A hard look at Certificate Transparency, Part I: Transparency Systems
Everyone loves Merkle trees
Posted by ekr on 13 Dec 2023
Identifying the communicating endpoints is a key requirement for nearly every security protocol. You can have the best crypto in the world, but if you aren't able to authenticate your peer, then you are vulnerable to impersonation attacks. If the peers have communicated before, it is sometimes possible to authenticate directly, but this doesn't work in many common situations, such as when you are given the address of a Web site and need to connect to it securely.
Nearly every major communications security protocol has the same basic authentication design:
- Endpoints have human-readable identities (e.g., domain names, e-mail addresses, phone numbers, etc.)
- A trusted authentication service attests to the binding between an identity and the endpoint's public key.
- The endpoint uses its private key to prove it identity.
For example, in the HTTPS/Web context, sites are authenticated by having certificates which are issued by a certificate authority (CA).[1] These CAs are in turn vetted by browser vendors, who decide which CAs their browsers will trust. This entire system is called the "WebPKI" (see here for more background on this.)
The key word in this system is trust: the endpoints need to trust that the authentication service doesn't falsely attest to a binding for the wrong person (technical term: "misissuing"). If an authentication service makes a mistake or deliberately cheats, then this could allow the attacker to impersonate a valid user of the system, which is obviously bad. This is not merely a hypothetical issue. In the WebPKI alone, there have been a series of high profile certificate authority failures, perhaps most famously in 2011 when the Dutch CA DigiNotar was subverted and issued a series of bogus certificates, including one for Google. The bottom line is that an authentication service of this type represents a single point of failure for the system as a whole. The WebPKI is especially bad here because there are a large number of CAs, nearly all of which can attest to any domain name, so there are multiple entities, each of which is a single point of failure.
There are a number of potential approaches for defending against this problem but the one that the community seems to have settled on is what's called a transparency system. The basic concept of such a system is that you retain the idea of a trusted authentication service but add on a layer in which it publishes the bindings it is attesting to so that anyone can check that it's not misissuing. The first transparency system, and still the most widely deployed, is Certificate Transparency (CT), designed by Ben Laurie, Adam Langley, and Emilia Kasper (all at Google at the time) in the wake of the DigiNotar incident. CT was designed to bring transparency to the famously mismanaged WebPKI. More recently, there has also been a lot of interest in CT-like (but fancier) systems for non-WebPKI applications, such as "key transparency" for messaging systems, but in this post I want to focus on CT.
As you can see from the diagram below, CT is a very complicated system, in part because it had to be retrofitted onto the existing WebPKI design and in part due to some technical decisions which in retrospect look like they were mistakes (I'll get into those in the next post in the series).
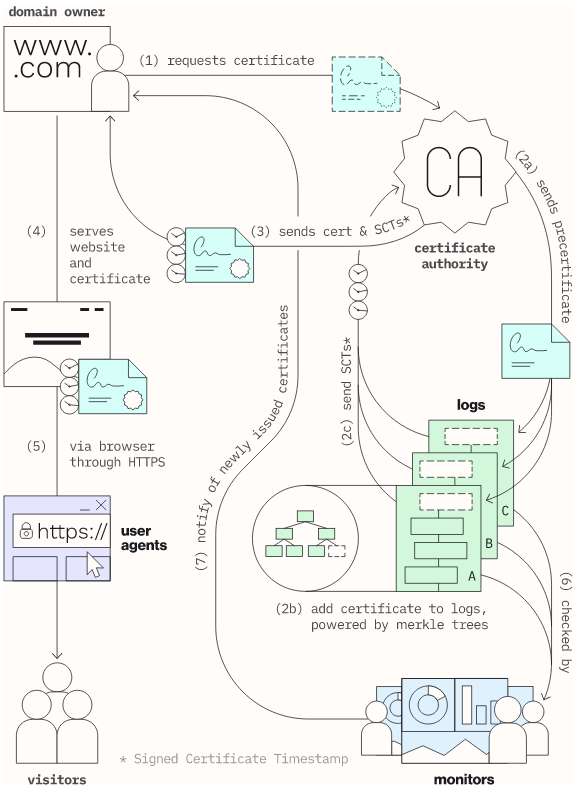
[Overview of Certificate Transparency from transparency.dev]
What I want to do in the rest of this post is to try to gradually build up to a sort of idealized version of CT from first principles. In a future post, I'll look at actually existing CT, some of the compromises that it made in the name of deployment, and the implications of those compromises.
Transparency Systems #
The basic idea behind a transparency system is not to prevent misissuance but to detect it. At a high level, this works as follows:
-
The CA publishes every certificate that it issues.
-
The owner of a given identity—and potentially other people—ensures that it recognizes every certificate that was published.
-
Relying parties check that a certificate is in the log before accepting it.
The figure below provides an overview of the verification pieces of this process in the Web context:
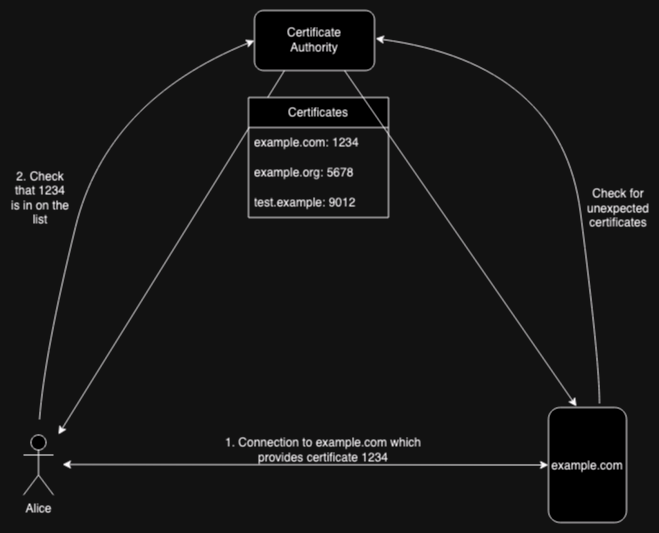
At some point, example.com gets a certificate (1234) from the
CA, which publishes that certificate. Then, when Alice wants to connect to example.com,
it presents that certificate (step 1). Alice then checks with the
published certificate list to verify that the certificate is
actually on the list (step 2). Separately, example.com periodically
checks the list to be sure that only certificates it knows
about are on the list.
There are a lot of moving pieces, so it's worthwhile working through the logic here for why this works.
Is it possible to prevent misissuance? #
While detecting misissuance is good, it would be better to prevent
it entirely. Unfortunately, this turns out to be a very challenging
problem because the authentication service has to determine who
owns a given name (e.g., example.com), and that determination
isn't directly verifiable by third parties. There are designs
which bind name issuance to authentication (often using some
kind of blockchain), but the problem with these systems is
that they don't allow for any discretion on the part of the
authentication service, so, for instance, if I register
example.com and then lose my keys I still want to be able
to reclaim it. This may require some kind of
manual intervention. More on this here.
If you're going to allow for discretion to handle this kind of
case, then you need to worry about that discretion being
abused.
Misissuance Detection #
Because every issued certificate is published, if the CA misissues a certificate, then it will also be published and can then be detected, either by the true owner of the identity or by a third party who notices something fishy (why is some CA I've never heard of issuing a certificate for Google?).
In the Web context, this is all somewhat harder than it sounds: if you're a big and well-operated site, then you may well know every certificate that you have requested, but that's not necessarily true for smaller sites.[2] Similarly, third party verifiers won't necessarily be able to check that the issued certificates are what is expected. The result is that while you should expect that misissuance of high profile sites will likely be detected, misissuance of smaller sites could easily go unnoticed.
Managing Misissuance #
OK, so you've detected a certificate that was misissued, now what? The general story is that you report it. What happens then depends on how the certificate was misissued. In the simple case of unintentional misissuance—which definitely happens—you would expect the CA to revoke the certificate, investigate what happened, and if possible address whatever issue lead to the misissuance.[3]
However, it's also possible that the CA is not well operated or the misissuance is more than a simple mistake. In this case, browsers might decide to distrust the CA, with the effect that all certificates issued by the CA. This is a disruptive step, but it does happen, even to large CAs. For instance, in response to a series of operational issues the browsers distrusted Symantec (very gradually) between 2016 and 2018.[4]
Much of the value of a transparency system like this is that works together with the threat of distrust as an incentive to good behavior. As noted above, it's possible for misissuance for the names of small sites to go undetected, but once there is some evidence of some misbehavior—perhaps of a single site—the transparency system allows for easier investigation of the other certificates issued by the CA. It is also possible to use the transparency system to detect other kinds of CA misbehavior than misissuance which can then prompt further investigation.
Incompetence versus Malice #
If all we are worried about is mistakes by the authentication service, then just publishing all the certificates is mostly enough; even if the CA inadvertently issues a certificate to the wrong person, it will still be published and so the mistake can potentially be detected. But what if the CA is intentionally misissuing? In this case, it can just provide the certificate to the attacker without publishing it, in which case the fraud isn't readily detectable.
This is the reason for requiring the relying parties (clients) to enforce that the certificate has been published (point 3 above). This prevents attacks where the AS doesn't publish the certificate because the relying parties just won't accept it, making the attack pointless. If relying parties don't check for the presence of the certificate on the published list then nothing requires the CA to publish every certificate.
Partitioned Views #
The description above just covers the logic of a transparency system but doesn't tell you how one actually works and in fact I've glossed over an important technical problem, which is how to ensure that the published list of certificates is the same for everyone. The obvious thing to to do is for the AS to just publish the list of certificates it has issued on its Web site, but this isn't secure. Consider what happens if the AS gives different answers to different people, like so:
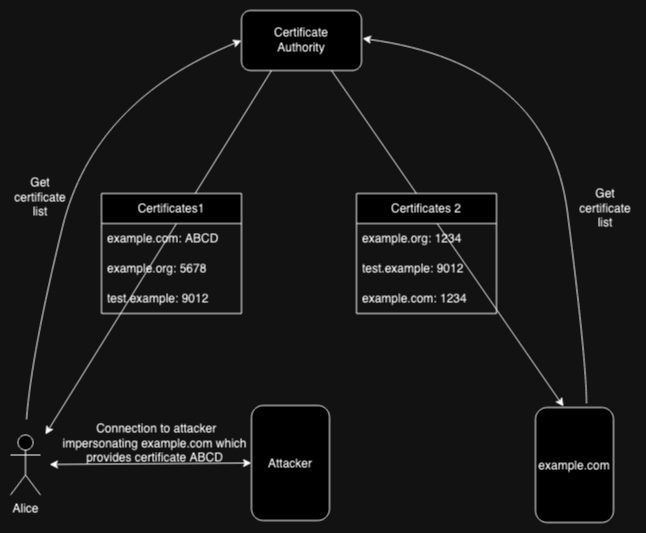
In this scenario the attacker has obtained a misissued certificate from the CA (not shown), which creates two lists of certificates:
- List 1, which has the attacker's certificate
- List 2, which has the legitimate certificate
When example.com goes to check the list of certificates,
the CA provides List 2, containing the correct certificate (1234) so everything looks OK.
On the other hand, when Alice connects to the attacker (impersonating example.com),
it presents the fake certificate (ABCD). Alice then
connects to the CA, which provides List 1, containing ABCD
everything looks OK here too, and the attack
goes undetected.
The point here is that the authentication server needs to publish the certificate list in some way that everyone has the same view and that they can verify that they have the same view (technical term: consensus). As long as this is true, then we know that the owner of the identity has had a chance to check any certificate which the relying party might treat as valid.
The analogy I like to use for this kind of consensus (I'm not sure who originated it) is that the authentication server publishes each binding by using a giant laser to inscribe each binding onto the face of the moon. This allows anyone with a telescope to look up—at least during the night—and see what bindings have been created.

This is what is known as a "publicly verifiable" system in that it doesn't require trust. Anyone can see for themselves what is written on the face of the moon, so you aren't depending on the CA not to cheat.
Unfortunately, the giant laser is physically impractical, and so we need some other technology for providing consensus. Much of the complexity in transparency systems derives from this requirement.
Manufacturing Consensus #
As noted above, the basic challenge we have here is ensuring that every client has the same view of the certificate database.
The obvious thing to do is for people—really client software—to share copies of the database with each other so that you effectively flood fill the database to everyone and eventually everyone has a copy of the whole database. Alternately, if you have a piece of software like a browser which has an update channel, the vendor can send a copy of the database to all its users. Of course in this case you're trusting the browser vendor not to send a fake database, but as a practical matter you're also trusting them not to send you malicious updates anyway, so it's not clear how much worse this makes the situation. More on this in a future post. Whichever design you are using, if the attacker has mounted a partitioning attack as described above, then the site will eventually get a copy of the correct database from some other element, thus allowing for detection of misissuance when it sees a certificate it doesn't recognize.
One thing that's very important to realize is that it doesn't matter if some—or even most—of the endpoints in the system are malicious; if the flood fill system is working, then eventually[5] each endpoint will talk to someone who isn't malicious, so they will eventually get a copy of every certificate. And because certificates are publicly verifiable (you just check the signature), it's easy to store every certificate that is valid and discard the ones that aren't. A malicious node can remove certificates from the database they send you, but they can't insert certificates that don't exist or prevent other endpoints from sending you valid certificates.
Moreover, it's not really required that everyone get a full
copy of the database: consider the case where we have a fake
certificate for example.com. If the operators of example.com
see it, then they can publish it and report it to the browser
vendors, who can then investigate, as described above. The point here is that the system
doesn't need to work perfectly in order to detect attacks;
it just needs to work well enough that (1) any relying party
will be able to validate that a certificate has been published
in the database and (2) the attacker cannot reliably prevent parties
trying to verify database correctness from getting a copy of
misissued certificates.
With the right data structure, it's also possible to make partition attacks easier to detect. For instance, if each CA publishes one database a day and signs the entire database, then any element which receives two databases for a single day can immediately detect that there has been cheating.
The problem, obviously, is that this kind of flood fill is incredibly inefficient: Let's Encrypt alone has about 300 million valid certificates; at 1K each, this would be a database of 300GB, not something you want to be storing on your phone, let alone having to send to everyone else you come into contact with—ignoring for the moment the question of how you're going to transmit the database around. Clearly, this simple system is not practical.
Of course, you don't actually need to send a copy of the database to everyone, you just need to verify that you have the same database as everyone else, which you can do by exchanging hashes of the database, but this doesn't get us very far because (1) you still need to keep a copy of the database on your computer and (2) the database isn't static, but instead new certificates are constantly being issued (Let's Encrypt issues over 3 million certificates a day). Addressing this requires some new technology, specifically something called a "Merkle Tree".
Background: Merkle Trees #
The idea behind a Merkle Tree is to allow a way to efficiently commit to a set of values without actually publishing any of the values.
As an intuition pump, suppose I run a streaming service which send movies over the Internet and I want people to be confident that they are getting the right movie and not some content generated by an attacker. In the real world, we just carry all the data over a TLS connection, but let's assume I'm too cheap for that. Instead, what I could do is send the hash of the content over the TLS connection and then let the client retrieve the rest over HTTP (there used to be a time when people really worried about the cost of encryption). The problem with this is that the hash is computed over the entire movie, but we obviously want people to able to verify that there hasn't been any tampering as they are watching it. The obvious solution here is to break the movie up into chunks—you want to do this anyway so that people can easily scroll forward or backward—and then send a hash for each chunk over the TLS connection. Then, when the client retrieves each chunk, they can verify the hash before they play it.
This still involves sending a fair amount of data over the TLS connection, though: suppose each chunk is 5s long, then a 2 hr movie will be 1440 chunks and require sending something like 46KB over the TLS connection. It turns out that there is a more efficient strategy, using one of the computer scientist's favorite tools, the binary tree. The basic idea is that we hash each chunk and then arrange the chunks in a binary tree, like so:
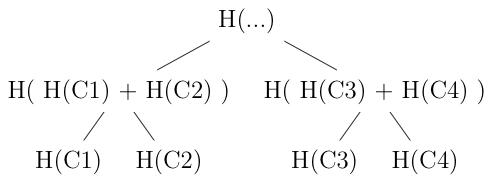
The leaves of the tree are the hashes of the individual chunks and then each interior node is the hash of its two children[6] This way, the root of the tree includes the hashes of all of the leaves, so if any leaf changes then it would also change the hash of the root. This way, you can publish only the root hash over the TLS connection and anyone can verify the leaves by just hashing them up to the root.
Well, sort of. What I just described requires having all the chunks,
but remember we want to be able to verify a chunk without other
chunks. Fortunately, there is an easy way to arrange this: when
you send a chunk, you also send enough nodes in the tree to let
the receiver reconstruct the tree. Specifically, you send the
nodes next to the nodes on path between your chunk and the root.
For example, suppose I just sent chunk 1. The receiver can compute
H(C1) for themselves, but they can't compute the parent node without
knowing H(C2), so I have to send that. Similarly, they can't compute
the root without knowing H ( H(C3) + H(C4) ) so I have to send
that as well. I don't have to send H(C3) or H(C4) because they
don't need that to compute the root.
The figure below illustrates what I'm talking about:
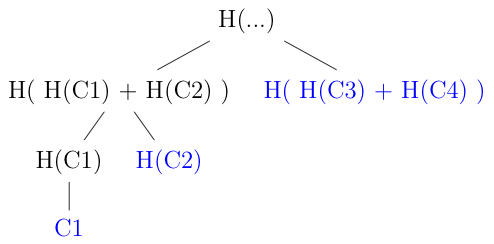
The sender has to transmit everything in blue, specifically:
- The chunk
C1itself so that the receiver can computeH(C1), though of course it was transmitting this anyway. H(C2)so that the the receiver can compute the parent nodeH( H(C1) + H(C2) )H( H(C3) + H(C4) )so that the receiver can compute the root
The receiver computes everything in black for themselves and then
compares it with the root hash it received over the secure channel.
If everything checks out, then this proves that the tree was computed
over C1 (and that it was in that position in the tree) and therefore
that it's a legitimate chunk. The technical term here is
an "inclusion" proof, because it proves that the chunk was included
in the computation for the tree.
The key thing to realize is that the number of extra hashes that the sender has to include in order to let the receiver verify a chunk is less than the number of total chunks. Specifically, it's the depth of the tree, which is to say the logarithm base 2 of the number of chunks. In this case, that's 2 hashes, which is only half the number of chunks, but if there were thousands of chunks then this would be a huge difference.
A Transparency System with Merkle Trees #
It should now be apparent what we are going to do next, which is to put the certificates into a Merkle Tree. As a starting point, let's say that each CA takes all the certificates and makes them the leaves of the tree.[7] With Let's Encrypt's 3 million certificates a day, this tree will be of around depth 22 for a day's certificates. The figure below provides an overview of how this fits together:
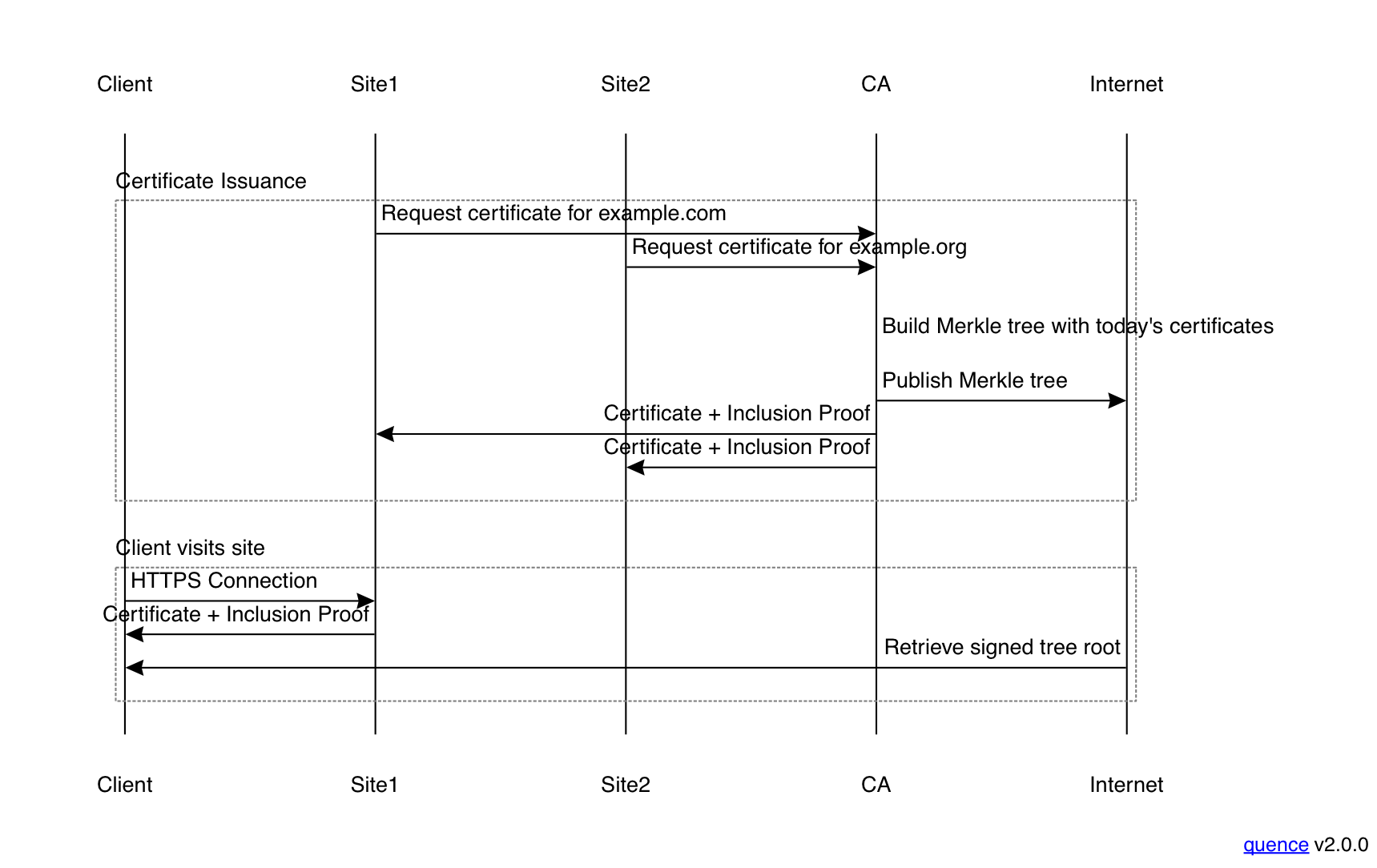
When example.com wants to get a certificate, it contacts the CA
as usual. The CA does whatever procedure it wants to validate
the request and then waits for other certificate
requests to come in. After some period (in this case daily), the
CA generates all the certificates and then builds a Merkle tree
out of them. It publishes the whole Merkle tree on the Internet
and then sends each site it's certificate, as well as the
inclusion proof that the certificate was included in today's
tree. The inclusion proof is comparatively small; using
Let's Encrypt as our reference point, it will be about 600-700
bytes.
When the client subsequently contacts the site, the site provides both its certificate and the inclusion proof.[8] The certificate can be verified in the usual fashion, but the client also needs to verify the inclusion proof in order to ensure that the certificate was actually published. In order to do this, it needs both the inclusion proof itself and the root of the Merkle tree that was published at the time of certificate issuance. Instead of flood filling the tree itself, we instead arrange to flood fill the signed root of the tree (or, more likely for a browser, to distribute it in the update channel). The client verifies the signature on the root to ensure that it's valid and then checks the inclusion proof in order to be sure that the certificate was really included in the tree.
This is a big improvement in the amount of information the client needs to store and retrieve. The signed root itself is very small (~100 bytes) and then on each connection it needs to retrieve ~600-700 bytes of inclusion proof for each certificate, which is around the size of your typical certificate, so this perhaps doubles the overhead of the TLS connection, which isn't that bad.
Note that in order to verify that there are no unexpected certificates for its domain names, the site still needs to download the entire certificate database, or more likely use some service which does it for it. However, sites typically have significant resources, and the database isn't that big, so this is a much smaller burden than requiring every browser to retrieve a copy. Moreover, a service which does this kind of checking just needs to download the database once for all of its clients, which lets it amortize the cost.
Security Properties #
This system does a reasonable job of providing the security guarantees we asked for at the start.
Because the client verifies the inclusion proof for a certificate, it is able to ensure that it chains up to a signed root. While the CA can technically make more than one tree with different contents, that requires signing two tree roots, which then have to published somehow in order to be useful. As there is supposed to be only one root per day, as soon as any endpoint sees two different roots for the same period, it knows that the CA is cheating and can prove it to any third party just by publishing both signed roots.
If we're doing simply peer-to-peer flood fill, not every client will be able to see both roots, but it's likely that one will. If clients are getting their copy of the signed root from their vendor, then the situation is even simpler: every client from the vendor will have the same root and as long as vendors check that their roots match and sites/services that want to check the database verify that their roots match the vendors roots, there's no real way to publish two roots without being immediately detected.
The result is a system that is publicly verifiable in that everyone has the same view of the certificates that have been published. This isn't perfect in that you still have to actually detect misissuance, which isn't always straightforward for the reasons I discussed above, but at least it's not possible to have covert misissuance. This means that misissuance for big sites will probably be detected, and if any kind of misissuance is detected it's much easier to investigate because you have a permanent record.
Next Up: Real World Certificate Transparency #
At the beginning, I said that I was going to try to build an idealized version of Certificate Transparency, and that's what we have here. There are still a fair number of moving pieces, but the result has strong and fairly straightforward security properties. Unfortunately, CT as actually deployed involved quite a few technical compromises and the result was something more complicated and with quite different security properties. I'll be talking about those compromises and their consequences in the next post.
Yes, yes, I know it's technically a "certification authority", but at this point, can we just agree that it's "certificate authority". ↩︎
It's also not always possible to outsource this job to a CDN or hosting provider, because you might have your site hosted across more than one service, so no single service can check that it recognizes every certificate. For instance, suppose your site is both on Cloudflare and Fastly; both services will have certificates for your domain and if Cloudflare goes to check for certificates that weren't issued to it, it will find the ones issued to Fastly. ↩︎
The processes used to validate domains for certificate issuance are far from perfect, so even a well-operated CA can still misissue. ↩︎
Note that because certificates are signed by the CA, anyone can verify that they really issued it, without the cooperation of the CA after the fact. The certificate itself plus the claim by the domain's operator is prima facie evidence that something is wrong. ↩︎
"Eventually" is doing a lot of work here, but this isn't the system we're going to build, so I'm just going to handwave past it. ↩︎
Technical note: you actually don't want to use exactly this structure because because it creates ambiguity between an interior node with children H(A) and H(B) and a leaf node with value H(A) + H(B), but that's easy to fix. ↩︎
Actual CT uses one big tree that grows over time, but this is conceptually easier to describe. ↩︎
For deployment reasons, we'd actually like the inclusion proof to be included in the certificate, so we don't need to modify the TLS stack. This is technically possible but doesn't matter at the moment. ↩︎