protocol machinery is built into the mail client, which knows how to send email, download it, etc. It can show any UI it wants but it needs to comply with the protocols.
The Web is also built on standardized protocols, of course: HTTP and TLS for interacting with the server, HTML and CSS for formatting the page, JavaScript and Web service APIs for application logic. These are all standardized, which is why—at least most of the time—any Web site will work on any browser. But these standards only define the application infrastructure: the actual Web application is a combination of logic on the server (however that's implemented) and logic on the client written in JavaScript. This has huge implications because it means that the application author provides both the client and the server and therefore doesn't need to coordinate with anybody but themselves. That's why the world was able to switch from applications that used XML for data transfer to JSON for data transfer without changing the Web browser at all.
When the first real interactive Web applications using AJAX came out, this was a truly revolutionary property. After years of painstaking coordination defining every detail of application protocol behavior, suddenly it was possible to quickly build a complete client/server application without talking to anyone. It had of course had always been possible to define your own protocol and write a client and server that spoke it, but getting people to download your client was a huge obstacle; by contrast anybody could use your Web app just by navigating to the right place. Moreover, the Web browser included all kinds of powerful facilities—this is even more true now—that you would have had to build (or at least download) yourself.
Of course, now it's 2022, 15 years after the introduction of the iPhone. We have mobile app stores and the problem of software distribution—and in particular updating—has gotten much easier, so on mobile you can invent some proprietary protocol and roll out an app and as long as people download it, you're good to go. If you want to change the protocol, no problem, just update to a new version. The Web is like this, but even moreso because users don't need to install or update software: they just get whatever the new thing is when they load your site. This lets vendors build a completely vertically integrated system that leverages the power of the Web platform but without having to standardize—or, often, even document—anything.
Obviously, this has real benefits in terms of engineering velocity, but it's also contributed to a situation in which the user experience of a site and its functionality are completely entangled, so it's hard to use (say) Facebook without the Facebook UI. If you don't like something about that UI, you're basically out of luck. And even if you did reverse engineer the server-side APIs that Facebook used and write your own client, there's no guarantee Facebook won't change those APIs tomorrow. By contrast, if you want to use a different mail client with mail that is hosted by Gmail, it's just a download away.
This isn't to say that there isn't still plenty of work going into creating standardized technologies for the Web. However, that work is primarily concentrated on creating new plumbing (e.g., TLS 1.3 or QUIC) or new Web platform features (e.g., WebRTC or Web Assembly). This all makes the Web a better platform for running applications, but the applications themselves live on top of that substrate and are largely opaque and non-interoperable.
Next Up: Origins, and the Same Origin Policy #
At this point, we've covered most of what you need to know about how the Web works in order to understand its security model (and I'll be introducing the rest as we go). In the next post, I'll be covering the basic unit of Web security: the origin.
Note that this actually says
ekr%40rtfm.com. This is what's called escaping of the @-sign. It's not really necessary here but is done for consistency with cases where the address would appear in the URL, where the @-sign is forbidden. ↩︎Not quite as slow as you might think because a lot of the images and the like on the page can be cached, but still slow. ↩︎
Obviously standalone apps can and do use these APIs, but the topic of these posts is the Web. ↩︎
Yes, I know that calling both of these APIs is confusing. I resisted calling the HTTP APIs offered by servers "APIs" and then finally gave up. ↩︎
JSON is modestly easier to work with, but like styles of jeans, data formats tend to cycle in and out of fashion. ↩︎
For the nerds here, we also have the Web Push API which consolidates channels to multiple servers. ↩︎