DNS Security, Part I: Basic DNS
Posted by ekr on 19 Dec 2021
Over the past few years, the topic of the security of several Web browsers, including Firefox, Chrome, and Safari, have been rolling out DNS over HTTPS (DoH), which as brought the question of DNS security to the forefront, but also resulted in (or just revealed?) a lot of confusion about DNS security. This post is the first in a series on that topic, covering the basics of DNS and some of the security properties. Future posts will cover DNSSEC, DoH, etc.
What is DNS? #
The basic unit of addressing for devices on the Internet is the IP (Internet Protocol) Address, which is just a large number (32 bits for IP version 4 and 128 bits for IP version 6). It's conventional to write IPv4 addresses like so:
192.0.2.1
And IPv6 addresses like so.
2001:0db8:0000:0000:0000:8a2e:0370:7334
For obvious reasons, people don't want to memorize these addresses and
instead want to use names, such as example.com. The Domain
Name System (DNS) is responsible for mapping these names (domain
names, hence "Domain Name System") onto addresses. This lets you type
https://www.example.com/ into your browser, with the computer
then figuring out the actual IP address and connecting to it.
The DNS can also serve other kinds of information than IP addresses,
such as MX records, which say where to find a mail server
for a given domain (this is what allows me to have the mail and
Web service) or TXT records, which contain freeform text.
How does it work? #
DNS names consist of a series of names ("labels") separated by a period
(conventionally called a "dot"). This is arranged in a hierarchy so
that (for example) example.com is "owned" by .com.
Conceptually, you organize the names in
a tree, with the name being read right to left and the tree organized
from top to bottom. Thus example.com is the node at the lower
left of the tree:
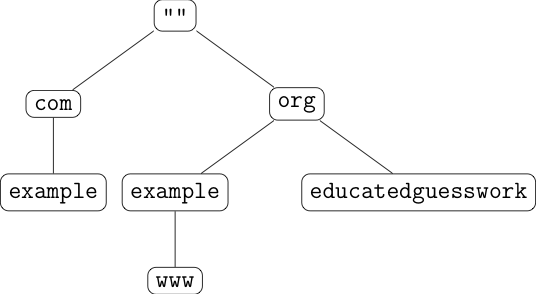
Every node on the tree can have data associated with it, so
for instance, example.org could have IP address 192.0.2.1
and www.example.org could have IP address 192.0.2.2.
This is a familiar computer science data structure and
as you might expect if you are used to working with trees,
you look up data in the tree (the jargon here is
"resolving") by starting at the top of the tree and working
your way downwards.
The Resolution Process #
The figure below shows the process of
resolving example.org. (I know that
this is complicated, but don't worry I'll walk through it.)

The general structure here is what's called a "request/response"[1] protocol: the client sends a request to a server and gets a response. There are three request/response pairs, each to a different server. I go through each message below.
-
The client starts by sending a request to the root server and asks it who is responsible for the domain name
org.[2] Root servers are special servers which know about all the single-label names ("top-level domains") such as.org,.com, etc. There are actually a number of root servers, nameda.root-servers.net,b.root-servers.net, etc, and the client just picks one. In order for this to work, the client needs to be preconfigured with a list of root servers and of their addresses, so it can send them messages (obviously it can't look them up with DNS because that would require contacting the root servers, which needs the addresses). -
The root server, in this case
a.root-servers.netreplies thatb2.org.afilias-nst.org(operated by name operator Afilias is responsible for.organd tells the client that[3]. One interesting thing to note is that the root server also provides the address at whichb2.org.afilias-nst.orgcan be reached; because that server also has a name in.org, the client can't use the DNS to resolve it (it would first need to contact that same server!) and so the root has to provide the address. The technical term for this information is "glue". -
The client now contacts
b2.org.afilias-nst.organd asks who is responsible forexample.org. -
b2.org.afilias-nst.orgresponds thatb.iana-servers.netis responsible. In this case, the server doesn't need to provide a glue address because the response is in.netand so the client could look it up via the normal process (not shown). -
The client now contacts
b.iana-servers.net, but instead of asking who is responsible forexample.orgit asks for its address (it already knowsb.iana-servers.netis responsible). -
b.iana-servers.netresponds that example.org's address is93.184.216.34.
At this point (after three round trips), the client knows the IP address for example.org.
Recursive Resolvers #
In the description above, I talked about the "client" resolving a domain, but as a practical matter, this process is mostly not done by end-user computers. Instead, those computers talk to what's called a "recursive resolver"[4] provided by the network. The way this works is that the user's computer sends its query to the recursive resolver, which does the whole resolution process shown above and then returns the answer, like so:

Historically, this approach has been seen as having number of advantages. First, it allows the
recursive resolver to cache. If your network has 10 clients
(not unusual for even a small home network), then it's kind of
silly to have each one separately contacting the resolver
for google.com to learn Google's address (and even
sillier each time someone wants something in .com. The recursive
resolver can cache the first response it receives[5] and return responses immediately to other clients,
thus reducing the load on servers and also improving
performance for users because you don't need as many
round trips to resolve a name.
Second, it allows the recursive to apply local policies.
For instance, suppose that I don't want users on my network
to go to attacker.invalid, I can program my recursive
to return an error instead of resolving it, thus effectively
filtering out those names (this is often called "blackholing").
It's pretty common to use this kind of DNS filtering technique
in schools, libraries, etc. to filter out sites deemed
inappropriate.
Of course, whether this is an advantage depends on one's
perspective: if you're a user who wants to visit a site
that has been filtered in this way, you might think otherwise
(I'll get into this more in a future post).
You can also use control of the resolver to create names that only resolve locally. Suppose you have something (e.g., a printer) that you only want to be accessible to users on your local network. You can (partly) achieve this by not having the name be publicly resolvable but by having the recursive resolver inserting responses for it. This is called split horizon DNS.[6] A similar technique is used by some ISPs to serve ads by detecting if you try to resolve a name which does not exist (e.g., because of a typo) and inject their own response which points you to a page they control.
Historically, software on the user's computer didn't even talk to the recursive resolver directly. Rather, it called an operating system API that did the work for it. This saved work for the client programmer as well as providing a consistent experience between different clients on the same machine. This also allowed the operating system (and the administrator) control of the resolution process, which is especially important if you are running other name systems besides DNS, such as Windows Internet Name Service; the operating system can automatically check all the potential name services without bothering the client. Now that DNS is so dominant, this consideration is less important, and as we'll see later, DNS in applictions is also becoming more popular.
Finding the Recursive Resolver #
As I said above, typically the recursive resolver is associated
with the network, but how does your machine learn about it?
Back in the old days (the 90s!), when you attached your computer to the network
someone would tell you the IP address to use and the IP addresses
of the recursive resolver. You'd put them in a file called
/etc/resolv.conf, like this:
nameserver 192.168.1.1
Of course, this is not exactly convenient and most people have never done it (though you still can if you want to!). Instead, when you join a network, the network sends your device configuration information, including the IP to use and its recursive resolvers[7].
This means that whoever controls your network controls which DNS server you use. As a practical matter, there are several main cases:
-
If you are connected directly to your ISP network, then it will be the ISP's server. This is especially true on mobile devices.
-
If you are connected to some kind of local network, like a WiFi router, often that will provide its own resolver, which isn't a full recursive but instead connects to the ISP's resolver (this is called a "proxy").
-
If it's a wireless hotspot like at the airport or a coffee shop, they will often run their own resolver.[8]
-
If you are in an enterprise network, the enterprise will often run their own resolver and do some kind of filtering as mentioned above.
It's also possible to use a "public recursive resolver", which is one that is not associated with a given network but just offers DNS service to anyone. There are a number of popular public resolvers, with the best known being:
| Operator | IP Address |
|---|---|
| Cloudflare | 1.1.1.1 |
| 8.8.8.8 | |
| Quad9 | 9.9.9.9 |
The reason for the simple addresses is that they are easy to memorize and therefore to manually configure.

There are a number of reasons to use a public resolver, including:
-
Predictable good performance (these organizations generally do quite a good job).
-
Avoiding filtering. If your network filters DNS, a public resolver can help avoid that. Famously, back in 2014, when Turkey blocked Twitter, Turkish protesters were writing the address of Google Public DNS on walls to help others evade the block.
-
Enabling filtering. Several of the public resolvers offer filtering services, for instance for malware and adult content.
These resolvers are quite popular. As of 2019, about 9% of DNS traffic went through Google public DNS alone.
Security and Privacy #
DNS security and privacy is, to use a technical term, "bad". DNS was designed back in 1987 in an era where there was basically no encryption[9] on the Internet and until recently, not much had changed.
There are two major attack models to consider:
-
Attackers who are "off-path": they can send packets but can't see traffic.
-
Attackers who are "on-path": between you and the recursive resolver or between the recursive resolver and the servers.
Historically, DNS security mostly focused on preventing forged responses by off-path attackers, which it should have been possible to protect against even without cryptography. In practice, however, due to some misfeatures in the protocol combined with some implementation errors (Son and Shmatikov do a good job covering this) DNS has not done always done a fantastic job here, although modern resolvers have a number of defenses against off-path attacks. Without cryptography, it's essentially not possible to protect against on-path attackers, as they can impersonate anyone to anyone else. There are a number of cryptographic approaches designed to protect against on-path attacks, which I'll be covering in a future post.
The good news, such as it is, is that the correctness of DNS responses has an increasingly smaller impact on user security, especially for the Web. The reason for this is that if traffic is encrypted with HTTPS--which something like 80% of Web page loads are, then even if an attacker manages to change DNS to point you to the wrong server, they will not be able to impersonate the right server. That doesn't mean that they won't be able to mount a "denial of service" attack in which they stop you from connecting at all, but that's nowhere near as bad as impersonating your bank.
It's important to note that there is a big difference between ensuring that DNS responses are correct and ensuring that they are private. Much of the work on DNS security (e.g., DNSSEC) is focused on ensuring correctness of the response but doesn't prevent attackers from learning what domains you are resolving, which has obvious privacy implications. Specifically, not only does your resolver get to see where you are going (this can be a problem in and of itself if your ISP has bad privacy practices) but anyone on the same network does as well. Again, this is something where cryptography can help; more on this later too.
Next Up: DNSSEC #
OK, so this was all pretty depressing, but surely now that we have better cryptography, we can do something about it, right? The next post covers the first major standardized attempt to protect DNS, Domain Name System Security Extensions (DNSSEC).
And typically, it's UDP, so one packet out and one packet back. ↩︎
Historically, the client would actually ask for the answer to
example.orgbecause it's possible that the server you are asking would have it and could answer right away but this has the property that you leak your entire query to everyone, and so it's common now to just resolve one label at a time, a practice called QNAME Minimization (QMIN) and specified in RFC 7816. ↩︎There are actually 6 servers responsible for
.org:b2.org.afilias-nst.org,b0.org.afilias-nst.org,a2.org.afilias-nst.info,d0.org.afilias-nst.org,c0.org.afilias-nst.info, anda0.org.afilias-nst.infobut I'm simplifying. ↩︎Confusingly, the thing on the user's computer is called a "stub resolver" and the servers are also called "resolvers". ↩︎
The records have indicators in them indicating their cache validity lifetime ↩︎
The security provided by this mechanism is limited unless you also make the device unreachable from the Internet, e.g., via a firewall. Otherwise, if the attacker can guess the IP address of the device (probably not hard with IPv4) they can attack it. ↩︎
With IPv4 this is likely done with DHCP, with IPv6 either with a Router Advertisement or DHCPv6. ↩︎
Often these will also have some kind of "captive portal" functionality which forces you to log onto the network first. These can be implemented with DNS by pointing any domain to the captive portal server. ↩︎
I often hear this framed as if the people who designed these systems didn't know about security, but that's not really true. It's mostly that due to a combination of missing technological pieces, patents, and resource constraints the kind of widespread encryption we're starting to take for granted was quite difficult to deploy. Recall that the patent on RSA didn't expire until 2000). ↩︎