Can we make Safe Browsing safer?
It's an essential service, but it would be better if it were more private
Posted by ekr on 16 Aug 2022
The Web is full of bad stuff and it's the browser's job to protect you from it as best it can. For certain classes of attack, such as attempts to subvert your computer, that is a conceptually straightforward matter of hardening the browser, as described in the Web security guarantee:
users can safely visit arbitrary web sites and execute scripts provided by those sites.
In practice, of course, browsers have vulnerabilities which mean they don't always deliver on this guarantee. However, even if you ignore browser issues, there are other classes of harm, such as phishing or fraud, that aren't about attacking the computer but rather about attacking the user. Because these threats rely on users incorrectly trusting the site, hardening the browser doesn't work; instead we want to warn the user that they are about to do something unsafe. The primary tool we have available for protecting against this class of attack is to have a blocklist of dangerous sites/URLs. The most widely used such blocklist is Google's Safe Browsing, which is used by Chrome, Firefox, and Safari, and other browsers (there are other similar services, but Safe Browsing is the most popular).
The Safe Browsing Database #
In order to implement Safe Browsing, Google maintains a database of potentially harmful sites that it collects via some unspecified mechanism. The Safe Browsing database[1] consists of a list of blocked strings which consist of:
- Domain names or parts of domain names
- Domain and path prefixes, broken at path separators (
/) - Domain and paths and query paramaters
So, for instance, for the URL https://example.com/a/b/c the
database might contain example.com if the whole domain was
dangerous or maybe example.com/a/b if only some parts of the
domain were dangerous. In order to check a URL, you break it down into the list of
prefixes and check all of them. If any of them match, then
the URL is dangerous. Here's the example Google gives for
the URL http://a.b.c/1/2.html?param=1:
a.b.c/1/2.html?param=1
a.b.c/1/2.html
a.b.c/
a.b.c/1/
b.c/1/2.html?param=1
b.c/1/2.html
b.c/
b.c/1/
If any of the substrings match, then the browser shows a warning, like this:
Pretty scary, right?
Querying the Database #
Note: There are a number of versions of Safe Browsing. This describes the Safe Browsing v4 protocol which is what is currently implemented in Firefox, which I just call Safe Browsing for convenience..
Of course, the Safe Browsing database is on Google's servers, so the browser needs some way to query it. The obvious thing to do is for the client to send Google the URLs it is interested in and just get back a yes or no answer. Safe Browsing does have an API for this, but of course this has some obvious very serious privacy problems, in that the server gets to learn everyone's browsing history, which is something that many browsers try to stop in other contexts. AFAIK, no major safe browsing client currently operates this way by default, although Chrome offers a feature called "enhanced safe browsing" in which Chrome queries the Safe Browsing service directly for some URLs:
When you switch to Enhanced Safe Browsing, Chrome will share additional security data directly with Google Safe Browsing to enable more accurate threat assessments. For example, Chrome will check uncommon URLs in real time to detect whether the site you are about to visit may be a phishing site. Chrome will also send a small sample of pages and suspicious downloads to help discover new threats against you and other Chrome users.
However, this is not the default behavior.
The other obvious design is to just send the entire database to the client and let it do lookups locally. This is a reasonable design and one which I'll consider below, but it's not the way the current system works. Instead Safe Browsing uses a design which is intended to balance performance, privacy, and timeliness.
The basic structure of the system works as follows. For each string S_i in the database, the server computes a hash H(S_i). It then truncates each hash to 4 bytes (32 bits) and sends the truncated list to the client, as shown below:
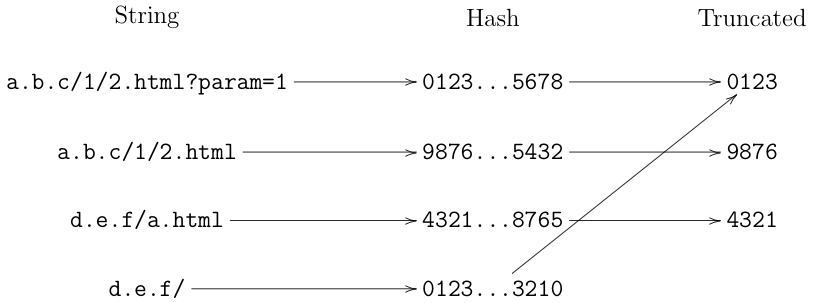
The impact of this process is to compress the set of strings somewhat, to a total size of 4I bytes where I is the total number of strings (there is also a system to compress the database somewhat). As shown in this diagram, it's possible that multiple strings will map onto the same truncated hash (though different full hashes). As a practical matter, this is a pretty sparse space: there are only about 222 (3 million) strings and there are 232 possible truncated hashes, so there will be approximately as many truncated hashes as there are input strings; the full hashes are 256 bits long and so are unique with extremely high probability.
However, the cost of this design is false positives: effectively, the hash function maps an input string onto a random 32-bit hash, and about 1/1400 of these hashes will correspond to one of the truncated hashes that the server sends to the client.[2] Obviously, if the client were to generate an error every time there was a match this would create an unacceptable client experience, as people would regularly encounter scary warnings. However, this data structure does not have false negatives: if the hash prefix isn't in the list, then the hash won't be in the full list either.
Order of Operations #
In Firefox, Safe Browsing checks proceed partly in parallel to retrieving the URL; because the primary risk is the user inappropriately acting on the returned Web page, it's fine to contact the server as long as you don't display the result. This parallelism allows for better performance.
However, Firefox uses a similar mechanism for it's Tracking Protection feature, and the purpose of that feature is (partly) to prevent trackers from using IP address-based tracking, so it's not even safe to send a request to the server before checking the blocklist. Fortunately, Tracking Protection downloads a list of full hashes and so doesn't need to wait for the server.
Instead of generating an error, the client double-checks the match by asking the server to send the full hashes corresponding to the truncated hash. In order to check a string, the client proceeds as follows.
- Compute the full hash
- If the 32-bit hash prefix is not in the downloaded list, then the string is OK and continue to retrieve the URL.
- Otherwise, send the hash prefix to the server and ask the server to provide the list of corresponding full hashes with that prefix (typically just a single result).
- If the full hash is on the list of returned hashes, then generate an error.
- Otherwise, continue to retrieve the URL.
This design has a number of advantages. First, it means that the server doesn't need to send the client the entire database, which is about four times larger than the truncated database because the hashes are four times larger (though more on this later).
Second, it allows the server to quickly retract inappropriately blocklisted sites. Suppose that the server had blocklisted a URL with hash XY where X is the 32-bit prefix and Y is the rest of the hash. The client retrieves X as part of downloading the database and then when it gets a match, asks for all the hashes starting with X. However, in the meantime, the server has decided that XY is OK. In this case, it can just return an empty list and the client will continue without error.
Conversely, however, the server cannot easily add new values between client-side database updates. Because the client never contacts the server if the prefix isn't in the database, then the server won't have an opportunity to add new entries unless they happen to correspond to a prefix which is already in the database, which, as noted above, is quite unlikely. This is somewhat unfortunate because a lot of phishing attacks operate on the time scale of minutes to tens of minutes and so you would need the client to update its database unpractically frequently in order to catch them (hence the reason for "enhanced safe browsing").
Finally, because most of the potential hash prefixes don't appear on the prefix list, the client mostly doesn't need to contact the server. This improves performance (because most URLs can be retrieved immediately) and privacy (because the server doesn't learn anything for most URLs). In addition, the client can cache any full hashes it has retrieved for a given prefix for some time, so it won't need to recontact the server during the cache lifetime.
Privacy Implications #
The basic privacy problem with the Safe Browsing is that even though clients don't connect to the server for most URLs, they do connect for some URLs. Naively, you would expect the server to get queries for about 1/1400 of the user's browsing history keyed by the IP address (obviously the browser shouldn't send cookies!) but actually this underestimates the situation in two important ways:
-
As described above, the browser checks multiple strings for the same URL, with the exact number depending on the URL. Each of these might result in a query to the server. If we assume that there are 5-10 strings to check per URL, we're looking at more like 1/200 to 1/400 URLs.[3] The situation is even worse if you visit multiple URLs on the same site.
-
This calculation assumes that the server isn't malicious. Consider a server which wants to know whenever you go to Facebook: it just needs to compute the hash prefix for
facebook.comand publish that. When the client queries for that prefix, it returns a random hash (thus ensuring there is no blocking), but the server gets to learn that the client might be going to Facebook.
Checking Passwords #
Another general problem in this space is checking compromised passwords. The general setting here is that there is a server which has a list of passwords that have been in breaches, such as HaveIBeenPwned and the client wants to determine if the user's password is on the list. Naively, you can use the same protocol for this application as for Safe Browsing, but there are two complicating factors:
- The server may not want to keep the list of password hashes secret to prevent people from learning the list of passwords.
- Because some passwords are much more common than others, the client may want to prevent the server from learning that it has one of these passwords by sending the corresponding hash prefix.
An example of a technique tuned specifically for password checking is provided in a paper by Li, Pal, Ali, Sullivan, Chatterjee, and Ristenpart which uses a combination of private set intersection to prevent the client from learning the hashes and "frequency smoothed" hash bucketing to prevent the hash from leaking information about the client's password.
Of course, the server doesn't actually learn which URLs the client is visiting because (1) it learn hashes and (2) the hashes are truncated, so that there are many strings with the same truncated hash. Note that it's very important that the client only request hash prefixes because if the client were to ask for the full hash, it would be relatively straightforward for the server to determine most of the input strings just by computing the hashes for known URLs.
However, even though there are many strings with
the same hash prefix, some of those
strings (e.g., facebook.com) are more likely to
be visited by users than others (e.g., 86c0cb28d2ae2b872eb52.example).
An additional consideration is that a client might
need to query multiple strings associated with the same
site. For instance, if the client queries the hash
prefix for educatedguesswork.org (hash=A) and educatedguesswork.org/posts/safe-browsing-privacy/ (hash=B) then it's more likely that the user is visiting
this site than a pair of unrelated sites that
happen to have hashes A and B. Providing a complete
analysis of the level of privacy leakage from Safe Browsing
is fairly complicated and depends on the distribution of visits
to various sites and your prior expectations of which sites
a user is likely to visit, but suffice to say that there
is clearly some privacy leakage. Ideally, we would have
no leakage.
Improving Privacy #
Trying to improve Safe Browsing and in particular address these privacy issues is an active area of work and in particular something that Google and Mozila have collaborated on for quite some time. There are three primary known approaches to improving the privacy of this kind of system:
- Proxying
- Use full hashes
- Crypto!
I'll discuss each of these below.
Proxying #
The most obvious technique is just to proxy the queries to the server. This conceals the IP address, which prevents the server from directly linking queries to the user. As I understand it, Apple already proxies Safe Browsing traffic, at least for iOS. Proxying is a nicely general technique which is simple to implement and reason about. Indeed, one might think that we could simplify the system by skipping the prefix list and just having the client query the server for every string (or more likely every full hash). This would provide better timeliness, including the ability to quickly add new entries, though of course at some performance cost.
There are a number of subtle points, however. First, it's important that the queries be unlinkable from the perspective of the server. Consider what happens if the client makes a long-term connection to the server (through the proxy) and then proceeds to make all its queries through that single connection. In that case, the server might be able to use the pattern of requests to infer the user's identity and then to connect that to the rest of their browsing activity. For instance, suppose user A retrieves the following URLs:
github.com/fuzzydunlopp fuzzydunlopp.example/edit www.instagram.com/marlo.stanfield/
It's a fair inference that the user in question is
fuzzydonlopp and that they also are visiting
Marlo Stanfield's Instagram.
This suggests that connection proxying systems like MASQUE are bad fits for this application and instead we would be better served by message proxying systems like Oblivious HTTP. In O-HTTP, each request is separately encrypted to the server, but requests from multiple clients are multiplexed on the same connection from the proxy, thus making it difficult to link them up. Even so, however, you need to worry about timing analysis (e.g., when potentially related requests come in close succession).
A related problem is that some servers are concerned about abuse (e.g., excessive requests). It's common to use IP addresses for this purpose, for instance by looking for excessive traffic for a given IP address. It's not actually clear to me that abuse is that big a consideration in this case because serving the query is actually very cheap, as it's just a very small data value, but in any case having a proxy which conceals the client's address prevents them for being used for this purpose. This potentially makes it harder to manage misbehaving clients while providing service to legitimate clients.
There are a variety of techniques which might be usable for this application (e.g., PrivacyPass), but it's not clear how well they work in this case because you need to design a system which provides anti-abuse without linkability but which is also cheap enough to verify that it's not easier to just serve the request. For instance, if you have the choice between verifying a digital signature and then serving the request or just serving all the requests, it's probably better to just serve the requests: the vast majority of requests will be valid, and for those you need to both verify the signature and serve the requests so you have to pay both costs. Moreover, in many cases even a failed verification will be more expensive than just serving the request. In addition, if the proxy and the server have a relationship, then the proxy can do some of the work of suppressing abuse, as described in the O-HTTP spec.
Distribute Longer Hashes #
Another alternative design is to send the client longer hashes. The false positive rate is dictated by the fraction of hashes which correspond to blocked strings, and so just making the hash longer makes the false positive rate lower. If you use a sufficiently long hash, then you can make the false positive rate acceptably low and there is no need to double check with the server at all. This produces a much simpler system which is both faster (because you never need to contact the server) and more private (because the client never makes any queries to the server which depend on your browsing history).
How long a hash do you need? Safe Browsing uses 256-bit hashes (SHA-256), but you almost certainly need less. If you use a b-bit hash and there are 220 blocked strings, then the chance that a randomly chosen non-blocked string will be reported as blocked is 2-(b-20) If we used an 80-bit hash, then the natural rate of false positives would be 2^-60, which seems acceptably low. However, this leaves open an attack in which an attacker deliberately creates a collision in order to make a site unreachable.
Consider the case where the attacker wants to block
example.com. They make their own malware site and
search the space of URLs until the find one which
has the same hash as example.com. They then put their
site up at that URL and wait for the server to detect
it. Once they do, then they publish the hash and suddenly
no client can go to example.com. This attack doesn't
work with the current Safe Browsing design because the
client contacts the server, which uses a full hash
(though the attacker can force the client to contact
the server for example.com), but it works if you
remove the double checking step.
The natural defense against this attack is to just
make the hash longer. For instance, if we were to use
a 128-bit hash, then the attacker would need to
do more like 2100 work in order to create a collision, which
is probably acceptably large.[4]
It's important to note that the privacy guarantees of this system are better than those of the proxy system: with the proxy, privacy depends on the proxy and the server not colluding, whereas with longer hashes the privacy of the system does not require trusting anyone.
Of course, sending longer hashes means more communication cost: if we use 128-bit hashes, it will probably cost about 4 times as much to update the client. However, this is an upper bound: in the current Safe Browsing design, the client needs to make connections to the server in order to double check (this is even more expensive with proxying) and these are not necessary with longer hashes. Moreover, those connections are in the critical path for downloading URLs, whereas updating the hashes can be done in the background.
Crypto! #
Finally, we could use cryptography. This is closely related to a well-known problem called Private Information Retrieval[5] in which the client wants to query a database without the server learning which database entry it is querying. Naively, PIR is precisely what we want here, in that it would give good privacy and yet full timeliness (we might still want to distribute the partial hashes to reduce the number of queries required for performance reasons) but the problem is that it's really hard to build a PIR scheme that has good enough performance to be in the critical path for a browser. For instance, in 2021, Kogan and Corrigan-Gibbs published a system called Checklist specifically designed for Safe Browsing, but it comes at real costs, as described in the Checklist abstract:
This paper presents Checklist, a system for private blocklist lookups. In Checklist, a client can determine whether a particular string appears on a server-held blocklist of strings, without leaking its string to the server. Checklist is the first blocklist-lookup system that (1) leaks no information about the client’s string to the server, (2) does not require the client to store the blocklist in its entirety, and (3) allows the server to respond to the client’s query in time sublinear in the blocklist size. To make this possible, we construct a new two-server private-information-retrieval protocol that is both asymptotically and concretely faster, in terms of server-side time, than those of prior work. We evaluate Checklist in the context of Google’s “Safe Browsing” blocklist, which all major browsers use to prevent web clients from visiting malware-hosting URLs. Today, lookups to this blocklist leak partial hashes of a subset of clients’ visited URLs to Google’s servers. We have modified Firefox to perform Safe-Browsing blocklist lookups via Checklist servers, which eliminates the leakage of partial URL hashes from the Firefox client to the blocklist servers. This privacy gain comes at the cost of increasing communication by a factor of 3.3×, and the server-side compute costs by 9.8×. Checklist reduces end-to-end server-side costs by 6.7×, compared to what would be possible with prior state-of-the-art two-server private information retrieval.
Of course, PIR schemes continue to improve (for instance, Henzinger, Hong, Corrigan-Gibbs, Meiklejohn, and Veikuntanathan just published a new system called SimplePIR), so at some point it may just be possible to swap in a PIR system for all of this custom machinery. This has the potential to provide the best combination of security, timeliness, and privacy.
Final Thoughts #
Safe Browsing and similar services are a key part of protecting users on the Internet, but the current state of technology requires us to make some compromises between effectiveness, privacy, and timeliness. It's not clear to me that the current design has the optimal set of tradeoffs, but with better technology, it may also be possible to build a system which is superior on every dimension.
There are actually several databases for different categories of blockage. ↩︎
Effectively, this is a single hash Bloom Filter. ↩︎
I thought I remembered the Firefox sent some random hash prefixes to the server to create some additional deniability, but a quick skim of the code doesn't show anything. Will update if I learn more. Updated 2022-08-17: here. Thanks to Thorin for the link. ↩︎
Another potential defense would be to have the server generate the hash with a secret salt value, thus making collisions hard to find. However, this makes incremental updates hard because the attacker then learns the salt. The server could also make the problem somewhat harder by using a large number of public salts, but this just increases the work factor by the number of salts. ↩︎
We don't need private set intersection here because it's not a problem for the client to learn the server's data even if there is not a match. ↩︎