Why it's hard to trust software, but you mostly have to anyway
Posted by ekr on 28 Dec 2024
[Edited to change the title and subtitle -- 2024-12-28].

My long-time collaborator Richard Barnes[1] used to say that "in security, trust is a four letter word", and yet the dominant experience of using any software-based system—which is, you know, pretty much anything electronic—is trusting the manufacturer. Not only is there no meaningful way to determine what software is running on a given device without trusting the device, even when you download the software yourself, verifying that it's not malicious is extraordinarily difficult in practice and mostly you just end up trusting the vendor anyway. Obviously, most vendors are honest, but what if they're not?
A good motivating case here is secure messaging apps like iMessage, WhatsApp, or Signal. People use these apps because they want to be able to communicate securely and they are willing to trust them with really sensitive information. In fact, a large part of the value proposition of a secure messenger is that not even the vendor can see your communications. For instance, here's what Apple has to say about iMessage and FaceTime.
End-to-end encryption protects your iMessage and FaceTime conversations across all your devices. With watchOS, iOS, and iPadOS, your messages are encrypted on your device so they can’t be accessed without your passcode. iMessage and FaceTime are designed so that there’s no way for Apple to read your messages when they’re in transit between devices. You can choose to automatically delete your messages from your device after 30 days or a year or keep them on your device indefinitely. Messages sent via satellite also use end-to-end encryption to protect your privacy.
This security guarantee critically depends on the app behaving as advertised, which brings us right back to trusting the vendor.
"But what about open source software?" I hear you say. "I'll just review the source code and determine whether it's malicious".

I would make several points in response to this. The first is: "LOL". Any nontrivial program consists of hundreds of thousands to millions of [2024-12-28 -- fixed typo] lines of code, and reviewing any fraction of that in a reasonable period of time is simply impractical. The way you can tell this is that people are constantly finding vulnerabilities in programs, and if it were straightforward to find those vulnerabilities, then we would have found them all. You're certainly not going to review every program you run yourself, at least not in any way that's effective. And that's just the first step: the supply chain from "source code available" to "I actually trust this code" is very long and leaky. Even if you did review the source, most software—even open source software—is actually delivered in binary form (when was the last time you compiled Firefox for yourself?) so what makes you think the binary you're getting was compiled from the source code you reviewed?
Obviously, this is a bad situation if what you're using software to do sensitive stuff—which, again, pretty much everyone is—and there's been quite a bit of work on the general problem of being able to give people more confidence in the software they're running. It's far from a solved problem, so what I'd like to do here is give you a sense of the problem, hard it is, the solution space that's been explored, and how far we are from a real solution.
Checking Software Provenance #
As a warm-up, let's look at the problem of verifying downloaded software (e.g., via your Web browser). This is a much easier problem because we're trusting the publisher not to provide malicious software; we're just trying to ensure that the software we got is what the publisher intended.
The Basic Supply Chain #
For reference, here's an example of a relatively simple software supply chain with just a single code author.
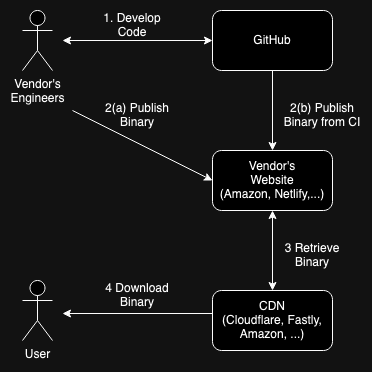
The process starts with the vendors engineers developing the code. Typically this is done on their desktop (or laptop) machines, with the engineers collaborating via some code repository site (usually GitHub. When engineer A makes a change to the code, they publish it on GitHub and then engineers B, C, etc. update their local copy.
When it's time to build a release, a number of things can happen, including:
- Some engineer builds it on their local machine (step 2(a) above)
- The engineers tag the release on GitHub, prompting it to build a release (step 2(b) above).
The release then gets uploaded to the vendor's website, which is probably hosted on some cloud service like Amazon or Netlify. You can also host the binaries on GitHub. In principle, users could just download the binaries directly from your site (or GitHub) but it's common to instead use a content distribution network (CDN) like Cloudflare or Fastly which retrieves a copy of the binary once, caches it, and then gives out copies to each user. CDNs are designed for massive scaling, thus saving both load on your servers and cost.
One thing you should notice right away is how many third parties are involved in this process. Each of these is an opportunity for corruption of the code on its way from the developers to the user.
Code Signing #
The obvious "right thing" approach to software authentication that everyone comes up with is to just digitally sign the package. This provides both integrity (ensuring things weren't changed) and data origin authentication (telling you who the package is from). Moreover, signed objects are self-contained, so, for instance, you can sign your package and then put it up for download on someone else's site (or, in the diagram above, a CDN) and users will still be able to verify it's from you. These is a pretty good sounding set of properties and unsurprisingly, both MacOS and Windows support signed applications.
The basic idea here is that when you install a piece of software you get a dialog like this (on Windows):
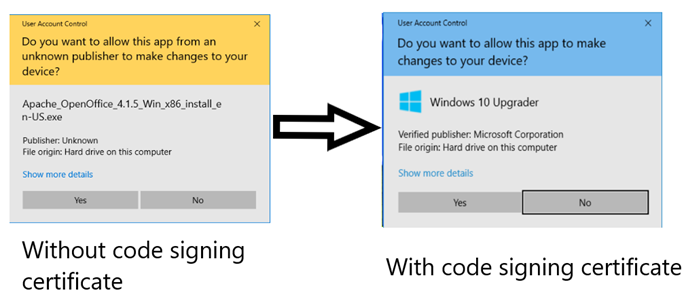
Windows code signing dialog. Image from Sectigo.
Or alternately, maybe you just get warning:
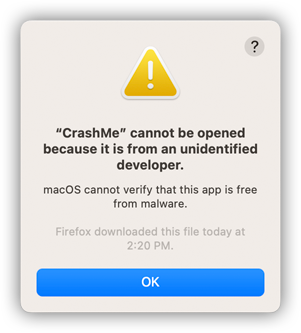
Mac unsigned binary dialog. Image from Dennis Babkin.
Here's what Apple's dialog looks like for a signed binary.
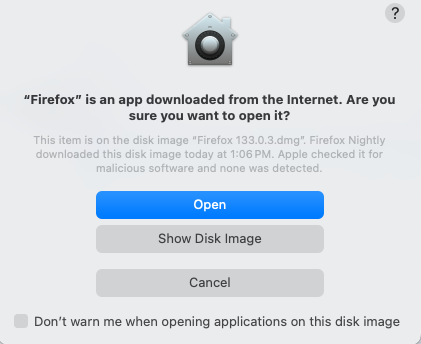
Mac signed binary dialog.
The way that Microsoft's version of code signing (Authenticode) works is the software author gets a code signing certificate issued by a public certificate authority. They then use their private key to sign the binary. Apple's system is similar, except that instead of using a public CA you need to be an Apple registered developer (surprise!). When you download a binary and try to run it the first time, the operating system checks the signature and then pops up the appropriate dialog box, telling you who signed the code, or warning you that it's unsigned, with the exact details depending on the operating system version.[2] Modern versions of MacOS have become increasingly aggressive about not letting you run unsigned code, but as of this writing, it's still possible.
Mobile operating systems are even more locked down, where almost all software is installed from some app store (typically operated by the vendor). Historically, Apple has only let you install apps from the iOS app store, whereas on Android you could install third party apps if you were willing to work a bit. In response to the EU Digital Markets Act, Apple is allowing alternative app installation inside Europe, but even then it's much less convenient, and not available in the US at all. Apps installed through the app store are also signed and the mobile OS automatically verifies the provenance of the app.
The basic problem with code signing systems is that they rely heavily on user diligence, because the OS only verifies that the code was signed but doesn't know who was supposed to sign it. In the simplest case, consider what happens if you are lured to the attacker's web site and persuaded to download an app. As long as the attacker has a code signing certificate—or is an approved Apple developer—then they can send you a malicious binary, which will run fine. In principle users are supposed to check the publisher name—assuming, that is, that the OS even shows a dialog box—but we know from long experience that users don't check this kind of thing. If it becomes well-known that a given publisher is signing malicious binaries, the OS vendor might blocklist the publisher, but this takes time and leaves the vendor constantly chasing bad behavior.[3] Moreover, "well-known" is doing a lot of work here, as it's not exactly unheard of for malicious apps to make it into various app stores.
If you're on a mobile operating system, you'll of course be downloading programs via the app store. The situation is a little better here because the app store operates the directory, and so offers (sort of) unambiguous naming and at least in principle the app store operator can do something about copycat software with confusing names, so it's harder to trick you into installing the wrong package, though of course you're trusting the app store vendor to provide the right package. It's still signed but the device vendor controls the signing key authentication system, so they can can impersonate anyone they want.
Whether you are downloading software directly or via an app store, it's usually necessary to download software over a secure transport even if there is code signing. If you don't download software using secure transport then a network attacker can substitute their own code—signed with their own valid certificate—during the download process; unless you check the publisher's identity, you'll end up running the attacker's code.
Of course, if you have to download software over secure transport anyway, this raises the natural question of why bother to sign the code at all? Why not just have all downloads happen over secure transport? One reason is that is that signing allows for third party hosting. The big technical difference between code signing and transport security is that the signed object is a self-contained package that can be distributed by anyone. This is a big asset in any scenario where the publisher doesn't want to—or isn't allowed to—distribute the software directly.
Blocklisting #
Another reason for signing is to make blocklisting easier. As I mentioned above, if the OS vendor determines that a publisher is misbehaving, they can revoke permissions for that publisher, thus preventing software signed with their certificate from being installed. This is a highly imperfect mechanism for two obvious reasons:
-
An attacker can register as a different publisher and continue to sign as that publisher until they get caught.
-
An attacker can just distribute unsigned software.
Note that you could operate a blocklist where you just listed malicious software—for instance by publishing a hash—but that would be much easier to evade, as the attacker could just change their software until it evaded detection; this is a common problem with antivirus software. If you require software to be signed by some key that chains back to some non-free credential, then this allows you to increase the level of friction to distribute all software, but especially malicious software. If you want to register as a different publisher, you have to establish that identity and then get a certificate, join the developer program, etc. None of this is free, though we're probably talking hundreds of dollars, not thousands,[4] so it makes it somewhat more expensive to distribute malware.
Of course, the attacker could just distribute unsigned software, but then there's some additional friction in the install experience, so you might not manage to infect quite as many victims.
Automatic Updates #
A lot of modern software has some sort of self-updating feature. Unlike the initial install, however, the software updater is written—or at least distributed—by the publisher, who knows precisely who should be signing the update, and so signatures work just fine as a security measure. Conceptually, this is a similar to the trust on first use (TOFU) mechanisms used by SSH: as long as you get the right packager the first time, you're safe in the future because the publisher can directly authenticate the code.
Package managers #
In the open source world, it's common to have a package manager which lets you install software from the command line. For instance:
-
Linux and FreeBSD come with a variety of package managers (apt, dpkg, etc.). On MacOS it's possible to install third party software via Homebrew
-
Many modern programming languages have some kind of package manager, such as npm (JavaScript), Cargo/Crates (Rust), PyPi (Python), etc.
The way these systems typically work is that people publish their packages onto the package manager site and people download the packages from there using some local program provided with the language or the operating system. This obviously makes the distribution site a single point of vulnerability, in at least two ways:
-
The package author's account on the package repository might be compromised (e.g., if they don't use MFA), and the attacker uploads a malicious version. A huge amount of the energy in securing open source supply chains has gone into preventing this kind of attack.
-
The package repository itself is compromised, and the attacker uses their access to upload a malicious package.
Using secure transport to the package repository is standard practice, but it doesn't help against either of these threats because the problem is the data on the package manager itself is compromised. In theory it seems like signatures offer a way out of this: if packages are signed then even if the attacker compromises the repository they won't be able to replace the package with their own.
Unfortunately package signing isn't a complete solution for the same kind of identity reasons as before.
-
Attackers can submit malicious copycat packages to the package repository with similar names to legitimate packages. It's easy to be fooled by this.
-
If the package repository is malicious, then it can point you to the wrong package. When you first decide to use a package, you probably go to the package manager site and do some kind of search (e.g., "give me a package for task
example). If the package manager site is under the control of the attacker, then they can just tell you to install packageexample-attacker(hopefully with a less obvious name) instead of packageexample. The package will be signed, just by the attacker. -
Even if you know the right package name, a malicious package repository can still attack you because you don't know what key should be signing the packages, so once again you have to worry about identity substitution. What's needed here is some way to issue credentials that are tied unambiguously to the package name. One could imagine a number of ways to do this, including (1) having the package manager repo run its own CA or (2) tying package names to domain names the way Java does (e.g.,
com.example.package-nameand using the WebPKI, which already attests to domain names.
As with the case of software updating, however, the problem is easier
once a package has been downloaded, because you could store the
package signing key along with the package (e.g., in the
package.json) file, and then generate an alert if packages
aren't signed with that key (TOFU again).
Better yet, this would also work when other people go to use
your package: if they get your list of keys then all the dependencies
would be protected.[5]
There's been talk for a long time about signing packages, but it doesn't seem to have really gotten off the ground for any of the major package managers. For example, PyPi used to have GPG signatures, but it looks like they didn't work that well for a variety of operational reasons and they were recently removed and replaced with "digital attestations" based on sigstore, but many popular packages are not signed,[6] and as far as I can tell there is as yet no automatic verification. Note that npm supports what's called "registry signatures" using ECDSA, but the signatures are made by the npm registry (package manager) using its keys, so this doesn't protect you against compromise of the package management system. The bottom line is that you mostly need to trust the server that is publishing the packages not to send you malicious packages.
How not to trust the publisher (or at least trust them less) #
Of course, this was all warmup for the real problem we want to solve. Everything up to now was about ensuring that you get the binary that the publisher wanted to send you. This still leaves you trusting the publisher, which you shouldn't, both because it's bad security practice to have to trust people and because there is plenty of evidence of software publisher misbehavior.
There are two main threats to consider from a malicious vendor:
- A broad attack where a malicious binary is distributed to everyone.
- A targeted attack where a malicious binary is only distributed to specific people.
Over the past 10 years or so, the industry hive mind has developed a sort of aspirational three part roadmap for what it would take to actually provide confidence in binaries without trusting the vendor.
- Reviewable source code to allow people to verify program functionality.
- Reproducible builds to verify the compilation process.
- Binary transparency to ensure that people are getting the right binary and that everyone is getting the same binary (thus preventing targeted attack).
The relationship between these is shown in the diagram below.
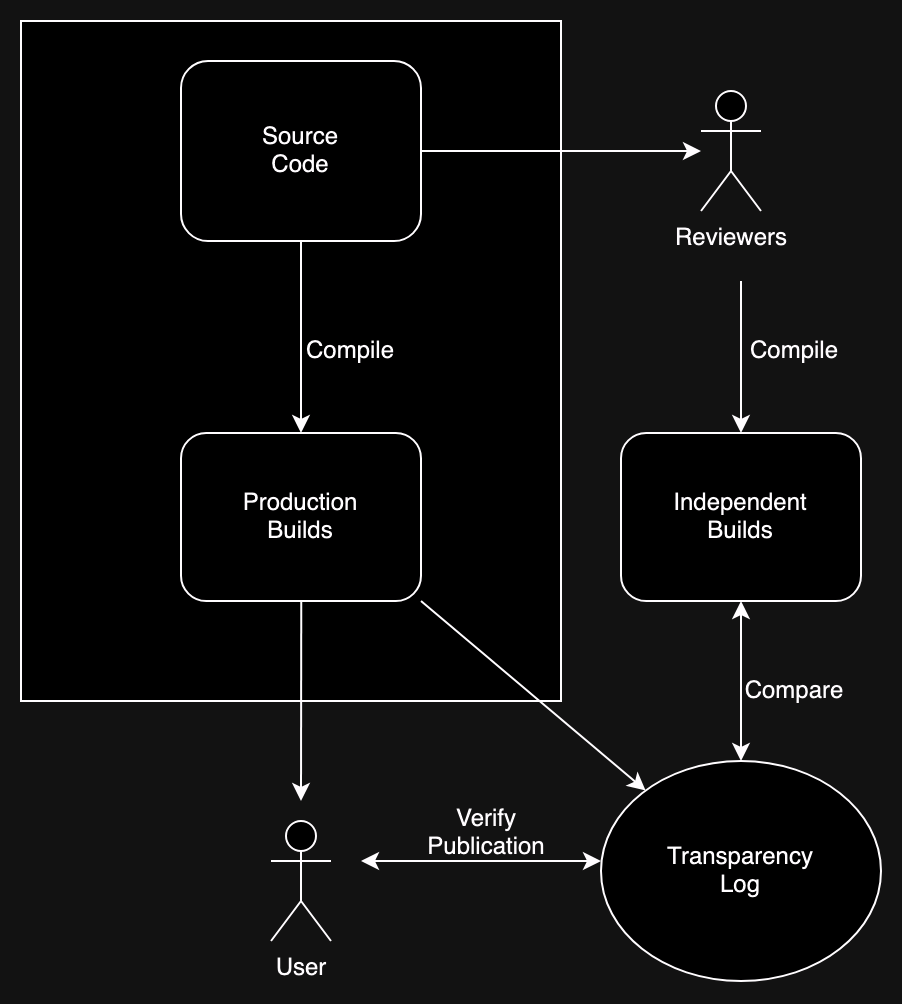
The process starts with the publisher releasing the source code. As a practical matter, some kind of review of the source code is a necessary but not sufficient precondition to being able to have confidence in a piece of software. Reviewing the binary is not really practical on any kind of scalable level; it is of course possible to reverse engineer binaries, but it's incredibly time consuming even for experts. The expectation is that if the software is important enough, then some set of people will scrutinize it, looking for defects. If this process is working correctly, then it should be safe for people to download the (reviewed) source code and compile it themselves.
That's enough in some cases (e.g., if you're building a Web app and you didn't minify or obfuscate the code), but in most cases, people want to download compiled versions even when the software itself is open source. But how do you know that the binary that the vendor is distributing to the user corresponds to the (presumably) safe source code. The general idea is that some set of people (the reviewers again?) build the binary themselves and compare it to the binary that the vendor is distributing. This is actually harder than it sounds for two reasons:
- It's often not the case that you can compile the same source code and get the same binary.
- Even if the reviewers get the same binary as the vendor, how do you know that you got the same binary as both of them?
The first problem is addressed by having what's called "reproducible builds", which is what it sounds like: making it possible for two people to get the same binary from the same source. Once you have reproducible builds, then it should be possible for third parties to check the compilation process.
The second problem is addressed by a technique called binary transparency (BT). BT is like Certificate Transparency (CT) and involves publishing hashes of each binary generated by the vendor. For instance, when Mozilla releases Firefox 140, they would publish hashes for the Mac, Windows, and Linux builds into the BT log. Users and reviewers could then independently verify that their copy of the binary (downloaded in the case of the user, built in the case of the reviewer) were what was in the log, providing assurance that everyone got the same binary.
When you put all of this together, you get what should be end-to-end verifiability for the program's behavior:
- Independent source code review verifies that the source code is non-malicious.
- Reproducible builds allow for comparison between the vendor compiled binary and independently produced binaries from the reviewed source code.
- Binary transparency allows users to verify that they got the same binaries that were compiled from the reviewed source code, and that they are the same as everyone else got.
Let's look at each of these in more detail.
First, we publish the source #
Even with access to the source code, it's very difficult to really be sure what a program does and even hard to exclude the possibility that it does something malicious.[7] The basic problem is that software is incredibly complicated and so just getting to the point where you understand approximately what it does is very time consuming.
Moreover, the easiest way to read code—at least for me—is to try to figure out what it's trying to do, which means just reading it. Like reading text, this means that you skip over little details and errors because they interfere with overall comprehension. It's much harder to put yourself in the mode of really studying each piece of the code and making sure you know exactly what it is actually doing rather than what you think it should be trying to do and assuming it does that. However, that's exactly what you need to do when you review a piece of code, because defects so often arise when the programmer wrote something that is superficially sensible but is actually broken on closer inspection. It's a similar task to copy editing, where you have to focus on the details and deliberately suppress your mind's natural tendency to correct any errors and process the big picture. And of course the more code you have to read the harder the job is.
10 lines of code = 10 issues.
— I Am Devloper (@iamdevloper) November 5, 2013
500 lines of code = "looks fine."
Code reviews.
I'm certainly not telling you not to review code, but it's important to recognize its limits. To a first order, every line of code that goes into Chrome and Firefox is reviewed and the reviewers take their jobs seriously, and yet both browsers still ship with plenty of undetected vulnerabilities and even more undetected defects. Humans simply aren't up to being able to the task of finding every defect in a piece of software, especially when it requires reasoning about hundreds of thousands of lines of code all at once; it's not even easy to find defects when you know they're there and and approximately what the misbehavior is, as anyone has had to debug a complicated issue can tell you.
Moreover, everything I've just said is about the setting where the original author and the reviewer are on the same side, with the author trying to write clear, correct code and the reviewer trying to genuinely understand it. The problem is of course much harder if the author is trying to actively deceive the reviewer, which is what we are worried about here. There used to be something called the underhanded C contest where the idea was to write a program which looked normal and behaved normally under most conditions but had a defect that could be triggered with the right input. Some of the programs are quite clever and it's easy to believe you would miss errors during the review phase.
Vulnerabilities vs. Malicious Code #
It's important to recognize that a malicious vendor doesn't need to embed all the functionality that they want into the source code; they just need to introduce a vulnerability that allows them to exploit the software once it's compiled, just as attackers regularly do with unintentional vulnerabilities. This makes it much harder to detect malicious code because you can't just study the functionality to see if there is something fishy, you need to find all the defects.
The problem is especially acute in non-memory safe languages like C and C++ because (1) it is easy to create defects that cause memory vulnerabilities and hard to detect them (2) exploiting those vulnerabilities is a very well understood problem and (3) memory vulnerabilities are generally lead to powerful exploits, up to and including remote code execution, which would allow an attacker to do anything they wanted on your machine. By contrast, in a language like Rust or Python, many defects just cause program failure and you have to work a lot harder to get to remote code execution.
Actually, a malicious vendor doesn't really have to do anything to deliberately introduce defects because, as I keep saying, real software is full of vulnerabilities, which in almost all cases were introduced by accident. All the vendor has to do is not fix some of those defects (assuming they discovered them themselves). Presto, instant malicious software, plus plausible deniability.
You're not really going to do this yourself are you? #
Even if it were in principle possible to verify that a piece of software was free of malicious code and vulnerabilities, it would be at best an incredibly time consuming process. For example, Firefox consists of tens of millions of lines of code. If you were to review one line of code a second, you'd still be looking at something like a year wall clock time just to review that one program. And this assumes that you're expert enough to do that, which almost nobody is. Clearly, this isn't something people are going to do for themselves.
This is a piece of the puzzle that doesn't get talked about that much, but I think that people have some vague that somehow the open source community will self-organize to review the entirety of all open source software in the given enough eyeballs, all bugs are shallow sense, and if something bad was found, it would be reported and fixed, and if really obviously bad, there would be some consequences for the vendor, if only in the form of negative press and people complaining on Hacker News.
I think you should be suspicious of this in at least two ways. First, open source software routinely has quite old vulnerabilities, so clearly whatever we have now is not effectively fulfilling this function. Second, it's not clear to me what such a structure would look like: would someone parcel out the pieces of code for others to look at? Would we have a registry of what had been reviewed? How would you know that reviewers weren't malicious? Who would pay for all this reviewer time? I suppose it's possible we could build some mechanism for the highest profile software, though in practice my experience is that that's precisely the code that everyone just assumes is nonmalicious.[8] In a number of cases vendors have contracted for some published third party audit (e.g., cURL, Homebrew, Mozilla VPN, etc.), and there has been some progress on crowdsourcing review of Rust crates, but I don't think anyone really thinks audits capture every vulnerability so much as providing an overall assessment of code quality, and in my experience auditors don't usually go into the engagement assuming that the vendor is malicious.
Verifying the Build #
OK, so you've convinced yourself that the source code is non-malicious, but in most cases you don't run the source code but rather the compiled binary, and you usually don't compile it yourself but rather download it from the vendor, even for open source software. There are a number of reasons for this, but for starters, compiling even a modestly large package can take a long time, and that's not even to mention installing all the prerequisites (do you even have a compiler installed?). There certainly are systems where people have to install everything from source (Gentoo Linux, I'm looking at you), but it's not exactly the most convenient thing; there's a reason why even systems like Homebrew which start with other people's source code provide binaries.
However, if you're installing the binary, how do you know that the vendor has actually compiled it from the source code you looked at rather than from some other malicious source? The obvious thing to do is to just download the source code and compile it yourself. This is actually a lot harder than it looks because two independent compilations of the same source code often do not produce the same binary. This may be somewhat surprising, as compilation feels like a mechanical process, but there are actually a number of important sources of variation, including:
- You may not have exactly the same toolchain (libraries, compiler,
etc.) as the publisher used.
- If you have two different versions of some dependency and that is included in the final binary, the result will obviously be different.
- The compiler has a lot of discretion in how to compile a given piece of source code, and even different versions of the same compiler might behave differently (e.g., using different optimizations).
- Binaries often include timestamps, which will obviously be different each time you compile.
- Some build chains are inherently non-deterministic. For instance, Firefox builds uses a technique called profile-guided optimization in which you run the program under instrumentation and use the results to inform the optimization process. Because profiling is sensitive to the underlying state of the computer, you can have small instabilities in the results which produce different outcomes.
This isn't to say that it's impossible to have builds be exactly the same each time (this is called reproducible builds, and there is a known set of techniques for making them work) but it's a nontrivial task to make a given build reproducible, and if the publisher hasn't done it for their system—including providing reproduction information—then you're pretty much out of luck. However, if the publisher has enabled reproducible builds, then it should be reasonably practical to independently verify a given binary.
A non-reproducible build #
Back when I was at Mozilla, one thing I worked on was the the NSS security library in Firefox. NSS dated back to the original origins of Firefox back at Netscape and had some unusual and very old feeling formatting choices. The team decided to adopt the Google C style guide, in part because you could use an automated formatter to mass reformat all the code. Naturally we were a little worried about introducing defects, so we decided to compare the output binaries pre- and post-format. NSS compilation was pretty simple and so we expected this to just work, but surprisingly the results didn't match.
After a fair bit of head scratching, one of the engineers discovered
the issue: we had a few locations in the code that used the C __LINE__
preprocessor macro, which is translated to the current line of source code,
and embedded the result in a a string. When we had reformatted the
code, it had changed what line this use of the macro appeared,
leading to a difference.
Binary Transparency #
If the publisher has made builds reproducible, then, then in principle you should be able to compile the code yourself and compare the binary you get to the one on the publisher's Web site, but then why did you bother to download the binary at all? Just as with reviewing the source code, maybe somebody else that you trust could do this and report back if there was a mismatch. This is where binary transparency (BT) comes in.
BT is like Certificate Transparency (CT) but instead of publishing every certificate, the publisher instead publishes a hash of every binary they release. The idea here is that there should be only a small number of canonical binaries for every version (say one for each platform/language combination). When you went to install a piece of software you would verify that it appeared in the BT log and that there weren't an unreasonable number of entries in the log (ideally there would be exactly one for every configuration). This doesn't verify that the binary is non-malicious but just that you're getting the same binary as everyone else.
Our hypothetical auditors would independently build copies of the binary and verify that they matches whatever was in the log. If there was a mismatch, they would (somehow) report the issue and hopefully it would get enough PR that the publisher would be required to explain the issue; if they didn't have an innocuous explanation (e.g., an alternate way of compiling to that binary) then this is evidence that something is wrong. Note that this system relies crucially on some assumptions about the behavior of third parties, namely that:
- Someone is actually doing their own builds and checking the logs.
- Reporting of log mismatches gets enough attention that there will be consequences for the publisher.
This seems like something that will work a lot better for big vendors; if Chrome[9] builds can't be matched to something in the BT log, this is a much bigger issue than some package with 20 users.
Even without open source and reproducible builds, BT still provides some value in that it makes it harder for the vendor to supply individualized malicious builds to a small number of people; if you get a unique build you should perhaps worry that you have been targeted. Of course in this case we're depending even more heavily on the BT logs being audited because the signature of this attack is just an unusual number of versions in the log, and it's not at all uncommon to have a lot of software versions floating around for various reasons (alpha/beta releases, A/B testing, development builds, localization, etc.)
Smuggling Binary Transparency into Certificate Transparency #
When I was at Mozilla, we spent some time trying to
figure out how to deploy Binary Transparency. At the time there weren't any BT
logs at all, so one of us (I think it was either Richard Barnes or I)
came up with the idea of publishing the binary hashes in
the CT log by minting new domain names of the form
<hash>.<firefox-version>.fx-trans.net, getting certificates for that
name, and then using the CT log to provide transparency.
At present we're seeing modest levels of binary transparency. In particular, Google has deployed it for Android firmware and APKs, using Google-provided logs. The sigstore project provides generic tooling for binary signing, reproducible builds, and binary transparency and seems to be getting some uptake. However, we're not seeing the kind of large-scale deployment that we have for certificate transparency, and there don't seem to be any generic logs in wide use like there are with CT. Facebook has also deployed a system called Code Verify to provide a form of binary transparency for Facebook Messenger. See below for more on this.
What's your Trusted Computing Base? #
If you've been paying attention you may have noticed that this all requires a fair amount of computation on the user's computer. After they've downloaded the binary, they need to compute its hash and verify that it's been published in the BT log; obviously you're not going to do this by hand unless you have a lot of time. All of this requires some kind of software on the user's computer, and it needs to be software you trust.
Ideally, of course, we'd have some sort of generic system that
handled all of this, but that's not generically the case on a desktop operating
system, so we're mostly back to the problem at the very
beginning of identifying which software package the user is trying
to download; it's not
just that the binary is somewhere on the BT log; it needs to be
associated with the right name, which is to say firefox and not
firef0x, but the vendor knows
Updaters #
Once you have downloaded the right software, then the publisher can incorporate BT checking into the software updater as it's already custom software so you don't need to worry about having a generic BT log (because there really isn't one). Moreover, this solves the problem of knowing what binary to look for in the BT log, because the vendor knows the name of their own software.
Of course, now we've just shifted the problem from having to trust the software provider to provide you a nonmalicious binary to having to trust the software provider to send you a nonmalicious updater, so things haven't necessarily improved that much. However, it is better in one specific way: it protects you from the publisher starting out nonmalicious and then becoming malicious. That's a real problem, for instance if the attacker takes over a legitimate package or if they decide to attack you personally for some reason.
App Stores #
By contrast, mobile operating systems do have a generic initial software installation mechanism, which is to say the app store. App stores also come with automatic updating, and because the app store operator rather than the publisher is responsible for the update, it's much harder for the publisher to provide target-specific malicious code, though of course they can provide a malicious build to everyone. This provides some guarantee that everyone is getting the same binary even without binary transparency, because the publisher can't supply multiple binaries.
Of course, as noted above, you have to trust the platform vendor who operates the app store not to themselves send you a malicious binary, but in most cases you're trusting them anyway because they provided the operating system, the installer, and any mechanism you have to view the binary. This is obvious on iOS, which is a completely closed system, but even on Android, all of your interactions with the system are intermediated by hardware and firmware provided by the device vendor, so you're reduced to trusting Google and the phone manufacturer anyway. I'm not saying this is good, just that it's the way it is.
Note that it doesn't really help that much if the platform vendor actually did binary transparency, because it's their software that does the checking and you don't have a good way of checking that software. So while I think it's good that Google is trying to prime the pump some with Android binary transparency, I'm skeptical that it provides significant benefit to the user.
On the other hand, if you do trust the platform vendor, then the app store model can provide a significant amount of additional security even in the absence of the app store enforcing strict policies on the binaries, just because the app store insulates you from the publisher. Moreover, if the vendor requires reproducible builds, then any source code review that they do—or if the program is open source, that others do—can be connected to the resulting binary. For example, Firefox add-ons can be submitted in two ways:
- In source code form directly (add-ons are written in JavaScript, so you don't need to compile prior delivery).
- In a pre-packaged form, but with a complete copy of the source code sufficient to build the packaged version (and even then, obfuscation is forbidden).
Mozilla does some source code review, and this system ensures that whatever ships is what was reviewed, though of course you're reliant on the quality of Mozilla's review, which is somewhat variable. If the add-on isn't open source (which isn't required by Mozilla's policies) this is all you get, but if it is open source (or just delivered as source), then anyone can in principle do this kind of review for themselves.
The Web #
We're well over 7000 words already, but I do just want to briefly touch on the topic of the Web. The Web has a number of properties that do make the problem somewhat easier:
- Web programs execute in the browser, which serves as the trusted computing base.
- There's a clear way to identify the "program" the user is trying to run, which is to say the origin.
- Web applications are (mostly) not compiled but rather HTML and JavaScript, which are (again mostly) readable, which might make the problem of reproducibility easier.
However, it also has several important properties that make the problem much harder:
- The Web application is individually downloaded directly from the publisher by each user, often after they have been authenticated, making it very easy to mount a targeted attack.
- It's very common to send each user a slightly different Web page, for instance if there is personalized content, which makes the question of whether it's the same program very difficult.
- Authors of Web applications often change the application very frequently, either deploying as soon as changes are made ("continuous deployment") or for experimentation purposes (A/B testing), which means there are a lot of different versions floating around even without personalization.
- Web pages often consist of a lot of pieces of JavaScript from various servers (e.g., all the ads that are displayed on the page). This JavaScript is part of the application and so has to be validated somehow, but in many cases it's not even meaningfully under the control of the Web site.
Probably the most serious attempt to provide binary transparency for Web applications, is Facebook's Code Verify) system, provided in collaboration with Cloudflare. Code Verify works by the user installing a browser extension which checks that code running on WhatsApp, Facebook, Instagram, and Messenger matches the source of truth known to Cloudflare. This is a good start but it's also fairly far away from being globally usable.
The Bigger Picture #
As should be clear at this point, the situation is fairly dire: if you're running software written by someone else—which basically everyone is—you have to trust a number of different actors. We do have some technologies which have the potential to reduce the amount you have to trust them, but we don't really have any plausible venue to reduce things down to the level where there aren't a number of single points of trust.[10] This doesn't mean we should succumb to security nihilism: there's still plenty of room for improvement and we know how to make some of those improvements. However, this isn't a problem that's going to get solved any time soon. Open source, audits, reproducible builds, and binary transparency are all good, but they don't eliminate the need to trust whoever is providing your software and you should be suspicious of anyone telling you otherwise.
Apparently on Windows if the binary is signed with an Extended Validation certificate, then you don't get a dialog at all, and the binary just runs. ↩︎
I should also mention that requiring code signing allows the platform vendor to centrally control who is allowed to write programs for their platform and what those programs are allowed to do. This kind of control can be used in ways that protect users from malware or just software that has user-hostile behaviors but can also be used to restrict user choice. How big a deal this is depends on how hard the platform makes it to run unsigned programs. iOS is a good comparison point here, where Apple requires that (1) all software be installed from the app store and that (2) that software comply with Apple's rules, with the result being that you just can't run any software at all that Apple doesn't approve of, whether that's pornography, encouraging smoking, or just using a browser engine other than WebKit (except in Europe where you sort of can as long as you jump through a lot of hoops). ↩︎
For instance, a GlobalSign code signing certificate is $289/yr, though you have to establish your company first. ↩︎
Many systems allow you to distribute a package "lock" file that contains both the versions and a hash of the package, thus guaranteeing that any dependencies will be exactly what the original programmer expected. This obviously has some side effects, and practice around use of lock files varies. ↩︎
For instance, pandas, numpy, pytorch, requests. It's a little hard to get hard numbers here, but PyPi says that they are hosting almost 600,000 packages and the Trailofbits announcement of signatures from November 2024 says that just under 20,000 packages use the "trusted publishing" workflow, which seems to be the main workflow for signing. ↩︎
Just to get this out of the way, if you've taken automata theory, you know that it's not possible to mechanically determine the behavior of every program, even for trivial properties like does it run forever, but most of those situations arise with specially contrived programs. I'm talking here about perfectly ordinary programs which you could figure out if you had enough time. ↩︎
For example, when I was at Mozilla we just imported several hundred thousand lines of WebRTC code from Google as part of its WebRTC implementation, and nobody thought we were going to really review all that code. ↩︎
As an aside, it doesn't appear that Chromium builds are reproducible and Chrome itself has some proprietary components, which makes verifying the whole system problematic. Firefox builds aren't reproducible either, although the Firefox-derived Tor Browser builds are. ↩︎
There's not even a remotely plausible story about not needing to trust anyone, but that's true for mostly everything in life. ↩︎