An overview of browser privacy features
How browsers protect you, and don't
Posted by ekr on 04 Jul 2022
Recently I was interviewed by for an article about how to privately search for reproductive health services. During the discussion I found myself explaining the different privacy features available to Web users and wishing that I had something written to point to. Hence this post.
Types of Tracking #
First, it's important to be clear about what we are trying to accomplish. When we talk about Web tracking, there are two different kinds of tracking we are concerned about:
-
Cross-site tracking of your activity across web sites (e.g., I went to Nike and Adidas).
-
Same-site tracking of your activity at different times on the same site (e.g., I searched on Google for "shoes" and then later for "tofu").
Mostly, when people talk about "Web tracking" they are talking about cross-site tracking. This is clearly something that people didn't really sign up for and doesn't really provide much direct user benefit (we can argue about whether personalized ads are a user benefit, but if so they're not a very large one). For this reason, a number of browsers have started to build privacy features designed to block cross-site tracking by default.
By contrast, a lot of important Web functionality depends on the ability to link up one visit to another (for instance, this is how you stay logged in to your accounts between visits). Even in cases where users don't explicitly log in, sites use information about previous visits to personalize your experience (for instance, to make content recommendations). This isn't to say that all such tracking is desirable, but merely that we can't just turn it off because users would notice and be unhappy. This means that we need to find some way of providing privacy in cases where users want it and not when they don't.
Attacker Models #
Most browser privacy work focuses on what's called a Web attacker. which is to say an attacker who controls some set of Web sites. This is distinct from a lot of Internet security work which assumes a network attacker (see here for more on this) who can observe all of your traffic. The main reason for this is that it's a lot harder to defend against a network attacker—defending against a Web attacker is hard enough—and as we'll see below, we don't know how to do so cheaply.
Tracking Your Browsing History #
Consider the browsing history shown
in the diagram below, in which the user visits the sites
a.example, b.example, and c.example. If a tracker
is present on each of those sites (this is not uncommon!) it will
be able to get an accurate picture of your browsing history, learning
which sites you visit and in which order.
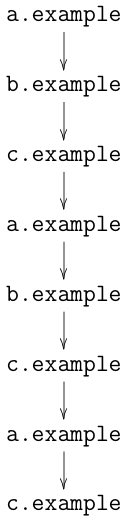
Cookies #
The main mechanism that sites use to track your behavior is the cookie. Recall that a cookie is just a piece of state that a site can set in your browser and gets sent back to that site whenever you visit it. Because cookies can be embedded on multiple sites, this allows the third party to gradually build up a picture of your browsing behavior, as I described previously, thus building up a more complete profile of your browsing history. This is obviously extremely bad for user privacy.
As noted above, a number of browsers—notably Firefox and Safari— have started building in anti-tracking mechanisms to reduce this privacy leakage. These mechanisms are concerned with reducing cross-site tracking and operate primarily by restricting the use of third-party cookies and other cross-site state mechanisms. The idea is that instead of allowing trackers to link up behavior on multiple sites, they just get to see behavior on individual sites. The state of the art here is what's called first-party isolation (FPI) (or "double keying") which means that the browser stores cookies separately for each top-level site (the one that appears in the URL bar). In Firefox, this feature is called Total Cookie Protection (TCP), and in Safari, I think it's just part of their Intelligent Tracking Protection[1] suite.
With FPI, if tracker T appears on sites A and
B it will get a different set of cookies on each site.
The diagram below shows the usual situation without FPI. The client first
visits a.example which incorporates an ad. Because this is the
first time the client has encountered this ad server, the client
has no cookies for it. When the server serves the ad, it also sets
cookie 1234. When the client later visits b.example, which
uses the same ad server, the client sends the cookie 1234 which
lets the server link up the two visits. Finally, the client
goes back to a.example, which again serves an ad, and the
client sends the same cookie.

The next diagram shows the same browsing pattern but with FPI
on. The first interaction is the same, but then when the
client goes to visit b.example and loads an ad from the
ad server, it doesn't have a cookie, because cookies
for visits to a.example are stored separately from
those for visits to b.example (no matter which origin
the cookie is for!). Instead, the client makes the request
without a cookie and the ad server sends a new cookie
5678. However, when the client goes back to a.example
it sends the original 1234 cookie. This preserves some
important functionality, such as when a web site uses multiple
domains associated with the same company (e.g.,
the site is served off of service.example but has an
API on a CDN such as service.cdn.example),[2]
as opposed to blocking third party cookies, which would
break this kind of use case.

Because FPI allows trackers to link up two visits to the same site, but not to different sites, our original user's browsing history would appear to the tracker as three separate traces, like so:
![]()
Ideally, the tracker has no way of knowing that these traces are all from the same browser or from different browsers. How much privacy this provides depends on how much time you spend on site. For instance, because people spend a lot of time on Google and Facebook, they get a pretty good idea of your activity and interests, and, depending on that activity, they may be able to tie it to your personal identity. On the other hand, if you go to a site once, then that site doesn't learn a lot about you.
Other Tracking Mechanisms #
Unfortunately, cookies are not the only way to track users. There are two much harder to block mechanisms:
- The IP address
- Fingerprinting
The IP address is largely tied to a given device, though devices—especially mobile devices—can change their IP address, so it serves as a pretty strong/stable long-term identifier. Because the IP address is necessary for communicating with the server, there's not a whole lot that browsers can do about it directly without relaying traffic through some other node (more on this below).
The other major non-state mechanism for tracking users is fingerprinting. Fingerprinting exploits natural variation in the hardware and software that users run. The Web provides a number of APIs that allow sites to learn information about a user's machine, such as what browser and version they are running, what operating system it is on, what language it is set to, and even the number of logical processor cores it has. Any individual value like this isn't particularly identifying, but when you add them up they provide a significant amount of information about user identity. Estimates of precisely how much vary widely, but everyone agrees it's nonzero and probably at least enough to reduce the set of possible users by a factor of 1000 or more, depending on how unusual a given user's configuration is.
Countering fingerprinting is a difficult problem, and requires compromising between providing maximal privacy and breaking functionality. For instance, a number of Web APIs can be—and are—used for fingerprinting, but they are also widely used for non-fingerprinting purposes, so restricting their use is difficult.
Private Browsing Modes #
Most browsers include some kind of mode ("Private Browsing" on Firefox and Safari , "Incognito" on Chrome) that is designed to provide a somewhat more private experience. Historically, these modes were mostly designed not to prevent web tracking but rather to prevent against local attack. The idea here is largely that you might have some kind of shared computer and you don't want whoever you share it with to know what sites you are going to. The official motivating use case for private browsing is often phrased as buying presents for someone, with the unofficial use case being pornography.
At a high level, private browsing modes work by not storing browsing state past the lifetime of the browsing session (though the definition of session varies somewhat). Here's Firefox's list of what it doesn't store:
- Visited pages (history)
- Form and search bar entries
- Download list entries
- Cookies
- Cached Web content and Offline web content and user data
If this is all working correctly, then someone who uses your computer after you have closed the browser should not be able to learn what sites you have gone to.
Because cookies and cached content are deleted, private browsing also inherently provides some protection against tracking by Web sites in both the first and third party contexts. This protection operates at the level of preventing linkage between sessions. In particular, it should prevent the use of these mechanisms for tracking between private and non-private contexts, such as when you visit a site in private browsing and then go back to it in regular browsing. It also prevents sites from using these mechanisms to track you between multiple private browsing sessions. If our example browsing activity above had used private browsing along with FPI, then what trackers would see is shown below:
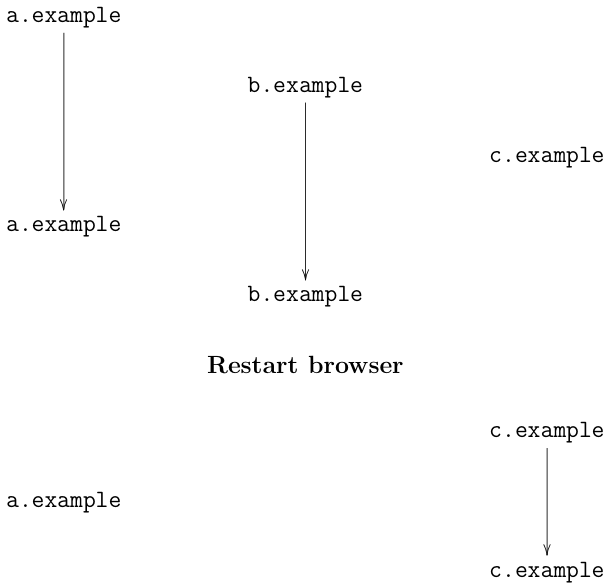
The thing to notice here is that the browsing activity before and after the browser restart are disconnected, so the trackers (in theory) can't link them up.
Of course this also means that you don't stay logged to sites that you logged into in private browsing, which is obviously a pain. And if you do log in, then of course the site is able to link up your behavior before and after, obviating the value of using private browsing for those sites. This makes private browsing mode of limited usefulness for a lot of browsing activities (e.g., shopping).
In addition to clearing state, browsers have started to add more explicit anti-tracking mechanisms to private browsing mode. For instance, Firefox Private Browsing mode automatically enables Enhanced Tracking Protection Strict Mode (not the world's least confusing name), which stops the browser from even connecting to many known third party trackers, thus preventing them from tracking you by IP address or via fingerprinting (see below). The theory here is that users who have selected private browsing have shown they care more about privacy than breakage compared to the usual person so the browser can take a more aggressive posture in terms of enabling privacy features. Thus, private browsing modes may provide some additional protection against cross-site tracking within a session as well as well as between sessions. This is something that varies a lot between browsers.
Beyond Private Browsing Mode #
For the reasons described above, private browsing only provides partial protection against tracking, either by first parties or across sites. In order to get that, you need to do something about IP-based tracking and probably about fingerprinting.
How Stable Are IP Addresses? #
Most devices use IP addresses that are assigned by their local network, for instance using DHCP. In principle, the network can change these addresses frequently, but as a practical matter they appear to change infrequently. Note that this does not mean that IP addresses are uniquely identifying: it's common for multiple devices to share the same home IP address via NAT, in which case sites may or may not be able to distinguish multiple devices behind the NAT. Specifically, if the devices are of different types, then the site probably can, but if you have two identical iPhones, they might not be able to.
The situation with mobile devices is generally a bit better because, well, they move around. The way that Internet routing works is that the address helps determine where to send the packets, so if you move around physically—e.g., to really different cell towers—your address should change too in order to allow the data to be delivered correctly.[3] Though of course, if you are using a mobile device from your home WiFi, that address is of course likely to be fairly stable.
Preventing IP-Based Tracking #
Addressing IP based tracking requires routing your traffic through some service that will conceal your IP address. At present, there are three main alternatives:
- A VPN
- Apple's iCloud Private Relay
- Tor
Technically these are all somewhat different but at a high level they all work by hiding your IP address behind that of the service, so that the site can't track you over long periods of time (depending on how often your IP address changes). Because your traffic is encrypted to the proxy, these mechanisms also provide some privacy against network attackers, though that protection is somewhat limited. For instance an attacker who controls the network on both sides of the proxy might be able to link up your traffic on either side via timing and packet sizes.
From the perspective of Web tracking, these systems are all mostly equally good. The main difference between the designs comes down to how worried you are about other kinds of tracking. For instance, in a typical VPN design, you connect to the VPN service and it forwards your packets to the server. This means that the VPN sees both your address—and presumably has your account information anyway—and the site you are going to, so it is able to track you even if the site doesn't; you're just trusting them not to.
iCloud Private Relay addresses this by having two proxies as shown below:
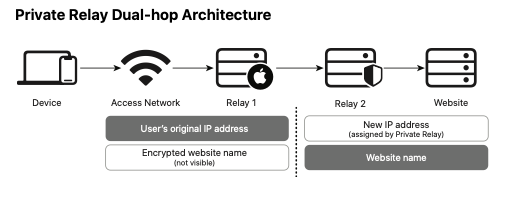
[Source: Apple white paper]
Those proxies are operated by different providers and so neither has both your identity and the site you are going to and would therefore have to collude in order to learn your browsing history. You could potentially have accomplished[4] the same thing by getting two VPN accounts with different providers, but that's not the usual configuration and would require you to do the work yourself. With Private Relay you just engage with Apple and they take care of the arrangements with the providers (using some somewhat fancy crypto to authorize you to the provider without revealing your identity). Tor takes this one step further by having three hops chosen out of a set of community operated servers. In both cases, the idea is that your behavior is private as long as one of the server is honest—or hasn't been subverted.
The basic problem with all of these designs is that they require some server (or servers) which relay the traffic and someone has to pay for those servers and their associated bandwidth. iCloud Private Relay and most VPNs are not free, so the user is the one who pays. Tor is different: instead of having a single provider such as Apple or your VPN provider, Tor servers are operated by the Tor community on a volunteer basis and are free to users (this is one of the reasons why Tor performance is generally not great).
Preventing Fingerprinting #
As I said above, a browser's fingerprint depends on a combination of the client software and the hardware it's running on: if you run the same browser on the same hardware, you'll have a fairly stable fingerprinting result. If you run a different browser on the same hardware, you'll have a somewhat different fingerprinting result. This means that if you use one browser for your usual browsing and another browser on the same machine for your "embarrassing" browsing, then each set of activity will have a consistent fingerprint and may be somewhat linkable; it may also be possible to partially link up the two sets of activity based on the fingerprint; I would not generally assume that if you use (say) Chrome for your regular browsing and Firefox for your private browsing, you are entirely safe from fingerprinting. It's probably worse if you use the same browser engine[5] type (e.g., Chrome and Edge[6]) or the same browser but in regular vs. private browsing mode, in part because they will expose the same hardware affordances and so have similar fingerprints in that respect.
A number of browsers have explicit anti-fingerprinting mechanisms with varying degrees of effectiveness. These include:
- Blocking connections to origins which perform fingerprinting (Firefox)
- Adding noise to API return values to make fingerprinting harder (Brave)
- Removing APIs which can be used for fingerprinting and trying to make other APIs return consistent results across devices (TorBrowser)
Chrome has also proposed something called the Privacy Budget in which sites would be allowed to access some data but then to throttle access after they had obtained a certain amount (see here) for our analysis of this proposal. I don't believe it's been implemented.
This is an area of research that I'm not super familiar with, but my sense is that it's not really that clear how much information can be obtained from fingerprinting. There have been a number of papers on this topic but they generally fall into two categories:
- Specific new fingerprinting techniques
- Attempts to measure the amount of fingerprinting information available via fingerprinting.
Estimates of the total amount of fingerprinting surface vary a fair bit but generally hover around 18-20 bits of information. Naively, this would be enough to reduce the size of the crowd you are hiding in by a factor about a million, which is obviously bad, but not enough to identify you specifically in many cases. This is kind of misleading because some people's configurations are more unusual than others. For instance work by Gómez-Boix, Laperdrix, and Baudry found that out of a data set of around 2 million users 29% of mobile users are unique, whereas 56% of personal computers are.[7] On the other hand, if you have a very popular device that is configured in a common way—e.g., an out of the box iPhone—then this might leak a lot less than 18-20 bits. I'm not aware of much academic research on this question or on the effectiveness of anti-fingerprinting mechanisms (please let me know if you have any!). Presumably it's better than nothing, but I don't know by how much.
Final Thoughts #
The bottom line here is that there are a lot of tracking mechanisms on the Web, and I've just covered the main ones. It's possible to do quite a bit to mitigate tracking, but the more you do, the bigger impact it has on your browsing experience, both in terms of functionality and performance. Everyone has to sort of choose their own level of comfort here, but if you don't at least do something to protect yourself from IP-based tracking, then the level of privacy is going to be limited, especially for a single site. Finally, if you want to actually browse privately, then you actually have to be anonymous, which means not logging into stuff, not buying things, etc. You can still watch cat videos, though.
This is the best link I could find, but a better one would be appreciated. ↩︎
You might say that people shouldn't architect their systems that way, but this kind of thing happens and if the browser breaks them, then the browser gets blamed. ↩︎
I say "potentially" because those two providers might have their equipment in the same data center or cloud provider, in which case you need to worry about that provider. ↩︎
For those who don't know, a lot of browsers are built on the Chromium open source code base that Chrome is based on, which means that they are internally very similar. In addition, every browser on iOS is based on the same engine because Apple forbids other engines on iOS ↩︎
Brave is a potential exception here because of their anti-fingerprinting features). ↩︎
This is also a bit misleading because in a larger data set, these might not be unique. ↩︎