Understanding Memory Management, Part 1: C
Posted by ekr on 13 Jan 2025
UPDATED: 2025-02-15: Fixed some bugs in the examples and pointed out that you don't usually just want to panic on memory allocation failure.

I've been writing a lot of Rust recently, and as anyone who has learned Rust can tell you, a huge part of the process of learning Rust is learning to work within its restrictive memory model, which forbids many operations that would be perfectly legal in either a systems programming language like C/C++ or a more dynamic language like Python or JavaScript. That got me thinking about what was really happening and what invariants Rust was trying to enforce.
In this series, I'll be walking through the logic of memory management in software systems, starting with the simple memory management in C and then working up to more complicated systems. This series isn't intended to be a tutorial on how to write C, Rust, or any other language; rather the idea is to look at how things actually work under the hood at a level that we usually ignore when all we are doing is trying to write code.
How Programs Use Memory #
Consider the following program, written in Python
all_lines = []
f = open("input.txt")
for l in f:
all_lines.append(l.strip())
all_lines.sort()
for l in all_lines:
print(l)This program does something very simple, namely, it reads input
from the file one line at the time, then sorts the lines, and
prints out the lines in sorted order. So if input.txt has
the following contents:
jim
bob
deb
carolThe output will be:
bob
carol
deb
jimHowever, there is something complicated hiding under the hood: because we don't know the sort order of the lines in advance, we have to store all of the lines we've read until we know that we've seen all of them, and only then can we write them in sorted order.[1] If we're going to store all the lines, they have to go somewhere, which is in the computer's memory.
Storing a List #
Conceptually, a computer's memory is just a giant table of values, with each value having an address. For convenience, let's assume that entries are numbered from 0 and each entry can hold a single character. Thus, if we want to store the string "computation", we end up with something like:
| Memory Address | Value |
|---|---|
| 0 | c |
| 1 | o |
| 2 | m |
| 3 | p |
| 4 | u |
| 5 | t |
| 6 | a |
| 7 | t |
| 8 | i |
| 9 | o |
| 10 | n |
Or, in a more compact notation:
Starting Address
0 | c | o | m | p | u | t | a | t | i | o |
10 | n |
The way to read this is that each cell is a memory location and on
the left we have the starting address for each row, so the p is at
address 3 (the fourth column in the first row).
With this in mind, how do we store the data from this file into memory. The obvious way is something like this, which immediately reveals that we have a problem:
0 | j | i | m | b | o | b | d | e | b | c |
10 | a | r | o | l |
If we just concatenate the values in memory, how do we know where one line ends and the next begins? For instance, maybe the first two names are "jim" and "bob" or maybe it's one person named "jimbob", or even two people named "jimbo" and "b". Obviously, we need some way to keep track of the memory regions associated with individual values.
There are a number of alternatives here, but let's just do something obvious, which is to prefix every value with its length, like so:
0 | 3 | j | i | m | 3 | b | o | b | 3 | d |
10 | e | b | 5 | c | a | r | o | l |
If you know that an entry starts at address X, then you can print out that entry in the obvious way:
address = X
length = *X
address = address + 1
while length > 0 {
address = address + 1
print *address
}
For non-C programmers, the notation *X means "take the value at memory address X" (technical
term: dereferencing X) so the second
line is setting length to be whatever is in X and the 5th line is
printing whatever is currently stored at address. So, what happens here
is that we first read the length of the current line out of address, then count
down one character at a time.
So far so good, but what if we want to print out the whole list? The obvious thing to do is just to repeat the process above, but now we have a new problem, which is knowing when to stop. Remember that the memory is a giant table and we're just showing the relevant portion of it. In reality, we have:
0 | 3 | j | i | m | 3 | b | o | b | 3 | d |
10 | e | b | 5 | c | a | r | o | l | O | T |
20 | H | E | R | | | S | T | U | F | F |
30 | . | . | . |
This is just a new version of the same problem, which is we don't want want to read off the end of the list. This requires knowing where does our list end and the other stuff in memory begins. One obvious thing to do is to prefix the list with the amount of memory that it consumes, like so:
0 | 19| 3 | j | i | m | 3 | b | o | b | 3 |
10 | d | e | b | 5 | c | a | r | o | l |
Now we can write a program to go over the whole list, like so:
total_length = *X
address = address + 1
while total_length > 0 {
length = *X
address = address + 1
total_length = total_length - (length + 1)
while length > 0 {
address = address + 1
length = length - 1
print *address
}
}Note that this is a self-contained object. As long as you know where it
starts and what type it is (i.e., a list of strings), then you can read
it out knowing just the starting address X. I.e., we can have a
subroutine/function, like so:
function print_list(X) {
total_length = *X
address = address + 1
while total_length > 0 {
length = *X
address = address + 1
total_length = total_length - (length + 1)
while length > 0 {
address = address + 1
length = length - 1
print *address
}
}
}However, we do have to remember where the object starts, as it's
not going to always start at 0 (what if we have two lists, or a
list and something else?). So how do we do that?
The Stack #
Up till now I've been acting like memory is just an undifferentiated table, but the reality is much more complicated. Although from a hardware perspective the memory is largely undifferentiated there is a conventional way to lay things out, as shown in this diagram I borrowed from Geeksforgeeks:
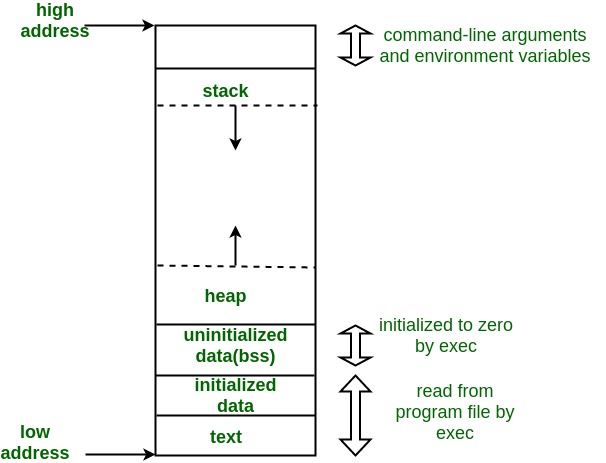
To orient yourself, address zero is at the bottom of the diagram and higher addresses are at the top. The program is actually split up into two pieces: the program itself ("the text segment") There are also two different parts of memory where the program's data is stored call the "stack" and the "heap". Very roughly speaking, they are used like this:
-
The stack is used to store fixed-size data that is part of the local context of the function.
-
The heap is used to store arbitrary-sized data or data that survives past the lifetime of a function.
For instance, in our print_list() function above, total_length, address,
and length are fixed size values (effectively integers big enough to hold
a memory address), so they can be allocated on the stack. By contrast,
the list of strings is arbitrary sized and in fact of a size that's
dependent on the file we are reading in, and so is allocated on the heap.
When we call a function in a compiled language like C (or Rust), the
compiler makes sure you have enough space on the stack to store all
the variables it needs and makes room for it in memory. This is called
a "stack frame". So, print_list() would have a stack frame big
enough to store all three of these values just laid out end to end,
like so:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| total_length | address | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Importantly, the layout here is fixed (and dictated by the compiler) and so we don't need to have any metadata telling us how long things are; the compiler just knows.
The stack is laid out contiguously in memory, with each function call extending the stack by enough room for the stack frame associated with that function, which depends on which function it is. For technical reasons, the stack grows "downward" in memory towards smaller addresses, so the callee has a lower address than the caller. The following figure shows a simple example.
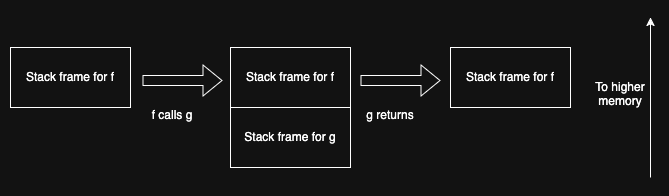
At the left of the figure, we see the situation where we are in
the function f(). The stack just consists of the stack from
for f(). If f() calls g() then we add a new stack frame
for g() (technical term: pushing onto the stack), shown in the middle of the figure. Then when g()
returns, the stack shrinks (technical term: popping the stack), leaving
us back where we were before. Note that if f() called a different
function h(), it would end up where the g() frame was before,
but might be of different size, depending on how many local
variables it had.
You should now be able to see why the stack isn't suitable for variable-sized objects: we need to allocate the stack frame when the function is called, and we can't do that if we don't know how big the variables in the stack will be. It's possible to grow stack frames but not convenient, so instead, we need to allocate them somewhere else, which is what the heap is used for.
The Heap #
Conceptually the heap is just a big pile of memory that we can allocate
space out of. In many languages (e.g., Python or JavaScript)
this is done automatically when you make an object, but in C,
you have to do memory management by hand. This is done with the malloc() API, which is
used like this:
space = malloc(100);This works exactly like you would expect, namely reserving a block of
100 bytes on the heap that the caller can then use however they want.
The return value from malloc() is the memory address of the allocated
region. Internally, of course, malloc() has to do some bookkeeping
to know which memory is in use and which is not. There are a large number
of different data structures that can be used here, but essentially any
technique will involve using some of the heap for that bookkeeping,
leaving the rest available for allocation.
Memory Management in C #
With that background, let's try rewriting our program in C, where we have to do the memory management by hand. This gets a lot more complicated, so let's take it in pieces.
Read in the file. #
First, we have to read in the file.
FILE *fp = fopen("input.txt", "r");
char line[1024];
char **lines = NULL;
size_t num_lines = 0;
if (!fp) {
abort();
}
// 1. Read in the file.
while (1) {
char *l = fgets(line, sizeof(line), fp);
if (!l) {
break; // End of file (hopefully).
}
// Make room in the list of lines.
if (!num_lines) {
lines = malloc(sizeof(char *));
} else {
lines = realloc(lines, (num_lines + 1) * sizeof(char *));
}
if (!lines) {
abort(); // We are out of memory so panic.
}
char *copy = strdup(l);
if (!copy) {
abort(); // We are out of memory so panic.
}
lines[num_lines] = copy;
num_lines++;
}We start by opening the input file, in this case input.txt. Then,
as before, we're going to iterate over the lines in the file and
add them to our list of stored lines. This is accomplished by our
while loop.
We can read the line in using the fgets() function, which
reads a line (defined by ending in a \n newline character)
out of the file fp into the buffer (memory region) associated with line.
char line[1024];
...
// 1. Read in the file.
while (1) {
char *l = fgets(line, sizeof(line), fp);
if (!l) {
break; // End of file (hopefully).
}What's a buffer? #
For those of you who haven't heard the term before, a buffer is just programmer jargon for some piece of storage used to hold data temporarily, as in this case case where we're reading in a line of data and then quickly doing something with it. It's also the name for this doodad which is responsible for stopping trains which don't stop on their own at the end of the track.

From Wikipedia by User:Orderinchaos - Own work, CC BY-SA 3.0, Link
There's already something sus here, though. Did you notice the line char line[1024]?
This is C notation for "make a buffer called line which is long enough to hold 1024 characters".
As noted before, line has to be fixed size and 1024 is just an arbitrary
number that's hopefully large enough to hold any line in the file.[2]
But what if
one of the lines is longer? In that case, fgets() will break up the line into
two pieces, causing the program to be incorrect. The right way to do this would
actually be to keep reading until we had a full line, but this would make
the program even more complicated, so we'll just live with the defect, seeing
as it's an example program.
fgets() returns a pointer to the input buffer if successful and a zero value
(NULL) at the end of the file (or any error, actually), so when we test
for l, we are actually testing for the end of the file, at which point the
loop exits.
At this point, we have the next line of the file in line, but we overwrite
that buffer every time we read a new line from the file, so we need to store it
somewhere. We use the lines variable for this, which is defined as:
char **lines = NULL;
size_t num_lines = 0;This notation can be a bit hard to read for non C programmers, but briefly * means
that something is a pointer, which is to say that it's something that holds a
memory address. ** means that it's a pointer to a pointer, which is to say that
lines holds the address of a block of memory that is itself full of values
that themselves are memory addresses, in this case the individual stored lines.
num_lines stores the number of lines that we have in memory.
We can see this in action by looking at the next block of code:
// Make room in the list of lines.
if (!num_lines) {
lines = malloc(sizeof(char *));
} else {
lines = realloc(lines, (num_lines + 1) * sizeof(char *));
}
if (!lines) {
abort(); // We are out of memory so panic.
}
char *copy = strdup(l);
if (!copy) {
abort(); // We are out of memory so panic.
}
lines[num_lines] = copy;
num_lines++;Storing a copy of line is a two-part process:
- Make a copy of the line itself.
- Store the pointer to that line in
lines.
However, in order to store that pointer, we first need to make room in
lines, which means allocating some memory. This happens on the two lines
at the start of this snippet. There are actually two cases here:
- Lines is empty (nothing is stored), which happens at the start.
- Lines is non-empty but doesn't have enough room.
We distinguish these by looking at num_lines which starts at 0.
In the former case, we allocate enough memory for a single line,
like so:
lines = malloc(sizeof(char *));This says "make enough room to hold the address of a single string", and is nothing we haven't seen before.
The latter case is more complicated, however, because we already
have something in lines, it's just that there's not (necessarily)
enough room in memory to add another value. This means we (may) need to
- Allocate enough memory to hold the new number of values.
- Copy over the current contents of
linesinto the new memory region. - De-allocate the original memory.
What are all the parentheticals doing here? The answer is that
the block of memory pointed to by lines may already be big
enough. When you call malloc(size) the system guarantees that
the returned pointer is at least big enough to hold an object
of size size—assuming that the allocation succeeds—but it's
allowed to be larger. This could happen for a number of reasons
(see How Malloc Works below for some more
background), but one of which is to facilitate exactly this
case: if people want to resize an object frequently, as we are doing
here, then it's not efficient to have to copy the contents of
the object over and over again. Instead, you can allocate more
space than the programmer asked for and then when they ask for
more, just say "ok" without taking any other action.[3]
All of this is handled automatically by the realloc() function call.[4]
At the end of this process lines may or may not have the same
value from what you passed into realloc. What
matters, though, is that the memory that lines points to has
the same contents as before, and that's what realloc() guarantees.
It's also possible that the memory allocation will fail, for instance
if the computer is out of memory. In that case, lines will be set to
NULL and we need to abort:
if (!lines) {
abort(); // We are out of memory so panic.
}
I'm just calling abort() which makes the program crash, but
you could do something more sophisticated here, such as having
the function fail and let some higher level handle it, either
via an orderly shutdown of the program or actually trying
to recover enough memory to let the program survive. The
right thing to do here was fairly hotly contested on the
Hacker News thread for this post, but in my experience most
programs crash. [2025-02-15 -- added]
Now that we have room in lines we can store a copy of the actual
line we've read in, but first we have to make a new buffer to store
it in (remember that line will be overwritten). We can do that with
the strdup() function call, which makes a copy of a string,
allocating new memory as needed:
char *copy = strdup(l);
if (!copy) {
abort(); // We are out of memory so panic.
}Here too, we can run out of memory, so we need to check for copy being
NULL.
Finally, we can append the copied line to the end of lines and increment
the number of stored lines:
char *copy = strdup(l);
if (!copy) {
abort(); // We are out of memory so panic.
}The diagram below should help provide an understanding of the data structures here:
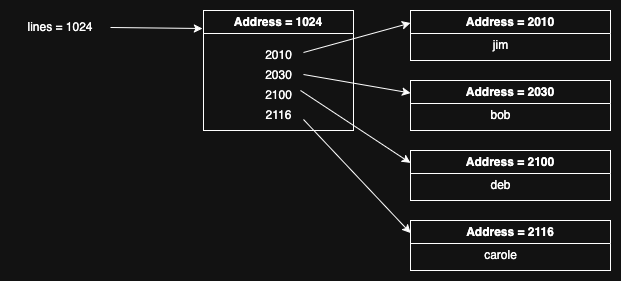
On the left we have the lines variable itself, which is stored somewhere on the
stack. It contains the address of the memory we have allocated to store the
list of lines, namely address 1024. That memory region is shown in the middle
of the diagram. Finally, on the right we have the individual regions for each
stored line. The memory region for lines stores their addresses, each laid
out one after the other. Note that there's no variable on the stack which
points to these regions, they're just pointed to by the addresses stored in
the region pointed to by lines.
Sorting the Lines #
The next thing we do is to sort the lines. This is done by the qsort() library
function.
// 2. Sort the lines.
qsort(lines, num_lines, sizeof(char *), compare_string);qsort() is kind of hard to use because it's designed to sort a list of
any kind of object of any size. This means that you have to pass:
- The pointer (address) to the first object in the list (in this case
lines) - The number of objects in the list (
num_lines). - The size of the objects
sizeof(char *). In this case, that's the size of a pointer to a string.[5] - A comparison function which tells
qsort()the sort order for two objects. I'm going to skip over the details here.
qsort() sorts its arguments in place, so this means that after it's
done, lines is sorted, like so:
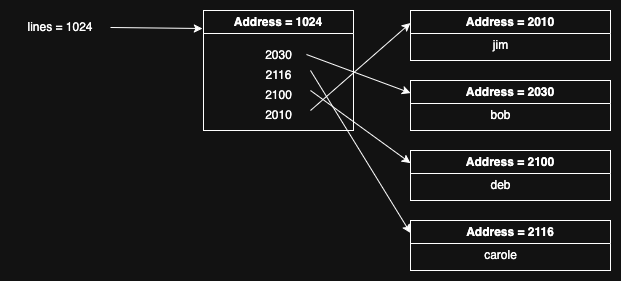
Importantly, the only thing that's changed here is the values in
the middle memory region, referenced by lines. The actual strings
are unchanged and are in the same memory regions; we've just
rearranged the pointers in lines to point to the strings in
the right order. Note that that order is not given by the
numeric order but rather by the lexical order of the strings.
That's convenient, but actually required, because
qsort() doesn't know anything about the
objects it's sorting; it just knows how to pass them to the comparison
function, so all it can do is manipulate its own data as if the objects
were numbers, whatever their actual semantics.
Printing the Results #
After all this, we're ready to print the results. This is comparatively
simple, just iterating over the entries in lines and printing the
corresponding strings:
// 3. Print the lines.
for (size_t i=0; i<num_lines; i++) {
fputs(lines[i], stdout);
}One thing you may be wondering about here is how we know how long each
line is, as we haven't stored any length information. The convention in C is actually to have each string end with
a byte with the value of 0, usually written as \0. This is
pretty universally agreed to have been a bad idea, but we're taking
advantage of it here because it means that the strings are self-contained.
Cleaning Up #
Finally, we want to clean up. In this simple program, that's not really required
because when a program terminates the operating system automatically reclaims
its resources, including memory, but this function might be used by
some bigger program, in which case we'd want to reclaim the memory
used by the list of strings, as well as close the open file (remember
input.txt?).
If this function were to return without cleaning up, it would create
what's called a "memory leak". Remember that the only variable in
our program that knows about any of this memory is lines, which
points to the list of pointers for the individual stored lines. lines
is on the stack and will be lost when the function returns,
so if the function returns without cleaning up, then there is no
program variable pointing to any of this memory and it's just lost.[6]
The result of a memory leak is that the leaked memory isn't available
for new allocations but also can't be used because there's nothing
pointing to it. If the program runs
long enough and has a big enough leak, you can eventually accumulate
enough leaked memory to affect the program function or even cause it
to run out of memory, so you want to clean up. This is one reason why
it often works to restart a program that seems stalled.
In C, memory is freed using the free() function, which takes the
pointer to be freed. Here's what the cleanup looks like:
// Clean up.
fclose(fp);
for (size_t i=0; i<num_lines; i++) {
free(lines[i]);
}
free(lines);Note that we need to free the stored lines before we free lines
because once we've freed lines nothing points to the stored
lines and so there's no way to free them (remember, we need
their addresses). This means we need to iterate through lines
freeing each individual allocation and then only when we're
done freeing lines itself. Recall that all the local variables
will just be deallocated when the function returns. However,
this doesn't mean that the things they point to are deallocated,
just that the storage used by the variable itself is reclaimed.
Error Handling #
Because this is demonstration code, I've chosen to ignore the
case where a line is longer than 1024 characters, but what if
we wanted to handle that instead? You can detect this case with
fgets() by checking to see if you have a newline at the
end of the buffer[7]
char *l = fgets(line, sizeof(line), fp);
if (!l) {
break; // End of file (hopefully).
}
if (l[strlen(l)-1] != '\n') {
return BAD_LINE_ERROR;
}The problem with this code is that it has a memory leak:
if we have already read in some of the lines, then we'll
leak lines and whatever lines we read in. In order to
avoid the leak, we need to run our cleanup routines.
Once common way to handle this is to have an error block
that we execute. For instance:
int status = OK;
...
char *l = fgets(line, sizeof(line), fp);
if (!l) {
break; // End of file (hopefully).
}
if (l[strlen(l)-1] != '\n') {
status = BAD_LINE_ERROR;
goto error;
}
...
error:
// Clean up.
fclose(fp);
for (size_t i=0; i<num_lines; i++) {
free(lines[i]);
}
free(lines);
return status;The goto instruction here just says to go to the line labelled
error.
This works but is error prone: you need to note every
case where the function might return and jump to the right
error block. Moreover, the error block needs to be able to
clean up after any kind of error, so, for instance, it
needs to be able to handle when lines = NULL (fortunately,
free() handles this case automatically). Finally, if
you forget to set the status value, then you are incorrectly
returning an OK status even if there was an error.
Locally Scoped Allocations #
You might ask why you can't just free all the memory that was allocated by a function when the function returns rather than just the memory on the stack? Then we wouldn't have to do all of this stuff where we explicitly free everything.
There's an obvious answer to this question: some functions
intentionally allocate memory and don't clean it up. An obvious
example here is the strdup() function we used above. Internally,
strdup does something like this:
char *strdup(const char *str) {
size_t len = strlen(str);
char *retval = malloc(len);
if (!retval) {
return NULL;
}
strcpy(retval, str);
return retval;
}If we automatically freed all memory that was allocated by the
function, then we would free retval before returning, at which point
the caller would be left with a pointer to memory that has been freed,
which is clearly a problem. In fact, it's the source of a common
security vulnerability called use after
free.
Clearly we would need something more sophisticated than just
freeing everything that was allocated in the function when
it exits.
What you actually want is the compiler to know when objects are intended to outlive the function and when they are not, but actually distinguishing these cases is very difficult in C, at least without help from the programmer, as we will see in the rest of the series. In fact, making this kind of analysis possible is one of the the main motivating design choices for much of the Rust memory model.
How malloc() works #
So far we've just been treating malloc() as a kind of black box,
and that's generally fine for most programming tasks, but it's
helpful to have some sense of what's going on internally. The first
thing to realize is that malloc() isn't magic. In fact, you can
write your own memory allocator in C (Firefox, for instance, uses
a custom allocator).
At a very high level, you should think of malloc() as having
access to one or more large contiguous blocks of memory, which it
then dispenses on demand. On a very simple computer, malloc() would
just have access to the entire memory of the machine, but on a
modern multiprocess operating system, it gets chunks of memory
from the operating system. For our purposes, let's easiest to
think of it as having a big contiguous chunk of memory to work
with. As I said, we usually wouldn't start at memory location 0,
so we'll just assume the block starts at 1000.
The figure below shows the situation after a single allocation
of size 200, with the allocation being red and the unallocated
space being blue. What's happened here is just that malloc(200)
just picked the first available memory region, which is
at the start of the block because no memory has been allocated.
The allocation starts at address 1000 and goes to address 1199,
so malloc() just returns the address 1000, which points
to the start of the allocated region.
The next figure shows the situation with two more allocations, one of size 400 and one of size 200. Again, this is what you'd expect: the allocator just picks the lowest available region. As noted above, a real allocator would probably leave some extra space to facilitate growing the allocation but we're trying to keep things simple for the purpose of examples. Designing fast memory allocators is a whole (complicated) topic all on its own.
So far so good, but now what happens when we free allocation #2? The result is shown below.
We have a 400 byte sized hole of free memory. If we try to do another 200 byte allocation, it will work fine, like so:
But if we now try to allocate another 400 bytes, it obviously won't fit, so we need to go into higher memory.
As the program runs longer and memory is allocated and freed you tend get lots of small holes that can't be filled with big allocations, and so you have to allocate higher and higher memory regions. This is called fragmentation. In the extreme, you can get to the point where you can't allocate new memory even though there's actually plenty of free space; it's just not in a convenient form. There are techniques for avoiding this kind of fragmentation as well as for allocating memory more efficiently, but they're too advanced to cover here.
How does malloc() get its memory? #
As I said above, malloc() gets chunks of memory from the operating
system. Remember that your program has to share the computer, including
its memory, with other programs and the operating system is responsible
for arbitrating which program has which chunk of memory. Conceptually
this is actually somewhat like malloc() except that malloc()
calls some system API (for instance, mmap() to request memory from the operating system.
Note that modern systems all have virtual memory, systems in which the system automatically moves ("swaps") data in and out of the physical memory and onto disk so that programs can allocate more space than is in the hardware of the system. In order to this, the operating system may have to move stuff around in physical memory, so it maintains a mapping from the address the programs use to the actual physical location in memory. In a future post, I may cover virtual memory in more detail, but no promises.
A natural question to ask is why we can't just move things around
to accommodate the holes? The reason is that the pointers stored
in the program literally just point to the memory addresses
where the allocations are stored. So if (for instance) we were
to slide allocation #3 over to the right to make room for
allocation #4, then whatever pointer was returned from the initial
malloc() for #3 would now point somewhere in the middle of
allocation #4, which is obviously a problem. The compiler doesn't
keep track of the variables holding the pointers, so it has no
way to go back and readjust them.
The key thing to realize here is that all that malloc() and free()
are doing is bookkeeping: the allocator remembers which memory is
currently in use and then hands out pointers to regions that aren't
currently in use as needed. This naturally raises the
question of how the allocator does the bookkeeping. How does it
remember which regions are in use and which aren't? The obvious answer
is the right one: the allocator reserves some of the memory it
has to work with for this kind of bookkeeping metadata, at minimum:
- The size of each allocation (so it can be freed)
- The regions that are currently free, for instance the top of the highest allocation and the addresses of the the freed holes.
When you call malloc() the allocator finds a suitable region
and allocates it. When you call free() it adds it to the list
of holes (or adjusts the highest allocation value if it's the
highest allocation).
Interestingly, it's not always necessary to store a list of every chunk of allocation memory. You can do this, but that means you need some data structure that lets you look up the allocations from their addresses. A common thing people do instead is to store the per-allocation metadata as a header right before the allocated region. The header contains the size of the allocation and maybe some other stuff. For instance, the first allocation above might look like this:
Instead of returning 1000, in this case malloc() would return
1100. (I've drawn it as 100 to make the figure more readable,
but hopefully you're not wasting 100 bytes of overhead on every allocation.)
Then when you call free(1100) the allocator would subtract
the size of the header and deallocate the whole region from
1000-1299. The reason this works is that free() requires
knowing the memory address anyway, so there's no need to
store it. If you call free() on some region of
memory that wasn't returned from malloc() the results are
likely to be disastrous, because free() has no way of knowing
that this is a mistake and will just treat whatever is right
before the pointer you passed in as the header. If that
data is attacker controlled, it can easily lead to a vulnerability.
Multiple References and UAF #
Let's consider a slight modification of the function we've been looking at, in which along with printing out all the lines, we instead return the last line in sort order.[8] With a lot of trimming, the function might look like this:
char *find_smallest(const char *filename)
{
...
// 2. Sort the lines.
qsort(lines, num_lines, sizeof(char *), compare_string);
largest = lines[num_lines - 1];
...
// Clean up.
fclose(fp);
for (size_t i=0; i<num_lines; i++) {
free(lines[i]);
}
free(lines);
return largest;
}This function gets called like this:
char *largest = find_largest("input.txt");
printf("%s\n", largest);The experienced C programmer will immediately note that this
code has a serious bug, because we are trying to use the
memory pointed to largest after we have free()d it.
When the calling function tries to use largest, there are
no guarantees at all about what will happen.
This is called a use after free (UAF)
bug. For example,
the allocator might have reallocated the memory in response
to some other call to malloc(), in which case it is now
full of some other data. Of course, it's also quite likely
that the region is still unused and has the same contents
as before; it's just that the allocator added it to the list
of holes. In this case, the program may work fine under
test but then fail unpredictably later when some change
to your code causes allocations to happen differently and
suddenly largest points to some memory reason being used
for something else.
The reason this is all possible is that in C pointers are
just values that hold the memory address; effectively they're
just numbers and they behave like numbers. So if you assign
a pointer value to another variable, now you have two variables
that point to the same thing (i.e., they have the same value).
When we call free on the first copy of the variable, that
doesn't have any effect at all on the other copy (or on the
first one, for that matter). It just changes the state of
the memory region addressed by the variable. Once you've
called free(x) you're still left with whatever is in x,
and nothing in C stops you from using it; it's just illegal
to do so, and it's your job not to, or else.
Next up: C++ #
As you have probably gathered by now, managing memory yourself is a huge amount of work, which is one reason why C programs have so many memory issues. In the next post in this series, we'll be taking a look at C++, which has some features that make things a bit better, at least some of the time.
This code actually stores the lines in unsorted order, then sorts them, and then finally writes the output, but you could also store them in a sorted data structure. Either way, you need to store all of the lines. ↩︎
C99 supports a feature called "variable length arrays", but they don't automatically grow the way a Python array does, so that doesn't help us much. There seems to be a lot of sentiment that they are a misfeature. ↩︎
If you know you're going to be doing a lot of reallocation like this, many people will themselves overallocate, for instance by doubling the size of the buffer every time they are asked for more space than is available, thus reducing the number of times they need to actually reallocate. I've avoided this kind of trickery to keep this example simple. ↩︎
In reality, you can pass a
NULLtorealloc()for the existing memory and it will just allocate new memory, but I'm handling the cases separately for pedagogical reasons. ↩︎In C, pointers to different kinds of objects can be different sizes. ↩︎
This isn't technically true because the memory allocator has kept track of what memory has been allocated, but the allocator doesn't know that we should have cleaned up (for instance, we might have stored the value in
linessomewhere) and so it can't clean up for us. ↩︎For the nitpickers out there, this will also catch the case where the last line in the file doesn't end in a newline. ↩︎
Obviously you don't need to sort the lines in order to do the largest one, but this is necessarily an artificial example. ↩︎