Understanding Online Identity
Posted by ekr on 02 Jun 2022
You often hear a lot about "identity" on the Internet, but in my experience, the situation tends to be pretty muddled. This post is my attempt to try to unpack a number of different concepts surrounding identity as well as some of the relevant technologies.
The most basic function that people think of when they think
of identity is what might more properly be called authentication,
which is to say proving that you are who you say you are.
In typical applications, this means proving that
you own/are associated with a specific identifier, whether
is an account name (e.g., ekr on Github), an
e-mail address (e.g., [email protected]), or a personal
name ("Eric Rescorla").
This kind of identifier mapping is good enough for a wide variety of applications, but in a number of cases people also want to be able to prove other facts about themselves, such as that they are over 21, have a license to drive, or have a given address.
As an example of these concepts, consider a drivers license:

This driver's license contains two identifiers:
- The driver's name: "Alexander J. Sample"
- The driver's license number: I1234562
Authentication of the license holder is performed by matching the biometrics on the license (mostly the picture, but also the various listed characteristics such as sex, hair color, etc.) to the person in front of you.
The license also carries a number of other attributes that might be interesting, such as the date of birth, whether you're an organ donor, what driver's license class you hold, etc. The way that this all fits together is that you show the driver's license to the TSA agents, the cop who pulled you over, or your bartender. They compare the biometrics to your appearance and assuming they match, they know—or at least have reason to believe—that the identifier and the attributes apply to you.
Identity on the Internet #
The situation on the Internet is somewhat different: most sites don't really need your legal name and biometric authentication mechanisms don't translate well into mechanical verification systems. Instead, most services use a different metaphor: the account.
Driver's Licenses on the Internet #
It's actually worth a moment to think about why your driver's license isn't a useful form of identity on the Internet. The problem isn't that the information on the license isn't relevant, but rather that there's no really good way to use them for authentication: pretty much all of the information on the license is public so anyone who has seen your license knows it and so it can't be used for authentication. In most contexts, there's no good way to check the biometrics (it's not like you had to do a video call to make a GMail account, though some systems do actually require this). Finally, although licenses do have anti-forgery mechanisms, they're mostly tied to the physical plastic and so don't really work in online contexts. This all adds up to it not being a very useful form of online authentication.
Accounts #
The basic idea behind an account is fairly simple. For each service you interact with, you have:
- An identifier (i.e., an account ID).
- Some authentication mechanism. Historically, this is a password (see my series on passwords for more on the deficiencies of passwords).
When you first interact with a given service, you register, creating an account. The service then assigns you an identifier (sometimes you are allowed to choose one, unless it's already in use, etc.) and collects your authentication information (password) and creates the account. From then on, you can log in to the account using your authenticator.
Example: Gmail #
For example, suppose you want to use Gmail. You go to the site and pick a username and a password, as shown below:
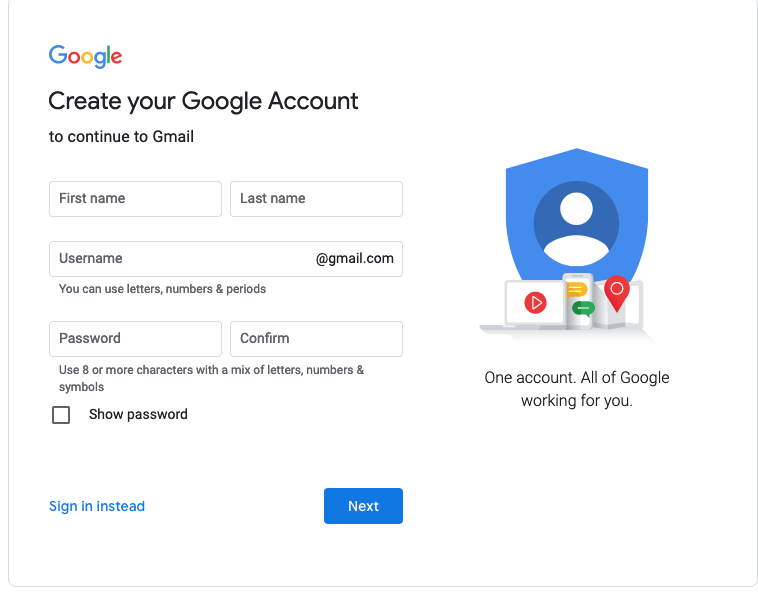
The username becomes your email address (with
@gmail.com appended to the end) and your password
becomes the authenticator.
But what about those other fields you enter, like your
name? Even though you're providing your name to Google and it
gets attached to your identity in some sense (e.g., it's
in the From line of your email), that Google isn't
actually doing anything to verify that it's yours; if you
want to call yourself Alan Smithee
or Fuzzy Dunlop, that's
your choice and Google will happily attach it to your
account.
By contrast, Google is authoritative for your
email address, so they know that's right: if they say it's [email protected] then
it is. If Google wants to take away your address and give
it to someone else, then they can just do so.
Example: Amazon #
As another example, consider Amazon. You go to their site and click the right buttons and get the following:
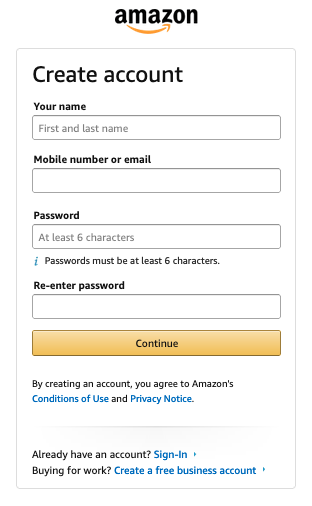
Superficially this is just like the Gmail account creation dialog, with your email address acting as your account identifier, but there's actually one very important difference: Amazon doesn't just let you pick an account name; they ask you to provide a preexisting identifier in the form of either an email address or a mobile number, which they then use as your account identifier (i.e., username).
Amazon doesn't just trust that you have the e-mail address you claim to have: they check it as part of account creation process. Moreover, in an important sense the email address is used as an authenticator because if you lose your password, Amazon can reset your account with your email address. That's not something that works with Gmail (if you lose your password you can't read your mail!), which is why they encourage you to set a recovery account with a separate address.
The Cookie #
Of course, on the Web once you've logged in with whatever mechanism (passwords, SMS, etc.) you need to authenticate subsequent requests. This is done with a cookie. Cookies can be incredibly long-lived, so in some sense the cookie is the authenticator.
What I'm getting at here is that Amazon is bootstrapping their identities off of another identity system, in this case either the email address or the public switched telephone network (PSTN). They rely on those systems to maintain people's identities, assure they are unique, and ultimately for authentication. A system like this really has two kinds of authenticators:
- The password
- The ability to receive a message at the indicated address.
It's not uncommon to see systems where you have to demonstrate both of these in order to log in; this is one form of multi-factor authentication (MFA). I've also seen systems which don't have passwords at all and just require you to demonstrate the ability to receive at a given address.
Federated Authentication #
In the example above, the Amazon account is bootstrapped off of your email or phone number, but once that's happened, you authenticate to Amazon directly using your password. In other words, Amazon has outsourced your identity to the e-mail/phone system but still controls authentication for itself. It's possible to go further, however, and outsource authentication as well. Consider, for example, the account creation interface for the popular sports social network Strava:
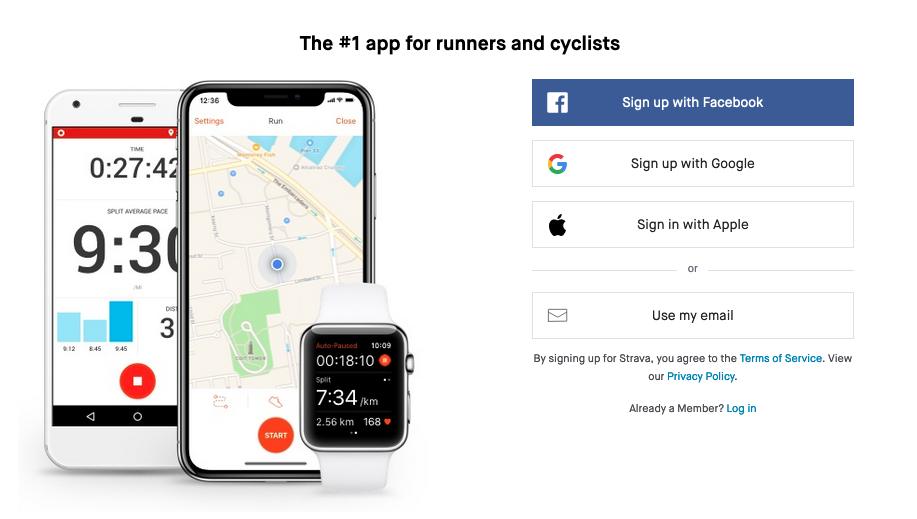
The "Use my email" option is basically the same as with Amazon, where they use your e-mail address as your identifier but thereafter use a password, but "Sign up with Google" (or Facebook or Apple) is different. In this case, you authenticate with Google (or Facebook or Apple) as well. The way this works is that if you already have an account with one of these big services they can act as an identity provider (IdP) which authenticates you to third parties. The technical details are fairly complicated, (see OAuth and/or OpenID [Edited to add OpenID 2022-06-02]) but at a high level, what happens is that the service either (1) exposes an API called by the third party site (the technical term here is relying party (RP)) or (2) provides the client with a token [Edited to add tokens -- 2022-06-03] which it gives to the RP. In either case, this allows the third party site to:
- Verify that the browser contacting it is associated with a particular account on the IdP
- Learn some details about that account.
When you first register with the RP, they will typically bounce you to the IdP so you can approve information sharing with the RP and then from then on, they can talk to the RP without explicit consent. For instance, here's what Google shares with Strava:
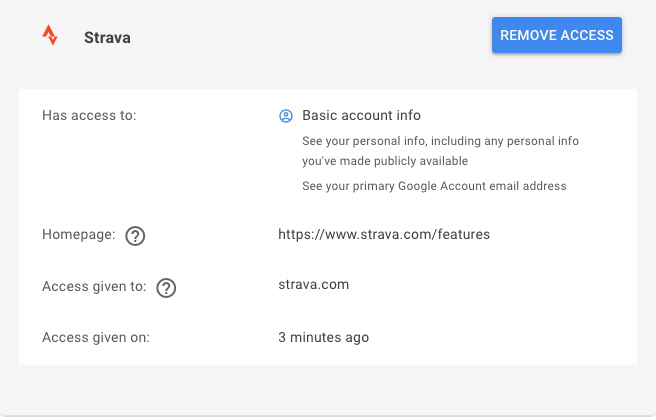
This mechanism, generally referred to as "federated authentication"[1]
has a number of important advantages from the perspective of the RP. First, it avoids needing to create your own credential management system: you don't need to check password quality, store passwords (and worry about the password hashes leaking), or deal with users losing their passwords and needing to reset them (this is surprisingly common!). In addition, it streamlines the user account creation process, by eliminating the need to create a password—or often an account name—as well as the need to process the email verification from the RP, which can be a place that user account creation can stall, causing you to lose potential users.
Finally, the IdP may also offer APIs that give the RP additional capabilities, such as learning more information about the user's account (for instance, your name and your social contacts) or even to interact with the IdP on the user's behalf. For instance, it's common for developer services sites like CircleCI to use GitHub authentication and then ask for fairly broad permissions such as to read from and write to your git repositories. This allows them to integrate tightly with your developer experience, but of course without having your password.
As with a direct 1:1 authentication system like a password, sites will generally persist the user's information in a cookie. However, if the user clears their history, moves to a new computer, or the cookie just expires, instead of asking for the user's password instead the site will re-validate the user with the IdP.
Enterprise Single Sign-On (SSO) #
The previous examples were largely for end-users, but suppose that you operate a company and want to outsource employee services such as payroll or expenses. These services are now frequently packaged as what's called Software as a Service (SaaS) which is a fancy name for "we have a Web site that your employees use".
Obviously, your users need to authenticate to these SaaS services, and in principle you could have them create an account on each of these services, have the service check their e-mail addresses, and move forward. However, this has a number of obvious drawbacks, including:
-
Increased friction for each user, especially if you have a lot of these services, which is not at all uncommon.
-
Lack of unified access control policies. For instance, if you want to require 2FA, you can enforce this centrally rather than having to reach out to every SaaS provider you use.
-
Lack of control. For instance, if a user quits, how do you notify each SaaS provider to terminate their account?
These drawbacks can be addressed by using essentially the same technologies as described in the previous section. In this case, the company (or more likely some third party like Auth0 or Okta [Edited to add Okta -- 2022-06-03] acts as the IdP, with each of the SaaS providers acting as the RP.[2] When an employee wants to use one of your SaaS providers (e.g., to do their expenses), they first authenticate to your IdP and then use the IdP to authenticate to the provider. The IdP login can be long-lived, allowing the user to authenticate to multiple IdPs without logging in repeatedly (hence the "single sign-on" name). This kind of system also allows the company to track logins, manage access, and disable/suspend accounts.[3]
Real-World Identities #
You may have noticed that none of the above does much about your real world identity. As a general matter, sites just take your assertions about your identity at face value, allowing you to use whatever name you want, as well as to claim to be any age you want etc. Some social networks try to require you to use your "real name" (see, for instance, Facebook's real name policy), but not too much hangs on this and they generally don't try super hard unless you claim to be someone famous or your name looks fake (though, as the link above indicates, "looks fake" is a subjective standard and lots of people have names that someone—or some algorithm—at Facebook might think were fake.)
In some cases, sites will make an attempt to actually verify your name, but the mechanisms are often kind of weak. For instance, in order to get a Twitter "blue Verified badge" you can send Twitter a photo of your driver's license. This isn't nothing, but it's also not at all difficult to photoshop yourself a fake driver's license, given that it doesn't have to pass much scrutiny and the anti-counterfeiting mechanisms such as holograms and the like don't work through the Internet.
There are a few situations in which a service will attempt to create a stronger binding between your legal identity and your account, typically where money is involved. For instance, you might need to provide your social security number, account number, mother's maiden name, your ATM PIN, or demonstrate that you know the amounts of some recent transactions. Often, these mechanisms work by leveraging some preexisting relationship (account) you have with the service and then linking your online account to that preexisting account, so it's not like they are trying to authenticate someone they have never heard of.
What's wrong with this picture? #
As noted above, the ergonomics of having to make an account on every new system are fairly bad: it requires the user to have a large number of passwords, which is more opportunities to use a bad password or to lose your password and have to recover. There are some opportunities for improvement around the margin (e.g., WebAuthn instead of passwords for authentication), better form fill-in so users don't have to type their name over and over, etc, but at the end of the day, there's only so much you can do.
On the other hand, the existing federated authentication mechanisms have a number of pretty serious drawbacks.[4]
Centralized Control #
The first big problem with the existing federated identity systems is that they inherently tie you to a small number of centralized identity system. First, for RP A to accept an identity from IdP B, A needs to actually make some kind of arrangement with B. This is typically pretty lightweight, but probably involves establishing some kind of pairwise API key. Second, because A has no way of knowing which IdPs a user has accounts with, it has to offer the user a separate button for each one, like so:

Fixing the NASCAR Problem #
The reason that the NASCAR problem is hard to fix is that these federated identity systems use existing Web technologies and there's no way with those technologies to know which IdPs the client has an account with, so it just has to show all the logos. If there were such a way then we would have a privacy problem, because then you could use the set of IdPs the client had an account with to track them, or, worse yet, use the same mechanism to encode the user's identity by creating a pattern of account/no-account states with various sites you controlled.
This is sometimes called the NASCAR problem because it resembles the various advertiser logos you see on NASCAR cars. This of course contributes to a lousy user experience but also discourages the site from adding additional IdPs, because each one adds to user confusion.
When put together, existing federated authentication systems provide a strong incentive to only accept identities from the biggest IdPs, which promotes centralization and makes it hard for new providers to enter the market.
Privacy #
In general, the privacy properties of existing federated authentication systems are quite bad. Every time you log into site A with IdP B, B learns about it. This allows your IdP to track you around the Internet whenever you use it to log in. This is made worse by the high level of centralization in two ways. First, because it is hard to start a new IdP it is hard for users to find one that has better privacy, whether in terms of better policies or better technology. Second, because there are a small number of IdPs, this creates concentration of this tracking information. In addition, many of the existing IdPs already do a lot of Web tracking via other mechanisms.
Another privacy problem is that IdPs typically provide the same identifier (e.g., your e-mail address) to each RP. Sites can use these identifiers to track users (see this post by Steve Englehardt on this topic). This is actually technically soluble by having the IdP give a new identifier to each site, but this is not general practice, in part because sites want the user's true identifier so that they can contact you. This problem also exists with conventional e-mail/password systems but can be addressed with e-mail masking systems like Firefox Relay or Apple's Private Email Relay.
Improving Federated Identity #
There has been a fair amount of work over the years on building federated identity systems with better properties.
End-User Certificates #
In the early days of the Web—well before things like Google Login existed—a lot of people thought that users would authenticate with certificates: every user would be issued a certificate with their identity, much like Web sites have certificates that attest to theirs. Presumably these certificates would have the user's e-mail address and maybe their name. They would then be able to use TLS certificate-based client authentication to authenticate to every server. This has much the same identity properties as federated identity, but has better privacy properties because the CA doesn't need to be involved in the authentication transaction and so doesn't learn what sites you are going to.
Client certificates also potentially have better centralization properties.[5] In particular, client certificates have the potential to fix the NASCAR problem because the client knows which certificates you have, so the site doesn't need to display the logos of every CA you might have a certificate with.
Needless to say, this never happened; TLS client authentication is in use in some settings, typically for enterprises which issue their own certificates but never really became a plausible competitor to passwords and then federated authentication came along. There are quite a number of reasons for the failure of client certificates, but any list would probably include:
-
The lack of certificate authorities which would issue convenient free client certificates (this was true for server certificates too until Let's Encrypt).
-
The TLS interaction is pretty bad in a number of ways, such as playing badly with TLS intermediaries such as CDNs and, prior to TLS 1.3, leaking the client's certificate if you did authentication at the beginning of the connection.
-
A truly hideous UI. I've shown the Edge UI below but all of the browser client auth UIs are pretty bad.

[Source: Eric Lawrence]
In addition, because you use the same certificate for every site, it can be used to track you across sites, which is obviously a privacy problem, though, as noted above, is not a property unique to client certificates.
Persona and FedCM #
Although client certificates never really took off, they have a number of good properties and are a natural starting point for trying to improve the situation.
Mozilla took a fairly serious run at this some years back
with Persona.
Effectively Persona
worked by making every site its own certificate authority; they
could then issue certificates to browsers which used them for authentication,
so for instance example.com could issue certificates for addresses
ending in @example.com. The browser would then use those
certificates to sign into sites. This was intended to have the
benefits of certificate-based authentication but be easier to
deploy and more compatible with Web technologies.
One very important property was that
because the site could use
the certificate to authenticate to any server, it didn't
allow the IdP to track the user.
The obvious way to implement Persona was with browser support: when the user creates an account with an IdP, the browser would keep track of it. When the user wants to log into a site, it calls a browser API, which causes the browser to present a list of acceptable IdPs which the user can choose from, thus avoiding the NASCAR problem and giving the user more direct control over how their information is being used. In practice, the initial Persona deployments depended in a trusted web site to help mediate this interaction, thus avoiding the need to modify browsers.
Persona ultimately failed to gain much market traction and Mozilla stopped working on it, but it inspired other designs, such as Chrome's Federated Credential Management API (FedCM). FedCM is a more modest increment on the current federated authentication model intended largely to make federated identity continue to work in environments where third party cookies have been removed, but also to have some additional privacy benefits. Unlike Persona, it doesn't really address centralization, though it's possible that it could be extended to do so.
FedCM is relatively new and so hasn't seen any real deployment. It's an open question whether it will get any deployment or whether any of the big IdPs such as Google or Facebook will support it (see deployment below).
Other Cryptographic Identity Systems #
Recently there has been increasing interest in the use of cryptographic identity systems that are often called "decentralized" or "self-sovereign" what's called "self-sovereign" or "decentralized" identity. Here's how Sovrin describes this:
Everyone (including businesses and IoT) has different relationships or unique sets of identifying information. This information could be things like birth date, citizenship, university degrees, or business licenses. In the physical world, these are represented as cards and certificates that are held by the identity holder in their wallet or safe place like a safety deposit box, and are presented when the person needs to prove their identity or something about their identity.
Self-sovereign identity (SSI) brings the same freedoms and personal autonomy to the internet in a safe and trustworthy system of identity management. SSI means the individual (or organization) manages the elements that make up their identity and controls access to those credentials– digitally. With SSI, the power to control personal data resides with the individual, and not an administrative third party granting or tracking access to these credentials.
The SSI identity system gives you the ability to use your digital wallet and authenticate your own identity using the credentials you have been issued. You no longer have to give up control of personal information to dozens of databases each time you want to access new goods and services, with the risk of your identity being stolen by hackers.
This is called “self-sovereign” identity because each person is now in control of their own identity—they are their own sovereign nation. People can control their own information and relationships. A person’s digital existence is now independent of any organization: no-one can take their identity away.
Controlling your own identity sounds good, but it's remarkably difficult to get a clear picture of precisely what people have in mind here. For example, in an early post on the topic, Christopher Allen writes:
With all that said, what is self-sovereign identity exactly? The truth is that there’s no consensus. As much as anything, this article is intended to begin a dialogue on that topic. However, I wish to offer a starting position.
Rather than try to offer a definition, the rest of this section instead focuses on what's technically possible in this space.
In general, the starting point for these systems is to root identity in a cryptographic key. I.e., I create a public/private key pair and my public key then becomes my identity. This has the convenient property that it's self-authenticating: I don't need to use a password or any other authenticator because I can prove my identity just by signing a challenge with my private key. In principle I could just create an account by giving you my public key and having that be the account ID.[6]
Attributes #
Unfortunately, as-is this system also has a number of significant drawbacks. First, as we've seen throughout this post, sites don't want to address users through opaque identifiers, they want to attach them to some means of contacting them, like an e-mail address or a phone number. This is partly because sites want to actually be able to contact their users and—at least at present—it's not really practical to message users via their public key pair and partly because it lets them deal with exceptional cases like account recovery.
Most of the decentralized identity systems I have seen proposed have some mechanism to attach more meaningful attributes to a given identity. The simplest version is effectively a certificate, i.e., a signed statement that a given public key belongs to someone with the following properties (e-mail, name, date of birth, etc.). A number of these systems use fancy cryptography to allow for selectively disclosing pieces of these attributes (e.g., "I am over 21" but not my birthday). However, it's a bit unclear who would do this signing; for instance, who would you trust to attest to my personal name? The government? Which government? How about my email address?
Key Recovery #
The second problem with this kind of system is that if you lose your private key you lose access to your account—or more likely, all your accounts. There are a lot of proposed mechanisms for addressing private key loss (e.g., secret share your key with 10 of your closest friends) but you can be sure that plenty of people won't do them. Long painful experience shows that users lose their credentials quite frequently, don't do much to plan ahead for that event, and any system that doesn't recover gracefully if the user drops their phone in the toilet is going to have a lot of dissatisfied customers.
Of course, you can always create a new key and then get the same attributes attached to it—and potentially detached from the old key. Depending on the precise structure of the system, this may or may not be technically possible (for instance, you could have a system where each e-mail address was registered on the blockchain and nobody could ever re-register it). However, as we saw with blockchain-based DNS systems, the problem becomes that the same mechanisms which are designed to give you complete control of your identities independent of third parties also make it difficult for those third parties to help you recover your identity if you lose your keys. Obviously, this makes a lot more sense for attributes which aren't unique, such as your age, but at the end of the day you're still at the mercy of the people attesting to your attributes, and those, not your key, become your true identity.
Independence #
At the end of the day, I'm not sure how much these systems really deliver on the independence value proposition of self-sovereignty that I quoted above. The problem here is that there are two kinds of identities in play:
-
A trivial form of identity which is basically "I am the person with this public key".
-
A deeper form of identity which ties that key pair to other attributes which people actually care about, such as your name or e-mail address.
The first type of identity is indeed independent in the sense that it's hard to take away from you and you don't need anyone's help to exercise it. The second, however, depends on a whole infrastructure of third parties who are busily attesting to various properties that are then somehow attached to your key pair. And for the system to function properly, you need them to do that attestation not just once but regularly. This statement may come as a surprise, but in real identity systems you generally need some way to revoke assertions when you discover (for instance) that people's keys have been compromised or that the assertion was issued incorrectly. You need to be able to do this without the cooperation fo the subject, and so that means that in practice the attesting entity needs to be involved pretty regularly and so you're not really able to exercise those forms of identity independently from them.
This is not to say that you can't use cryptography to build identity systems that will have better properties than our current third-party identity systems, especially in the area of privacy and tracking by the IdPs. However, it seems to me that it's mostly the decoupling of the identity assertion from the IdP—as in Persona—that provides that value, not having them be decentralized or rooted in an identity tied to a specific cryptographic key.
Deployment #
A major challenge with any new identity system is getting broad-scale deployment. Specifically, it's not worth it for RPs to support a new IdP unless that IdP has a lot of existing users. Conversely, it's not worth users creating accounts with an IdP unless a lot of RPs accept that IdP. This deadlock makes it hard to get going with something new, and it should come as no surprise that all the major public IdP systems are associated with services like Google, Facebook, or Twitter which already have large user bases of people who use the service for some other reason. This allows them to easily offer a valuable authentication service and makes it worthwhile for RPs to accept them. Any new identity system will somehow have to get past this.
Right now, this dynamic makes it difficult for a new IdP to enter the market even if its APIs are basically identical to an existing IdP, both because the existing systems tend to need prior arrangement and because the NASCAR problem makes it expensive for RPs to support a new IdP. However, this need not be the case: it's possible to design an identity protocol which works with any IdP without prearrangement—indeed Persona was such a protocol—but in order for that to get off the ground you'd still need some large IdP to support it in order to bootstrap RP support. For obvious reasons, that kind of interoperability is not really in the interest of existing IdPs, and most of the proposals I have seen for improving the situation don't come from IdPs.
The same basic situation applies to cryptographic identity systems. It takes extra work on the part of the RP to support such a system and that work is hard to justify if there's no additional benefit, either in terms of getting a lot of users that you couldn't get before, or in terms of some new capability that you can get for a lot of existing users (like learning information you couldn't learn before).
It's important to recognize that this dynamic applies even if the new systems are better for users, because the users can only really choose between the systems supported by the RPs. For instance, if you as a user use some new identity system X that has much better privacy, but the site you want to go to only supports Google Login, you can either use Google Login or not, but you can't force it to use X. Once an IdP is well established and widely supported then users choosing it has some impact at the margin, but it's hard to make a system take off through user choice along.
Summary #
Identity on the Internet is a difficult problem. Having to make an individual account for each site is clearly bad. On the other hand, between a high level of centralization and a low level of privacy provided by third-party authentication systems is also not great. However, the network effect dynamics of identity systems make it very hard to deploy something new without the cooperation of some system that has a lot of users, which is to say the services who are benefiting from the existing system. For that reason, my first question whenever someone proposes deploying a new identity system, my first question is "who is going to provide the identities and how many users do they have already?"
The terminology here is a bit confusing. For instance some people draw a distinction between "delegated" identity systems in which the RP is outsourcing identity to a given IdP and ones in which the RP can use any IdP. in practice, it seems to me that most of the deployed RPs allow a small number of IdPs but not any IdP. To some extent there is a policy decision about which IdPs to support, but as described in this post, it's also the case that some technological approaches are more suited to allowing an arbitrary number of IdPs than others. My sense is "federated" is the more common term, so I'm using that here. [2022-06-03] ↩︎
In the third party case, the third party would somehow hook into your identity system so it could authenticate users. ↩︎
Because of cookies, this doesn't necessarily happen instantaneously, but you can configure things so that the RP requires the user to re-authenticate frequently, thus giving the IdP a chance to say that the user's account is suspended. ↩︎
I'm largely excluding enterprise SSO systems, as they serve a different purpose, and while in my experience they're a bit clunky, it's more just generic software kludginess than it is architectural/ecosystem issues. ↩︎
Given that roughly half the Web certificates in the world are issued by Let's Encrypt, we shouldn't get too optimistic about decentralization in the certificate market. ↩︎
We actually do see the use of public keys for authentication in practice, but usually in the form of attaching a public key to an existing account, rather than using it as the account identifier. ↩︎