End-to-End Encryption and the EU's new proposed CSAM Regulation
Posted by ekr on 19 May 2022
Last week the European Commission published a new "Proposal for a Regulation laying down rules to prevent and combat child sexual abuse". This regulation would require Internet communications platforms to take various actions intended to prevent or at least reduce what it terms "online sexual abuse".
Proposal Summary #
The proposed regulation runs to 135 pages and is somewhat light on detail, but here's a brief summary of the most relevant points (with the disclaimer that I am not a lawyer).
-
Requires all "hosting services and providers of interpersonal communications services" to perform a risk assessment of the risk of use of their service (Article 3) for online sexual abuse and to take "risk mitigation" measures (Article 4), said measures being required to be "effective in mitigating the identified risk".
-
Allows the "Coordinating Authority" of a member state to issue a "detection order" (Article 7) which would require the service to set in place technical measures that are "effective in detecting the dissemination of known or new child sexual abuse material or the solicitation of children, as applicable" (Article 10(3)(a)) based on indicators created by a new EU Centre.
-
Creates a new EU Centre which will develop technologies for detecting the above types of content and make them available to providers as well as generating indicators of contraband content (Article 44).
-
Impose various transparency and takedown requirements on providers, for instance requiring them to block/takedown specific pieces of content.
It's a bit unclear to me what the line is being required to have measures that are "effective in mitigating the identified risk" versus "effective in detecting the dissemination of known or new child sexual abuse material or the solicitation of children", but I would expect that any significant-sized service is likely to be served with a detection order, given that the standard for issuing the orders, as set out in Article 7 (4) is that "there is evidence of a significant risk of the service being used for the purpose of online child sexual abuse", which is probably the case for any major service, just because there is so much traffic; even if detection were perfect—which it isn't—there would always be new users wanting to exchange prohibited material. For that reason, it's probably most useful to focus on the implications of the detection order requirement.
Technologies for Detecting Online Sexual Abuse #
This proposal is concerned with three main types of material:
- Known child sexual abuse material (CSAM).
- New CSAM that hasn't before been seen.
- Solicitation of children
The standard techniques for detecting known CSAM mostly depend on perceptual hashing, in which we compute a short value that is characteristic of the image (or video). You start with a database of known CSAM objects and compute their perceptual hashes. The idea is supposed to be that:
-
If two images look "the same" then they will have the same hash, even if they are slightly different. For instance, a color and black-and-white version of the same image.
-
If two images are "different" then they will have different hashes with very high probability.
Note that this is different from cryptographic hashing because similar looking images will have the same hash, whereas with a cryptographic hash even a single bit difference should produce a new hash. In order to scan a new piece of content you compute its hash and then look up the hash in the table of known hashes. If there's a match, then the content is potentially CSAM and you take some action, such as alerting the authorities. (see here for some limitations of this kind of system).
Hashing doesn't work for unknown images, however, because you won't have their hashes, and won't work for detecting text messages and the like that are designed to solicit children. The state of the art for detecting this kind of material is to train machine learning models ("classifiers") that attempt to distinguish innocuous material from contraband. This kind of technique is already in wide use for spam filtering, but there are also technologies like this that attempt to identify CSAM and solicitation; as I understand it, these technologies are already in use in some systems.
Traffic Encryption #
Most services do encrypt traffic, but often it's only in transit between the client and the server, which doesn't prevent the service from doing any analysis on it they want. You'll also often hear that services store data encrypted, but that usually just means it's encrypted with keys they know. This isn't worthless: it migh protect you if someone steals one of their hard drives, and depending on things are built might make certain forms of inside attack difficult—for instance if administrators can't get the keys—but doesn't do anything to get in the way of the service itself inspecting your data.
It's important to recognize that these technologies require having access to the content itself, whether to compute the hash or to run the classifier. If you have a system where the service sees the data in plaintext, then this is straightforward, but if the data is end-to-end encrypted, meaning that that service doesn't see it, then life gets more complicated, by which I mean "there isn't really a good solution".
Content Filtering on Encrypted Data #
The obvious way to address the problem of content filtering on encrypted data is just not to encrypt it, but of course this has a very negative impact on the security of people's communications (see my previous post on E2EE and encrypted messaging for more on this), and so there has been quite a bit of work on content filtering with encrypted data. The EU proposal relies heavily on an EU-sponsored Experts Report (see Annex 9 of their impact analysis) describing their analysis of the situation and making some recommendations. I'll address this report below, but at a high level, there are two main approaches:
- Filter on the client and report results back to the server.
- Filter on the server or some other central point.
However, neither of these really works very well, for reasons I'll go into below.
Client-Side Filtering #
Aside from just not encrypting at all, the obvious solution is to have the client filter the data; after all, it already has the plaintext. However, there are a number of challenges to making client-side filtering work in practice.
Algorithmic Secrecy #
The first major challenge for client-side filtering is the desire to keep the algorithms used to determine whether to flag a given piece of content should be secret. For instance, many server-side filtering systems use a perceptual hashing technology called PhotoDNA. Although the general structure of the algorithm is known, the precise details are secret. In addition, the hashes themselves are secret.
{kind=link}
As far as I can tell, there are two major reasons for this secrecy. The first is that it's intended to deter evasion. If you have the hash algorithm and the list of hashes, then you can check for yourself whether a given piece of content is on the list and either avoid transmitting it or alter the content so that it has a a different hash that's not on the list. Even if you just know the hash algorithm and you have a piece of content that might be on the list, you can easily alter the content so that it has a different hash, thus reducing the chance of detection. Or, in the case of a detector for solicitation, the client might warn the user to cut off the conversation when the classifier score got too high.
If the algorithm is secret, it's harder to know if two slightly different inputs will have the same hash (recall that the idea of a perceptual hash is that visually similar inputs produce the same hash), but if you know the algorithm, it's trivial. It's also possible to go in the other direction, where you generate a piece of innocuous content that matches a hash and send it to someone to "frame" them. This is much easier if you know the hash.
The second reason is that it might be possible to use the hashes themselves to reconstruct a low-res version of the original image, which would obviously be undesirable, as it would mean that distributing the hash database was kind of like distributing a low-fi version of the original images with an unusual compression format.
Apple's proposed client-side CSAM scanning system (see my writeup here) partly addresses these issues by using advanced cryptographic techniques to conceal the hash list from the client. Briefly, the way this works is that the service provides the client with an encrypted copy of the hash database. The client computes a "voucher" based on the content and the hash database, and sends it to the service, but the service can only decrypt the voucher if the content matched one of the hashes. This prevents the client from knowing whether their content matched a hash but actually requires the client software to know the hash algorithm, which they have to be able to compute locally[1] so it would still be possible for an attacker to change content so it has a different hash.
Moreover, Apple's system only works for known hashes, and it's not known how to extend it to the problem of having a client-side classifier that is itself secret (unlike NeuralHash). As we'll see later in this document, the need to run arbitrary computation rather than just hash matching makes this whole problem space a lot harder. It's maybe possible you could use some kind of encrypted computation solution in which some server ran a classifier on an encrypted copy of the content and then told the client whether it was contraband, but then we'd have the problem that the client could use the server as an oracle for whether a given piece of content was OK, which, as noted above, is undesirable.
Client Nonconformance #
The other major problem with executing the classifier on the client is that there's nothing requiring the client to actually run the classifier on the true input, or on any input at all. For example, in the Apple system, the client sends an (image, voucher) pair up to iCloud but there's nothing in the system that forces the image to match the voucher.[2] Instead, the client can just compute a voucher on an innocuous image (in the Apple system, it can actually just produce a random voucher, but one might imagine a different design where that was not possible) and upload that voucher along with the image.
The major barrier to this kind of attack is how inconvenient it is for the user—who recall, is the attacker in this system—to run a nonconformant client. Of course, if you're using an iOS device, then you're running Apple's software, which is designed to behave correctly, and it's a pain to replace it with your own (though nothing like impossible), and in any case, this isn't a generic solution to the problem of tens to hundreds of apps, including those which run on systems much less locked down than iOS (including MacOS). This problem is much worse for "open" systems in which the protocols are public or in which the clients are open source because in those systems anyone can build their own client that interoperates with the system but doesn't correctly run the classifier (i.e., it lies!), which makes the system far less useful. Of course, some people will still use the default client, but in many of the scenarios of interest, people know that they are sending contraband and so will be willing to use custom tools that evade filtering, in which case almost any system other than having the client send the data in the clear won't work.[3]
Server-Side Filtering #
The other set of the designs use a server for filtering ("don't encrypt" is the trivial version of this). Similarly, you could send a copy of the data (or, in the hash version of the system, a copy of the hash) to some "trusted" server which does the filtering. The nominal advantage of such a design is that the service provider (e.g., WhatsApp) can't see your data (or the hash) but of course this third party would and it's not clear how that's better, as it comes down to trusting some server operated by someone you don't know not to spy on you.
The EU Experts Report[4] proposes two fancy cryptographic mechanisms for addressing this problem:
-
Having the client upload encrypted hashes and use multiparty computation (MPC) to determine whether one of the hashes matches.
-
Using fully homomorphic encryption (FHE) to compute the perceptual hash over the content and determine if it matches the hash list.
As far as I can tell, the encrypted hash/MPC design is inferior to Apple's proposal in that it's more complicated and still only does hashes. The EU report frames the FHE system as being about hashes, but if it works at all, I think it's likely to work with classifiers too, because it involves the server running am arbitrary computation. With that said, it's also not clear to me how it's intended to work. Here's the diagram from their report:
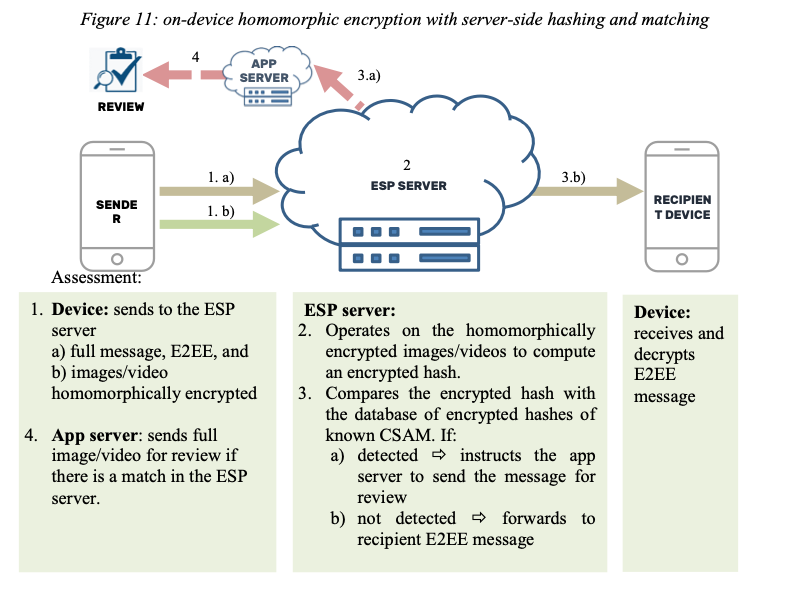
FHE is a bit outside my main area of expertise, but I'm having trouble making sense of this. The point of homomorphic encryption is that you can perform a computation on encrypted data. In the typical FHE setting, the client encrypts the data and sends it to the server which operates on the encrypted data and returns the result, as shown below:

Partially Homomorphic Encryption #
It's been known for a very long time how to do partially homomorphic encryption. As a concrete example, consider the case where you encrypt some data by XORing it with a key, i.e.,
$$Ciphertext = Plaintext \oplus Key$$
With this system, you can have the server compute the XOR of two plaintexts, $P_1$ and $P_2$ The client sends:
$$ (C_1, C_2) = (P_1 \oplus K_1, P2_2 \oplus K_2)$$
The server returns:
$$ C1 \oplus C_2 $$
Which the client XORs with $K_1 \oplus K_2$, i.e.,
$$P_1 \oplus K_1 \oplus P2_2 \oplus K_2 \oplus K1 \oplus K_2 $$
When you cancel out the keys ($A \oplus A = 0$) you get:
$$ P_1 \oplus P_2$$
The difference between partially and fully homomorphic encryption is that with a partial homomorphic system you can compute some functions on encrypted data but not others. With a fully homomorphic system you can compute any function, whereas this system is homomorphic with respect to XOR but not (say) to multiplication. The problem of fully homomorphic encryption had been open for a long time until Craig Gentry finally showed how to do it in 2009.
The idea here is that the client has some input that it wants some expensive computation done on. It could just run the computation in some cloud service like AWS but it doesn't want the cloud service to see the data. Instead, encrypts the data and sends the encrypted version to the server. The server then performs the computation on the encrypted data, but without seeing the data (ordinarily this would not be possible but there is some extremely fancy math involved). The computation is structured so that the server doesn't get to see the result but just an encrypted version of the result, which it sends back to the client. The client then decrypts the result and learns the answer.
What makes this use of of FHE weird is that the response doesn't go back to the client but rather the server somehow sees an encrypted hash that it compares with a list of other encrypted hashes, which doesn't seem to be the customary FHE setting. It's possible I'm missing something, but as described, it seems like this design would allow the server to learn the actual content, not just whether it matches a given hash. The issue is that the server determines the algorithm that it runs on the encrypted data, and so it can design an algorithm that allows it to extract the data. For instance, suppose you have an algorithm that looks at a single pixel of an image and emits:
- The hash of a known piece of CSAM if the image is black.[5]
- A random value if the image is white.
You then run the algorithm in sequence over each pixel of the image at a time and you've extracted the content (assuming it's black and white).[6] You could obviously extend this technique to be more efficient, or to work on text, etc.
It's possible that the design of the system might be able to somehow restrict the algorithms that the server can run—though usually homomorphic encryption does so at a lower level, like that you can only multiply but not add—but that restriction would have to be enforced by having the client encode data in a certain way, such that it was just partially homomorphic. This seems impractically inflexible, especially in light of the fact that we don't just want the server to compute perceptual hashes but to run generic classifiers, which tend to be fairly complicated systems, and that they are supposed to be based on whatever indicators are provided by the EU Centre. Restricting the classifier algorithm by controlling the inputs seems even more problematic if you want to keep it secret from the client, which, as noted above, is important for preventing evasion; if the client wants to evade and knows that only certain classifiers can be run, it can tune its content to evade those classifiers.
You could of course build a more traditional FHE-style system in which the server just told the client whether the content had been flagged, and count on the client to report the user. However, with that design, you're telling the user whether they have been flagged, which, as above, is undesirable, and you still have to worry about client nonconformance (i.e., just ignoring that the user was flagged). If the response is encrypted, then the server has no way of knowing that the client is behaving correctly.
I should also mention at this point that even the piece where you build the classifier using homomorphic encryption is kind of a research problem, as stated in the report:
Another possible encryption related solution would be to use machine learning and build classifiers to apply on homomorphically encrypted data for instant classification. Microsoft has been doing research on this but the solution is still far from being functional.
The bottom line here is that I don't think we're at the point where fancy crypto is going to help. Even if it's possible in principle to build something that allows the server just to tell if something is contraband without seeing the content (which is far from clear), it's not practical do do so with our current cryptographic tools.
Trusted Execution Environments #
One approach that has recently become popular for dealing with this kind of complicated trust problem—especially when it feels too hard for crypto—is to use what's called a Trusted Execution Environment (TEE) or an "enclave". A TEE is a processor feature that allows the operator of the processor to run computations on data without being able to see the data.
The basic way a TEE works is that:
- The processor manufacturer installs a signing key when the processor is manufactured. This key is signed by the manufacturer's key.
- The TEE internally generates a secret encryption key pair.
- The operator installs a program onto the TEE.
- The TEE then signs a statement (using the signing key) that attests to the program and to the public half of the encryption key pair.
The operator can then send this statement to someone else who knows that (1) they are interacting with the TEE rather than with the operator and (2) precisely what program the operator is running on the TEE. That someone else verifies the signature chain and compares the program to its expectations.
It's easy to see why a TEE is attractive, as in theory it ought to offer a generic solution to a huge number of privacy and security problems: there's no fancy crypto to be concerned with, you just write your program to do whatever you want and shove it in the TEE. You do have to be a little (well, more than a little) careful to write the program on the TEE so it doesn't leak information about the data its operating on via side channels and the like (remember what I said about the difficulty of safely computing on secret data), but one might hope that that's a problem that could be solved with the right programming practices and then you just have a magic box that securely executes any program you want.
Given such a box, the problem becomes a lot easier. For instance, the EU report suggests that the client send the encrypted messages to the TEE along with the encryption keys , which would run whatever filtering algorithms were needed on it and then either forward the encrypted message (if it was OK) or would report a violation (if it was not). You could also use the TEE to run filtering on the client because you could run the classifier secretly in the TEE without disclosing it to the user. (You won't be surprised to hear that one of the big uses of TEEs is for DRM for media.) Running a secret classifier is somewhat tricky, but you might imagine a system in which the classifier was revealed to some set of experts who would then attest that it was OK and publish a hash of it that clients could check.
There's just one tiny problem: TEEs are a lot less secure than one would actually like. There is a whole line of papers attacking the best-known TEE, Intel SGX (see here for a survey). Moreover, these attacks are all based on running code on the processor, which is a fairly weak form of attack. However, they generally don't provide defenses against physical attacks in which someone who has physical control, in part because this is hard to do in processor-sized package.[7] For instance here's what Intel says:
Side-channel attacks are based on using information such as power states, emissions and wait times directly from the processor to indirectly infer data use patterns. These attacks are very complex and difficult to execute, potentially requiring breaches of a company’s data center at multiple levels: physical, network and system.
Hackers typically follow the path of least resistance. Today, that usually means attacking software. While Intel® SGX is not specifically designed to protect against side channel attacks, it provides a form of isolation for code and data that significantly raises the bar for attackers. Intel continues to work diligently with our customers and the research community to identify potential side-channel risks and mitigate them. Despite the existence of side-channel vulnerabilities, Intel® SGX remains a valuable tool because it offers a powerful additional layer of protection.
The problem here is that this is very high value data and so you have to worry about very motivated attackers. For instance, in the server-side TEE system described in the EU report, the TEE would effectively have access to the plaintext of everyone's messages, which means that any effective attack on the TEE breaks E2EE and enables universal surveillance by the server. Given the history of successful attack on systems like this, assuming that it cannot be broken even given the resources of a state-level adversary who wants to read everyone's communications seems unreasonably optimistic.
Finally, the whole security of a TEE system relies on the processor manufacturer not cheating, but those processor manufacturers are big companies, so users also have to worry about the manufacturers being compelled to assist in surveillance, for instance by signing a processor key for a processor which didn't actually provide the TEE security functions.
Algorithms and Systems Design #
Even if we ignore the security pieces, this is still a hard problem. Although automated content scanning is widely employed, these systems routinely misclassify data, which is why you still get spam messages in your mailbox even with best-in-class spam filters and why any big content system has to employ—or more likely subcontract—an army of humans to manually go through stuff that's been flagged by their algorithms. How well these algorithms work seems to vary a fair bit depending on what they are asked to do, and the EU impact analysis is fairly light on details:
Thorn’s CSAM Classifier can be set at a 99.9% precision rate. With that precision rate, 99.9% of the content that the classifier identifies as CSAM is CSAM, and it identifies 80% of the total CSAM in the data set. With this precision rate, only .1% of the content flagged as CSAM will end up being non-CSAM. These metrics are very likely to improve with increased utilization and feedback.
This 99.9% number is reported as "Data from bench tests". Thorn itself reports a 99% number, but doesn't provide details of how the tests are conducted.
By contrast, the problem of classifying "solicitation" seems to be much harder. The EU references some work by Microsoft and says "Microsoft has reported that, in its own deployment of this tool in its services, its accuracy is 88%.".
Reporting Test Accuracy #
I just want to take a moment here to complain about the way these numbers are being reported, which is really confusing. Any given test has two types of errors:
-
false positives in which you report a positive test (in this case a violation) when there is none.
-
false negatives in which you report a negative test (in this case no violation) when there is one
The typical way to report these is just like that. I.e., the false positive rate is the fraction of positives you would get if you performed tests on inputs which were truly negative. For example the iHealth COVID test "correctly identified 94.3% of positive specimens and 98.1% of negative specimens", which means that if you are negative, there is a 1.9% chance the test will report positive.
It's important to recognize that this is number is different from the fraction of positives which are actually negative, because that number depends on the population you are testing. For example, if you went back in time and administered COVID tests to people in 2010, then every positive test would be a false positive because nobody had COVID. The lesson here is that the use of a test is dependent on the properties of the population in which its being used; even a very accurate test can have a lot of false positives—to the point where most of the positives will actually be false positives—if the number of true positives is very low (see Schneier on the base rate fallacy).
Conversely, it's not possible to determine the accuracy of a test by reporting the fraction of errors without knowing the sample it was tested on. For instance, I could have a CSAM filter test that just reported "is CSAM" for everything and if I tested it only only CSAM inputs, it would look to be 100% accurate, even though it's obviously useless. So in this case, that 99.9% number on bench tests is useless without knowing the set of inputs it was tried on. The 88% number is even worse because "accuracy" could mean anything, and I wasn't able to find anywhere where Microsoft reported their own research.
Without this kind of information we can't tell how effective a system like this will be. Only a tiny fraction of the content on the Internet is CSAM or solicitation, and so even a very accurate filter is still going to produce a large number of false positives. Knowing about how many there will be is critical to understanding the practical effectiveness of this kind of system.
Manual Review #
As noted above, the possibility of false positives usually means that you need manual filtering as a backup. In a system without end-to-end encryption, this is straightforward: you already have the data because you ran a filter on it, so you just send a copy to whoever is doing the double checking.
If the data is end-to-end encrypted, however, the problem becomes much harder, because—with the exception of the TEE-type systems, which have other problems—the server doesn't have the data in the clear, so it needs to obtain either the encryption keys for the content or the content itself. The Apple system solves this problem automatically but as I mentioned above, it only works for hash matching, not for general classification algorithms. Of course, if the classifier shows a positive result, the server can always ask the client to send a copy of the plaintext, but then this isn't secret from the client, and of course a nonconforming client might lie about the content, so this doesn't seem like a great solution.
Policy Implications for End-to-End Encryption #
Both the proposal and the public communications around it have been fairly vague about the implication for end-to-end encryption, instead framing this as a "technology neutral" set of regulations:
Assuming the Commission proposal gets adopted (and the European Parliament and Council have to weigh in before that can happen), one major question for the EU is absolutely what happens if/when services ordered to carry out detection of CSAM are using end-to-end encryption — meaning they are not in a position to scan message content to detect CSAM/potential grooming in progress since they do not hold keys to decrypt the data.
Johansson was asked about encryption during today’s presser — and specifically whether the regulation poses the risk of backdooring encryption? She sought to close down the concern but the Commission’s circuitous logic on this topic makes that task perhaps as difficult as inventing a perfectly effective and privacy safe CSAM detecting technology.
“I know there are rumors on my proposal but this is not a proposal on encryption. This is a proposal on child sexual abuse material,” she responded. “CSAM is always illegal in the European Union, no matter the context it is in. [The proposal is] only about detecting CSAM — it’s not about reading or communication or anything. It’s just about finding this specific illegal content, report it and to remove it. And it has to be done with technologies that have been consulted with data protection authorities. It has to be with the least privacy intrusive technology.
However, for the reasons discussed above, designing a communications system that combines end-to-end encryption with robust content filtering is basically an open research question.[8] This is not to say that it's not something that can never be solved, but rather that it's not something we know how to do today, even at the level of "we have a prototype that just needs to be tech transferred". Whatever the intent, it's hard to see how a mandate of this form that applies to all platforms isn't effectively a prohibition on end-to-end encryption.
Apple didn't publish NeuralHash but it was quickly reverse engineered and published and people started demonstrating the kind of attacks I mention above. ↩︎
Note that Apple doesn't presently E2E encrypt data in iCloud, so presumably they could check that the voucher matches, but the whole point of this system is to ensure that they don't need to scan the image, so we should model the problem as if the images were encrypted. ↩︎
For instance, the use of Tor Hidden Services to distribute CSAM in the 2014 "Playpen" case. ↩︎
Oddly, I couldn't find an author list, so I don't know which experts. ↩︎
This requires the server to know such a hash, but these hashes are fairly widely known, so shouldn't be an obstacle to a state-level attacker. ↩︎
You may recall this technique from its appearance in my post on side channels. ↩︎
You can purchase "hardware security modules" which aren't just part of the processor but rather are a separate computer in a tamper-resistant casing (the IBM 4758 is an early example.). These do better at resisting physical attack but are a lot less convenient to use, due to limited processing power and large size. ↩︎
Note that the EU report's recommendations implicitly concede this: "Immediate: on-device hashing with server side matching (1b). Use a hashing algorithm other than PhotoDNA to not compromise it. If partial hashing is confirmed as not reversible, add that for improved security (1c)." They recommend further research on the other avenues. ↩︎