Understanding The Web Security Model, Part III: Basic Principles and the Origin Concept
Posted by ekr on 21 Mar 2022
Note: This is one of those posts that is going to be best read on the Web, especially if you read your email using Gmail or the like, as it will tend to mangle some of the HTML features.
This is Part III of my series on the Web security model (see parts I and II for background on how the Web works). In this part, I cover the primary unit of Web security, the origin and some of its implications.
The Web Security Guarantee #
Unlike applications or e-books, the experience of using the Web is not confined to content provided by one vendor. Instead, even if you start on one site, many of your activities on that site will take you to other sites. Consider, for instance, the experience of searching for something using Google. Once you execute the search, Google then gives you a set of links, many of which take you to another site. Google's relationship to those sites is arms-length at best: it doesn't control them and doesn't bear any responsibility for their content beyond some vague assertion that this might be something that was responsive to your search. The situation is the same for other big content platforms like Facebook and Twitter: just because you see some link there doesn't mean that the site endorses it.
The Web vs. Internet Threat Models #
RFC 3352 (self-citation alert) defines a threat model in which the attacker has complete control of the network, which means that they can read or modify any packet. In this case, it is trivial for them to look at any unencrypted traffic or impersonate any site the client is making an unencrypted connection to. Because this kind of network attack is so powerful, it renders most questions about the Web security model more or less superfluous: if the attacker can intercept your connection to the site, it doesn't much matter whether there is some way that some other site can mount a weaker attack.
However, although powerful network attackers are reasonably common—just open your browser using Airport WiFi—there are also many weaker attackers. It used to be common to talk about the Web threat model in which we assume that the attacker has their own site that they can get you to talk to but is unable to interfere with your connections to legitimate sites. Due to the complexity of the Web, there are still a number of attacks in this setting. Moreover, now that HTTPS use has become so common and most traffic is encrypted (and browsers have banned mixed content) the Internet and Web threat models have basically merged.
In order for the Web to work successfully, people have to feel comfortable visiting arbitrary Web pages, even those controlled by the attacker. It's the browser's job to mediate that interaction so that it's safe. Back in 2011, my coauthors and I described this as the "core security guarantee" of the Web: users can safely visit arbitrary web sites and execute scripts provided by those sites.
Just to reinforce this point, in this threat model the Web site is the attacker. You can come in contact with a malicious site in several ways:
-
An active attacker on your network can pretend to be a Web site you are trying to go to. This is less common now with the rapid increase of encrypted connections in the form of HTTPS, but it's still reasonably common for people to visit a small number of unencrypted sites.
-
You can be lured in some way to a malicious site, for instance by an ad campaign, phishing, or just visiting the wrong link.
In this series, we are not primarily concerned with network attacks. First, this is supposed to be prevented at a lower layer, specifically, via HTTPS (modulo phishing). Second, if you have an insecure connection to your bank, then the attacker can tamper with your requests to do whatever they want. Instead, we're primarily interested in cases where the attacker gets you to visit their site and uses that as a foothold to attack your computer or your interaction with the bank.
This leads to the following set of requirements:
-
A malicious site won't be able to compromise your browser or your computer.
-
A malicious site won't be able to see or interfere with your interaction with other sites. For instance, if you have Gmail in one tab you don't want an attacker in another tab to be able to read your emails.
This series of posts is mostly about the second category of attacks. Making networked programs secure against arbitrary input is a serious problem, but one that's not unique to Web browsers, so we can take it up at a different time.
Motivation: Cookies and Ambient Authority #
One of the problems with writing these posts serially rather than all at once is that sometimes you find there is something you wish you had explained earlier that now you can't go back and do. This is one of those times. In Part II, I explained how to use cookies to implement a shopping cart, but another of the main uses of cookies is to persist authentication. This is something you experience every time you use a Web site that uses authentication: the first time you go to the site, it detects you aren't logged in and gives you a login prompt. On subsequent visits, though, it just remembers who you are.
This works in more or less the way you would expect, shown in the figure below:
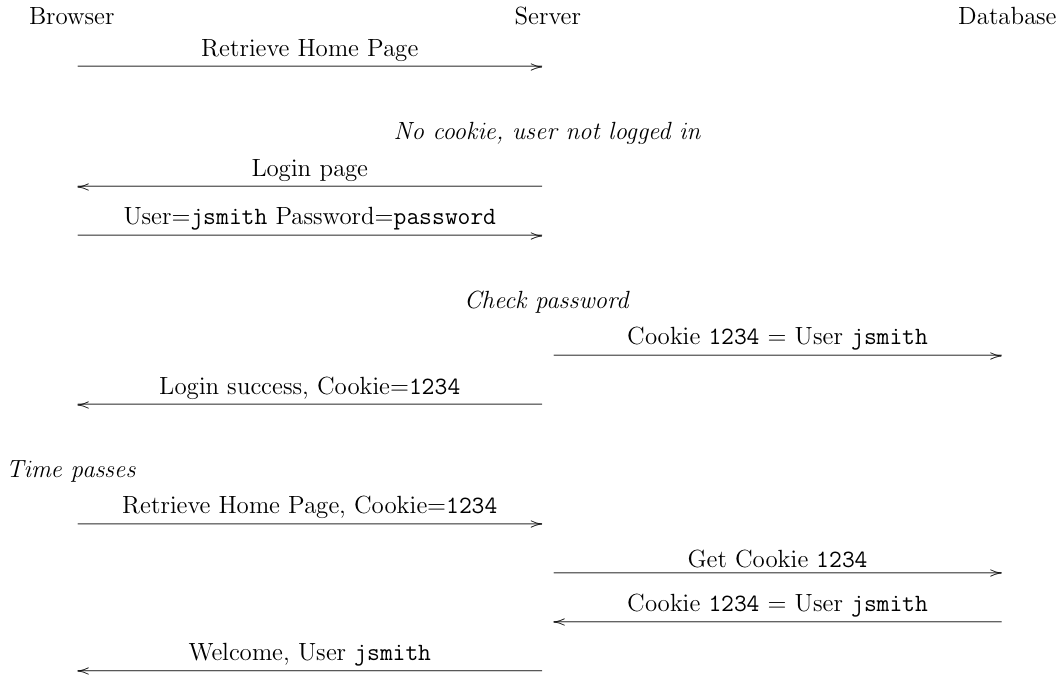
Initially, when the user goes to the site, they have no cookie. The site notices this and sends them a login page with the usual username and password prompt. The user enters their password (presumably in a Web form) and the browser sends it to the server. The server checks the password. Assuming the password is correct, the server generates a new cookie, stores it in the local authentication database along with the user identifier, and then returns a success page to the user along with the cookie. The next time the user visits the site, their browser sends along the cookie. The site can then look the cookie up in the database and if successful it knows who the user is and can present an appropriate page. In reality, this doesn't happen just on subsequent visits, but during the same visit. Whenever the user clicks on another link, or even loads an image off the site, the cookie is used to authenticate them; the password is just used to authenticate the user long enough to set the cookie.
It's important to realize that from this point on, the cookie is the only thing authenticating the user to the site. In effect, the cookie is a new password that's created by the site and just handled by the browser rather than remembered by the user. Anyone who has access to the cookie is effectively the user (the technical term here is a bearer token, which means that anyone who has a copy of the token can impersonate the user). This means that the cookie has to be (1) unguessable and (2) be kept secret (this is where encryption comes in, as we'll see later).
Now here's where things start to get complicated. If you remember
the discussion of online advertising in Post III,
cookies get sent whenever a resources is loaded, regardless of
the site where the resource is being loaded from. For instance,
suppose that you have a picture on a photo site which is available
only to certain people who are logged into the site. If the
URL isn't secret, a site can embed an <img> tag pointing
to the picture and it will be shown on the site. In general,
this applies to any request made by the browser, no matter how
it is triggered. This property
is called ambient authority.
As I've just described it, this sounds really bad: any site can just load access-controlled material off of any other site, and would obviously violate the second half of the guarantee above. And if that were the whole story it would indeed be bad. What makes this all work is a set of rules called the same-origin policy that dictate that while a site can load the content from another site and show it to the user, it can't read the content. This is a powerful tool, but in practice a very tricky one to use correctly, as we'll be exploring in some detail.
The Same-Origin Policy #
The same-origin policy (SOP) is the collective name for a large-ish set of rules about how browsers behave in cross-origin situation. These rules have gradually evolved over time . In an important 2006 paper[1] on Web privacy, this, Jackson, Bortz, Boneh, and Mitchell describe it as follows (under the name of "same-origin principle"):
Only the site that stores some information in the browser may later read or modify that information.
First, however, we must define what we mean by a "site". As described in the previous two posts, any given Web page is often composed of resources from multiple servers, with each resource being retrieved via a URL. Obviously, we don't want all of these resources to be isolated from each other because we want them to work together to provide a unified experience. So, we need some concept of "the same site" that is different from just the URL. This concept is given by the origin.
Recall the structure of the URL from post I:

Risks of Including Paths in the Origin #
One interesting detail is that the path component is not part of the
origin, so https://example.com/abc and
https://example.com/def are in the same origin.
There's an obvious reason for this, which is that Web
sites frequently consist of multiple paths and you
want them to share cookies and state. However, it used
to be fairly common to have several people share a given
server, for instance by having Alice have her home page at
https://example.com/~alice/ and Bob have his
site at https://example.com/~bob/. Unfortunately,
this has some problematic security properties. For
instance, it's possible to scope cookies to a given
path prefix, but if Alice sets a cookie, Bob can
read it by injecting script into the page. For more on
this class of problems, see the classic paper
"Beware of Finer-Grained Origins"
by Adam Barth and Collin Jackson.
The origin of a piece of content retrieved by a URL is defined by the following three values:
- scheme: e.g.,
http:orhttps: - host: the domain name of the server
- port: the TCP or UDP port number that the server is listening on
In order for two origins to be the same, all three values must be the same.
We've covered scheme and host before, but what's a port? Internet hosts are addressable by IP address, but what if you want to run multiple services on a given machine, such as mail and Web. This is handled by having a second layer of addressing: the port, which is just a 16-bit number carried in the transport porotocol. You can have a large number of different services on a server, each addressed by a separate port (the technical term here is that you are multiplexing multiple services on the same IP and the port is used to demultiplex them). Traditionally, each protocol has a fixed port number (HTTP is 80, HTTPS is 443, e-mail transmission (SMTP) is 25). However, nothing stops you from running services on other ports; you just need some way to tell the other side what port to talk to. In URLs, this is done by appending a colon and the port number.
Here are some examples of URLs and their associated origins:
| URL | Scheme | Host | Port |
|---|---|---|---|
http://example.com |
http |
example.com |
80 |
http://example.com:8080 |
http |
example.com |
8080 |
https://example.com |
https |
example.com |
443 |
Notice that in the first and last examples, the port isn't provided: HTTP has a default port value of 80 and HTTPS has a default port value of 443. In the second example, the port (8080) is explicitly provided. As a practical matter, nearly all Web traffic runs on the default port, though it's common to use other ports for development purposes.
It's important to note that the path is not part of the origin. So, for instance, these URLs have the same origin (See MDN for some more examples, as well as examples of some edge cases.)
https://example.com/index.htmlhttps://example.com/~ekr/homepage.htmlhttps://example.com/js/scripts.js
As I mentioned above, this allows them to work together to provide a unified experience (though see below for some special considerations for JavaScript).
In general, if two resources have the same origin, then they can share information. However, if A and B are from different origins, then their interactions are going to be fairly limited.
Reading/Writing Other Resources #
First let's look at the example I used above: a page from origin A
loading an image from origin B. The SOP requires that A be able to see
the content if and only if A has the same origin as B. If A and
B are from different origins then I can only learn if it was
loaded but can't see the actual content.
The way you read the content of an HTML <img> tag is
by drawing it on a Canvas
element and then reading the data back with getImageData(). The following
JavaScript snippet does that and then writes the resulting value
below the image:
function onloaded(el) {
let canvas = document.createElement("canvas").getContext("2d");
canvas.drawImage(el, 10, 10);
let pixelvalue = null;
try {
let imgdata = canvas.getImageData(0, 0, 1, 1);
pixelvalue = imgdata.data[0];
} catch {
pixelvalue = "forbidden";
}
el.parentElement.appendChild(document.createTextNode("URL=" + el.src + " pixel=" + pixelvalue));
}By setting the onload property on the image element, we can arrange that this function runs whenever the image is loaded. Below you can see the results with two images, the first loaded from this site, and the second loaded cross-site.


As you can see, in both cases you can tell when the image was loaded (because the
function gets called) and get some basic
information like the URL (and the width and height). However, when we try
to actually access the image data, call to getImageData() only works
with the same site image, producing the pixel value
[211, 196, 173, 255],[2]
but fails with the cross-site image, producing
the result "forbidden". This is
the same-origin policy at work. The same thing applies to other elements
that you load cross-origin like this, for instance audio files or videos.
It also applies if you load another Web page in an IFRAME or in another
tab. If the page is same-origin, then you can access the DOM of that
page, but if it's cross-origin you cannot. In addition, same-origin
IFRAMEs or pages can access the original page.[3]
Note, however, that the containing site can write to a cross-site element, or rather, it can replace them with other elements. This makes sense, because even though the site can't read the element it ultimately controls the DOM that the element appears in, so it can just replace it with something else, as in the following code snippet, which just swaps the image element below between two images whenever you click:
var onclickimageindex = 0;
const images = [
"/img/ekr.jpg",
"https://www.rtfm.com/ekr-ud.jpg"
];
function imageonclick(el) {
onclickimageindex++;
el.src = images[onclickimageindex%2];
} What About JavaScript? #
But if cross-origin resources can't access the DOM, then how is it
that you can load JavaScript libraries off of other sites, which, as I
mentioned,
people do all the time? The answer is that when you load JavaScript
into a site with a <script> tag, that JavaScript runs in the
origin it was loaded by not the origin it was loaded from. For
instance, if a page loaded from https://educatedguesswork.org
pulls in a script from https://example.com that script has the
same privileges as if it were loaded from
https://educatedguesswork.org/ and can do anything one of those
scripts can do.
It's important to recognize that an attacker who can run script in a
site's security context effectively controls that site from the user's
perspective. Because scripts can manipulate the DOM, they can make the user
see anything they want. They can access locally stored state
and can often access cookies (via the document.cookie variable.).
They can't directly access the user's password, but they can prompt
the user to retype it and the user will likely do so; a password
manager cannot protect you here because they determine what password
to show based on the site's origin. Being able to run script on a
site is very nearly as good as intercepting all communications between
the client and the site.
Mixed Content #
Because imported JavaScript is so powerful, it's critical to ensure
that the right script is loaded: an attack on imported JavaScript
is nearly the same as an attack on your site.
Suppose that ExampleCo serves example.com over HTTPS, but
that site imports JavaScript from http://libraries.example.
This situation is called mixed content (because you are mixing secure and insecure content).
In this case, even though a network attacker cannot directly attack
example.com, they can attack the JavaScript from http://libraries.com
and through that JavaScript control how the browser renders example.com.
In other words, this is barely better than having the original
site served insecurely.
Mixed content used to happen quite frequently: if you wanted to upgrade your insecure site to HTTPS, you might find that some of your dependencies were insecure; the easiest thing to do was just accept the situation. Eventually, as HTTPS became more common, browsers started blocking active mixed content (like JavaScript), loading the original page but just generating a network error when it tried to load the insecure content. This obviously broke some sites which still depended mixed content, but also protected users from attack on those sites (and in some cases, the site would still work correctly).
Compromised Dependencies and Subresource Integrity #
Another form of attack on cross-origin JavaScript—or really any included JavaScript—is attack on or by the site hosting the script. Suppose that your site depends on a JavaScript library like jQuery but loads it off the jQuery CDN rather than hosting it locally. If the jQuery CDN—or the jQuery distribution itself—is compromised, then the attacker can serve malicious JavaScript and subvert the user's experience of the site. This works even if the connection to the CDN is encrypted, because the problem is a compromised endpoint, not a network attacker.
The W3C has standardized a technology called
Subresource integrity (SRI) which is intended
to prevent this type of attack. The idea behind SRI is that
the <script> tag loading a piece of JavaScript includes
a cryptographic hash of the expected result. When the browser
loads the resource, it checks the hash and generates an error if
it doesn't match. For instance, here is a lightly modified
example from the SRI spec:
<script src="https://example.com/example-framework.js"
integrity="sha384-Li9vy3DqF8tnTXuiaAJuML3ky+er10rcgNR/VqsVpcw+ThHmYcwiB1pbOxEbzJr7">
</script>In theory, SRI solves the problem of compromised subresources, but in practice deployment has been fairly slow. One likely reason for this is that coordination is difficult: the site author must somehow learn the hash of the JavaScript library they are loading, and it's just one more thing to go wrong. At present most sites (this site included) which depend on external JavaScript—which is a huge fraction of the Web because of advertising and tools like Google analytics—are just dependent on the security of the external servers which host those scripts.
Cross-Origin Requests (and Cross-Site Request Forgery) #
As noted above, the SOP allows site A to make requests to site B but not read the responses. Unfortunately, this still allows for attacks. The basic problem here is the combination of cross-site requests under control of the attacker with ambient authority provided by cookies. Suppose that there is a shopping Website such as the one we described in part II. If the attacker knows that you have logged into the site and can get you to visit their site, they can force you to make purchases on the shopping site, as shown below:
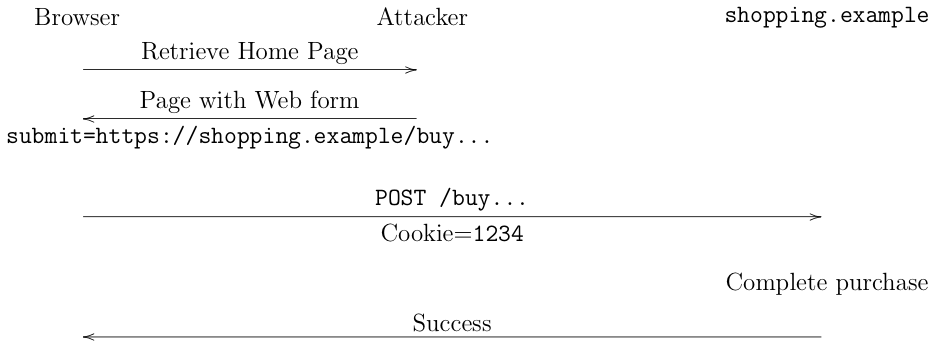
The way this works is that when you visit the attacker's site, they serve you an HTML page with an element that causes the browser to make a request to the shopping site's server to buy something; that request is the same message that the browser would have sent if you were on the shopping site's page and comes along with the user's cookie (ambient authority, remember?). This all looks fine and the site just goes ahead and executes the purchase. This is called a *Cross-Site Request Forgery (CSRF) attack.
It's worth mentioning a few fine points. First, why am I using
an HTML form here? The reason is that many (most?) sites use
the HTTP POST method for requests that are supposed to
have side effects, such as buying something.
[4]
Most of the HTML elements that result in a cross-origin
load use the GET method, but forms allow you to use
POST. You can also use JavaScript methods to make this
kind of cross-origin request, but the situation is somewhat
more complicated, so I'm going to get to it later when
I talk about Cross-Origin Resource Sharing (CORS).
Second, it's possible to make this operation automatic and invisible to the client: even though form submission usually results in navigation events, you can put the form in a hidden IFRAME so the user doesn't notice the event. Similarly, you can use JavaScript to trigger the form submission so that it happens automatically on loading the page.
Obviously, CSRF is a serious attack, and we'd all be in trouble if it were regularly possible to mount CSRF attacks on (say) Amazon or (worse) Wells Fargo. The most basic CSRF defense is to use what's called a CSRF token. The idea is that when you access the legitimate site, it adds a random token to every HTML element corresponding to a request which would generate side effects. For instance, if it gives you a link to add something to your shopping cart, that link might have a random token at the end. Then, when your browser dereferences the link to add the item, it sends along the token; the site checks it and only takes the action if the token is correct. Because the CSRF request the attacker induces doesn't have the token, it will be rejected.
It's worth taking a moment to think about how this defense works: effectively, it's a check on ambient authority. ordinarily, requests are authenticated just by having the cookie but because of CSRF that's not good enough; the token restores the concept of the provenance of the request. In order for it to work properly, the token has to be (1) unknown to the attacker and (2) tied to the user (presumably via the cookie). If it's not tied to the user, the attacker will just go to the site themselves, retrieve the token, and give it to the user's browser on their page.
One very important property of CSRF tokens is that they work with every browser because they don't depend on any new browser feature. Over the years a number of such features have been introduced to make CSRF harder, but any new feature takes time to propagate throughout the entire user population. This is a general problem with Web security. When a new attack like CSRF is discovered, sites need to be able to protect themselves immediately and so defenses which don't require client side changes are strongly preferred and can't be relaxed until effectively the entire user population has upgraded to the new client-side defenses.
There is some good news on this front, however. As I noted above, this is a consequence of the fact that
cookies are sent both in the situation where the resource
is on the same site and where the resource is on a different
site. Arguably this is a misfeature in HTTP, and so one fix is to
simply have cookies only apply to same site resources.
This is the idea behind SameSite cookies.
When you set a cookie, you can add the SameSite label with a cookie
to say whether it can or cannot be used for cross-site resources.
Recently, browsers have started to default cookies to SameSite=Lax,
which is intended to prevent cookies being used in contexts which would
enable CSRF. Once those browsers become ubiquitous,
sites should finally be able to deprecate CSRF tokens.
Next Up: Cross-Origin Resource Sharing #
The same-origin policy is a fairly blunt—albeit complicated—instrument. There are times when you would like to do cross-origin requests that also carry authentication and actually be able to see the data. In the next post, I'll be talking about a mechanism designed to allow that: Cross-Origin Resource Sharing (CORS).
This paper is actually quite entertaining reading, as it describes many tracking techniques we see in use today, such as bounce tracking. In addition, Section 1 starts with "The web is a never-ending source of security and privacy problems. It is an inherently untrustworthy place, and yet users not only expect to be able to browse it free from harm, they expect it to be fast, good-looking, and interactive — driving content producers to demand feature after feature, and often requiring that new long-term state be stored inside the browser client" ↩︎
The four values are R, G, B, and alpha. ↩︎
Technical note: in order for this to work, you need the two pages to have a handle to each other. This happens if page A was opened by page B with
window.open()or if page B is an IFRAME on page A. ↩︎The HTTP spec spec strongly discourages using GET in contexts that have this kind of user-visible side effect "Request methods are considered "safe" if their defined semantics are essentially read-only; i.e., the client does not request, and does not expect, any state change on the origin server as a result of applying a safe method to a target resource. Likewise, reasonable use of a safe method is not expected to cause any harm, loss of property, or unusual burden on the origin server." ↩︎