A hard look at Certificate Transparency: CT in Reality
Everybody has a plan until they get punched in the face
Posted by ekr on 25 Dec 2023
This is part II in my series about Certificate Transparency (CT) and transparency systems. In part I, we looked at how to build a simple transparency system that guaranteed that each certificate was published and that each participant in the system has the same view of the list of certificates. This prevents covert misissuance of certificates and makes it possible—at least in principle—to detect when misissuance has occurred. In this post, I want to look at CT as it is actually deployed on the Internet.

[Update: 2023-12-25. After I posted this, I had a long discussion with Chrome's Emily Stark and Ryan Hurst (formerly Google Core Security and Google Cloud) on X/Twitter. I've made some revisions below in light of that discussion. Big thanks to Emily and Ryan for the critique and detailed discussion.]
Deployment Compromises #
In the previous post, we designed a greenfield system without worrying too much about deployment. Unfortunately for CT, the WebPKI was already well established—with all its faults—by the time CT was developed. You run into a number of challenges when you go to retrofit it to the existing WebPKI, starting with the fact that it was a lot of work for CAs and didn't bring them any value. Importantly, deploying CT doesn't make a CA's customers any more secure because the attacker can just try to get a certificate for those customers from another CA. What it mostly does it make it harder for your CA to misbehave, but that's not really a selling point, and after all, mistakes are something that happen to other people!
Google's plan for overcoming these deployment hurdles came in two parts:
- (Eventually) Require CAs to use CT in order to be trusted by Chrome, thus forcing universal deployment of CT.
- Make a bunch of technical compromises designed to make CT easier for CAs to deploy.
Obviously, part (1) of this plan kind of involved playing chicken with the CAs. Chrome is by far the most popular browser, but it wouldn't be for long if it didn't work with a lot of Web sites. In order to make requiring CT a credible threat, Google needed to get enough CAs onboard that the number of sites with certificates not published in CT was very small, thus making it possible to break them with making Chrome useless, hence the need for the technical compromises to make it more palatable. The remainder of this section talks about some of those compromises.
Transparency Logs #
Previously I talked about the CA publishing the Merkle tree of certificates, but there's no technical reason the CAs have to do it themselves; the certificates just have to be published somewhere. CT separates the job of running the CA from the job of publishing the certificates by creating the role of a transparency log, which is responsible for building the tree. The CAs don't have to operate a log (though some do) just register their certificates with the log.
This design has several advantages. First, it makes life easier for the CAs, who don't have to run logs. This may not seem like a big deal, but it turns out that running a log is a lot of work for reasons we'll get into below, and indeed very few CAs actually run their own logs today. Instead, some entity with a lot of operational resources and experience (i.e., Google), could run a log that supports multiple CAs, hopefully making it easier for the CAs to deploy.
Second, having a relatively small number of logs improves the scaling properties of the system somewhat: much of the overhead for the clients comes in the form of getting an authentic copy of the signed root (what CT calls a signed tree head (STH)), and if each CA has its own tree, that means one root for each CA. If there's just a small number of logs then you need a correspondingly smaller number of roots. Similarly, in order to ensure that no certificates have been misissued, sites need to have a copy of the database for every CA; it's easier if those databases are all aggregated into a small number of logs than to have to retrieve them independently.
Finally, the log design makes it possible to publish certificates even for CAs which don't participate because the log can just unilaterally ingest those certificates. Consider what happens if most CAs publish their certificates in CT but some don't, but Chrome wants to require CT. They could use the Google crawler to collect certificates for non-cooperating CAs and put them in the log, thus potentially making it easier to require CT. This doesn't help as much as you'd think because you still have the problem of how the client gets the inclusion proof for the certificate, but there are some (not great) options here.
Signed Certificate Timestamps #
The big problem with the design as I described it in part I is that it
inserts a delay in the certificate issuance process:
if you are going to provide the inclusion proof at the time
of certificate issuance, then you need to collect all the
certificates that go into the Merkle tree before you can
issue the certificates to the site. If you publish one
signed tree a day, this means that on average it will take
12 hrs between the certificate request and issuance, which
also means that it takes on average 12 hours and up to a day
at the worst case to bring a site online. This might have
been acceptable if we were starting from scratch, but
certificate issuance times are measured in minutesseconds [Updated 2023-12-25. Per Ryan Hurst]. and so
this would have represented an unacceptable regression,
especially for sites which didn't have a valid certificate
and so would have to wait up to 24 hours to deploy
(not such a big deal the first time, but an absolute
emergency if you had a live site and you let your certificate
expire).
In order to address this issue, Google introduced a new concept, the signed certificate timestamp (SCT). An SCT is a signed promise that the log will add the certificate to their tree soon, even though they haven't yet. The figure below shows the issuance flow with SCTs.
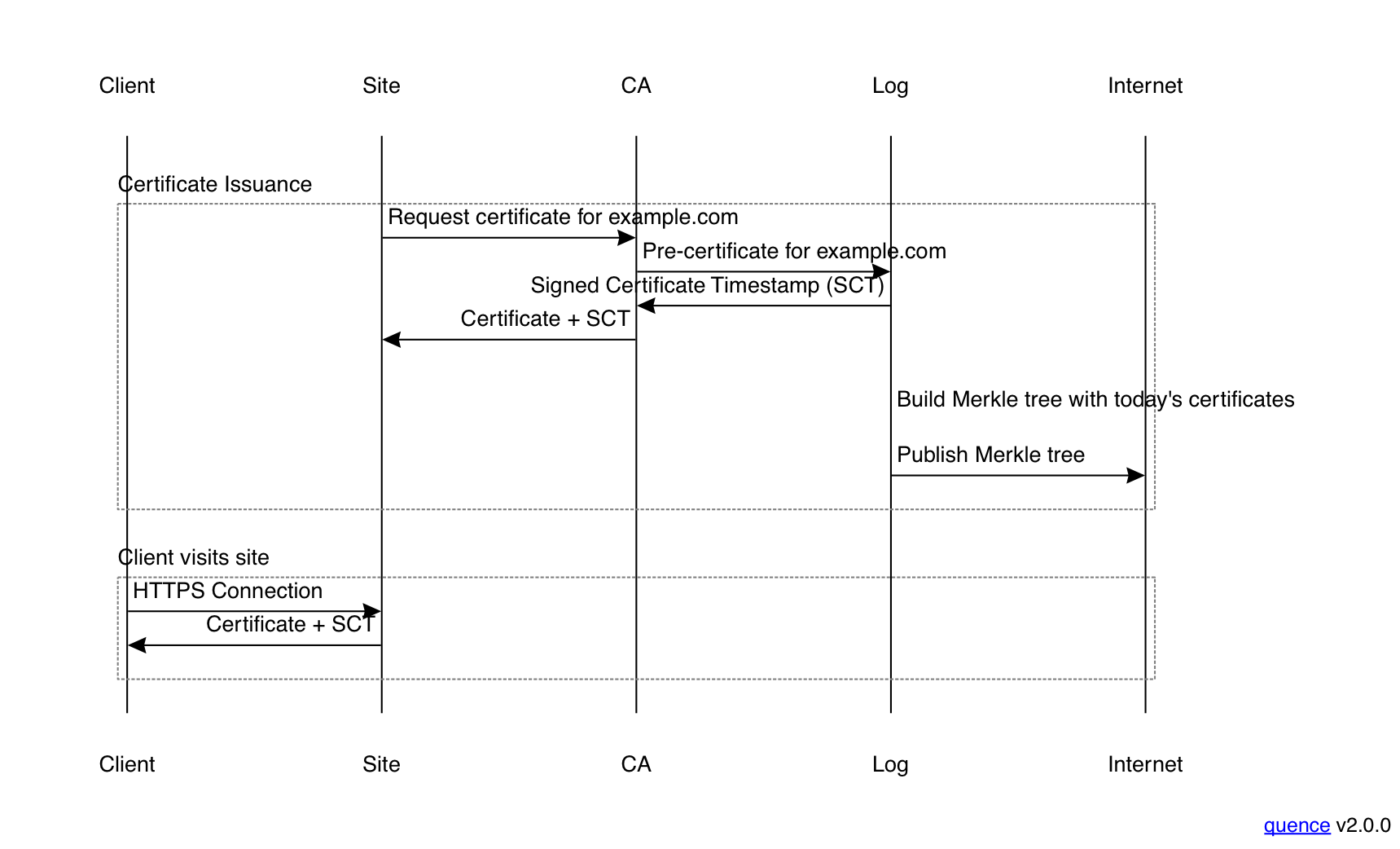
The way this works is that the CA produces what's called a "pre-certificate", which is a data structure that has all the information that would be in a real certificate. It then sends that to the log, which returns an SCT that covers the pre-certificate. The CA then takes the SCT and adds it to the certificate before issuing it to the site. This has the big advantage that the site doesn't need to know about CT; because the SCT is part of the certificate, it can use the certificate as before without changing anything, which is obviously a big deal for incremental deployment. In fact, the CA can deploy CT entirely on its own one day and sites will just automatically have CT-enabled certificates.
Because SCTs can be generated immediately by the log, CAs can deploy CT without significantly slowing down their issuance process; they just retrieve the SCT and it's the log's responsibility to eventually publish the pre-certificate in its own Merkle tree ("eventually" is doing a lot of work here, as we'll see below). The resulting certificate is immediately usable because the client checks for the SCT rather than checking the Merkle tree.
Trust is a bad word #
The good news is that CT with SCTs is minimally disruptive while also allowing the browser to enforce the use of CT. The bad news is that it has totally different and much weaker security properties from the system we started with. The problem is that the SCT is just a promise that the log will incorporate the certificate into their Merkle tree, rather than a proof that it actually did, so you're reduced to trusting the log not to lie.
Recall the security logic of a transparency system, as described in Part I:
-
The CA publishes every certificate (i.e., identity/public key pair) that it issues.
-
The owner of a given identity—and potentially other people—ensures that it recognizes every certificate that was published.
-
Relying parties check that a certificate is in the log before accepting it.
The use of SCTs breaks part (3) of this
system, because the client is just checking that the log promised
to incorporate the certificate, rather than that it actually did.
Consider what happens if you have a malicious CA that colludes
with a malicious log. The CA would misissue a certificate for
example.com, along with an SCT from the malicious log,
but the log would omit the certificate
from its published tree. The client will accept the certificate because
it has the SCT, but because the log never publishes the certificate,
example.com has no opportunity to detect the misissuance.
What's happened here is that we've taken a system which was publicly verifiable and turned it into a system in which we have to trust the logs not to cheat by issuing SCTs for certificates they don't actually publish, potentially with some double checking, as described below [Updated 2023-12-25]. This is still better than where we started because a successful attack requires that both the log and the CA be malicious, but it's a much weaker set of properties from not having to trust the log at all.
This design also means that not anyone can run a log but instead logs have to be vetted to be trustworthy and to conform to browser policy. This trust decision has to be encoded into the browser which decides whether to accept a given SCT. At present, Chrome accepts logs from only six operators:
- Google itself
- Cloudflare
- DigiCert
- Sectigo
- Let's Encrypt
- TrustAsia
When Google originally launched the CT requirement in Chrome, they actually required that at least one of the logs be Google's log, which meant that the policy effectively came down to "we (Chrome) trust Google's log not to lie", but had some obvious problems from an openness perspective, as it meant that realistically CAs had to use Google's log. They have since changed the policy and now you can use any two accepted logs (for certificates valid for 180 days or less) or three logs (for certificates valid for more than 180 days). This means that in order to covertly misissue you need a malicious CA and two malicious logs to collude.
Update: 2023-12-25: Ryan Hurst points out argues that the requirement for policy compliance is more about ecosystem health than about the need to trust the logs (assuming I understand him correctly) and that Chrome's auditing allowed them to verify inclusion, and thus to relax their log policy. As noted below, I think this has some force for Chrome, but mainly because it's effectively making Google the guarantor that a certificate has actually been published.
Closing the Loop #
Because the source of the problem is that the client isn't verifying inclusion of the certificate (by checking the inclusion proof) but only that the log says it would include it (by checking the SCT), the obvious fix is to have the client somehow verify that the certificate actually was included. This turns out to be somewhat challenging and there have been a number of attempts, none of which really work.
The first problem is that we will not always be able to enforce inclusion in real time for the same reason that we need SCTs in the first place: the certificate might have just been issued very recently. For these certificates the client has to trust the SCT to establish the connection and at best can check that the certificate was subsequently included by the logs. This is actually worse than it sounds because the CA has complete freedom about what timestamp to put in its certificates, and so—assuming it can collude with two logs—it can always have a misissued certificate appear to be recent. The result is that the attacker will succeed in impersonating the server and at best the client will be able to detect the cheating at some later time when it determines that the certificate was never logged.[1]
Verifying Inclusion #
Even once you are past the time when the certificate should have been logged, verifying that it actually was is tricky. For obvious performance reasons we don't want to have to download the entire database. The inclusion proof is nicely compact, but when the client contacts the log and asks for the inclusion proof, that tells the log which certificate the client is checking and hence which site the client is visiting; together with the client's IP address, this allows the log to track the client's activity. Obviously, this problem is worse if there are only a small number of logs and was even worse when Google had to be one of them.
In order to prevent this form of tracking, we need some way for the client to retrieve the inclusion proof anonymously. There are a number of possible options here (VPNs or proxies) or Private Information Retrieval. As far as I know, no log deploys any kind of PIR—it would probably be quite expensive—and while proxies or VPNs are technically feasible, they're not free to run. There are similar problems with clients reporting certificates which are not included but should have been. I'm not aware of any major browser which verifies certificate inclusion proofs [Update 2023-12-25] by default (Chrome had some ideas about using DNS,[2] but seems to have abandoned them.[3]), though see below.
Distributing Inclusion Proofs #
One way to minimize the privacy risk of retrieving the inclusion proofs is to have the server distribute them to the client. Of course, if you're not willing to wait for the next STH, then you still have to deal with SCTs, but at least after the STH was issued the server could somehow get a copy of the inclusion proof and send that to the client, thus preventing the client from having to retrieve the inclusion proof for older certificates. This seems like a good idea in practice but ran into several problems.
First, it was never really clear how you would distribute the STH to the server, which, after all, already has the certificate. One possibility is to incorporate the STH into a new certificate, which the server would then retrieve a day or two later and thereafter server to the client; this seemed kind of impractical when CT was originally designed, but in the intervening 10 years, automatic certificate issuance has become far more common (specifically, a protocol called ACME, originally developed for Let's Encrypt), and so it wouldn't be that hard to imagine modifying ACME to send an updated certificate. Importantly, this is something that could be deployed incrementally, because clients have to be able to fall back to SCTs anyway. However, it doesn't seem to be something that's happening.
There were also ideas about using what's called OCSP stapling. Because certificates have a long lifespan, they might be revoked while still otherwise valid. The OCSP protocol allows clients to check whether a certificate is still valid, but introduces latency and has its own privacy problems. For a while, there was interest in having servers pre-retrieve OCSP responses (they're signed by the CA) and give them to clients proactively, thus letting them skip the OCSP checks, and it would be straightforward for the CA to put the inclusion proof in the OCSP response. This has similar deployment properties to the new certificate idea, except that it requires servers to actually do OCSP stapling. However, at the end of the day browsers adopted a different set of mechanisms for handling revocation, centered around centrally distributed revocation lists, so OCSP stapling never really took off.
All of these ideas about providing inclusion proofs to the client were made more complicated by ambiguity about which STH the inclusion proof was supposed to apply to. In the system I described in part I, there was a new Merkle tree every day, but the way CT is actually designed is that there is an ever-growing Merkle tree and STHs are issued at whatever intervals are convenient for the log, as long as they aren't too far apart. This means that it's possible for the browser to have an STH for 5 PM but the server to have an inclusion proof for 4 PM. CT has a way of handling this with a mechanism called a "consistency proof" that bridges between these two versions of the tree, but retrieving the consistency proof requires contacting the log, which creates new privacy problems.
This is actually a solvable problem if the logs provide a more predictable mapping from certificates to STHs (a technique called STH discipline which Richard Barnes and I worked on), but by the time this was all worked out, there wasn't that much energy for changes to CT.
Gossip Doesn't Work #
Even if we did have some mechanism for verifying the inclusion proof, we still have the problem of getting consensus on the STHs. The original CT design assumed a flood fill technique (what they called "gossip") like I described in part I, but was frustratingly short on specifics:
All clients should gossip with each other, exchanging STHs at least; this is all that is required to ensure that they all have a consistent view. The exact mechanism for gossip will be described in a separate document, but it is expected there will be a variety.
Needless to say, this is some vigorous handwaving, and actually building a system like this is fairly hard. In particular, there's no obvious way for browser clients to discover and communicate with each other (see my post on ICE to see some of the challenges here), as this isn't something they otherwise normally do.[4] Eventually the IETF did try to produce a document with some ideas, but it was quite complicated and the IETF abandoned it and as far as I know, no browser ever implemented gossip.
Another option to gossip is to have the software vendor just provide the STHs. This arguably is less secure than gossip because the vendor can lie, but as I noted previously, the vendor also controls software updates and the trust anchor list, so browser vendors are reasonably comfortable with designs that require trusting them, at least for now. This is something Richard Barnes and I looked at in concert with STH discipline, but ultimately it wasn't worth it without some way to actually get the inclusion proofs on the servers, which remained largely an unsolved problem. As things stand today, clients don't really do anything to retrieve or double-check STHs.
Update: 2023-12-25 Note that what I'm referring to here is that it's hard for clients to gossip. It's obviously not a problem for services which are verifying each certificate that was issued (monitors) to gossip, as discussed below.
Chrome CT Auditing #
Added 2023-12-25
As Emily Stark pointed out to me on X/Twitter, Chrome actually does some auditing, which I had somehow managed to miss. Specifically, it checks to see if Google is aware of a given SCT. Joe DeBlasio has a summary here:
- No Safe Browsing protections -> no SCT auditing
- Default Safe Browsing protections -> SCT auditing logic selects a small proportion of TLS connections and performs a k-anonymous lookup on an SCT. If that privacy-preserving SCT lookup reveals that the SCT is not known to Google but should be, the client uploads the certificate, SCTs, and hostname to Google (but no other information).
- Enhanced Safe Browsing protections -> SCT auditing logic selects a small proportion of TLS connections and uploads the certificate, SCTs, and hostname to Google (but no other information).
This is an interesting design and gets around some of the problems that I've discussed above.[5] The security properties it provides are:
-
Google can learn which certificates have been issued by other logs and do whatever checks it wants on whether they should have been issued.
-
Google can check that other monitors are seeing the same thing as it does (by gossiping between monitors, as in the previous section), thus allowing them to independently check for misissuance.
-
Under certain assumptions about the attacker's capabilities, Google will eventually learn about any certificate which wasn't logged. What I mean by "certain assumptions" is that (1) the attacker has to use the certificate reasonably often to have a high probability of report and (2) a powerful attacker might be able to impersonate the server to a client and then block the client's subsequent network access to Google so that it can't make the report.
This isn't nothing, but I think it also falls short of public verifiability in several respects. First, it still leaves clients vulnerable to accepting certificates which were never published; it just makes it possible—modulo the caveats in point (3) above—to detect the compromise after the fact. Second, it fundamentally depends on Google acting as the guarantor that certificates were published because they're the ones who run the auditing service.
Overengineering #
As a result of all this, CT has more or less given up on
public verifiability. As soon as you allow for SCTs, clients have no way of ensuring that
certificates have been logged before accepting them, and without
some mechanism for verifying retrospectively that certificates were
logged, there's not even any way for clients to detect that they
accepted an unlogged certificate, and CT just reduces to a system
where the clients trust the logs not to lie about whether they
are going to publish a given certificate.
Updated 2023-12-25, in light of conversation with Emily and Ryan As a result of all this, CT provides fairly limited public verifiability. At the time of acceptance, clients have no way of ensuring that certificates have been logged before accepting them, because the certificate might have just been issued and not yet incorporated into a log. Chrome's CT auditing provides a partial mechanism for retrospectively detecting that unlogged certificate was accepted, but this really depends on trusting Google, because Google has to see a copy of every certificate to make this work.
If we're just trusting the logs, though Why then do we need all the machinery
of Merkle trees? The logs could just take in pre-certificates, issue SCTs,
and publish the certificates on their sites as soon as possible
(effectively immediately). This doesn't provide public verifiability,
of course; instead the logs act as what's called a "countersignature",
in which the signature from the logs isn't attesting that they verified the certificate's
trustworthiness themselves, just that they've seen it.
To a first order, the answer is that what we actually
have is a countersignature scheme and that the Merkle tree machinery
is unnecessary overhead, or, perhaps,
more charitably, futureproofing against some future world where we
solve the engineering problems described above.
The problem is that it's expensive futureproofing, both in terms of protocol complexity and in terms of operational brittleness. A fairly large fraction of the CT RFC is concerned with specifying the Merkle trees, the machinery of Merkle tree proofs, and the like. All of this could just go away if we were to just treat CT as a "countersign + publish" protocol, leaving a dramatically simpler protocol that would be a thin layer on top of HTTP.
Worse yet, CT logs turn out to be hugely operationally complex to run correctly. I haven't personally operated one, but the basic problem seems to be tight timing requirements combined with the immutability of the Merkle tree structure. Recall that an SCT is a promise to include the certificate into the Merkle tree, which has to happen within a finite period of time called the maximum merge delay (MMD) (which Chrome requires to be no more than 24 hours). The reason for this is so that the clients can check that the log fulfilled its promise in the SCT to actually put the certificate in the log. If the log just had to eventually put it in, then whenever the client checked it could just say "not right now", hence the MMD. But this means that if you have any kind of glitch (say a precertificate gets lost in some queue or you have some an outage of more than 24 hours), you're suddenly out of compliance. Running a big production service with no glitches is no easy task and it shouldn't be surprising that we've seen issues.
Some examples: In August, DigiCert's log was retired because they had a bit flip in one of the entries in the tree and just in November, Cloudflare's log had an outage in which they failed to include thousands of certificates within the MMD. Even Google has had outages and at least one resulted in an MMD violation.[6] The difficulty of running a log is a direct result of the requirements introduced by the combination of SCTs and trying to maintain the infrastructure that would support public verifiability, even though public verifiability doesn't exist in practice. Running them would be far simpler if those requirements were relaxed, and, as far as I can tell, it would have no material impact on user security.
Why then, do we have this overengineered design? The history is a little fuzzy, and I wasn't there at the beginning, but my sense is that when CT was originally designed the intention was not to have SCTs and instead to have just Merkle trees and inclusion proofs delivered with certificates (more or less the design I described in Part I). Despite some challenges, this design probably could have been made to work in a greenfield setting, albeit at the cost of high issuance latency, but eventually the designers were forced to add SCTs for deployability reasons. By the time it was clear we would be stuck with SCTs indefinitely, there was a huge amount of inertia behind the Merkle tree design, which was widely deployed and people were reluctant to climb down from it and from the hope of future public verifiability. So, instead we have a system with the complexity of public verifiability with the security of countersignatures.
Despite all this, the CT RFC (both the original 2013 version and the 2021 update) still claims that logs don't need to be trusted:
Certificate transparency aims to mitigate the problem of misissued certificates by providing publicly auditable, append-only, untrusted logs of all issued certificates. The logs are publicly auditable so that it is possible for anyone to verify the correctness of each log and to monitor when new certificates are added to it. The logs do not themselves prevent misissue, but they ensure that interested parties (particularly those named in certificates) can detect such misissuance. Note that this is a general mechanism, but in this document, we only describe its use for public TLS server certificates issued by public certificate authorities (CAs).
I suppose at the time it was written (2013) this could be read as aspirational language in the hope that some way could be found to deal with the issues described above. From the perspective of 2023, however, it looks more like wishful thinking.
CT: Still Useful #
Despite everything I've said above about the limitations of CT verifiability, it's still proven to be exceedingly useful. There is a robust set of logs and quite a few services, and CT has helped detect a number of serious incidents, in several cases leading to CAs being distrusted. [Updated: 2023-12-25]
First, a lot of CA issues are simple mistakes rather than intentional misbehavior that the CA is trying to conceal. Forcing CAs to publish all of their certificates makes this kind of error easier for third parties to detect, which happens with some frequency. This benefit doesn't require browsers to check SCTs at all, just that CAs be required to log certificates. In addition, the requirement to log certificates means that it's possible to construct a database of all the valid certificates, which is a very useful research tool.
Second, CT requirements make it harder to cheat because not only does the CA have to intentionally misbehave, it has to collude with logs to do so. Obviously, finding one or more malicious logs is harder than just having the CA be malicious, especially given the relatively small number of logs, so CT provides a real security benefit even with no public verifiability.
Finally, CT is a really useful tool for gaining visibility into the overall state of the WebPKI ecosystem; because every certificate has to be published, CT makes it much easier to understand the system as a whole.
The Bigger Picture #
What we have here is yet another case of how the Internet is build on "good enough".
It's a commonplace that the WebPKI is a cobbled together mess and at the time that CT was designed, it was even moreso. At roughly the same time CT was published there was a fair amount of interest in replacing the WebPKI with something based on DNSSEC/DANE which looked like it might have a better attack profile, in particular because there weren't a large number of actors able to attest to a given name. In practice, though, DANE deployment for the Web totally stalled, largely because it was basically a forklift upgrade.
By contract, CT is yet another patch on top of the WebPKI, but was incrementally deployable. Imperfect though it is, it has gone a long way towards improving the system, both by making undetected misissuance harder and by making simple misbehavior easier to spot and address. I know there are still people who want to replace the WebPKI with something based on totally different principles, but in 2023, that looks fairly implausible.[7]
Similarly, while CT is overcomplicated, hard to operate, and a lot more than we really needed, it's also what's deployed and people aren't really excited about changing it. In fact, while there was an extensive effort to produce a revision of CT ("Certificate Transparency v2"), eventually everyone just kind of ran out of energy and while it did get published as an RFC, as far as I know nobody implements it. If we were starting from scratch, we'd probably do it differently (see "good enough", supra), but that's not where we are, and it's easier to just stick with what we have.
None of this is to say that transparency and public verifiability aren't good ideas, and now that end-to-end encrypted messaging has become so popular there is increased interest in transparency for those systems. The requirements here are somewhat different and the result is a rather fancier system called "key transparency", which will be the subject of the next post in this series.
This is also the reason why clients requiring that servers provide inclusion proofs for sufficiently old certificates doesn't help. ↩︎
The reasoning here is that your DNS server already knows what sites you are visiting and so if you could also retrieve the STH over DNS, this would provide privacy. ↩︎
This state of knowledge paper by Meiklejohn, DeBlasio, O'Brien, Thompson, Yeo, and Stark provides a good survey of the alternatives and the present situation. ↩︎
Apple's recent deployment of Key Transparency for iMessage does gossip but this is much more natural because iMessage clients already talk to each other. ↩︎
As an aside, this has some undesirable privacy properties, similar to those of Safe Browsing, and worse if the client actually reports a suspicious certificate. ↩︎
See Andrew Ayer's excellent writeup of CT log failures, though Ayers is a bit more sanguine about failures than I am. ↩︎
Benjamin, O'Brien, and Westerban have a proposal to replace the combination of X.509 and CT with something called "Merkle Tree Certificates", but conceptually this is the same trust architecture as the WebPKI. ↩︎