Understanding Memory Management, Part 3: C++ Smart Pointers
Posted by ekr on 10 Mar 2025
This is the third post in my planned multipart series on memory management. In part I we covered the basics of memory allocation and how it works in C, and in part II we covered the basics of C++ memory management, including the RAII idiom for memory management. In this post, we'll be looking at a powerful technique called "smart pointers" that lets you use RAII-style idioms but for pointers rather than objects.
Why do you want pointers? #
Recall from before that I said that if you want to use RAII you need to store an actual object on the stack, not a pointer to the object, because if the object is on the heap, it won't be cleaned up when the function exits. This is an annoying limitation.
For example, suppose we want to write a function which hashes the contents of the file, returning a single string containing the hash. With just one hash function, that might look like this:
std::string hash_file(std::string filename) {
char buf[1024];
std::fstream fs(filename, std::fstream::in);
SHA1 sha1; // Hash object
if (!fs.is_open()) {
abort();
}
while (fs.read(buf, sizeof(buf))) {
sha1.update(fs.gcount()); // Hash a chunk of data.
}
return sha1.final();
}Our hash function is just an object with two methods:
update()which hashes a chunk of data.final()which returns the hash value.
I.e.,
class SHA1 {
public:
void update(const char* buf, size_t len);
std::string final();
};This works fine, but what happens if we want to support more than one hash function, for instance SHA-1, SHA-256, etc. One way to do this is to have the caller of the function provide the name in a string, i.e.,
std::string hash_value = hash_file("input.txt", "sha-1");Internally, we'd have what's called a factory functionthat makes a hashing object given the string name. I.e.,
class Hasher {
public:
virtual void update(const char* buf, size_t len);
virtual std::string final();
};
Hasher *get_hasher(std::string hash_name);All of the concrete hashers (e.g., HashSHA) inherit from
Hasher and get_hasher() returns an instance of the desired hash
object. Because of inheritance, we can just assign all of them to
Hasher *. This gives us a function like the following:
std::string hash_file(std::string filename, std::string hash_name) {
char buf[1024];
std::fstream fs(filename, std::fstream::in);
Hasher *h = get_hasher(hash_name);
if (!fs.is_open()) {
abort();
}
while (fs.read(buf, sizeof(buf))) {
h->update(fs.gcount()); // Hash a chunk of data.
}
return h->final();
}So far so good, but now instead of having an instance of
SHA1 on the stack we have an instance of Hasher on the
heap and it leaks when the function returns. So much for
RAII.
Fortunately, it's possible to recover RAII semantics
in a generic way using a "smart pointer".
What's a smart pointer and why is it smart? #
At a high level, a smart pointer is an object that can be used as if
it were a pointer but has better semantics. For instance, C++
unique_ptr
provides stack-like RAII properties for objects on the heap. It
gets used like this:
unique_ptr<Hasher> h(get_hasher(hash_name));This is literally the only change we have to make. From there
on, we can use h, which is actually a unique_ptr holding
Hasher *,as if it were a Hasher *. When h goes out of
scope out the end of the function, the pointer it's holding
will be freed, just as if the hasher object itself were on
the stack.
C++ has a number of different smart pointer types built into it, but first I want to look at how you actually implement a smart pointer.
Implementing a Smart Pointer #
Suppose, for example, we want to implement a unique_ptr-like
for Hasher. For starters, we need a class that holds a
Hasher* and destroys it on destruction:
class UniquePtrHasher {
private:
Hasher *ptr_;
public:
UniquePtrHasher(Hasher *ptr) {
ptr_ = ptr;
}
~UniquePtrHasher() {
delete ptr_;
}
};This is actually enough to give us RAII behavior: we can create
a UniquePtrHasher in the usual way and when it goes out of
scope it will be destroyed along with the hasher object inside:
HasherUniquePtr h(get_hasher(hash_name));This isn't really a smart pointer, though, it's just a container for
the object. If we want to do anything with object inside, we somehow
need to get at the pointer. The obvious thing is to just provide
a function called get() that gives you the pointer:
Hasher *get() {
return ptr_;
}This is called "unboxing" because we have the pointer in a box (the
smart pointer) but now
we take it out to use it. Unboxing will work, but now we have to change all the
code which previously used h as if it were a pointer to use
h.get():
while (fs.read(buf, sizeof(buf))) {
h.get()->update(fs.gcount()); // Hash a chunk of data.
}
return h.get()->final();
}Yuck! Not only is this a pain in the ass, but it undercuts the whole thing we are trying to do here, which is to avoid having to work with the raw pointer.
Fortunately, C++ has a feature that makes this unnecessary because
we can use operator overloading. In part II,
we overloaded the copy assignment operator but here we are going
to overload the -> operator instead so that
UniquePtrHasher acts like Hasher*.
The code
for that looks like this:[1]
T *operator->() {
return ptr_;
}You don't need to worry too much about the syntax, but the net
effect is that when you use -> with UniquePtrHasher it acts
like you were using -> with the internal pointer,
which is what we want. Here's our new code:
std::string hash_file(std::string filename, std::string hash_name) {
char buf[1024];
std::fstream fs(filename, std::fstream::in);
UniquePtrHasher h(get_hasher(hash_name)); // NEW
if (!fs.is_open()) {
abort();
}
while (fs.read(buf, sizeof(buf))) {
h->update(fs.gcount()); // Hash a chunk of data.
}
return h->final();
}The only line that's changed from our original code
is the one marked NEW where we
create the UniquePtrHasher but now we've eliminated the memory
leak.
This is a smart pointer after the fact, but it's kind of a dumb one. There are at least two big problems:
- It doesn't guarantee uniqueness.
- It's not generic.
Let's solve these in turn.
It's good to be unique #
Consider the following code:
UniquePtrHasher h(get_hasher(hash_name));
UniquePtrHasher h2 = h;As we saw in part I, this
will invoke the copy constructor. Because we haven't defined a copy constructor,
we end up with the default one which makes a shallow copy, with the
result that h and h2 both point to the same instance of Hasher.
When the function ends they will both try to delete it, which
leads to a double free, with the following error:
uniqueptrhasher(20294,0x2000dcf80) malloc: *** error for object 0x600003694040: pointer being freed was not allocated
uniqueptrhasher(20294,0x2000dcf80) malloc: *** set a breakpoint in malloc_error_break to debug
Abort trap: 6
As expected, the destructor for UniquePtrHasher fires twice, but with the same
pointer (0x600003694040). In this case, the implementation has
chosen to generate an error and crash the program for the double
free() (note that the error is in malloc() because this C++
implementation of new/delete is based on malloc()), but that's
just whoever wrote it doing you a favor. As noted in post I, anything
could happen at this point, but whatever it is is likely to be bad.
This is definitely a defect and quite
possibly a vulnerability.
What we want to do is make this case impossible, which is to say to
make UniquePtrHasher actually unique. By this point it should be
clear how to do this: we're going to overload the copy constructor and
the copy assignment operator. With what we know now, the obvious
thing to do is to just make them abort, like so:
UniquePtrHasher(UniquePtrHasher &other) {
abort();
}This works in some sense, but it's a runtime error, which means that
our program will crash if we try to copy a UniquePtrHasher but that
the compiler won't catch it so the program will still compile.
Moreover, there's no guarantee that the failure will be this
safe; it could easily be a serious vulnerability via use after
free.
What we really want is a compile time guarantee. The old way
to do this was to make the copy constructor private so that
it wasn't possible to call it, but the new way
(as of C++-11) is to mark it with delete:
UniquePtrHasher(UniquePtrHasher &other) = delete;If we then try to construct a new UniquePtrHasher from an existing
one, we get the somewhat helpful error:
uniqueptrhasher.cpp:23:19: error: call to deleted constructor of 'UniquePtrHasher'
23 | UniquePtrHasher u2(u);
| ^ ~
uniqueptrhasher.cpp:18:3: note: 'UniquePtrHasher' has been explicitly marked deleted here
18 | UniquePtrHasher(UniquePtrHasher &other) = delete;
| ^
If we do the same thing for the copy assignment operator, we've
then prevented anyone from making a second UniquePtrHasher pointing
to the same underling object. Well, sort of.
It's true that if we do all of this you can't make another UniquePtrHasher from
an existing one, but nothing stops you from making two UniquePtrHashers from the
same pointer:
Hasher* hasher = get_hasher(hash_name);
UniquePtrHasher h(hasher);
UniquePtrHasher hr(hasher);The obvious answer is "don't do that then" but we're just depending on programmer discipline, because the compiler won't stop you. How is it to know you didn't want that outcome (and later we'll see an example of where this kind of thing is totally legitimate, if slightly inadvisable)?
Moving Smart Pointers #
OK, so now have a unique pointer, but this is pretty limited. While we don't want to be able to make a copy of a unique pointer (that's what makes it unique), sometimes we want to move an object from one unique pointer to another. For example, suppose we have created an object but we want to store it in a container, like a vector. This presents two problems:
- We want the vector to own it so our destructor doesn't destroy it when it goes out of scope.
- The vector may need to move the object around when it reallocates its own memory to grow or shrink.
The key thing here is that we want to preserve the uniqueness
guarantee. After we do a = b, we want a to be holding
the pointer and b not to be.
Unsurprisingly, we're going to do this with the move assignment operator, which we saw in part I. It looks something like this:[2]
UniquePtrHasher& operator=(UniquePtrHasher &&other) {
// Check for self-assignment.
if (this == &other) {
return *this;
}
ptr_ = other.ptr_;
other.ptr_ = nullptr;
return *this;
} The move assignment operator does two things:
-
It sets the
ptr_field in the new smart pointer (the one being moved to) to point to the object that is being held. -
It invalidates the
ptr_field in the original pointer (the one being moved away from) by setting it tonullptr.
Put together, these will prevent the object from
being destroyed when the source smart pointer is
destroyed. We also want to make sure that any use
of the old smart pointer fails cleanly, so we should
add a check in the operator->() implementation:
Hasher *operator->() {
if (!ptr_) {
abort();
}
return ptr_;
}We'll also need to implement the move constructor, which is basically the same as the move assignment operator.
A generic smart pointer #
This is all fine, but note that we haven't written a generic unique
pointer class, but instead one that only works for Hasher.
If we want one for a new class called Smasher we need to
write it all again, or rather we need to take the Hasher
class and globally replace Hasher with Smasher (and
better hope you don't have anything called NotHasher because
it will become NotSmasher).
Fortunately, C++ offers a better way of doing this: templates.
Templates #
The idea with templates is to let the compiler do that search and replace for you,
which obviously works a lot better than text replacement.
We do this by making a version of the class with a placeholder typename
(conventionally T) instead of the actual concrete typename, like so:
template<class T> class UniquePtr {
T* ptr_;
public:
UniquePtr(T *t) {
ptr_ = t;
}
~UniquePtr() {
delete ptr_;
}
T *operator->() {
return ptr_;
}
UniquePtr(UniquePtr &&u) {
ptr_ = other.ptr_;
other.ptr_ = nullptr;
return *this;
}
UniquePtr& operator=(UniquePtr &&u) {
// Check for self-assignment.
if (this == &other) {
return *this;
}
ptr_ = other.ptr_;
other.ptr_ = nullptr;
return *this;
}
// Delete the copy constructor and copy assignment operator.
UniquePtr(UniquePtr &u) = delete;
UniquePtr& operator=(const UniquePtr& other) = delete;
};Note that we're going to call this UniquePtr rather than unique_ptr
to avoid confusing it with C++'s built-in implementation.
Developing a Template Class #
It's true that one of the advantages of templates is that
they avoid all the grotty search and replace, but it's
actually fairly common to develop a concrete instance
of the template for one class and then do search and
replace of Hasher (or whatever) to T. It's typically
easier to implement classes in the specific case and
then generalize, especially with C++'s famously terrible template-related error messages..
The syntax template<class T> tells C++ that this is a template and that the
name of the placeholder type is T (as an aside, you can have
multiple placeholder types). When you actually go to use the template
class, you tell it what type you want to make a unique
pointer for and the compiler replaces the Ts with that
typename, producing a new version of the UniquePtr class that is customized
just for that type (technical term: instantiating the template).
The syntax should be familiar by now:
UniquePtr<Hasher> h(get_hasher("sha-1"));Importantly, UniquePtr<Hasher> and UniquePtr<Smasher> are totally
different classes, as you can see if you try to stuff a Smasher *
into UniquePtr<Hasher>, provoking the following super-helpful
compiler error message:
./smart.cpp:44:21: error: no matching constructor for initialization of 'UniquePtr<Hasher>'
44 | UniquePtr<Hasher> h(new Smasher());
| ^ ~~~~~~~~~~~~~
./smart.cpp:6:3: note: candidate constructor not viable: no known conversion from 'Smasher *' to 'UniquePtr<Hasher> &' for 1st argument
6 | UniquePtr(UniquePtr &t) = delete;
| ^ ~~~~~~~~~~~~
./smart.cpp:10:3: note: candidate constructor not viable: no known conversion from 'Smasher *' to 'Hasher *' for 1st argument
10 | UniquePtr(T *t) {
| ^ ~~~~
Thinking Outside The Box #
This isn't a complete implementation of a unique pointer, but it illustrates the essential features.
The good news is that if you only use smart pointers and not regular pointers, then your programs will be a lot safer. This isn't to say that there can't be any memory errors because there are other ways to do unsafe stuff, but to a first order you won't have to worry about memory leaks or use after free. The problem here is that nothing in C++ restricts you to just using smart pointers.
For example, with unique pointers:
-
You can create a raw pointer and then add it to a smart pointer, but this doesn't invalidate the original raw pointer; you just end up with both the copy in the smart pointer (the "boxed" version) and the original one in the raw pointer (the "unboxed" version).
-
You can get an unboxed copy of the pointer just by doing
.get(). This doesn't invalidate the boxed version the way thatstd::move()does.
Both of these violate the uniqueness guarantee of
unique_ptr<T>, so if you do either of them, then
you're back in the situation where you have to worry
about manually managing memory and C++ won't protect
you.
The natural thing to say is "I'll just work with boxed pointers", and to some extent you can do that (though again, C++ won't stop you from unboxing stuff, you just have to not do it) but it's very common to have to work with code that doesn't know about smart pointers, and then you end up unboxing them, at which point you're back in the soup.
Other Smart Pointers #
One common situation where you end up having to sort of unbox unique pointers is when you want to pass them to a function, as in:
void doit(std::unique_ptr<Foo> foo) {
// do something
}
void f() {
std::unique_ptr<Foo> x(new Foo());
doit(x);
}As expected, this fails because passing x by value would require
making a copy of x, which would violate the uniqueness invariant. We
could move x but then we couldn't use it later, when what we really
want is to just let doit() do something with x temporarily
but keep ownership. One way around this would just be to pass a
pointer to x, like so:
void doit(const std::unique_ptr<Foo>* foo) {
// do something
}
void f() {
std::unique_ptr<Foo> x(new Foo());
doit(&x);
}This will work, but what it's really doing is working around
the uniqueness rule: we only have one object holding onto the
inner Foo * but we've got multiple variables pointing at the
unique_ptr<Foo>, one in f() and one passed as a pointer
to doit(). So, technically we haven't unboxed the inner
pointer, but we've unboxed x which has all the same problems as before.
C++ also has a feature called "references", where the
callee (in this case doit()) can just ask for what's
effectively a pointer to the object without modifying the
call site, and you could ask for a reference to x but
this still has the problem that you can copy the references
around, so it's possible to have a reference to x outlive
x. This isn't to say that it's not possible to safely
use references or pointers to a unique_ptr, just that
you have to be careful to follow the rules because the
compiler won't help you out. (Aside: in production code
you should use references rather than pointers, but I'm
trying to keep new syntax to a minimum).
It's also quite common to have situations where you actually want to
have two pointers to the same underlying object. For example, suppose
that we're building an HR application and we want to keep track of
people's managers. It's normal for two people to have two managers,
but we can't copy unique_ptr so things get tricky. Fortunately,
unique_ptr isn't the only type of smart pointer. For this task,
the tool we want is called shared_ptr.
Shared Pointers #
Unlike a unique_ptr, multiple shared_ptr instances can point to a
given object, just like with a regular pointer (or, if you're
used to a programming language like Python, JavaScript, or Go, just
like you happens all the time). shared_ptr keeps track of how many instances there
are (the "reference count"). When you copy a shared_ptr the
reference count increases by one. When a shared_ptr instance
is destroyed the reference count decreases by one. If the reference
count reaches zero, that means that there are no shared_ptrs to
the object and it's destroyed.
For example, consider the following code:
class Foo {
public:
Foo() {}
~Foo() {
printf("Destructor for Foo\n");
}
};
int main(int argc, char **argv) {
std::shared_ptr<Foo> p1(new Foo());
printf("Reference count %ld\n", p1.use_count());
std::shared_ptr<Foo> p2 = p1;
printf("Reference count %ld\n", p1.use_count());
printf("Reference count %ld\n", p2.use_count());
p2.reset(); // Forget about the pointer.
printf("Reference count %ld\n", p1.use_count());
p1.reset();
}When run, this produces the output:
Reference count 1
Reference count 2
Reference count 2
Reference count 1
Destructor for Foo
Note that when both p1 and p2 point to the object, then they also
share the same reference count (2). When we reset p2, telling it to
forget about the object, then the reference count drops to 1 and then
when we reset p1, then the reference count drops to zero and the
object is destroyed.
Once we have a shared pointer we can use it to pass an object around without unboxing it:
void doit(std::shared_ptr<Foo> foo) {
// do something
}
void f() {
std::shared_ptr<Foo> p1(new Foo());
doit(p1);
}When we pass p1 to doit(), it makes a copy of p1, incrementing
the reference count. Then when doit() returns, that copy is destroyed,
decrementing the reference count. The same thing happens when we want
to have multiple pointers to the same object, as in the case of
storing a pointer to an employee's manager.
It's worth taking a quick look at how shared_ptr works. The code
below shows the core of a homegrown implementation, focusing on
the new stuff.
template<class T> class SharedPtr {
struct detail {
T* ptr_;
size_t ct_;
};
detail *ptr_;
public:
SharedPtr() {
ptr_ = nullptr;
}
SharedPtr(T *t) {
ptr_ = new detail();
ptr_->ptr_ = t;
ptr_->ct_ = 1;
}
SharedPtr(SharedPtr &u) {
ptr_ = u.ptr_;
ptr_->ct_++;
}
SharedPtr& operator=(const SharedPtr& u) {
ptr_ = u.ptr_;
ptr_->ct_++;
return *this;
}
~SharedPtr() {
ptr_->ct_--;
if (!ptr_->ct_) {
delete ptr_->ptr_;
delete ptr_;
}
}
};The key intuition is that we need somewhere to store the reference
count, and that needs to be shared between the different instances of
SharedPtr so that they have the same view of the reference. This
means that it can't be stored in any one copy in case that copy goes
out of scope. Instead, we allocate a new detail object which stores
the reference count and every instance of SharedPtr just points to
the single detail instance, as shown here:
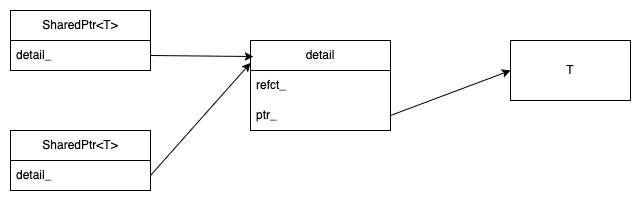
In this case, it also stores the pointer
to the owned object, though that could in principle also go in the
SharedPtr class, with each one having its own copy of the pointer,
which is what Windows seems to do.
Circular References #
Consider the following (potentially more complicated than necessary) code, which models a trivial family with one parent and one child. We want each parent to know its own child and and each child to know its own parent so that we can go from parent to child and vice versa.[3]
class Child;
class Parent {
public:
Parent() {}
~Parent() {
std::cout << "~Parent" << std::endl;
}
std::shared_ptr<Child> child_;
// Forward declaration.
void set_child(std::shared_ptr<Child>& child);
};
class Child {
public:
Child(std::shared_ptr<Parent>& parent) {
parent_ = parent;
}
~Child() {
std::cout << "~Child" << std::endl;
}
std::shared_ptr<Parent> parent_;
};
// Definition of set_child()
void Parent::set_child(std::shared_ptr<Child>& child) {
child_ = child;
}
void make_family() {
std::shared_ptr<Parent> parent(new Parent());
std::shared_ptr<Child> child(new Child(parent));
parent->set_child(child);
}When we run make_family() code, we would expect to get the following
output:
~Parent
~Child
However, in practice we get nothing. The reason is simple: parent
and child aren't actually being destroyed. But why not? To debug
this, let's add some instrumentation:
std::shared_ptr<Parent> parent(new Parent());
std::cout << "Parent refct=" << parent.use_count() << std::endl;
std::shared_ptr<Child> child(new Child(parent));
std::cout << "Parent refct=" << parent.use_count() << "; Child refct=" << child.use_count() << std::endl;
parent->set_child(child);
std::cout << "Parent refct=" << parent.use_count() << "; Child refct=" << child.use_count() << std::endl;And here's the output:
Parent refct=1
Parent refct=2; Child refct=1
Parent refct=2; Child refct=2
It's a little tricky to print out the reference counts after make_family() has completed,
because if we return shared_ptr<Parent> then we'll have a reference to it in
the caller and don't expect it to be destroyed. What we want is to somehow
keep ahold of parent without having a reference to it. We can do this
if we unbox parent via parent.get() and return it, allowing us to look
inside:
Parent* parent = make_family();
std::cout << "Child refct=" << parent->child_.use_count() << std::endl;
std::cout << "Parent refct=" << parent->child_->parent_.use_count() << std::endl;The output is:
Parent* parent = make_family();
std::cout << "Child refct=" << parent->child_.use_count() << std::endl;
std::cout << "Parent refct=" << parent->child_->parent_.use_count() << std::endl;
The output is:
Child refct=1
Parent refct=1
You may have figured out what's going on here, but if not, it's helpful to walk through things step by step and look at the structure, as shown in the following diagram.
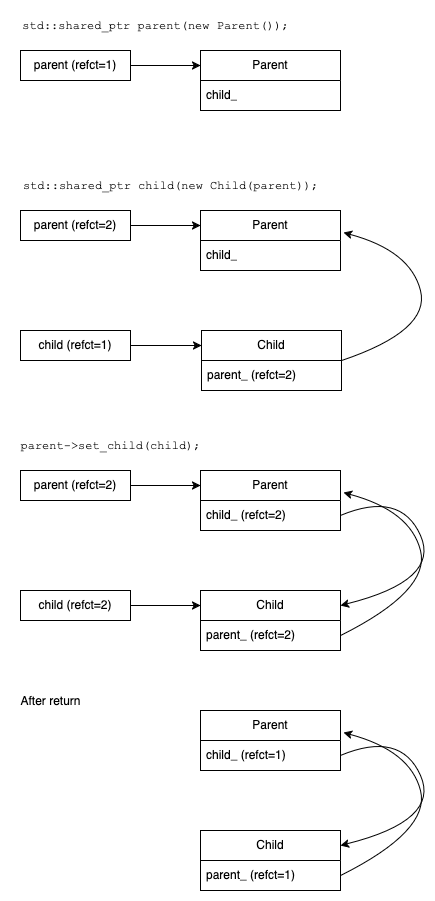
-
First, we allocate a new instance of
Parent, storing a pointer to it in the shared pointer local variableparent, with reference count=1. -
We then allocate a new instance of
Child, passing it a shared pointer toparent. The constructor forChildcopies the pointer toparentto its own internalparent_shared pointer, incrementing the reference count to 2. We then assign the newChildto the local shared pointerchild. -
We then tell our instance of
Parentabout our new instance ofChildwith theset_child()function, which copies the shared pointer into its own internalchild_shared pointer, incrementing the reference count to 2. -
Finally, when
make_family()returns, both local shared pointer instances are destroyed, decrementing the corresponding reference counts, with the result that each shared pointer now has reference count 1.
The reason that neither Parent nor Child is being destroyed is that
each is being owned by a shared pointer with reference count 1, held
by the other: Parent holding a shared pointer to Child and Child
holding a shared pointer to parent. Nothing else is pointing to either,
except for the the unboxed pointer to the Parent that we leaked for debugging
purposes, which you can ignore as it has no effect on the reference
count (you can easily reproduce this effect without returning that
as we did in the original program). Each object is keeping the other alive,
but they're not otherwise relevant.
What we've done here is reproduce the classic problem with reference counting for memory management: circular references. The basic assumption behind a reference counting system like shared pointers is that it assumes that the shared pointers are laid out in what programmers call a directed acyclic graph (DAG),[4] which is to say that there are no loops where if you follow the shared pointers from object A you eventually get back to A. If there are, then you can end up with objects which can't be freed even if all the references external to the loop are destroyed. In this case, the memory will be inaccessible but can't be freed.
Assuring Destruction #
OK, so we have some data which can't be freed? Is that such a big deal. It's important to recognize that when you are using RAII, this kind of error is not just a matter of wasted resource but a correctness issue because object destruction can have visible side effects.
As a simple, consider the following trivial code:
function write_stuff() {
std::ofstream file("x.out");
file << "Hello world";
}This just writes Hello world to the file x.out. However, there's a
lot hiding under that "just", because the program doesn't address the
disk hardware directly. Instead, it uses the "system call" write()
to ask the operating system to write some stuff to the disk, which
sets off a long chain of other events which I won't go into here. Each
call to write() is somewhat expensive, so programs typically will
buffer up individual writes internally and then flush the buffer
when it gets full or, critically, when the file is closed. In this
code, that is hidden by the use of RAII, which just magically takes
care of things when the function returns, but what's really happening
is something like this:
function write_stuff() {
std::ofstream file("x.out");
file << "Hello world";
// flush |file|
// free file's memory
}If something interferes with file being destroyed, then some data may
be left in the buffers, with the result that x.out will be truncated.
We can reproduce this by calling exit() at the end of write_stuff().
void write_stuff() {
std::ofstream file("x.out");
file << "Hello world";
exit(1);
}As the name suggests, exit() causes the program to exit, and it never
returns, which means that write_stuff() never returns, which means
that file is never destroyed (or, rather, that the destructor never
runs, because of course all the program memory is freed), which means
that anything still in the buffers is never written to disk. On my
computer (a Mac) the result of this program is a file containing only the
letter H, so presumably ello World is still in the buffer, lost
to us forever. The same thing would happen if instead we had some
bug that prevented the object from being destroyed, such as it was
held by some circular reference as above.
Note that the exact behavior you observe will depend on the precise
buffering strategy employed by your C++ implementation, as the
standard doesn't appear to prescribe one behavior. In fact, the astute
observer will note that I didn't end the write with a std::endl,
which adds a line feed to the end of the line; on my machine this
seems to cause the buffer to flush.
The key point here is that many nontrivial uses of RAII depend on the destructors actually executing at the right time, so defects like circular references, while not precisely a memory leak in the technical sense (each object is being pointed to by something), can lead to serious correctness issues.
Weak Pointers #
It's totally reasonable to want to make data structures which have reference loops, so if we can't just use shared pointers, what do we do? One option would be to have one of the pointers just be unboxed, but this undercuts the whole purpose of using smart pointers in the first place. What we instead need is a different kind of smart pointer called a "weak pointer".
Unlike other types of smart pointer, a weak pointer doesn't keep the pointed to object alive (in C++ jargon, it doesn't "own" it). This means that the object might be destroyed while you are holding the weak pointer. This means that you can have circular references as long as the reference in one direction is a weak pointer, because that breaks the cycle.
Because the object might be destroyed out from under you, in order to
ensure that a weak pointer is safely used, then, you need to temporarily
convert the weak pointer into a shared pointer using the lock() method.
This shared pointer keeps the object while you use it and when it
goes out of scope, you're still holding the weak pointer. For example:
std::shared_ptr<Temp> temp(new Temp());
std::weak_ptr<Temp> weak(temp);
std::shared_ptr<Temp> locked = weak.lock();
if (locked) {
locked->foo();
} else {
std::cout << "Object destroyed" <<std::endl;
}Importantly, if the underlying object has already been destroyed
(because the shared pointer reference count went to 0), the lock()
method can fail, in which case the resulting shared pointer will have
the value nullptr (pointing to nothing). This is an inherent
consequence of the fact that the weak pointer doesn't keep the object
alive.
While I'm not going to go into all the details of how to implement
weak pointers here (there are a number of techniques) I do want to
note that one way to implement it is for the shared pointer detail
object to maintain two reference counts, one strong, one weak. When
the strong reference count goes to zero, you destroy the object being
held. When both the strong and weak pointer counts are zero, you
destroy the detail object itself; this allows the weak pointer to
continue to exist and point to valid memory—though just to the
detail object—even if all the shared pointers have been
destroyed. This doesn't violate the RAII correctness guarantees
described above because the object is still destroyed, but it does
mean that there is some overhead from a weak pointer hanging
around even if the shared pointers are all gone.
When you have to unbox #
We now have unique_ptr, shared_ptr, and weak_ptr, which means we're
all set, right? Well, maybe. If you're writing totally new code,
then these three smart pointers are basically all you need, but if
you have to deal with older code which doesn't use smart pointers,
then you can run into problems.
Consider the following simple C-style API for timers.
void set_timer(unsigned int timeout, // How long to wait
void (*callback)(void *), // The callback to call
void *); // An argument to passThis is a bit abstruse, due to a combination of C's limited semantics and arcane syntax, but what it says is that you pass in three arguments:
- A timeout
- A function to call when the timeout expires
- An argument to pass to the function
In a modern language, you would either pass a Callback object that
encapsulated the callback and the context or, even better, a closure
that encapsulated all the relevant state, but neither of these is
available in C, so instead we have this.
You use this API this way:
void print_string(void *ptr) {
print("Called with argument '%s'\n", (char *)ptr);
}
set_timer(1000, callback, "Hello!");When the timer expires, print_string() gets called with a pointer
to the string provided as the third argument. Note that this can
actually be a pointer to any type of object (that's what void *)
means, and it's the job of the callback to know what type of pointer
it actually is and use it appropriately. The (char *)ptr means
"treat this as if it contains a string", which better be true
or things can turn very ugly very fast.
This is all fine, though a bit fiddly, but what happens if we want to pass some dynamically allocated object to the callback? In C, static strings are stored in the data segment so you don't need to allocate or free them, but what if we had a dynamically constructed string? In that case, we may need to free the object in the callback, like so:
void print_string(void *ptr) {
print("Called with argument '%s'\n", (char *)ptr);
free(ptr);
}We're back to C-style memory management here, but what if we want to work with an object which is owned by a smart pointer? We could unbox the pointer, like so:
shared_ptr<Foo> foo(new Foo());
set_timer(1000, do_something, (void *)foo.get());This works as long as foo outlives the timer, but there are
situations where you don't know the respective lifetimes. For
instance, consider what happens if you are making some
kind of network request and want to set a timer in case
the request takes too long. In this case, it could be either
the request error handler or the timer that is the last use
of the object, which is exactly the kind of problem that shared pointers
are designed to help you manage! What you actually want to do is
to pass the shared pointer to the callback handler, but this
impoverished API precludes that.
Internal Reference Counting #
One way to manage this situation is to move the reference count from outside the object (as in shared pointer) to inside the object. For instance, we can require that any managed object expose a reference counting interface like so:
class ManagedObject {
static void AddRef();
static void Release();
};Internally, the object has to maintain a reference counter which is
incremented whenever AddRef() is called. When Release() is called,
the reference counter is decremented. If the reference count reaches
0, Release() will destroy the object using delete this, which is
safe to do as long as you are
super-careful.
The implementation of the smart pointer itself looks sort of like
SharedPtr, except that it calls the AddRef() and Release() functions
rather than directly incrementing and decrementing its own reference
count.
If we adapt our program to use a reference counted pointer it looks like this:
void outer_function() {
{
Foo *f = new Foo(); // Reference count = 1
RefCountedPtr<Foo> foo(f); // Reference count = 1
foo->AddRef(); // Reference count = 2
set_timer(1000, do_something, (void *)foo.get());
}
// foo is out of scope. Reference count = 1
}
void do_something(void *ptr) {
// Reference count = 1, because |outer_function()| exited.
RefCountedPtr<Foo> foo((Foo *)ptr);
foo->do_something();
// object will be destroyed here.
}Note that unlike shared pointers, this still requires some attention
to the reference count. In particular, before we unbox the pointer
and pass it to set_timer() we need to manually increment the
reference counter. The reason for this is that the object is
essentially being owned by the timer infrastructure, and if we
didn't do that, then when outer_function() returned, the object
would be destroyed as the smart pointer went out of scope.
Perhaps less obviously, we have to manage what happens when the
RefCountedPtr takes ownership of an object: does it increment
the reference count or not? You need an option to have it leave
the reference count alone so that when it takes ownership in the
do_something() callback we don't end up with a reference count
of 2 rather than 1 (because it's being handed off from the timer
infrastructure to the callback). In this code I've opted to only
have that variant and force objects to self-initialize with a
reference count of 1, but another alternative is to have a flag
of some kind that tells the RefCountedPtr constructor
whether to increment or not.
Implementation Status #
C++ doesn't have a standard implementation of this kind of reference counted pointer, but the popular Boost C++ library project provides a version called intrusive_ptr, though it works a little differently than what I've sketched above.
Firefox makes very extensive use of internally reference counted
counted pointers using the RefPtr
template (the sketch above is sort of modeled on Firefox's
implementation). The decision to use this design is very
old (long predating my time at Mozilla) and dates from a time
when C++ didn't have good smart pointers. Once that changed
and good smart pointers were widely available, there were
a number of debates[5]
about which type to use (I was on Team
use the C++ standard) and so now Firefox contains a mix of
both styles. I don't know what decisions people would have been
made starting from scratch (though Chrome seems to use the
standard smart pointers a lot more, which is where I got used
to it).
Unboxing (again) #
As should be clear from the discussion above, unless you're writing totally greenfield code, it's very hard to avoid having to unbox pointers sometime. In my experience, engineers seem to have two attitudes towards this reality:
- Discourage it and make you work if you want to unbox.
- Lean into it and make it as easy as possible to unbox.
One of the core loci of this debate is whether you should be able to implicitly convert a smart pointer to a raw pointer, like so.
shared_ptr<T> t(new T());
T* t2 = t;Note that basically all smart pointers in C++ implement some unboxing
method like .get() and operator-> so that you can access methods
and properties; the question is whether you automatically convert to
T* in other contexts. Ordinarily this wouldn't work in C or
C++ because shared_ptr<T> and T* are totally different types and
you can't just assign one to the other. However, you can make it work
by implementing it
explicitly
as part of shared_ptr<T>.
The argument for implementing automatic conversion
this is that it makes it easy when you inevitably have to unbox; the
argument against it is that it's all too easy to unbox accidentally
and that you should have to do it explicitly. C++'s smart pointers
force you to call .get(). Firefox's do not
and in fact discourage calling .get().
I think this is the wrong answer but was not able to persuade enough
people to get it changed; it's easy to add affordances like this,
but much harder to remove them once people start to rely on them
and you need to change all the relying code.
This is all baked in #
One important thing to realize is that smart pointers aren't some new piece of C++ syntax; they're just a new combination of a number of existing C++ features, namely:
- Constructors and destructors to enable RAII
- Overloading the copy constructor, copy assignment operator, etc. provide the appropriate functionality for copying and assignment.
- Overloading
->(and sometimes automatic conversation) to make the smart pointer act like a regular pointer.
That's why we're able to implement our own smart pointers that do the same thing as the ones shipped with the C++ library. This kind of thing is something you see a lot with powerful languages like C++: people realize that they can put together existing features in new ways to produce new functionality that wasn't built into the language.
Next Up: Rust #
The major reason this is all so messy is that smart pointers are layered onto C++'s previously existing unsafe memory management system. This means that you can always opt out of smart pointers and use unboxed pointers, at which point you've given up all your safety guarantees. This is actually something you have to do sometimes—especially when you are working with legacy code—but the lack of compiler enforcement encourages you to do that rather than figuring out how to do things safely without unboxing. Next up, we'll be looking at a language which was built to be safe from the ground up: Rust.
It's not obvious why this should work, because we want to actually operate on
h->update()not get the internal pointer but the special sauce in C++ is that it will keep applying->until it gets something that makes sense. ↩︎Don't ask why the
&&syntax means move constructor; you don't want to know. ↩︎Note that there are some odd shenanigans in this code to deal with the fact that C++ requires that objects be declared before they are used. Because
ChildandParentboth reference each other, there is no order in which you can have the complete code forParentbefore or after the complete code forChild; instead we have to break them up a bit so the relevant pieces are available at the right times. Newer languages like Rust or Go tend to be better about looking ahead so you don't need to do this kind of thing. ↩︎Programmers love to say "DAG". ↩︎
Centering primarily around alleged performance concerns for incrementing and decrementing the reference count for shared pointer. ↩︎