Design choices for post-quantum TLS
Buckle your seatbelts, it's going to get rough
Posted by ekr on 30 Mar 2024
It's a cruel irony that just as encryption is finally becoming ubiquitous, quantum computers threaten to tear it all down.
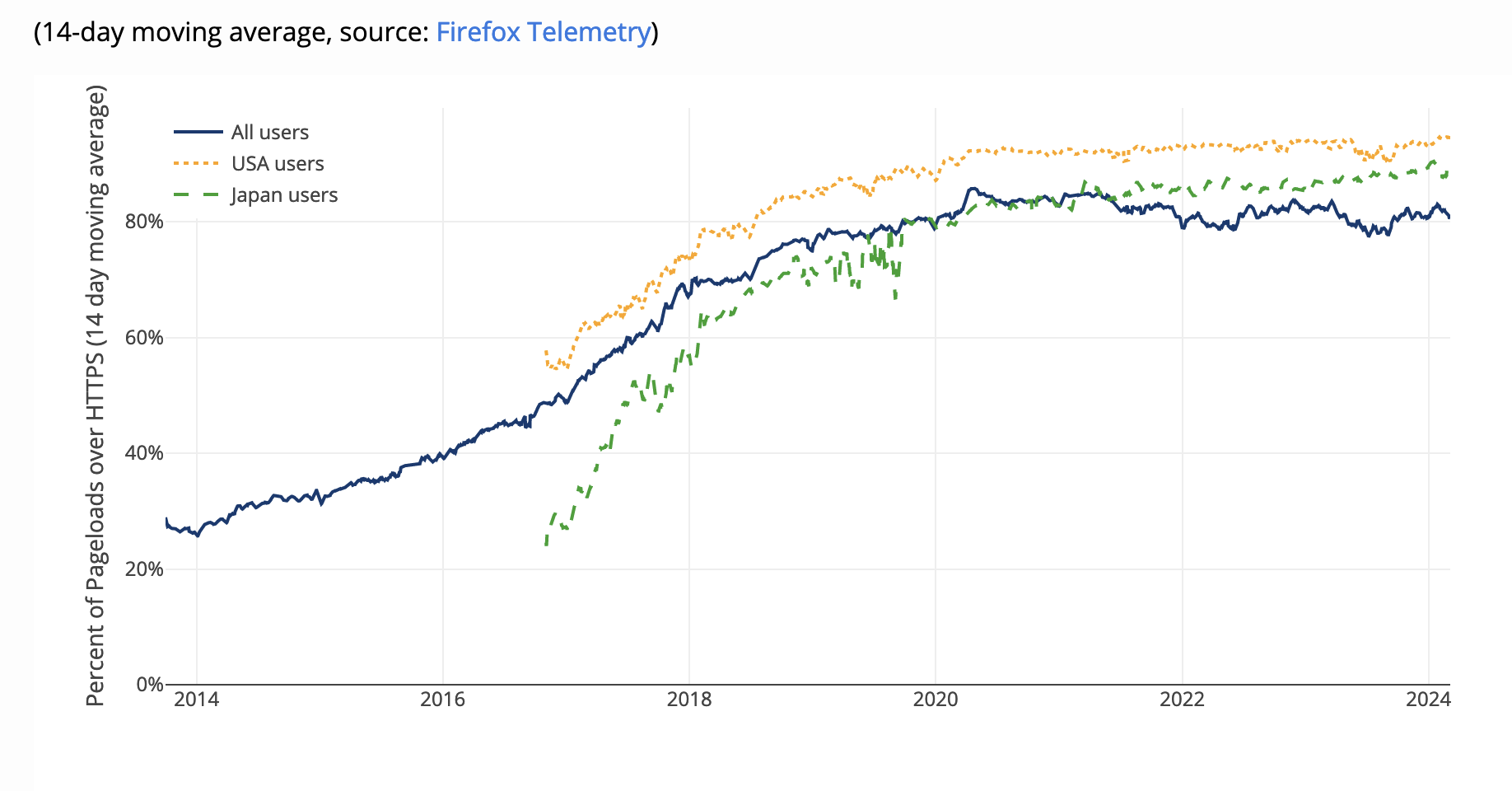
The technical details aren't that important (see here for some background), but the TL;DR version is that many of our cryptographic algorithms are designed to be difficult to break using "classical" computers (which is to say the kind we have now) but may not be difficult to break if you have a quantum computer, which takes advantage of quantum mechanical effects,[1] then it might be possible to efficiently break these algorithms.
I say might because the situation is somewhat uncertain in that while people have built quantum computers, they are currently quite small, nowhere near what you would need to mount an attack on a modern cryptographic algorithm. There's a lot of money being invested in developing quantum computers, but nobody really knows when we'll have what's called a cryptographically relevant quantum computer (CRQC), which is to say one which could mount practical attacks on the cryptosystems in wide use, or whether it's possible to build one at all.
There was the time Blueshell had a humor fit at Pham’s faith in public key encryption, and Ravna knew some stories of her own to illustrate the Rider’s opinion.
— Vernor Vinge, "A Fire Upon The Deep"
However, if a CRQC were to exist, the impact would be catastrophic, potentially rendering nearly every existing use of cryptography insecure. Specifically, it would break the "asymmetric" algorithms we use to authenticate other Internet users and to establish cryptographic keys, so an attacker would be able to impersonate anyone and/or recover the keys used to encrypt data. A CRQC probably won't have that big an impact on the actual "symmetric" encryption used to encrypt the data itself, but if you have the key you can just decrypt it with a regular computer, so that's not much in the way of comfort.
For that reason, researchers have started developing what's often called post-quantum (PQ) cryptographic algorithms which are designed to resist attack by quantum computers, or more properly, for which there are no known quantum algorithms which would allow you to break them (which isn't to say that those algorithms don't exist). After a fairly long competition, NIST published new standards for post-quantum key establishment (ML-KEM) and digital signature (ML-DSA)[2] and protocol designers and implementors are starting to look at how to adapt their protocols to use them.
In this post, I want to look at the challenges around that transition, focusing on the situation for TLS and the WebPKI, though some of the same concerns apply to other settings.
Why not just convert right now? #
The obvious question is why not just convert now, as we did when changing from older algorithms like RSA to newer ones based on elliptic curves (EC). The reason is that the new PQ algorithms are not clearly better than the EC algorithms that dominate the space now. Specifically:
- In many cases, performance is worse,
- in terms of CPU, key, ciphertext, or signature size. For instance, ML-KEM is faster than X25519 (the most popular current EC key establishment algorithm) but the keys are much bigger, over 1000 bytes compared to 32 bytes. The situation is much worse for signatures, where there really isn't any standardized algorithm which isn't a big regression from EC-based signatures in one way or another, and due to the large number of signatures that need to be carried in a typical protocol exchange, the size issue is a big deal, especially as there appear to be compatibility issues. These posts by Bas Westerban from Cloudflare and David Adrian from Chrome does a good job of covering the state of play of the various algorithms, but in general none of them has a better overall performance profile than EC.
- We're not sure that they're secure.
- There has been quite a bit of security analysis on the particular EC variants that are in wide use and while there has been a lot of work on the problems underlying ML-KEM and ML-DSA, my understanding is that there is still real uncertainty about how secure these systems are against classical computers. Daniel J. Bernstein (DJB) has been one of the biggest advocates for this view, but much of the industry is sort of antsy about the PQ algorithms.[3]
- We don't know if or even when we'll get a CRQC.
- Current quantum computers are very far away from being cryptographically relevant and of course progress is hard to predict. The Global Risk Institute has produced a report with estimates on when we will have a CRQC, with the results shown below:
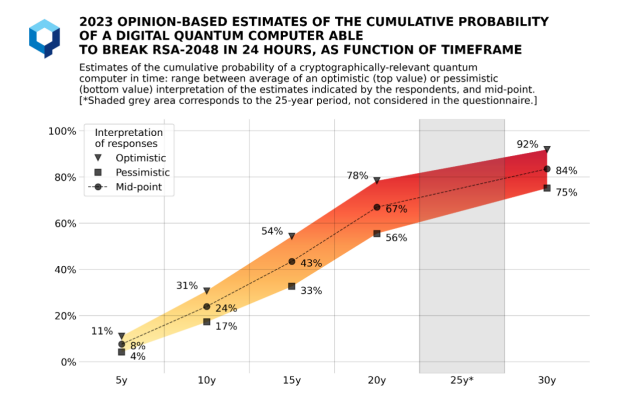
For these reasons, industry has generally been pretty cautious about rolling out PQ algorithms.
Threat Model #
Because classical key establishment and digital signature are based on the same underling math problems, the impact of a CRQC on these algorithms is also the same—which is to say very bad. However, the security impact is very different.
Key Establishment #
When you encrypt traffic, you want that traffic to remain secret for the valuable lifetime of the data. For instance, if you are encrypting your credit card number, you want it to remain secret as long as that credit card is still valid. Lots of information has very long lifetimes during which people want it to remain secret; presumably you wouldn't be happy with people learning your medical history 6 months from now.
When you encrypt traffic using keys derived via an asymmetric key-based establishment protocol—as with TLS—this means that you need that key establishment algorithm to also be secure for the lifetime of the data. In this context, that means that data that is being sent now using keys established with EC algorithms—which is to say most of it—might be revealed in the future if someone develops a CRQC. An attacker might even deliberately capture a lot of traffic on the Internet, betting that eventually a CRQC will be developed and they can decrypt it (this is called a "harvest now, decrypt later" attack).
For this reason, doing something about the threat of a CRQC to the security of key establishment is a fairly high priority, because every day that you use non-PQ algorithms you're adding to the pile of data that might eventually be decryptable. This is especially true because transitions can take a really long time even in the best case. For example, TLS 1.2 first added support for modern AEAD algorithms such as AES-GCM in 2008, but Firefox and Chrome didn't even add support for TLS 1.2 until 2013, and AEAD cipher suites didn't outnumber the older CBC-based ciphers until 2015. So, even in the best case, we're still going to be sending a lot of non quantum safe traffic for years to come.
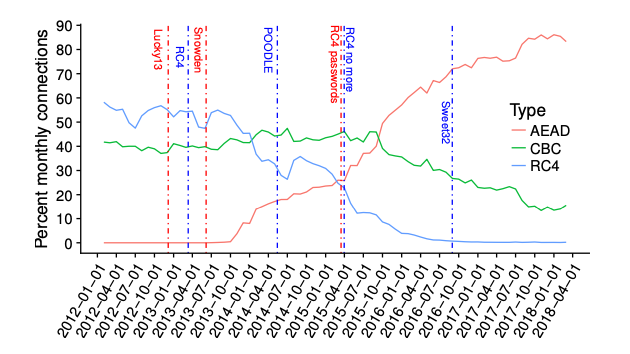
Negotiated cipher suites over time. From Kotzias et al., 2018
Digital Signature #
By contrast, a digital signature algorithm only needs to be secure at the time you make decisions based on the validity of the signature; in TLS this is at the time the connection is established. If a CRQC that breaks your signature algorithm is developed 30 second after your TLS connection is established, your data remains secure as long as you established a key using some non-vulnerable method (of course, your next connection won't be secure, so you'll want to do something about that).
Signatures for Object Security #
Note that the situation is different for signatures in object-based protocols like e-mail, because people want to be able to validate the signature long after the message was sent. Thus, having a PQ signature does help, even if paired with a classical signature, because it allows the signature to survive subsequent development of a CRQC.
It's also possible to allow a classical algorithm to survive the development of a CRQC by timestamping the signature to demonstrate that the classical signature was created prior to the development of the CRQC. For instance, you could arrange to register a hash of the signed document with some blockchain type system. You can then present the signed document paired with the timestamp proof (note that the timestamp service doesn't need to verify the signature itself; it's just vouching that it saw the document at time X.). The relying party can verify that the signature was made prior to the development of the CRQC, in which case it is presumably trustworthy.
For this reason, doing something about digital signatures is generally considered to be a lower priority, although of course it will be really inconvenient if a CRQC is built and we have no deployment of any PQ signature algorithms, as everyone will be scrambling to catch up. It's of course possible that someone—most likely some sort of nation state intelligence agency—already has a CRQC and isn't telling, but even then that's a lot less bad than having your communications be vulnerable to anyone who can get a QC shipped to them overnight as long as they have Amazon Prime.
This asymmetry in the threat model is convenient, because, as noted above, nobody is that excited about the PQ signature algorithms, whereas the PQ key establishment algorithms seem fairly reasonable—assuming of course that they're secure. As a result, people are focusing on key establishment and mostly keeping their fingers crossed that the signature situation will improve before it becomes an emergency.
Cryptographic Algorithms in Transport Security Protocols #
For the purpose of this post, I want to focus on transport security protocols like TLS. These aren't the only kind of cryptographic protocols in the world, but they illustrate a lot of the issues at play, in particular how we transition from one set of algorithms to another.
It's clearly impractical to just wholesale switch over from the old algorithms to the new algorithms at some point in time (what's often called a "flag day"). It took years (decades, really) to deploy everything we have in the ecosystem and any big change will also take time. Instead, TLS—and most similar protocols—are explicitly designed to have what's called algorithm agility, the ability to support more than one algorithm at once so that endpoints can talk to both old and new peers, thus facilitating a gradual transition from old to new.
The diagram below provides a stylized version of the TLS handshake.
The client sends the first message (ClientHello), which contains a
set of "key shares", one for each key establishment algorithm that it
supports.[4]
For Elliptic Curve algorithms, this means one key share for
each curve. When the server responds with its ServerHello message,
it will pick one of those groups and send its own key share
with a key from the same group. Each side can then combine its
key share with the other side's key share to produce a
secret key that both sides know.[5]
This shared key can then be used to derive keys to protect
the application data traffic.
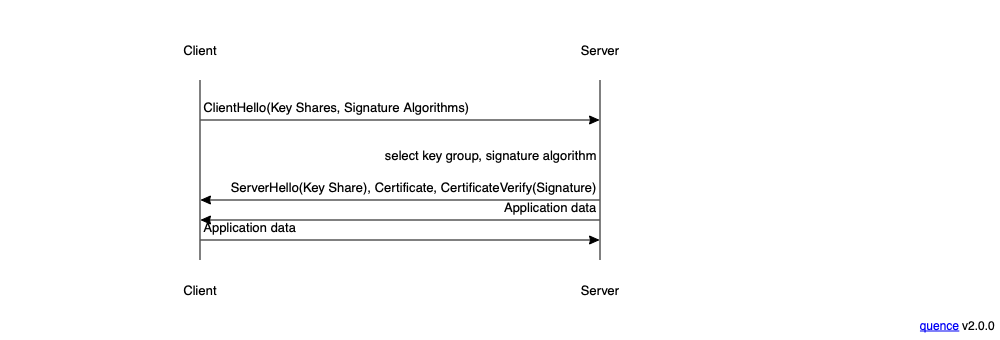
Of course, we also need to authenticate the server.
This happens by having the server present a certificate and then
signing the handshake transcript (the messages sent by each
side) using the private key corresponding to the public key
in its certificate. But as noted above, there are multiple signature
algorithms, so the ClientHello tells the server which signature
algorithms the client supports so that it can pick an appropriate
certificate. Of course, if the server doesn't have a certificate
that matches any of the client's algorithms, then the client
and server will not be able to communicate.
Note that there are actually several signatures here because the certificate both has a key for the server and is signed by some key owned by the CA. These keys may have different algorithms, and both have to be in the list advertised by the client. Moreover, the CA may have its own certificate and that signature also has to use an appropriate algorithm and then there are CT SCTs (I refer you again to David Adrian's post, which quantifies these).
Post-quantum algorithms fit neatly into this structure. Each PQ algorithm is treated like a new elliptic curve (even though they really don't have anything in common cryptographically) and signature algorithms just act the same (although, as noted above, the result is a lot larger). Even better, all of the generation and selection of key shares is done internally to the TLS stack,[6] so it's possible to roll out new key establishment algorithms just by updating your software without any action on the user's part (this is how EC was deployed in the first place). Of course, this is a lot easier if your software is remotely updatable or at least updates regularly; if we're talking about the software in a lightbulb, the situation might be a lot worse.
By contrast, in order to deploy a new signature algorithm you need a new certificate, and even though certificate deployment is partly automated now, it's not so automated that people expect new signature algorithms and the corresponding certificates to just pop up in their servers. Moreover, some servers are not set up to have multiple certificates in parallel. Given these deployment realities, the performance gap, and the threat model difference mentioned above, it shouldn't be surprising that there's a lot more activity around deploying PQ key establishment than around signatures.
The Current Deployment Situation #
In the past few years, we have seen a number of experimental deployments of PQ algorithms, primarily for key establishment.
Key Establishment #
Most of the key establishment deployment has been in what's called a "hybrid" mode, which is to say using two key establishment algorithms in parallel.
- A classical EC algorithm like X25519
- A PQ algorithm like ML-KEM
For instance, Chrome recently announced
shipping an X25519/Kyber-768 (Kyber is the original name for what
is now ML-KEM became ML-KEM after some modifications
[Updated 2024-03-30]) hybrid and Firefox is working on it as well.
The way that these hybrid schemes work is that you send key shares for both algorithms, then compute shared keys for both, and finally combine the shared keys into the overall cryptographic key schedule that you use to derive the keys used to encrypt the traffic. There are a number of ways to do this, but the way it's done in TLS 1.3 is simple: you just invent a new algorithm identifier for the pair of classical and post-quantum algorithms and the key share is the pair of keys. Similarly, the combined algorithm emits a new secret that is formed by combining the secrets from the individual algorithms. This works well with the modular design of TLS, because it just looks like you've defined a new elliptic curve algorithm, and the rest of the TLS stack doesn't need to know any better.
The advantage of a hybrid design like this is that—assuming it's done right—it is resistant to a failure of either algorithm; as long as one of the two algorithms is secure then the resulting key will be secret from the attacker and the resulting protocol will be secure. This allows you to buy some fairly cheap insurance:
-
If someone develops a CRQC the connection is still protected by the PQ algorithm.
-
If it turns out that the PQ algorithm is weak after all, then the traffic is still protected with the classical algorithm.
Of course, if the PQ algorithm is broken, then the traffic isn't
protected in the event that someone develops a CRQC, but at least
we're not in any worse shape than we were before, except for the
additional cost of the PQ classical [Updated 2024-03-30. oops.] algorithm, which, as noted above, is
comparatively low.
All of this makes a rollout fairly easy: clients and servers can independently add support for PQ hybrids to their implementations and configure their clients to prefer them to the classical algorithms. When two PQ-supporting implementations try to connect to each other, they'll negotiate the hybrid algorithm and otherwise you just get the classical algorithm. Initially, this means that there will be very little use of hybrid algorithms, but as the updated implementations are more widely deployed, you'll have more and more use of hybrid algorithms until eventually most traffic will be protected against a CRQC. This is the same process we historically used to roll out new TLS cipher suites as well as new versions of TLS, like TLS 1.3.
Of course, it won't be safe for clients or servers to disable support for the classical algorithms until effectively all peers have support for the PQ hybrids; if you disable support for them too early, then you won't be able to talk to anyone who hasn't upgraded, which is obviously bad. For many applications, this is a well-contained problem: for instance you can disable classical algorithms in your mail client as soon as your mail server supports the PQ hybrids. However, the Web is a special case because a browser has to be able to talk to any server and a server needs to be able to talk to any browser, so Web clients and servers are typically very conservative about when they disable algorithms. The standard procedure is to offer both new and old concurrently and then measure the level of deployment of the new algorithm and only disable the old algorithm when there are almost no peers who won't support the new algorithm. Unless there is some strong sign that CRQC is imminent, I would expect there to be a very long tail of clients and servers—especially servers—that don't support PQ hybrids, in part because PQ hybrid support is not present in TLS 1.2 but only TLS 1.3, and there are still quite a few TLS 1.2 only servers. This will also make it hard for browsers to disable the classical algorithms, even if they want to.
If a viable CRQC is developed, then it will be necessary for everyone else to switch over to post-quantum key establishment algorithms on an expedited basis, but that's not enough. If you accept classical algorithms for authentication, the attacker will be able to impersonate the server. This means that after the CRQC exists, you will also need to have everyone switch to PQ signature algorithms.
Signature #
By contrast, there has been very little deployment of PQ algorithms for signature, largely for the reasons listed above, namely that:
-
It's a lot harder to deploy a new signature algorithm than a new key establishment algorithm.
-
It feels less urgent because a future CRQC mostly affects future connections rather than current ones.
-
The signature algorithms aren't that great. And by "not that great" I mean that replacing our current algorithms with ML-DSA would result in adding over 14K of signatures and public keys to the TLS handshake. As a comparison point, I just tried a TLS connection to
google.comand the server sent 4297 bytes.
Before we can have any deployment, we first need to update the standards for signature algorithms for WebPKI certificates. From a technical perspective, this is fairly straightforward (aside from the performance and size issues associated with the certificates) in that you just assign code points for the signature algorithms. However, unlike the situation with key establishment, this is just the start of the process.
On the Web, certificate authority practices are in part governed by a set of rules (the baseline requirements (BRs)) managed by the CA/Browser Forum, which has historically been quite conservative about adding new algorithms. For instance, although much of the TLS ecosystem has shifted to new modern elliptic curves in the form of X25519, the BRs still do not support those curves for digital signature. So, the first thing that would have to happen is that CABF adds support for some kind of PQ algorithm or a PQ hybrid (more on this below). This probably won't happen until there are commercial hardware security modules that can do the PQ signatures.
Once the new algorithms are standardized, then:
-
The CAs have to generate new keys that they will use to sign end-entity certificates.
-
Those keys (embedded in CA certificates) need to be provided to vendors so they can distribute them to their users.
-
Certificate transparency logs need to also get PQ certificates.
-
Servers need to generate their own PQ keys and acquire new certificates signed by the PQ keys at CAs and CT logs.
Note that this transition is much worse than adding a new signature algorithm would ordinarily be. For instance, servers who wanted to use EC keys to authenticate themselves didn't necessarily need to wait for CAs to have EC keys themselves, because the CA could sign a certificate for an EC key with an RSA key, as RSA was still secure, just slower. This meant you could have a gradual rollout, and things got gradually better as you replaced the algorithms. But the whole premise of the PQ transition is that we don't trust the classical algorithms, so eventually you need to have the whole cert chain use the new algorithms. It's of course possible to have a mixed chain, but that's more useful for experimenting with deployment than providing actual security against a CRQC. In fact, as you gradually roll out, things get slower, but you don't get the security benefit until much later, which is actually the wrong set of incentives.[7]
Once all this happens, when an updated client meets an updated server, then the update server can provide its new PQ-only or PQ-hybrid certificate. Just as with key establishment, the client and server both need to support the classical algorithms until effectively every endpoint they might come into contact with has PQ support. This isn't a big deal for the client, but for the server it means that it needs to have both a regular certificate and a PQ certificate for a very long time.
However, unlike with key establishment, during this transition period neither client or server is getting any security benefit from using PQ algorithms. This follows from the fact that the security of the signature algorithm in TLS is only relevant at connection establishment time. There are two main possibilities:
-
Nobody with a CRQC is trying to attack your connections, in which case the classical algorithm was just fine
-
Somebody with a CRQC is trying to attack your connections, in which case they will just attack the classical key rather than the PQ key.
In order to get security benefit from PQ signatures in this context, relying parties need to stop trusting the classical algorithms, thus preventing attackers from attacking those keys. In the Web context, this means that Web browsers need to disable those algorithms; until that happens PQ certificates don't make anything more secure, but do make it more expensive, which is not a very good selling proposition.
For this reason, what I would expect to happen is wide deployment of client side support for PQ signatures but much less wide deployment of PQ certificates. The vast majority of clients are produced by a small number of vendors (the four major browser vendors) and this is a fairly easy change for them to make. By contrast, while servers are to some extent centralized on big sites like Google or Facebook or big CDNs, there are a lot of long tail servers who will not be motivated to go to the trouble. In particular, I would be very surprised if anywhere near enough servers adopted PQ-based signatures to make it practical to disable classical signatures absent from very strong pressure from the client vendors.
As a reference point, the first good attacks on SHA-1 were published in 2004, and SHA-1 wasn't deprecated in certificates until 2017. Moreover, even after Chrome announced that they would deprecate SHA-1, it still took three years to actually happen. The difference between SHA-1 and SHA-2 had had no meaningful impact on performance or on certificate size, so this was really just a matter of transition friction. This isn't an atypical example: the vast majority of certificates contain RSA keys and are signed with RSA keys even though ECDSA is faster (for the server) and has smaller keys and signatures.
There have been some recent changes to the WebPKI ecosystem to make transitions easier (e.g., shortening certificate lifetimes), but transitioning to PQ certificates has much worse performance consequences, so we should definitely expect the PQ transition to be a slow process.
Hybrids vs. pure PQ #
One of the big points of controversy is whether to mostly support hybrid systems that combine both classical and PQ algorithms or pure PQ algorithms. As noted above, the industry seems to be trending towards hybrids for key establishment, but the question of signatures is more uncertain.
Looming over all of this is the fact that the US National Security Agency and the UK GCHQ are strongly in favor of pure PQ algorithms rather than hybrids. In November 2023, GCHQ put out a white paper arguing for pure PQ schemes rather than hybrid:
In the future, if a CRQC exists, traditional PKC algorithms will provide no additional protection against an attacker with a CRQC. At this point, a PQ/T hybrid scheme will provide no more security than a single post-quantum algorithm but with significantly more complexity and overhead. If a PQ/T hybrid scheme is chosen, the NCSC recommends it is used as an interim measure, and it should be used within a flexible framework that enables a straightforward migration to PQC-only in the future.
Similarly, the NSA's Commercial National Security Algorithms 2.0 (CNSA 2.0) guidance contains some text that many read as saying they will eventually not permit hybrid schemes:
Even though hybrid solutions may be allowed or required due to protocol standards, product availability, or interoperability requirements, CNSA 2.0 algorithms will become mandatory to select at the given date, and selecting CNSA 1.0 algorithms alone will no longer be approved.
This isn't the clearest language in the world, but it seems like the best reading is they don't want to allow hybrids. On the other hand, at IETF 119 last week, NIST's Quynh Dang stated that NIST was fine with hybrids.
The specific timeline varies by product, but most relevant for this post, they say they want to have Web browsers and servers be CNSA 2.0 only by 2033:

It's a bit unclear what this means in practice for the Web, even if you read it as "pure PQ only". Recall that the way that TLS works is that the client offers some algorithms and the server selects one; this means that it should be possible for servers constrained by CNSA 2.0 ("national security systems and related assets") to select pure PQ algorithms as long as enough browsers support them, which seems somewhat likely, even though AFAICT no browser currently supports them. However, it's much less viable for a browser to only support PQ modes unless you never want to connect to servers on the Internet which, as noted above, are not likely to all support pure PQ. Are even government systems going to be configured to disable hybrids in 2035?
The CNSA 2.0 guidance is relevant for two reasons. First, there are likely to be a number of applications which are going to feel strong pressure to comply with CNSA 2.0. It's of course possible that if vendors just decide to use hybrids, that NSA ends up giving in and approving that, but people are understandably reluctant to find out. Second, GCHQ and NSA offer a number of arguments for why PQ algorithms as opposed to hybrids. This post is already getting quite long, so I don't want to go through them in too much detail, but they mostly come down to it's more moving parts to have a hybrid (hence more complexity, cost, etc.) and if there is a good CRQC, then the classical part of the system isn't adding much if anything in the way of security.
Another concern about hybrids is performance. Obviously, hybrids are more expensive than pure PQ, but the difference isn't likely to be a big factor. PQ keys and signatures are much bigger, so the incremental size impact of having the classical algorithm is trivial. ML-KEM is quite a bit faster than X25519, but X25519 is already so fast that my sense is that people aren't worried about this. Similarly, ML-DSA is about twice as fast as EC for verification but looks to about 4x slower for signing,[8] a bit misleading because in most uses of TLS it's the server that has to worry about performance and that's where the signature happens, so again the incremental cost of EC isn't that big a deal.
I'm not sure how persuaded I am by these arguments, but I think at best they are arguments at the margin. In particular, there's no real reason to believe that deploying hybrids is inherently unsafe, even if the classical algorithm is trivially broken. Assuming that we've designed things correctly, the resulting system should just have the security of the PQ part of the hybrid. I've seen suggestions that severe enough implementation defects against the classical part of the system (e.g., memory corruption) could compromise the PQ part. This isn't out of the question, of course, but modern software has a pretty big surface area of vulnerable code, so it's hard to see this as dispositive.
Inside Baseball: Code point edition #
For a long time, the IETF used to make it quite hard to get code point assignments, for instance requiring that you have an RFC. The idea was that we didn't want people using stuff that hadn't been reviewed and that the IETF didn't think was at least OKish. The inevitable result was that a lot of time was spent reviewing documents (for instance national cryptography standards) which the IETF didn't care about but were just needed to get code point assignments. Worse yet, some people would just use as-yet unassigned code points—this was easy because they're generally just integers—and if there was any real level of deployment, that code point became unusable whether it was officially registered or not.
The more modern approach is to make code point assignment super easy (effectively "write a document of some kind which describes what it's for") but to mark which code points are "Recommended" by the IETF and which are not. The "Recommended=Y(es)" ones need to go through the IETF process, but "Recommended=N(o)" code points are free for the asking. This has significantly reduced the amount of time that WGs spend reviewing documents for bespoke crypto and has generally worked pretty well. More recently the WG is adding a "Recommended=D(iscouraged)" for algorithms which the WG has looked at and thinks are bad.
Key Establishment #
As noted above, most of the energy in key establishment is in hybrid modes. They're easy to deploy now and seem safer than pure PQ algorithms, at least for now. In TLS in particular, what seems likely to happen is the following:
-
The TLS WG will standardize a set of hybrid algorithms based on ML-KEM on and recommend that people use them.
-
The IETF will assign a code point (algorithm identifier) for pure ML-KEM, but it won't be a standard and the IETF won't recommend (or disrecommend) its use.
The likely result is that there will be a lot of use of hybrids but people will be able to use pure ML-KEM if they want it. At some point, sentiment may shift towards pure ML-KEM, in which case the TLS WG will be able to take that document off the shelf and standardize it. However, as noted above, that isn't urgent even if there is a working CRQC: people can just burn a little more CPU and bandwidth and do hybrids while the hybrid → pure PQ transition happens.
Signatures #
The question of whether to use hybrids versus pure PQ for signature is still being hotly contested. As I mentioned above, it seems clear that servers will need both classical and PQ signatures for some time. The relevant question is exactly how they will be put together.
It seems likely that servers will have one certificate with a classical algorithm (e.g., ECDSA) as they do today and then have another certificate with a post-quantum algorithm. This could be in one of two flavors:[9]
- For a pure PQ algorithm (ML-DSA)
- For both a classical (e.g., ECDSA) and a PQ algorithm (ML-KEM). As with key establishment, these would be packaged into a single key and a single signature that was the combination of the two algorithms, with the semantics being that both signatures have to be valid.
For a while my intuition was that it was easier to just do PQ: because the PQ algorithms were so inefficient, clients and servers would largely favor the classical algorithms unless it became clear that the classical algorithms were insecure, and so it wouldn't matter much what was in the PQ certificates. And if it became clear that the implementations had to distrust the classical algorithms—which is going to be a super rocky transition anyway given the likely level of deployment of PQ certificates—then the classical part of the hybrid isn't doing much for you.
Now, consider the opposite case where instead the PQ algorithm is what's broken. At this point, you want to distrust that algorithm and fall back to classical algorithms. By contrast, to distrusting the classical algorithms, distrusting the PQ algorithms is comparatively easy because everyone is going to still have classical certificates for a long time, so relying parties (e.g., browsers) will probably be able to just turn off the PQ algorithm, in which case you don't really need a hybrid certificate for continuity.
This is all true as far as it goes, but it's also kind of browser vendor thinking because have really good support for remotely configuring their clients, so it really is practical to turn off an algorithm within days for most users. However, this isn't true for all pieces of software, many of which take much longer to update, and for those clients and servers the world will be much more secure if the only two credentials they trust are classical (still OK) and PQ hybrid (now just as secure as the classical credential). Moreover, it's also possible that there will be a secret break of the PQ algorithm, in which case even browsers won't update (the only thing we can do for a secret CRQC is to stop trusting the classical algorithms). For these reasons, I've come around to thinking that hybrids are the best choice for PQ credentials in the short term.
The Bigger Picture #
Getting through this transition is going to put a lot of stress on the agility mechanisms built into our cryptographic protocols. In many ways, TLS is better positioned than many of the protocols in common use, both because interactive protocols are inherently able to negotiate algorithms and because TLS 1.3 was designed to make this kind of transition practical. Even so, the transition is likely to be very difficult. While TLS itself is designed to be algorithm agile, it is often embedded in systems which themselves are not set up to move quickly.
-
Many proprietary uses of TLS—such as applications talking back to the vendor—should be able to switch pretty quickly and seamless. For instance, Facebook can just update their app in the app store and their server and they're done.
-
The Web is going to be a lot harder because it's such a diverse system and there isn't much in the way of central control on the server side. On the other hand, the browsers are generally centrally controlled by the vendors, which means that most of the browser user base can change quickly. There is of course a long tail of browsers in embedded devices (TVs, kindles, etc.) which may be much harder to update.
-
Beyond these two cases, there is going to be a long tail of TLS deployments which are in much worse shape and which can't be easily remotely updated (e.g., many IoT devices). Depending on how the clients or servers these devices need to talk to behave, they may either be stuck in a vulnerable state (if the peers don't enforce PQ algorithms) or just unable to communicate entirely.
Unfortunately, a rocky transition is actually the best case scenario. The most likely outcome is that absent some strong evidence of weakening of classical algorithms as a forcing function, we have a long period of fairly wide deployment of PQ or hybrid key establishment and very little deployment of PQ signatures, especially if the PQ signature algorithms don't get any better. Even worse would be if someone developed a CRQC in the next few years—long before there is any real chance we will be ready to just pull the plug on classical algorithms—and we have to scramble to somehow replace everything on an emergency basis. Fingers crossed.
Acknowledgement: Thanks to Ryan Hurst for helpful comments on this post.
Lots of stuff in your computer (the transistors, LEDs, etc.) are based on quantum effects, but fundamentally there's nothing that your computer does that couldn't be done by clockwork. This is something different. ↩︎
The ML stands for "module-lattice", which refers to the mathematical problem that the algorithms are based on. ↩︎
The situation here is a bit complicated. NIST is standardizing three schemes: ML-KEM, ML-DSA, and SLH-DSA. ML-KEM and ML-DSA are based on lattices, which have a fairly long history of use in cryptography. SLH-DSA is based on hash signatures which are also quite old, but has unsuitable characteristics for a protocol like TLS. Quite a few of the initial inputs to the NIST PQ competition have subsequently been broken (see this summary by Bernstein), including SIKE, which turns out to be totally insecure, which is disappointing because it had some favorable properties in terms of key size. There have also been some improvements in attacking lattices in the past few years, though they are not known to break either ML-DSA or ML-KEM. In addition to algorithmic vulnerabilities, some of the implementations of Kyber (the predecessor to ML-KEM) had a timing side channel, dubbed "KyberSlash". All in all, you can see why people might want to engage in some defense in depth. ↩︎
I'm simplifying here a bit, in that the client can actually advertise curves it doesn't send key shares for, but we can ignore that for the moment. ↩︎
Simplifying again. Each side actually generates a secret value and then computes their key share from that secret value. The shared secret is computed from the local secret and the remote key share. ↩︎
Although of course users can reconfigure it, at least in some systems. ↩︎
See my post on how to successfully deploy new protocols, coming soon. ↩︎
The numbers I have here are from Westerban and are for Ed25519, which isn't in wide use on the Web, but, at least in OpenSSL, EdDSA and ECDSA seem to have similar performance. ↩︎
There is actually another option in which you have a single certificate with the classical key in the normal place (
subjectPublicKeyInfo) and the PQ key in an extension. This certificate will be usable with both old and new clients, with new clients signaling that they supported PQ and then the server signing with both algorithms. This has the advantage of only needing a single certificate but otherwise is kind of a pain because it requires a lot more changes to TLS. In the naive way I've described it, it also involves sending a lot more data for every client, but there are ways around that. ↩︎