How to hide your IP address
A field guide to VPNs, proxies, and traffic relaying
Posted by ekr on 17 Oct 2022
As I mentioned previously in my posts on private browsing and public WiFi, if you really want to keep your activity on the Internet private, you need some way to protect your IP address (i.e., the address that machines on the Internet use to talk to your computer) and the IP addresses of the servers you are going to. There are a variety of different technologies you can use for this purpose, with somewhat different properties. This post provides a perhaps over-long description of the various options.
The Basics #
As usual, with any security problem, we need to start with the threat model. We are concerned with two primary modes of attack:
- The server learning the user's IP address and using it to identify them or correlate their activity.
- The local network learning which servers the user is going to.
- The server using your apparent geolocation as determined from your IP address to restrict access to certain kinds of content (soccer, BBC, whatever).
Of course, whether you think this last item is actually a form of attack that should be defended against depends on your perspective and maybe how big a Doctor Who fan you are.
The basic technique for defending against threats (1) and (3) is to push the traffic through some kind of anonymizing relay:

As shown in the diagram above, the client connects to the relay and tells it where to connect. It then sends traffic to the relay, which forwards it to the server. The relay replaces the client's IP address with its own, so the server just sees the relay's address. In general, the relay will be serving quite a few clients, so the server will find it hard to distinguish which one is which (k-anonymity).[1] This simple version clearly addresses threat (1), and, if the relay operator lets you select an IP address outside your own geographic region, threat (3). In order to defend against threat (2) you also need to encrypt the traffic to the relay so that an attacker on your network can't see which server you are connecting to and the traffic you are sending to it (see here for more on this form of data leakage). Ideally, you would also encrypt the traffic end-to-end to the server (using TLS or QUIC), but that's just generally good practice, not required for the privacy provided by the relay.
Relaying Options #
This basic design is at the heart of every relaying system, but the details vary in important ways. There are three major axes of variation:
- The network layer at which relaying happens
- The number of hops in the network
- Business model
We cover each of these below.
Network Layer #
The first major point of variation is the layer at which the relaying happens. Understanding this requires a bit of background on how the Internet networking protocols work.
IP #
The most basic protocol on the Internet is what's called, somewhat unsurprisingly, Internet Protocol (IP). IP is what's called a "packet switching" protocol, which means that the basic unit is a self-contained message called a packet. A packet is like a letter in that it has a source address and a destination address. This means that when you send an IP packet on the network, the Internet can automatically route the packet to the destination address by looking at the packet with no other state about either computer. A simplified IP packet looks like this:
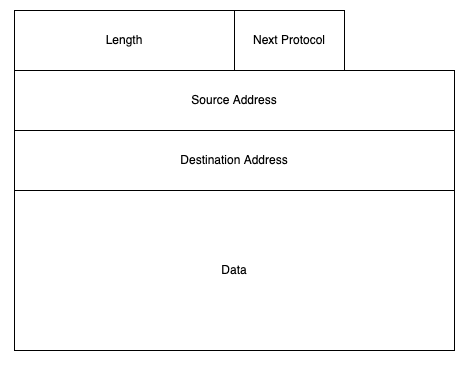
The main thing in the packet is the actually data to be delivered from the source to the destination, also called the payload. The payload is variable length with a maximum typically around 1500 bytes. The packet also has a next protocol field which tells the receiver how to interpret the payload (more on this later) and a length field so that it is possible to tell how long the entire packet is, including the variable length payload.
Using IP is very simple: your computer transmits an IP packet on the wire and the Internet uses the destination address to figure out where to route it. When someone wants to transmit to you, they do the same thing.
TCP #
If all you want to do is send a thousand or so bytes from one machine to the other, a single IP packet might be OK, but in practice this is almost never what you want to do. In particular, it's very common to want to send a stream of data (e.g., a file) which is much longer than 1500 bytes. At a high level, this is done by breaking up the data into a series of smaller chunks and sending each one in a single packet. But of course, life isn't so simple. For instance:
- Packets might be lost, and must be retransmitted so that the receiver gets them.
- Packets might be reordered, and the receiver must know which order to put them in.
- In general, the network will not be able to handle an entire large file at once, so the data must be gradually transmitted over time. The sender must have some way to determine the appropriate sending rate.
The Transmission Control Protocol (TCP) is responsible for taking care of these issues. The details of TCP are far too complicated to fit in this blog post, but at a high level, the data stream is broken up into segments, each of which has a length and a sequence number, which tells you where it goes in the stream. Each segment is sent in an IP packet. When the receiver gets a segment it can look at the sequence number to reconstruct the stream and is able to detect gaps where packets are missing. TCP also includes an acknowledgment mechanism in which the receiver tells the sender which segments it has received; this allows the sender to retransmit packets which were lost as well as to adjust its sending rate appropriately.[2] TCP requires setting up state between the two endpoints; this state is termed a "TCP connection."
There are of course other protocols besides TCP which can run over IP (for instance, UDP, mentioned later). This is why you need the "next protocol" field in IP: to tell the receiver what protocol is in the IP payload.
TLS #
TCP is a very old protocol and like most of the older Internet protocols, it was designed before widespread use of encryption was practical. This is obviously bad news from a security perspective, and eventually people got around to fixing it. The standard solution is to carry the data over Transport Layer Security (TLS). TLS basically provides the abstraction of an encrypted and authenticated stream of data on top of a TCP connection. As with TCP, you need to set up some state to use TLS, and that's called a "TLS connection". I can talk endlessly about TLS but I won't do so here.
UDP and QUIC #
Applications do not implement TCP themselves. Instead it's built into the operating system, specifically in what's called the operating system kernel, i.e., the piece of the OS that's always running and is responsible for managing the computer as a whole. The client application tells the operating system to create a TCP connection to the server, which creates what's called "socket" on the client side. The client writes data to the socket and the kernel automatically packages it up into TCP segments and transmits it to the other side, taking care of retransmission, rate control, etc. The kernel also reads TCP segments from the other side and makes them available to the application to read. Typically, the application implements TLS itself or more likely, uses some existing TLS library.
Why can't you write your own TCP stack? #
Obviously, you can write your own TCP stack (it's just software, after all) but the problem is that you can't install it, because on most operating systems, ordinary applications aren't allowed to write or receive raw IP datagrams. This is one of a number of restrictions on networking behavior that used to be used for security enforcement in a pre-cryptographic era. For instance, at one time it was assumed that if a packet came from a given machine address with a given "port number" (a field in the UDP/TCP header) it came from a privileged process (one that had operating systems privileges). There was even a whole system for remote login based on this where you could be on machine A and execute commands on machine B without authenticating. I know this sounds absurd now, but this was the situation from the early 80s to the late 90s, when we finally got proper cryptographic authentication (at least some of the time.)
This is convenient in that the application doesn't need to carry around its own TCP implementation, but inconvenient in that it's inflexible: suppose the application wants to make some change to TCP to make it more efficient? There's no way to do this without changing the operating system. By contrast, it's easy to change TLS behavior just by shipping a new version of the application. This became particularly salient in the late 2010s when people wanted to make performance enhancements to TCP but were unable to because the operating system didn't move fast enough. The solution was to invent a new protocol that could be implemented entirely in the application: QUIC.
QUIC is sort of like a combination of a fancier version of TCP and the cryptography of TLS (in fact, it uses many pieces of TLS internally). However, because it can be implemented entirely in the application, it can be changed very rapidly. Unfortunately, in most operating systems, applications are not allowed to write IP packets directly, and so QUIC runs over a protocol called the User Datagram Protocol (UDP). UDP is a very simple protocol which just lets applications send single units of data (datagrams) over IP. So, QUIC runs over UDP and UDP runs over IP.
The protocol stack #
It's conventional to talk about this as a "stack" of protocols and visualize it in a picture called a "layer diagram", like so:
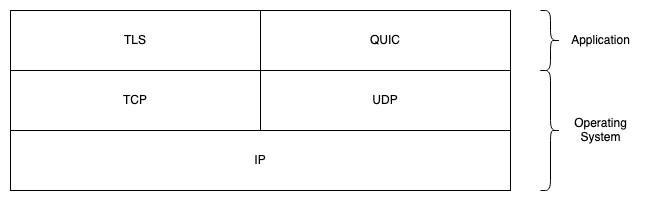
I've also drawn on this diagram which pieces are implemented in the application and which are typically part of the operating system. When the application wants to write data, it starts at the top of the stack and data moves down to the network. As data comes in from the network, it moves up the stack towards the application.
In terms of the way the data appears on the network, each layer adds its own encapsulation, typically either before or after the data. The diagram below shows two examples. The first is data being sent over TCP, in this case the string "Four score and seven years ago". TCP adds its own header with the sequence number, etc. and then passes it to the IP layer, which adds the IP header with the source and destination addresses. The second example is the same data being sent over TLS. The TLS layer encrypts the data (shown by the crosshatching) and adds its own header. It then passes it to TCP, which adds its own header, etc. The receiving process reverses these operations.
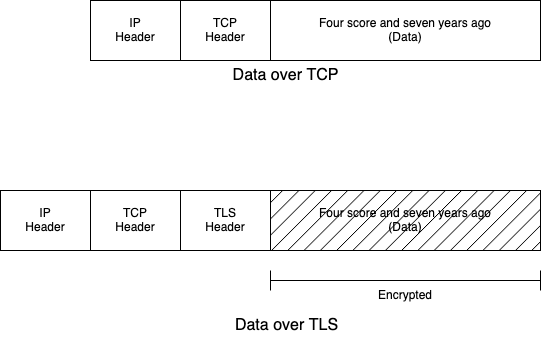
Naming chunks of data #
You'll probably notice that I've been using the terms "packet", "record", etc. These are not interchangeable. One of the most annoying problems in networking is how to name a single unit of data like a packet (sometimes called generically a protocol data unit (PDU)). Each protocol tends to have its own term for this, partly just due to being defined by different people and partly because when you are working at multiple layers of the protocol stack it's a pain to talk about "IP datagrams", "UDP datagrams", etc. Here's my incomplete table of names for PDUs in different protocols:
| Protocol | Name |
|---|---|
| Ethernet | Frame |
| IP | Packet (datagram) |
| UDP | Datagram |
| TCP | Segment |
| TLS | Record |
| QUIC | Packet (but it has things inside it called frames) |
| HTTP | Message |
| RTP | Packet (but they carry media frames) |
| OpenPGP | Packet |
| XMPP | Stanza |
One thing that's important to know is that TCP and TLS provide the abstraction of a stream of data, not a set of records. What this means is that the application just writes data and the TLS stack or the TCP stack coalesces those chunks into one record (packet) or breaks them up at its convenience. The TCP stack might even send the same data twice with two different framings. For instance, suppose that the application writes "Hello" and then the kernel sends it in a single packet. While the packet is in flight, the application writes "Again". If both packets get lost, and the kernel kernel has to retransmit them, it might write them as a single TCP segment ("HelloAgain").
Which Layer #
With this as background, we are ready to talk about one of the big points of diversity: what layer are we relaying the traffic at? There are two main options, at least for relaying encrypted traffic.
- Relay the IP-layer traffic
- Relay the application layer traffic (i.e., the data that would go over UDP or TCP)
I cover both of these below.
Relaying IP Traffic #
Encrypting traffic at the network layer (IP) is one of the obvious ways to address network security issues, as it has the important advantage that once you have set it up, it secures all communications between two endpoints. Work on this goes all the way back to the 1970s, but the IETF started standardizing technology for this purpose in 1992 under the name IPsec. The original idea was actually not so much the kind of relaying system that I discussed above but rather that you would encrypt traffic between the two machines that were communicating with each other. So, for instance, say my client wanted to communicate with your server, we would take the IP packets we wanted to send, encrypt them, and send them directly.
Like the protocols we discussed above, IPsec is an encapsulation protocol, which means that to encrypt an IP packet from A to B we take the entire original packet, encrypt it,[3] and then stuff it in another IP packet, like so:
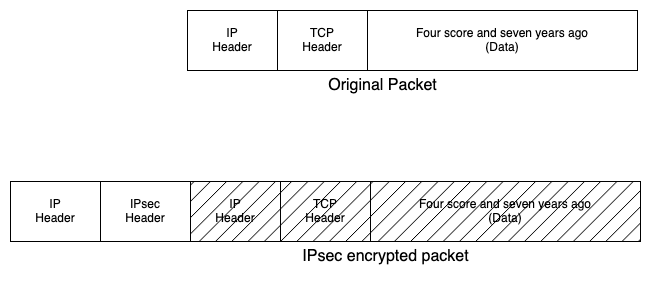
In the scenario I was discussing above, the inner (encrypted) IP header and the outer (plaintext) IP header will have the same addressing information, but it's of course possible to have them have different addressing information, which is useful for creating what's called a Virtual Private Network (VPN). The motivating idea here is that you have two networks (say two offices from the same company) and you want to connect them as if they were in the same location. Inside the office, you trust that the wires haven't been tampered with (this is before WiFi) and so you don't encrypt all your data (I know, this sounds naive now), and so what you really want is just a wire connecting office 1 and office 2. This kind of private connection—what used to be called a "leased line"—is very expensive to buy and what you actually have is an Internet connection which lets you connect to everyone. But if you encrypt the traffic between office 1 and office 2, then you can simulate having your own private wire. Hence virtual private network. The typical topology looks like this:
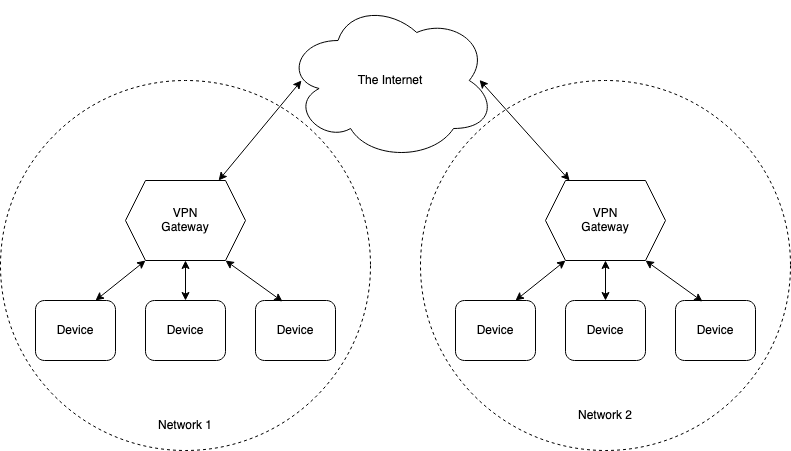
In this scenario, you have two offices, each of which has a "VPN gateway" which detects traffic that is destined from office 1 to office 2 and encrypts it before sending it along. Other traffic, say to Facebook, is left untouched. When the packets are received at the far VPN gateway, it just removes the encapsulation and drops them on the network. The effect is as if there were a single network rather than two networks.
It's also possible to deploy this kind of thing in a simpler scenario where a single user VPNs into their office network, for instance if you are in a hotel working remotely, as shown in the diagram below:
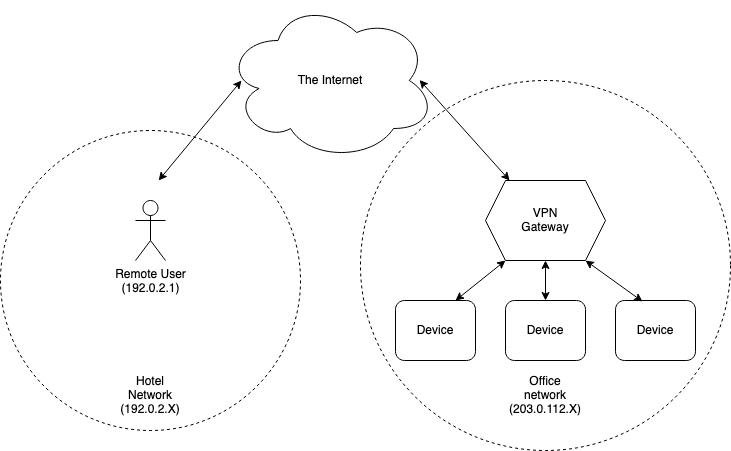
The effect here is that it's like you were in the office, but you're actually not. But this brings up a real problem, which is that the remote user's machine doesn't have the right IP address: it has an IP address associated with the user's home or office (192.0.2.1 in the diagram above) but you want it to appear to be in the office, which means it has to have an office IP address (something starting with 203.0.112).
There are two major ways to make this work. In the first, the VPN gateway tells the user's device what IP address it wants it to have, and then the user's device puts that in the inner IP header, while having the outer IP header having the actual address. For instance, the inner (encrypted) IP header would have 203.0.11.50 and the outer (plaintext) IP header would have 192.0.2.1. The alternative is to have both headers have the user's actual IP address and to have the VPN gateway translate that address into an appropriate local address for the office network (and translate in the other way on the return trip). Note that in both cases, the gateway needs to do some work, in the first case to keep track of what addresses were assigned and to enforce that the client uses the right one, and in the second case to do the translation.
With that background, we can finally get to the problem statement that we started with, namely concealing user behavior. Unsurprisingly you can use the same technology as you use for remote access, with the difference that the VPN gateway is on the Internet directly rather than on some enterprise network, as shown below:

To the server, this just looks like the user is connecting from the VPN gateway, with whatever the IP address of the VPN gateway is. The client's local network just sees a connection to the VPN server, but doesn't know where the data is eventually going.
Here I've focused on IPsec, but it doesn't really matter which encryption layer protocol you use to carry the IP packets: they're just being encapsulated and transported end-to-end. In practice, one sees VPNs deployed with a variety of transport protocols, including DTLS, OpenVPN, WireGuard and QUIC. From the user's perspective, the properties of these protocols are largely the same. Most products that are labeled "VPN" protect traffic at the IP layer using one or more of these protocols.
Relaying Application Layer Traffic #
As mentioned above, the nice thing about protecting traffic at the IP layer is that it protects all the traffic on the system. However, the bad thing is that protecting IP layer traffic requires cooperation from the operating system. This has several undesirable consequences:
- Your code isn't portable between operating systems.
- Many operating systems require some kind of administrator access in order to install or configure something that acts at the IP layer.
- You are often limited to whatever affordances the OS offers you. For instance, you may not easily be able to protect some traffic and not other types of traffic.
These issues can be addressed by relaying at the application layer rather than the IP layer. This can be implemented entirely in the application without touching the operating system; the application just connects to the relay (e.g., over TCP) and sends the traffic to the relay (hopefully encrypted to the server). The relay makes its own transport-level connection to the server and sends the application level traffic to the server, as shown below.
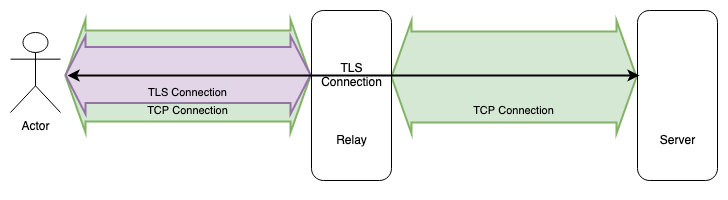
Note that in this diagram there are two TCP connections, one between the client and the relay and one between the relay and the server. The client connects to the relay over TLS and then over top of that creates an end-to-end TLS connection to the server (you could of course not encrypt your data to the server, but don't do that).
One of the big advantages of this design is that it makes it easy to relay some kinds of traffic and not others. As a concrete example, consider Safe Browsing, which leaks information about the user's browsing history to the Safe Browsing server. You might want to proxy Safe Browsing checks (which can be done very cheaply because there isn't much traffic) but not generic browsing traffic (which is much higher volume and hence more expensive). This is easy for the browser to do because it knows which traffic is which but is more difficult for an IP-layer system, which has to somehow distinguish different types of traffic. It's not necessarily impossible but it's significantly more work. For instance, if Safe Browsing uses a separate IP address from the rest of Google, then you could just relay that traffic, but if it shares the same IP address, then you will be encrypting people's search traffic as well.
A number of IP concealment systems relay at the application layer, including Tor, Apple's iCloud Private Relay, and Firefox Private Network. Typically, systems like this are referred to as "proxies". Apple's system is interesting in that it's implemented in the operating system mostly by hooking Apple's higher level networking APIs. Even so, it only works on Safari not other applications.[4]
How many hops? #
Whatever the relaying technology, at the end of the day the relay needs to send traffic to the server, which means it has to know what server you're connecting to. But this creates a new privacy problem: you're connecting to the relay and then telling it which server to connect to. This means that while you've prevented the server from learning your identity, you still have a privacy problem with respect to the relay itself. The relay will have some privacy policy about how it handles this information (ideally, not keeping logs at all), but that's just something you have to trust them on. Even better would be to have some form of a technical protection.
The standard approach to providing technical protection here is to have multiple layers of relaying, as shown in the diagram below:
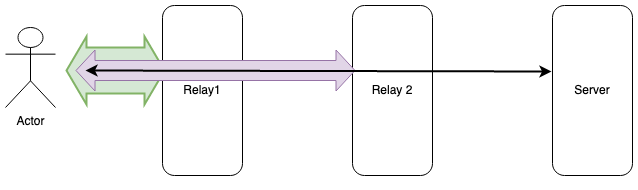
The way this works is that the client connects to Relay 1. It then tells Relay 1 to connect it to Relay 2. As with our single-hop system, that data is sent over the encrypted channel to Relay 1 and is itself encrypted to Relay 2. The client then tells Relay 2 to connect it to the server. The data to the server is thus encrypted three times by the client, in a nested fashion: once to the server, then to Relay 2, and then to Relay 1.[5] Each hop strips off one layer of encryption and passes it to the next hop.
The result is that no single entity (other than the client) gets to see both the user's identity and the identity of the server it's connecting to. Here's what each sees:
| Entity | Knowledge |
|---|---|
| Relay 1 | Client address, Relay 2 address |
| Relay 2 | Relay 1 address, Server address |
| Server | Relay 2 address, Server address |
Note that if the two relays collude, they can together uncover the client's address and the server's address. However, if either is honest, then the client's privacy should be protected, as neither can easily collude with the server to learn this information: relay 2 because it does not know the client's address and relay 1 because (hopefully) the client's connection to relay 2 is one of many connections it has made to relay 2 during this time period. How well this last part works depends on the scale of operation of the system, how long the client leaves the connection up, whether it reuses the connection to relay 2 for connections to multiple servers, etc.
Of course, in order for this to work, the relays need to be operated by different entities. Otherwise there's no meaningful guarantee of non-collusion. This includes not being run on the same cloud service provider (e.g., AWS). Sometimes you'll hear about multi-hop VPNs but if the same company is providing both VPN servers, then this doesn't really help. One nice feature of iCloud Private Relay is that your account is with Apple but they arrange for multiple hops with different providers, so you don't need to worry about the details.
One important limitation of multiple hops is that it can have a negative impact on performance. In general, the routing algorithms that run the Internet try to find a reasonably efficient route between two locations[6] and so you should expect that if instead of routing between point A and point B you route from A to C to B, then this will be somewhat slower (you'll often hear people use the term triangle inequality as shorthand for this). The more hops you do, the more likely it is you will have some kind of performance impact. This isn't a precise effect, but in general, you should expect to have some impact.
iCloud Private Relay is a two hop network, with the first hope being operated by Apple and the second hop being a large provider that Apple has contracted with (mostly Content Delivery Networks (CDN) like Cloudflare or Akamai). Both Apple and these CDNs have fast connectivity and good geographic distribution, which is intended to ensure high performance. Tor uses three hops, a "guard node", a "middle relay" and an "exit node". As discussed below, Tor relays are effectively volunteer services, so performance varies in practice.
Business Model #
Your typical VPN has a simple business model: you pay the VPN provider and then authenticate to them (e.g., with a password) when you connect. This isn't ideal for privacy because they know your name, contact information, and credit card number.[7] On the other hand, as described above, they already know your IP address and which sites you're going to, so it's not clear how much worse this makes things.
With Private Relay, however, this would create a real problem: it's not so bad with the first hop relay because that gets your IP address anyway, but if you authenticate to the second relay with your identity, then you've ruined everything and you might as well be back with a single hop system. In order to address this problem, Apple uses anonymous credentials generated using blind signatures to authenticate to the proxy, as shown below:
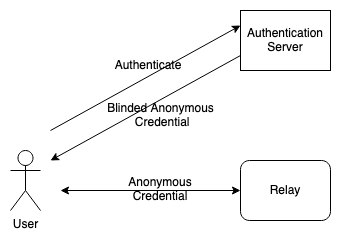
Briefly, the way this works is that the client connects to Apple and authenticates to it using its iCloud account. Apple then issues an anonymous credential that doesn't contain the user's identity. This credential can be provided to the relay to authorize use of the service. In order to prevent Apple from linking up these two activities the credential is blinded (essentially encrypted) when Apple generates it, and then the client unblinds it before sending it to the relay (see here for more detail on how this kind of credential works). This design allows the proxy to know that you are authorized to use the service but not to see who you are.
Tor is different from either of these because it's a free service, operated by members of the community (you can donate to people who run relays). This creates some unpredictable performance consequences because there really isn't much in the way of a Service Level Agreement (SLA). It also makes it somewhat hard to assess the actual privacy guarantees, because some of the Tor nodes might be run by people you don't trust or who are actively malicious. Obviously, with iCloud Private Relay you have to judge for yourself how much you trust Apple and its partners, but at least you have some idea who they are.
Summary and Final Thoughts #
IP addresses are an important and highly effective tracking vector and if you want to browse privately you need to do something to conceal your IP, and this mostly means relaying. Any relaying system will conceal your identity from the server, as long as your provider isn't colluding with the server. Any one hop system necessarily means that you are trusting the provider not to track your behavior and not to collude with the server. Depending on how you feel about your local network and its privacy policies, a single hop system might or might not be an improvement (see Yael Grauer's article in Consumer Reports for more on this). A multi-hop system has a much better privacy story because misbehavior by a single relay is not sufficient to compromise your privacy.
The technical details of how the system works (IP versus application layer, mostly) don't matter that much for privacy but do matter for functionality, with application layer systems being more flexible but providing less complete coverage for other applications on your device. In addition, all of the multi-hop systems that I know are at the application layer, so as a practical matter if you want a multi-hop system you probably will be using an application layer system.
Finally, it's important to know that even the best system provides only limited protection. An attacker who has a complete view of the network can often do enough traffic analysis to determine who is on each end of the traffic. Fortunately, most of us do not need to worry about this powerful an attacker.
Some people run their own relays, in which case they might successfully conceal their identity, but because they will be the only user, they'll be trackable by the IP of that relay. ↩︎
The way this works is that when you are sending too quickly, packets get dropped by the network, so the sender can use the rate of loss as a signal that its sending rate is too high. ↩︎
Yes, I'm ignoring "transport mode", in which you just carry the UDP or TCP datagram. ↩︎
This includes other browsers on iOS even though those browsers are required to use Apple's WebKit engine. As far as I can tell, this is just a policy choice on Apple's side, not any kind of technical limitation. ↩︎
You'll sometimes hear the term "onion routing" applied to this, especially with Tor. ↩︎
This is a hideously complicated topic all on its own. ↩︎
Yes, you could pay with Bitcoin but don't think that's private. ↩︎