First impressions of Bluesky's AT Protocol
More trees than forest
Posted by ekr on 06 Nov 2022
The first generation of Internet communications was dominated by largely decentralized—and barely managed—communications systems like USENET and IRC, built on documented, interoperable protocols. By contrast, the current generation is highly centralized, built on a small number of disconnected siloes like Twitter, Facebook, TikTok, etc. In light of recent events, it should be clear that this is not an optimal state of affairs, if only because what information people have available to them shouldn't depend on which billionaires own Facebook and Twitter.
Over the years there has been a lot of interest in building social networks with a more decentralized architecture, such as Mastodon and Diaspora. These don't have no users, but I think it's fair to say that they haven't really displaced Twitter in the public conversation. A few years ago Twitter's Jack Dorsey announced a project called Bluesky, which was intended to design and build such a system.
Twitter is funding a small independent team of up to five open source architects, engineers, and designers to develop an open and decentralized standard for social media. The goal is for Twitter to ultimately be a client of this standard. 🧵
— jack (@jack) December 11, 2019
Mastodon, ActivityPub, and the Fediverse #
I mention Mastodon here and that's what people seem to be using but technically Mastodon is a piece of software that implements Twitter-like functionality. Unlike Twitter, however, Mastodon can talk to other servers using the W3C ActivityPub protocol, including to servers running different software than Mastodon. The collection of servers that federate (or at least can federate) via ActivityPub is called the Fediverse, but realistically you're likely to be using Mastodon.
While there wasn't any technology at the point Dorsey made this announcement, it got a lot of interest anyway because Twitter using such a standard actually would be a big deal and make it a lot more likely to succeed. A few weeks ago, almost three years later, Bluesky published the initial draft of what they are calling ATProtocol (as in @-sign) or (ATP) which is described as "Social networking technology created by Bluesky". Let's take a look!
Overview #
Unsurprisingly, ATP seems principally designed to emulate Twitter, though presumably you could adapt it to be more like Facebook or Instagram. The basic idea behind ATP is that each user has an account with what's called a personal data server (PDS), which is where they post stuff, read other people's posts, etc. These PDSes communicate with each other ("federate"), with the idea that this provides the experience of a single unified network, as shown below:
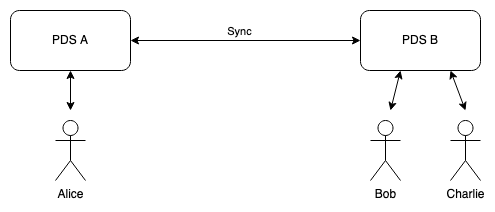
This is basically the obvious design and it's more or less what's been envisioned by previous systems, such as those based on ActivityPub. You can run your own PDS, but it seems more likely that most people will use some pre-existing PDS service, so most PDSes will have a lot of users.
Polling Versus Notifications #
There are two basic designs for the situation where node A is waiting for something to happen on node B:
-
Polling in which A contacts B repeatedly and asks "anything new"
-
Notifications in which A tells B what it is waiting for and B sends it a message when it actually does.
Polling systems aren't very efficient when events are infrequent, because B faces a tradeoff between timeliness and load: if it checks infrequently, then it won't learn about new events until long after they happen. If it checks frequently, then most of those checks are wasted and there is a lot of unnecessary load on both machines. In these cases, notifications are a lot more efficient because messages only need to be sent when something happens. On the other hand, when the time between events is very low compared to the acceptable latency for detecting them, then polling can work reasonably well.
For instance, in order to have an average detection latency of 1 second A needs to poll every 2 seconds (assuming events happen randomly). If events happen about every 100 seconds, then 98% of those checks are wasted. On the other hand, if events happen on average every .1 second, then almost every check will retrieve one or more event, and polling can be efficient.
The way this seems to work in practice is that when Alice wants to post a microblog entry (a "blue"? a "sky"?), she posts it to her own PDS. If Bob is following Alice, his PDS somehow gets it from Alice's PDS. It's not clear to me from the specs whether this is done by having Alice's PDS notify Bob's PDS or by having Bob's PDS poll. You probably want some kind of notification system, especially if there are going to be small PDSes, but the documents don't seem to specify that in enough detail to make it work. Similarly, when Bob decides to like one of Alice's her posts, he notifies his PDS and other PDSs, including Alice's pick that up. It appears that when he wants to follow Alice, he notifies his PDS, which notifies Alice's PDS which (I think) only succeeds if Alice's PDS agrees.
As I said above, this is mostly kind of the natural design, but there are two somewhat less obvious features.
Portable Identity #
In most distributed systems that I've seen, identity is tied
to the server that you use. For example, if you use
Gmail and your address is [email protected], then
you can't just pick up your email account and move it to
Hotmail. With some work you can move the emails themselves
but your address will be [email protected].
The situation is a little more complicated than this
because it's possible to use Gmail to host your
own domain, in which case you could transfer it
to another service, but all the addresses
in the same domain share the same service; you
can't have [email protected] be on
Gmail and [email protected] be on Fastmail.
The existing federated social networking systems I've seen
seem to share this property. For instance, if you
have an account on mastodon.social then your
identity is effectively [email protected];
this allows a user on (say) mastodon.online
to refer to you as https://mastodon.online/@[email protected],
which admittedly looks kind of awkward.
Note that this is hidden a bit by the UI because you can
just refer to people on your own server by unqualified
names. For instance, https://mastodon.online/@example
is shorthand for https://mastodon.online/@[email protected].
ATP allows you to have a persistent identity that is portable between PDSes. It does so by introducing the computer scientist's favorite tool, another layer of indirection. The basic idea is that your identity is used to look up which PDS your data is actually stored on; that way you can move from PDS to PDS without changing your identity. The stated value proposition here is that if a PDS decides to block you then you just move to a different PDS and you can take all of your posts and followers with you.
Account portability is the major reason why we chose to build a separate protocol. We consider portability to be crucial because it protects users from sudden bans, server shutdowns, and policy disagreements. Our solution for portability requires both signed data repositories and DIDs, neither of which are easy to retrofit into ActivityPub. The migration tools for ActivityPub are comparatively limited; they require the original server to provide a redirect and cannot migrate the user's previous data.
In order to make this work, each user's identity is associated with an asymmetric (public/private) key pair which is then used to sign their data (posts, likes, etc.). That way when they move their data from PDS A to PDS B, you can tell it's them by verifying the digital signature over the data.[1] In fact, at some level the PDS is just a convenience, though an important one: if you got their data by any mechanism at all, you could always tell it was correct by verifying the data.
Scaling #
The messaging fan-out of a system like Twitter is quite different from those of other federated messaging systems like instant messaging (and to some extent e-mail). Although there are groups, IM is mostly a person to person activity, with any given message being sent to a relatively small number of people. The situation with e-mail is somewhat more complicated, with most messages sent by individuals going to a small number of people (more below on marketing communications). Tweets, by contrast, tend to be sent to large groups.
As an example, I'm a relatively small-scale Twitter user, but I have over 1000 followers, which means that every time I push the tweet button I'm notifying all of those people. It's not unknown to have over 100 million Twitter followers like Elon Musk or Barack Obama. By contrast, even Gmail workplace users can't send to more than 2000 users in a single message, and only 500 of those can be outside of Gmail. So, the dynamics here are totally different. If you want to send to a large number of people, e.g., for marketing or mailing lists, then you would typically use a specialized e-mail sender like Sendgrid or Mailgun.
This level of fan-out already presents a bit of a challenge for a federated system: if I have 1000 followers on 500 different PDSs, then my PDS needs to contact each of them every time I tweet. This isn't necessarily infeasible, but if I have a million followers spread over 10,000 PDSes, the situation starts to get somewhat worse in terms of scale. We should of course expect that there will be significant concentration in the PDS market, just like with e-mail, with a few large PDSes having most of the users and then a long tail of small PDSes.
In addition to the high level of fan-out, Twitter provides functionality that covers large number of messages. In particular, it's possible to search for messages by content, hashtag, etc., and Twitter promotes "trending" tweets to you. These functions require access to the entire database—at least the public database—of tweets. Obviously, receiving the entire database of (6000+ tweets per second) is prohibitive for a small device, so it won't be possible for every PDS to offer this service.
ATP proposes to address this by having a two-level system, with a second layer of "crawling indexers" who have access to all the data and can offer a personalized view, as shown below:
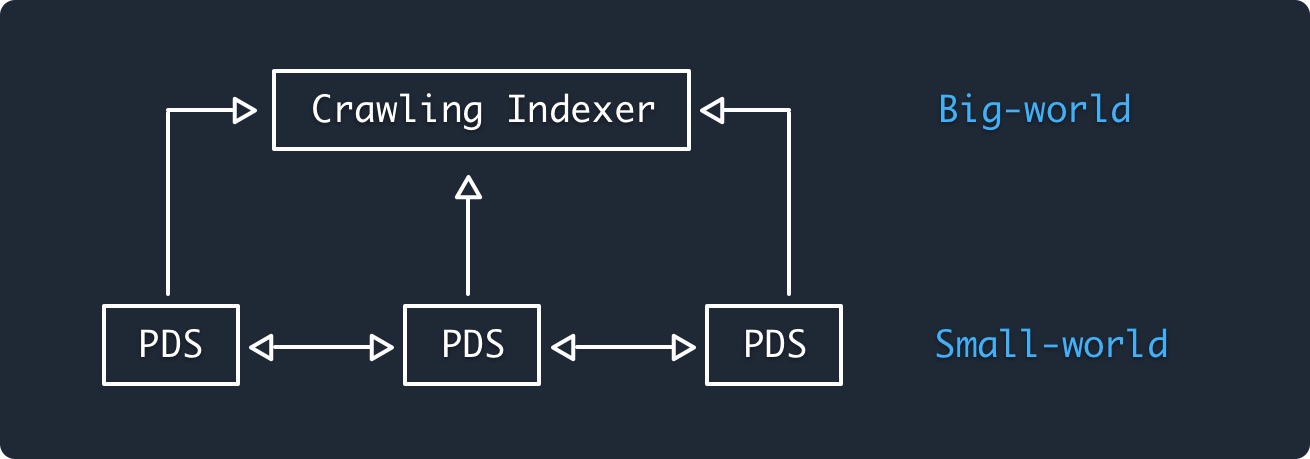 [Source: ATP docs]
[Source: ATP docs]
As above, the documentation is pretty vague on how this is supposed to work. Indeed, the diagram above and somewhere around 100 words in the docs are about all there is, so I can't tell you how it's supposed to work. With that said, the reference to "crawling" is surprising: for efficiency reasons you don't really want this kind of service to act like an ordinary PDS but rather to have special APIs that allow it to get a full feed of what's happening, and even better some directory-type mechanism for identifying all the PDSes in the world, but I don't see anything like this in the API docs (please point me at this if I'm missing it).
A Bit More Detail #
I don't want to get too deep into the details of ATP, but it's worth taking a closer look at a few of the pieces of the system.
Identity System #
As noted above, the way that the handle system works is that you
start with a "handle" that's expressed as a hierarchical name
rooted in the DNS, e.g., @alice.example.com. In a conventional
system like e-mail or Jabber, this would actually be expressed
as [email protected] but because this is supposed to be like
Twitter and Twitter already uses the @-sign to indicate
usernames—e.g., to distinguish them from hashtags—you
have to either have names with two @-signs, like @[email protected] like
Mastodo—or two different separators—or omit the separator between the actual username and the
domain it lives in. To parse these names, you just remove the
first label and treat it as the user name (note that this means
you can't have a . in your user name).
This creates some ambiguity about whether an identifier is a domain
name or a user name (e.g., what's web.example.com). In principle,
if it has an @-sign in front of it, it's a user name, but of course
people aren't consistent about that kind of thing, and the name
is perfectly legible without it. Moreover, because domain names
are hierarchical, it's possible to have a situation where the
same identifier is both a username and a domain name, e.g.,
if there is a user alice on the domain example.com but there
is also a subdomain alice.example.com. This can't happen
with e-mail addresses because the interior @-sign provides a boundary,
but that's not true here. In general, this just doesn't seem like
that great a design choice, though it's not a disaster.
In order to resolve an handle, you do an RPC query to the endpoint associated with the domain name of the handle. This returns a DID. That DID can then resolved to obtain the public key associated with the user. As described above, that key is used to sign the user's data.[2]
ATP supports two flavors of DID—out of the 50+ variants currently specified (this kind of profiling is necessary if you want to have DID interoperability):
-
did:web, which just means that you do an HTTPS fetch to a Web site to retrieve the DID document (i.e., the public key).
-
A new DID form called DID placeholder (did:plc)), which consists of a hash of a public key which can then be used directly or sign new public keys to allow rollover (see my long post for more on this topic). As an aside, it's not clear to me how you actually obtain the DID document associated with a
did:plcDID, as the public key isn't sufficient to retrieve it. There's apparently a PLC server, but is there only one? If not, how do you find the right one? This all seems unclear.
Obviously, the security of the did:web resolution process depends on DNS
security, but even if you use did:plc, the handle resolution process depends on the DNS.
This means that an attacker who controls the DNS or the handle server for
a given DNS name can provide any DID of their
choice, thus bypassing the cryptographic controls that did:plc or any
similar mechanism use to provide verified rollover. Suppose that Alice's
handle is @alice.example.com and this maps to did:plc:1234: because
an attacker doesn't know the private key associated with this DID, they
can't get it to authorize their public key, but if they can gain control
of example.com then they can just remap @alice.example.com to did:plc:5678,
and relying parties won't even get to the rollover checks.
There seems to be some implicit assumption that clients (or other PDSes) will retrieve the DID associated with a handle and then remember it indefinitely, though it's not quite explicitly stated:
The DNS handle is a user-facing identifier — it should be shown in UIs and promoted as a way to find users. Applications resolve handles to DIDs and then use the DID as the stable canonical identifier. The DID can then be securely resolved to a DID document which includes public keys and user services.
I'm not sure how realistic this is: retaining this kind of state is a pain and so it will be natural to treat it as soft state by caching it but not worry to hard if it gets lost because you can always retrieve it. In any case, a basic assumption of a system like this is that new PDSes—and users—will be constantly joining the system, and if the handle domain is compromised they will get the wrong answer, in which case you'll have a network partition in which some users and PDSes have the right key and some have the wrong key.
More generally, it's not clear what the overall model is. Specifically,
is the handle → DID mapping invariant once it's established or
is it expected to change? If the former, then it won't be possible
to transition from did:web to did:plc, or—as the name "placeholder" suggests—to
transition from did:plc to some new DID type, because there will
always be some clients who have permanently stored the old DID
and thus you will never be able to abandon it.
On the other hand, if it's not invariant, then you need some mechanism
to allow clients/PDSes to get updates, such as having a time-to-live
associated with the handle resolution process (potentially based on
HTTP caching). In either case, ATP should either build in some certificate transparency-type
mechanism to protect against compromise of the handle servers or
just admit that the security of ATP identity depends on the DNS,
in which case you don't need something like did:plc and
could presumably skip the DID step entirely and
just store the public key and associated data right on the handle
server. Either way, this is the kind of topic that I would ordinarily
expect to be clearly defined in a specification.
In any case, I don't think that this mechanism completely delivers on the censorship-resistance aspect of portability: it's true that you can move your data from one PDS to another, but because your handle is still tied to some server you're vulnerable to having that server cut you off. Even if some servers have cached your handle mapping, many won't have and so the result will be a partial outage. It's true that it's probably cheaper to run a handle mapping server than a PDS, so you might be able to run that but outsource the PDS piece, but it also seems likely that most people will just run them in the same place, so I'm not sure how much good this does in practice.
RPC Protocol #
At heart, ATP is a fairly conventional HTTP request/response protocol with a schema-based RPC layer on top of it. The idea is that new protocol endpoints are specified by JSON schema which define the messages to be sent and received and can then be compiled down to code which can be called by the user. They docs give the following example of a schema:
{
"lexicon": 1,
"id": "com.example.getProfile",
"type": "query",
"parameters": {
"user": {"type": "string", "required": true}
},
"output": {
"encoding": "application/json",
"schema": {
"type": "object",
"required": ["did", "name"],
"properties": {
"did": {"type": "string"},
"name": {"type": "string"},
"displayName": {"type": "string", "maxLength": 64},
"description": {"type": "string", "maxLength": 256}
}
}
}
}This generates an API which can be used like so:
await client.com.example.getProfile({user: 'bob.com'})
// => {name: 'bob.com', did: 'did:plc:1234', displayName: '...', ...}This is all pretty conventional stuff. I know that there are a lot of opinions in the Web API community over whether it's better to have this kind of RPC-style interface or a REST-style interface in which every resource has its own URL, but I don't think anyone would say it's a make-or-break issue; it's not like you can't make this kind of API work.
I'm more concerned by the fact that the API documentation is so thin. As a concrete example, here's the entire definition of the data structure "feed":
export interface Record {
subject: Subject;
createdAt: string;
}
export interface Subject {
uri: string;
cid: string;
}What do these values mean? We might infer that createdAt is a date, but
maybe not? What are the semantics of Subject.uri? Who knows?
I'll have more to say about this later, but for the moment I would observe that this is a pretty common pattern in systems that were built by writing software and then documenting its interfaces, rather than writing a protocol specification first and then implementing (though of course I don't know if that's what happened here). The result is that the specification just becomes "whatever the software does", and often the documentation is insufficient and you're reduced to reading the source code to reverse engineer the protocol. It's not awesome.
Access Control #
One thing that isn't clear to me is how access control is supposed to work. For instance, if I want to have a post that is only readable by some people how does this work? The situation is not at all clarified by the fact that the section on Authentication consists entirely of the word "TODO". However, ignoring the technical details, it seems like there are two major approaches, neither of which is really optimal.
- A post is separately encrypted to each authorized reader.
- The PDSs enforce access based on who is following a given user.
The first of these is straightforward technically, but operationally clunky as it requires not only knowing the public keys of all of your followers at the time you post, but also being able to go back and retroactively encrypt posts to new followers or when existing followers change their keys.
The alternative is less clunky, but requires a lot of trust in PDSes. To see why, consider the case when Alice is on PDS A and Bob and Charlie are on PDS B. Alice restricts here posts and Bob follows Alice but Charlie does not, so Charlie should not be able to see Alice's posts. However, when Alice posts something, it gets sent to PDS B, which then has to show it only to Bob but not Charlie. The obvious problem here is that Alice (hopefully) trusts her PDS but has no real relationship with PDS B; she just has to trust that it does the right thing (in Twitter, this is trusted by just trusting Twitter). This is basically a generalized version of the problem that Alice has to trust Charlie not to reveal her tweets, but it's obviously quite a bit worse in a system like this where there a lot of PDSes, where we end up with a distributed single point of failure in the form of exposure to vulnerabilities and misbehavior by every Alice where she has a follower.
Actually, the situation is potentially worse than this: what about PDS C which doesn't have any of Alice's followers? What stops it from getting Alice's posts? The documents don't say how this works, but at a high level, I think what has to happen is that PDS A has to verify that each PDS requesting a copy of Alice's posts has at least one user that follows Alice (presumably by working forward from the DIDs on Alice's follower list), which seems kind of clunky.
Thoughts on System Architecture #
When looking at a system like this, I usually try to ignore most of the details and instead ask "what is the overall system architecture"? The idea is to understand at a high level what the various pieces are and how the fit together to try to accomplish various tasks. In RFC 4101 I phrased this as being at the "boxes and arrows" level:
Our experience indicates that it is easiest to grasp protocol models when they are presented in visual form. We recommend a presentation format centered around a few key diagrams, with explanatory text for each. These diagrams should be simple and typically consist of "boxes and arrows" -- boxes representing the major components, arrows representing their relationships, and labels indicating important features.
For instance, it doesn't really matter whether the communications between client and server use RPC, REST, or something else, but what does matter is who talks to who, and when. Given this kind of architectural description, an experienced protocol designer can generally design something that will work, even if two designers wouldn't build exactly the same thing. It's much harder to go the other way, from the detailed description to the architecture. and worse yet, it tends to obscure important questions.
I think that this high level description is what the Overview is trying to provide, but it's really more of an introduction and leaves a lot of big picture questions unclear that would be easier to understand if it were a more complete description of how stuff worked. For instance:
- How does a PDS learn about new activity on another PDS?
- How do the "crawlers" learn about new PDSes and the content in them?
- How does access control work, for instance, if a post is private?
- What are the scaling properties of the system?
- What are the security guarantees around identities and integrity of the data?
- How do you handle various kinds of abuse? For example, suppose that someone sends abusive messages to others: does each PDS (or user!) have to block them separately or is there some kind of centralized reputation system?
As an aside, these questions would all be a lot simpler in a centralized system.
This isn't just a matter of presentation, but also of design.
In my experience, the right way to design a system is to start from
this kind of top-level question and try to build—and document—an architecture
that answers this kind of question and only then design the specific
pieces, in part because the details often
to obscure issues that are visible at higher layers of abstraction
(see, for instance, the discussion of DNS-based names and did:plc above).
However, it also makes it easier for people to understand what
you're talking about rather than forcing them to reverse engineer
the structure of the system from the details, as is the case here.
As noted above, I suspect this is a result of having a single implementation
and then a spec which documents that implementation.
The Even Bigger Picture #
As the ATP authors acknowledge in theor FAQ there already is an existing federated social networking system based on ActivityPub, though in practice mostly centered around Mastodon. Mastodon seems to be having a bit of a moment now in the wake of the chaos surrounding Elon Musk's acquisition of Twitter:
For anyone wondering, Mastodon got over 70K sign-ups yesterday alone. Let's keep the momentum going! The "public square" of the web must not belong to any one person or corporation!
— Mastodon (@joinmastodon) October 30, 2022
Even so, it has a tiny fraction of Twitter's user base.
In general, experience suggests that it's pretty hard to start a competitive social network (Google Plus, I'm looking at you), but not primarily because it's technically hard. There are some real challenges in building a federated network, but building a non-federated system like Twitter is conceptually pretty easy, though of course operating at Twitter's scale is challenging. Rather, the issue is that because social networks are network effect products (it's right there in the name) and so the initial value of the network when it has few users is very low. This is especially true with something like Twitter where so much of the value is in the feed of new content, as opposed to YouTube (or arguably TikTok), where someone can send you a link and you can just watch that one video.
Far more than any of the technical details, what made Bluesky interesting when compared to (say) Mastodon was that it was designed under the auspices of Twitter with the stated objective of being used by Twitter. If Twitter actually adopted ATP, then suddenly ATP would have a huge number of users, getting you past the entry barrier that other new social networks have to surmount. However, I was always pretty skeptical that this was going to happen, for two reasons.
First, Twitter, like most other free services, makes money by selling ads. If there were some way easy way to stand up a service which interoperated with Twitter, including seeing everyone's tweets, but without showing Twitter's ads, that seems pretty straightforwardly bad for Twitter, which would then have to compete on user experience rather than on its user base moat.
Second, Twitter didn't need a fancy new protocol to allow for service interoperability; they could have just implemented ActivityPub. I recognize that there were technical objectives that ActivityPub didn't meet, but something is better than nothing and they could have used the time to develop something more to their liking and gradually migrated over. Obviously, this isn't ideal from an engineering perspective, but if what you wanted to do was get rid of Twitter's monopoly, then it would get you a lot further than taking three years to develop something new; when put together with Twitter's lack of an explicit commitment to use the Bluesky work this suggests that actually making Twitter interoperate was not a priority, even with the old Twitter management.
Of course, now Elon Musk owns Twitter, so whatever Jack Dorsey's intentions were seems a lot less relevant, and we'll just have to wait and see what, if anything Musk decides to do. Perhaps it will involve a blockchain.
Actually over a Merkle Search Tree over the data, but the details don't much matter here. ↩︎
The documentation gestures at using the DID for "end-to-end encryption", but doesn't specify how that would happen. Building a system like this in practice is fairly complicated, so more work would be neeeded here. ↩︎