Understanding Memory Management, Part 5: Fighting with Rust
Posted by ekr on 20 Apr 2025

This is the fifth post in my planned multipart series on memory management. You will probably want to go back and read Part I, which covers C, parts II and III, which cover C++, and part IV, which introduces Rust memory management. In part IV, we got through the basics of Rust memory management up through smart pointers. In this post I want to look at some of the gymnastics you need to engage in to do serious work in Rust.
Unexpected Moves #
Consider the following simple Rust code:
fn main() {
let x = vec![1, 2];
for y in x {
println!("{}", y);
}
println!("{}", x.len());
}This is straightforward: we create a vector containing the values
[1, 2], then iterate over it and print each element, and then
finally print out the length of the vector. This is the kind of
code people write every day. Let's see what happens when we compile
it.
Error[E0382]: borrow of moved value: `x`
--> iter_into.rs:7:20
|
2 | let x = vec![1, 2];
| - move occurs because `x` has type `Vec`, which does not implement the `Copy` trait
3 |
4 | for y in x {
| - `x` moved due to this implicit call to `.into_iter()`
...
7 | println!("{}", x.len());
| ^ value borrowed here after move
|
note: `into_iter` takes ownership of the receiver `self`, which moves `x`
--> /Users/ekr/.rustup/toolchains/stable-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/iter/traits/collect.rs:346:18
|
346 | fn into_iter(self) -> Self::IntoIter;
| ^^^^
help: consider iterating over a slice of the `Vec`'s content to avoid moving into the `for` loop
|
4 | for y in &x {
| +
error: aborting due to 1 previous error
For more information about this error, try `rustc --explain E0382`.
make: *** [iter_into.out] Error 1
No joy! The error message is reasonably helpful, though:
note: `into_iter` takes ownership of the receiver `self`, which moves `x`At a high level, here is what is happening.
- The
for y in xsyntax tells Rust you want an iterator - In order to produce that iterator, Rust calls
x.into_iter(), defined by the trait IntoIterator which results in an iterator overi32. - The iterator takes ownership of the input vector
x.
In the spirit of this series, though, let's dig one level deeper. You can ignore the rest of this section if you don't really care about Rust details, but this took me a little while to work out, so it's going up on the Internet.
The for y in x expression in Rust is syntactic
sugar
for creating an iterator. The x value must implement the
IntoIterator
trait, which has the method into_iter():
pub trait IntoIterator {
type Item;
type IntoIter: Iterator<Item = Self::Item>;
// Required method
fn into_iter(self) -> Self::IntoIter;
}.into_iter() returns an
Iterator
object which exposes a .next() method that returns the next value
in the iterator. You can loop over the iterator by calling .next()
until it returns None (see
here
for some background on union types in Rust). For reference, here's what
the Rust reference says is the equivalent code to for ...:
{
let result = match IntoIterator::into_iter(iter_expr) {
mut iter => 'label: loop {
let mut next;
match Iterator::next(&mut iter) {
Option::Some(val) => next = val,
Option::None => break,
};
let PATTERN = next;
let () = { /* loop body */ };
},
};
result
}As the code above says, Rust implicitly calls IntoIterator::into_iter(x),
which is to say it calls the .into_iter() method call for x (in this
case of type Vec<i32>, i.e., x.into_iter()). The IntoIterator::into_iter() syntax is
needed in case x implements more than one trait that has an into_iter()
method because we need to tell the Rust compiler which method to choose
(see below).
This syntactic sugar is all internal compiler magic, but from here on in the rest is normal (though a bit arcane) Rust.
Function Overloads #
So why does this result in a move and why does replacing x with &x fix it?
If you've done any Rust programming, you know that you can call a method that
takes any kind of self parameter (i.e., a moved object, a reference, or a mutable
reference) as self.foo and Rust will automatically produce the right kind of parameter
assuming your object is compatible in terms of mutability.
For instance:
Code #
struct X {}
impl X {
fn ref_method(&self) {
println!("ref");
}
fn mut_ref_method(&mut self) {
println!("mut_ref");
}
fn move_method(self) {
println!("move");
}
}
fn main() {
let mut x = X {};
let mut y = X {};
let yref = &mut y;
x.ref_method();
x.mut_ref_method();
x.move_method();
// x.move_method(); Does not compile
yref.ref_method();
yref.mut_ref_method();
// yref.move_method(); Does not compile
(&y).ref_method();
(&mut y).mut_ref_method();
}Output #
ref
mut_ref
move
ref
mut_ref
ref
mut_ref
x is actually a mutable object, but as you can see, when we call the
ref_method, it gets an immutable reference and the mut_ref_method
it gets an immutable reference, so the compiler just handles this.
Note that if we try to call x.move_method()
twice, we get an error about the use of a moved value, just as we expect
(that's why I called this method last).
error[E0382]: use of moved value: `x`
--> receiver1.rs:23:5
|
18 | let mut x = X {};
| ----- move occurs because `x` has type `X`, which does not implement the `Copy` trait
...
22 | x.move_method();
| ------------- `x` moved due to this method call
23 | x.move_method()
| ^ value used here after move
|Similarly I can create a new X named y and a reference to it called yref and
call most of the methods via it. Note that you can't call move_method() because
you're not allowed to move things via references that way:
error[E0507]: cannot move out of `*yref` which is behind a mutable reference
--> receiver1.rs:27:5
|
27 | yref.move_method();
| ^^^^ ------------- `*yref` moved due to this method call
| |
| move occurs because `*yref` has type `X`, which does not implement the `Copy` trait
|
note: `X::move_method` takes ownership of the receiver `self`, which moves `*yref`
--> receiver1.rs:12:20
|
12 | fn move_method(self) {
| ^^^^I can even do the same thing without the temporary and just say (&y).ref_method().
So, if x and &x are (mostly) interchangeable in method calls,
why do we have a problem and why does &x fix it. The answer lies
in the fact that we're not calling a normal method but rather an
implementation of a trait (in this case IntoIterator). Because
traits are disconnected, it's possible for two traits to have
the same methods, like so:
struct Hat {
size_cm: f64,
}
trait Metric {
fn size(&self);
}
impl Metric for Hat {
fn size(&self) {
println!("Metric: {}", self.size_cm);
}
}
trait Imperial {
fn size(&self);
}
impl Imperial for Hat {
fn size(&self) {
println!("Imperial: {}", self.size_cm / 2.5);
}
}Both Metric and Imperial have size() functions, so if we make
a Hat and call .size(), what will happen? The answer is a compilation
error:
error[E0034]: multiple applicable items in scope
--> trait-overload.rs:28:7
|
28 | h.size();
| ^^^^ multiple `size` found
|
note: candidate #1 is defined in an impl of the trait `Imperial` for the type `Hat`
--> trait-overload.rs:20:5
|
20 | fn size(&self) {
| ^^^^^^^^^^^^^^
note: candidate #2 is defined in an impl of the trait `Metric` for the type `Hat`
--> trait-overload.rs:10:5
|
10 | fn size(&self) {
| ^^^^^^^^^^^^^^What's going on here is that the compiler has no way of knowing which
version of size() we want to call, because there are two equally
valid versions. In order to fix this, we need to disambiguate them,
and the compiler helpfully tells us how:
help: disambiguate the method for candidate #1
|
28 | Imperial::size(&h);
| ~~~~~~~~~~~~~~~~~~
help: disambiguate the method for candidate #2
|
28 | Metric::size(&h);You can get pretty far with Rust by just doing what the compiler says, and if we do that, things work as expected:
Code #
struct Hat {
size_cm: f64,
}
trait Metric {
fn size(&self);
}
impl Metric for Hat {
fn size(&self) {
println!("Metric: {}", self.size_cm);
}
}
trait Imperial {
fn size(&self);
}
impl Imperial for Hat {
fn size(&self) {
println!("Imperial: {}", self.size_cm / 2.5);
}
}
fn main() {
let hat = Hat { size_cm: 10.0 };
Metric::size(&hat);
Imperial::size(&hat);
}Output #
Metric: 10
Imperial: 4
If you look closely, though, you'll notice something that we
had to pass a reference to size(), as in Metric::size(&hat);
if we just change this to Metric::size(hat) you get a compilation
error:
--> trait-overload2.rs:28:18
|
28 | Metric::size(hat);
| ------------ ^^^ expected `&_`, found `Hat`
| |
| arguments to this function are incorrect
|
= note: expected reference `&_`
found struct `Hat`
note: method defined here
--> trait-overload2.rs:6:8
|
6 | fn size(&self);
| ^^^^
help: consider borrowing here
|
28 | Metric::size(&hat);
| +That's interesting: when we invoked a method with .size()
it didn't matter whether we explicitly provided a reference
or an object, everything worked great. But when we invoke it
this way, we actually have to provide an argument that will
match the self parameter, whether that's a value,
a reference, or a mutable reference, because we don't get
the magic behavior associated with ..[1]
Implementations of IntoIterator #
We're now in a position to understand what's happening here.
When we do IntoIterator::to_iter(x) this tells Rust to
expect a version of to_iter() that takes a value argument
(i.e., Vec<i32>)
which means we have to move x into the function, so we
can't reuse it.
It's a short step from there to understand why doing for y in &x
works: there is also a version of IntoIterator for &Vec<i32>, so
if we call IntoIterator::to_iter(&x) then that version gets invoked
(at this point, these are just totally different types from Rust's
perspective). Because that version just borrows x, things work
fine with no double move.[2]
Code #
fn main() {
let x = vec![1, 2];
for y in &x {
println!("{}", y);
}
println!("{}", x.len());
}Output #
1
2
2
You might ask at this point why Rust doesn't instead just do .into_iter()?
I can't find an explanation in the Rust documentation but I expect the
reason is that someone could implement another trait that provides
.into_iter() on whatever the x is in for y in x, thus resulting
in a compiler error because there would be two candidate implementations.
Method Calls #
The next thing I want to look at is the impact of method calls. This section uses the following (over)simplified model of a photo album module to walk through the relevant issues:
#[derive(Debug, Clone)]
pub struct Photo {
pub label: String,
pub content: Vec<u8>,
}
impl Photo {
fn new(label: &str, content: Vec<u8>) -> Photo {
Photo {
label: String::from(label),
content,
}
}
pub fn scale(&self, _scale: f32) -> Photo {
// In a real program this would adjust the
// size, but here it just makes a copy.
Photo {
label: self.label.clone() + "-copy",
content: self.content.clone(),
}
}
}
pub struct Album {
photos: Vec<Photo>,
}
impl Album {
// Load photos from disk. Right now just a stub.
pub fn init(_directory: &str) -> Self {
let mut album = Album { photos: Vec::new() };
for i in 0..5 {
// This is where we would load the content.
let content = Vec::new();
album
.photos
.push(Photo::new(&format!("Image {i}"), content));
}
album
}
pub fn add_photo(&mut self, photo: Photo) -> usize {
self.photos.push(photo);
self.photos.len()
}
pub fn get_photo(&self, index: usize) -> &Photo {
&self.photos[index]
}
pub fn list_photos(&self) -> Vec<String> {
self.photos
.iter()
.map(|photo| photo.label.clone())
.collect()
}
}This should be easy to follow if you know any C-like language, even if you don't know Rust, but just to orient you:
-
A
Photois a structure containing a label and some bytes that represent the image (content) (recall that I said this was oversimplified). -
An
Albumis a collection of photos.
Obviously, these "photos" are vacuous, in that they're just bytes, but
we're not going to be displaying them. Moreover, in
a real program, the album constructor (init) would load the photos
from a directory, but in this case it just makes up 5 empty Photos;
this is all fake, but the point here is just to have some scaffolding to
motivate/demonstrate the relevant issues.
Now, consider this simple program:
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0);
let smaller_photo = first_photo.scale(0.1);
album.add_photo(smaller_photo);
println!("Photos {:?}", album.list_photos());
}Obviously, this does the following:
- First, we create the photo album (again, this is supposed to be loading photos from the disk).
- Make a new photo that is a scaled down version of the first photo.
- Add the new photo to the album.
- List the photos.
This program compiles and runs just fine, like so:
Photos ["Image 0", "Image 1", "Image 2", "Image 3", "Image 4", "Image 0-copy"]
So far so good. Now, let's make a trivial modification where we also add a bigger photo. No problem, we'll just do some copy-and-paste DRY be damned:
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0);
let smaller_photo = first_photo.scale(0.1);
album.add_photo(smaller_photo);
let bigger_photo = first_photo.scale(10.0);
album.add_photo(bigger_photo);
println!("Photos {:?}", album.list_photos());
}Unfortunately, this totally doesn't work. Instead, we get the following error.
error[E0502]: cannot borrow `album` as mutable because it is also borrowed as immutable
--> examples/ex2.rs:7:5
|
5 | let first_photo = album.get_photo(0);
| ----- immutable borrow occurs here
6 | let smaller_photo = first_photo.scale(0.1);
7 | album.add_photo(smaller_photo);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ mutable borrow occurs here
8 | let bigger_photo = first_photo.scale(10.0);
| ----------- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `photos` (example "ex2") due to 1 previous error
LOLWAT?
The error message here is pretty good, but it's worth going through what's happening:
-
When we called
album.get_photo()the return value was a reference to an individual photo inalbum. In order to effectuate this, Rust takes an immutable reference toalbum, even though it's actually just returning a reference to one of the photos. -
When we now go to call
album.add_photo()we need to take a mutable reference toalbumin order to provide it as the&mut selfargument toalbum.add_photo(). However, because we already have an immutable reference toalbum, this is a double borrow and the compiler generates an error.
But wait, you say, I'm doing exactly this in the first program, and indeed you are. Let's look at these side by side:
Working #
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0);
let smaller_photo = first_photo.scale(0.1);
album.add_photo(smaller_photo);
println!("Photos {:?}", album.list_photos());
}Broken #
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0);
let smaller_photo = first_photo.scale(0.1);
album.add_photo(smaller_photo); // <--- Double borrow here.
let bigger_photo = first_photo.scale(10.0);
album.add_photo(bigger_photo);
println!("Photos {:?}", album.list_photos());
}Sure enough, the offending line is the first call to add_photo() which
was in the original code, not in the new code we added after. How can later
code break earlier code?

The answer here is—surprise!—the borrow checker. What's
going on is that in the original code the last time we use first_photo
is in the call to .scale(), so even though it's in scope when
we call .add_photo() the borrow checker knows we're not going
to use it and so decides that it's not really live at the earlier
point, and so we don't have a double borrow. What causes the problem in the new code is that
we use first_photo in the second call to scale(), which means that
it has to be still be live when we call add_photo(), resulting in
the double borrow error.
OK, so we know the problem. How can we fix it? There are a number of options.
Drop and Re-borrow #
The easiest thing to do is to invalidate first_photo
by dropping first_photo and reacquiring it after
we call .add_photo(), as shown below:
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0); // Acquire `first_photo` the first time
let smaller_photo = first_photo.scale(0.1);
album.add_photo(smaller_photo);
let first_photo = album.get_photo(0); // Re-acquire `first_photo`
let bigger_photo = first_photo.scale(10.0);
album.add_photo(bigger_photo);
println!("Photos {:?}", album.list_photos());
}I've done the Rust idiomatic thing here and reused the name
first_photo, thus shadowing the original variable, and you might
think that that's important, but this actually isn't necessary because
the Rust compiler can infer when a variable is being used, as we saw
before. It works just as well if you name the new variable
first_photo2.
Re-acquiring first_photo is a reasonable approach in this
case because finding the photo is just a matter of looking up
the first value in the .photos vector in album and vector
lookups are fast. However, imagine that instead we had to
do some expensive operation that involved examining all
the photos in the album. Imagine there was an API that
asked for the photo of the cutest cat. Clearly we wouldn't want to do
that computation again!
Store a Handle #
If we were using some expensive API to find the photo, then we need to find some way to avoid paying that cost for each photo we want to transform. One way to handle that is to have that API return a handle to the photo rather than the photo itself. The obvious thing to do here is to have the handle just be the index in the array, like so:
fn get_cutest_cat(&self) -> usize;You could then store the index and call get_photo() repeatedly,
as in the previous example, thus amortizing the expensive operation
and repeating the cheap one.
This will work as long as add_photo() doesn't invalidate
the handle. In this case, it doesn't because we add photos
to the end of the vector, but if we inserted them at
the front, then it would shift our photo up by one,
invalidating the handle. Note that this isn't something
that would be caught by the compiler; it just causes
a correctness error because the second time through we
try to resize the previous photo rather than the one
we intended. Deleting a photo would have a similar
problem. Note that no matter how badly you screw up,
this won't cause a memory error because Rust won't let
you index outside of the array; it's just a correctness
issue, but that doesn't mean it's not serious.
Make a Copy #
Alternatively, we can make a copy of the photo. Fortunately,[3]
Photo implements Clone, so this is straightforward:
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0).clone(); // Code changed here.
let smaller_photo = first_photo.scale(0.1);
album.add_photo(smaller_photo);
let bigger_photo = first_photo.scale(10.0);
album.add_photo(bigger_photo);
println!("Photos {:?}", album.list_photos());
}The obvious problem here is that the .clone() is actually moderately
expensive: we need to allocate enough space for a new copy of the image
and then copy the image data over. That's a lot of work to solve a
simple problem. Worse yet, this solution isn't always available,
as we might be working with a type that didn't implement Clone
or that wasn't in principle cloneable, for instance because it
was holding some external resource like a file. Nevertheless, this
is a common approach.
Restructure the Code #
The final approach available to us is to restructure the code a bit
so that the lifetime of first_photo doesn't overlap the calls
to .add_photo(). In this case, this is a fairly simple matter
of computing both smaller_photo and bigger_photo and then adding
them both, like so:
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0);
let smaller_photo = first_photo.scale(0.1);
let bigger_photo = first_photo.scale(10.0);
album.add_photo(smaller_photo);
album.add_photo(bigger_photo);
println!("Photos {:?}", album.list_photos());
}This is probably the most idiomatic thing to do in this specific case in that
it doesn't have the negative performance effects of the previous
options and doesn't require any changes to the API as the last
two options potentially do (making Photo Clone or adding
a handle API). However, it's also a lot more disruptive to the
logic of the code. Suppose that you wanted
to use a loop to generate images of various size, like so:
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0);
let sizes = [0.1, 0.5, 1.0];
for size in sizes {
let new_photo = first_photo.scale(size);
album.add_photo(new_photo);
}
println!("Photos {:?}", album.list_photos());
}Now we have to aggregate all of the modified versions of the original photo and then add them all at once, like so:
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory");
let first_photo = album.get_photo(0);
let sizes = [0.1, 0.5, 1.0];
let mut new_photos = Vec::new();
for size in sizes {
let new_photo = first_photo.scale(size);
new_photos.push(new_photo);
}
for photo in new_photos {
album.add_photo(photo);
}
println!("Photos {:?}", album.list_photos());
}At one level, this is just irritating, in that we have to restructure
the code. But because we're having to store the transformed
photos in memory we're potentially increasing the memory footprint
of the program significantly. That's not the case here because
add_photo() just moves a photo from the temporary vector to the vector
in album,[4]
but if Album stored photos on disk, we could run out
of memory in the first loop whereas if we stored photos right
away that wouldn't happen. In this situation you would have
to use one of the other approaches.
Non-Lexical Lifetimes #
I said above that Rust could infer that first_photo
wasn't in use and therefore it didn't count as a reference
for the purposes of the borrowing rules. This didn't used
to be true. In older versions of Rust, the fact that
the variable existed was enough to keep the reference
alive, whether it was subsequently used or not. So,
for instance, if we go back to our original code,
we would have a double-borrow problem because first_photo
is still in scope through the end of the function. Instead,
you would have had to do something like this:
let mut album = Album::init(&"directory");
{
let first_photo = album.get_photo(0);
let smaller_photo = first_photo.scale(0.1);
} // first_photo dropped here
album.add_photo(smaller_photo);
println!("Photos {:?}", album.list_photos());Putting first_photo in a braced block like this causes it to be
explicitly dropped so that when add_photo needs to borrow &mut self it's not a double borrow. This was obviously a pain in the ass
and Rust eventually added a feature called non-lexical
lifetimes
which made the compiler smarter about knowing when references were
really live.
One thing to notice is that the original code was always safe, it's just that the compiler didn't realize it. Rust's borrow checker is conservative in that it will only accept code it can prove is safe, but it will also reject code which is actually safe but the borrow checker can't prove is safe. This leaves room for improvements in the language as the borrow checker gets smarter and constructs which would previously have been errors—but were actually safe—become allowed.[5]
Why, oh why? #
At this point, you might want to ask why Rust is torturing you
like this? Why can't I just do what I want to, like in good ol' C++? And at first glance,
it looks like the original double borrow code is safe. After all, we're not using
first_photo simultaneously with album.add_photo(), it's just
sitting there waiting for us to use it again.
But actually what's happening here is the same problem we saw
in the previous post:
first_photo is a reference (a pointer) to an element in the
array, as shown below:
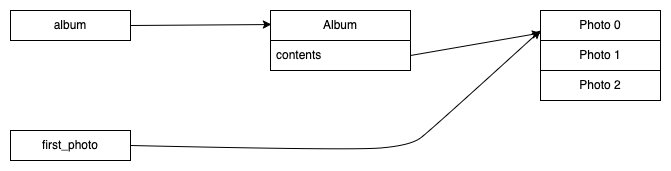
first_photo is a reference
If we add a new photo and that causes the memory allocated to
the array or vector to resize (this can happen even if we
just add an element to the end), then suddenly first_photo is
pointing to an unallocated region of memory, as shown below.
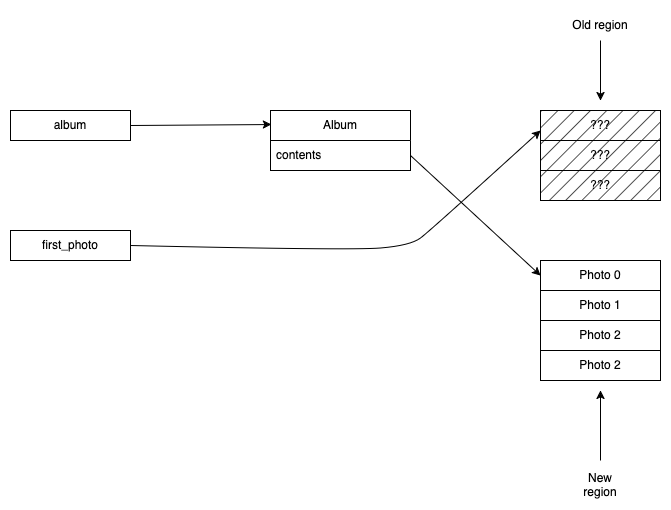
first_photo after a resize
If Rust is going to be safe, it can't allow this, so the code won't compile.
Safer Handles #
As an aside, it's somewhat possible to write handles in a way that is safer than just a simple integer. For example, we could have the handle store not just the index of the element but also some identifier for the contents of the element in such a way that the handle would become invalid if the element changed. In this case, the result would be that if an element were inserted before the photo, shifting the elements to the right, an attempt to dereference the handle would fail, so you'd get a runtime error.
Probably a better approach in this case is to replace
a generic handle with a query which caches its results.
For instance, we could have find_cutest_cat() remember
the current cutest cat and which photos it had looked at
and then when you ask for the result, it just looks at any
new pictures of cats to compare them to the current cutest;
this is far more robust than trying to build some kind of
safer handle structure.
It's important to realize that the logical situation is the same as with handles: we have a reference (in the general sense, not the Rust technical sense), which is now invalid. The difference is that the handle (in this case an integer) is an offset into the vector, as opposed to the address of some random region in memory. This means that only one of two things can happen:
-
The handle is smaller than the size of the array and so there's an element at the relevant location, just not the one that's expected. This causes the program to silently malfunction.
-
The handle is greater than or equal to the size of the array, in which case you'll get a runtime error right away.
In neither case do you have a memory error. This nicely illustrates the sense in which Rust is "safe", namely that it prevents you from memory errors but not logic errors (though it does protect against some, as seen below). It's still very possible to write bugs in Rust; it's just that they don't result in memory corruption.
Lifetimes #
In the previous section I just glossed over something tricky. Let's
take another look at Album::get_photo():
pub fn get_photo(&self, index: usize) -> &Photo {
&self.photos[index]
}In this code I'm taking a reference to &self.photos[index] and
returning it, but what makes this safe? Suppose that album gets
deleted while I'm still hanging on to the return value. Don't
I get a dangling reference. Let's try it and see.
use photos::photos::*;
pub fn main() {
let first_photo;
{
#[allow(unused_mut)]
let mut album = Album::init(&"directory");
first_photo = album.get_photo(0);
}
let _ = first_photo.scale(0.1);
}Reassuringly, this won't compile, producing the following error:[6]
error[E0597]: `album` does not live long enough
--> examples/ex4.rs:8:23
|
7 | let mut album = Album::init(&"directory");
| --------- binding `album` declared here
8 | first_photo = album.get_photo(0);
| ^^^^^ borrowed value does not live long enough
9 | }
| - `album` dropped here while still borrowed
10 | let _ = first_photo.scale(0.1);
| ----------- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `photos` (example "ex4") due to 1 previous error
Dodged a bullet there. After we've taken a deep breath because Rust saved us from ourselves,
we might start to wonder what is actually going on here: how
does Rust know that first_photo is a borrow of album? That's
information that is only available by looking at the implementation
of get_photo() and remember what I said about local reasoning?
Understanding what is going on here requires understanding what Rust calls "lifetimes". Let's start with the basic rule that Rust enforces.
If B is a reference to object A then B can't outlive object A.
Obviously, what's gone wrong here is that album goes out of scope at the end
of the block enclosing it, at which point the reference to album
in first_photo is invalid. I.e., it has outlived album.
The lifetime of a variable is the time between when it's first created and when it's last used. So, another way of stating the above rule is that:
If B is a reference to object A then B's lifetime must be contained
within A's lifetime (though they can be coextensive).
Just to see the problem more clearly here, I've annotated the code
to show the relevant lifetimes.
The annotated code below shows the lifetime of album and first_photo
in our working code. As you can see, first_photo is last used
before the end of the block, which is when album goes out of scope (and
hence the end of its lifetime).
use photos::photos::*;
pub fn main() {
let mut album = Album::init(&"directory"); <---------------+
let first_photo = album.get_photo(0); <-\ Lifetime of | Lifetime of
let smaller_photo = first_photo.scale(0.1);<-/ first_photo | album
album.add_photo(smaller_photo); |
println!("Photos {:?}", album.list_photos()); |
} <---------------+ Now compare the annotated version of the broken code:
use photos::photos::*;
pub fn main() {
let first_photo;
{
#[allow(unused_mut)]
let mut album = Album::init(&"directory"); <-+ Lifetime
first_photo = album.get_photo(0); | of album <-+
} <-+ | Lifetime of
let _ = first_photo.scale(0.1); <---------------+ first_photo
}
As before, album's lifetime ends at the end of the enclosing block,
but in this case, first_photo is used after that point, so its lifetime
extends past the end of album, which, as noted before, is forbidden.
Note that first_photo exists before it is first assigned to
point to album, but it's not a reference to album. Actually,
in this case it's not assigned to anything, and so using it would
be forbidden prior to assignment.
This brings us back to the question I asked above: how does Rust know
that first_photo is a borrow of album and not of something else?
And what if I did want to borrow something else?
Seeing Like a Compiler #
Although every variable in Rust has a lifetime, so far we've managed to avoid dealing with that because the compiler can often infer those lifetimes and act appropriately. However, there are situations where that's not the case.
Let's start with a simple example to get the idea:
fn return_first(first: &str, second: &str) -> &str {
first
}
fn main() {
println!("{:?}", return_first(&"first", &"second"));
}This is some pretty obvious code: we pass two string references
into return_first() and it returns the first one. But when
we try to compile it we get an error:
error[E0106]: missing lifetime specifier
--> examples/ex5.rs:1:47
|
1 | fn return_first(first: &str, second: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `first` or `second`
help: consider introducing a named lifetime parameter
|
1 | fn return_first<'a>(first: &'a str, second: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `photos` (example "ex5") due to 1 previous error
Rust error messages are usually clearer than this, but what's
going on is that the compiler isn't able to verify that the
lifetimes here follow the rules.
Specifically, the return value of return_first() is a reference to
something, but the compiler doesn't know how long it's supposed to be
valid for. This will cause a problem when we try to use println!()
on it, because Rust doesn't know if it's safe to use in that context.
We are able to examine the function and realize it's safe, but
because the compiler wants to use local reasoning, it's not able
to do so.
What I mean by local reasoning is when checking main()
from the compiler's perspective, at this point the program looks like this:
fn return_first(first: &str, second: &str) -> &str {
// STUFF WE WON'T LOOK AT.
}
fn main() {
println!("{:?}", return_first(&"first", &"second"));
}When checking to see if main() is following the lifetime rules,
the compiler wants to use only the information it has available
from the function signature, without looking at the implementation.
Conversely, when it checks return_first() it won't look at main().
If you're a C or C++ programmer, this should be conceptually familiar
because C and C++ programs have header (.h) files which conventionally
contain function and method signatures, with the implementation
(the body) living in .c or .cc (or .cpp or .c++) files.
This allows the compiler to compile one file (technical term: "translation unit")
without knowing how another file works, but only the interfaces it
provides. Rust doesn't have a header/body split like C and C++
but you can still get into the same situation if you are operating
on a "trait object" (the Rust equivalent of C++ virtual functions),
because you only know the trait definition.
In order to make this code compile, we have to help the compiler
out by telling it the expected lifetime of the return value.
We do this by decorating variables with a lifetime annotation,
which looks like 'a.[7]
Specifically, what we need to express here
is that the return value is not expected to outlive the first
argument and thus it's safe to use the return value as long as
the first argument is also alive. The notation for this looks
like:
fn return_first<'a>(a: &'first str, second: &str) -> &'a strNote how the notation here looks a little like C++ templates (and Rust generics, which we didn't go into as much), because this is a kind of generic. You read this line as follows:
There is some lifetime
'asuch that the return value is valid during'a(and can't be safely used after) and that whateverfirstis pointing to lives at least as long as'a.
The way to look at these lifetime annotations is that they are defining the contract for this function. In order to enforce that contract, the compiler does two things:
-
Analyzes the caller of the function to verify that it isn't using the return value outside of the lifetime of whatever it passed as the first argument. As noted above, it can do this without looking at the function body.
-
Analyzes the body of the function to verify that the return value is actually derived from the first argument, so that it will be safe as long as the first argument is valid.
We've seen the first check in action, but let's look at the second check. Consider what happens if we change the return value to be derived from the second argument:
fn return_first(first: &str, second: &str) -> &str {
second
}
fn main() {
// println!("{:?}", return_first(&"first", &"second"));
}I've commented out the call to return_first() so we're not even using
the return value, but we still get an error because the
function body isn't fulfilling the contract:
error[E0106]: missing lifetime specifier
--> examples/ex6.rs:1:47
|
1 | fn return_first(first: &str, second: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `first` or `second`
help: consider introducing a named lifetime parameter
|
1 | fn return_first<'a>(first: &'a str, second: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `photos` (example "ex6") due to 1 previous errorAs illustrated here, it's not possible to produce unsafe code by giving the compiler the wrong lifetime: if we screw up the compiler will throw an error. In this sense, lifetimes are just a hint to the compiler and a sufficiently smart compiler could do without them.
Lifetime Elision #
In fact, it's because lifetimes are a kind of hint that our original photo handling code works without lifetime annotations. To see this, consider the following trivial modification of this program in which we only pass in one argument:
fn return_first(first: &str) -> &str {
first
}
fn main() {
println!("{:?}", return_first(&"first"));
}
The compiler will process this just fine because it contains a set of default rules ("lifetime elision") that handle common cases. The rule that is applicable to this case are:
The second rule is that, if there is exactly one input lifetime parameter, that lifetime is assigned to all output lifetime parameters: fn foo<'a>(x: &'a i32) -> &'a i32.
In other words, Rust is secretly changing the function signature to be:
fn return_first<'a>(first: &'a str) -> &'a strThis is reasonable because the vast majority of—but not all—valid code that
has this kind of signature will be returning a reference to
something derived from one of the arguments.
However, once again, this is just a default: if we were to change return_first() to
return a reference to something not derived from first, then the compiler
would generate an error. First, consider the following:
fn return_first(first: &str) -> &str {
let s = String::from(first);
&s
}In this case, we are returning a dangling reference to s,
which only lives to the end of the function. This is plainly
illegal—in fact, this is exactly what Rust lifetimes
are designed to prevent—and so the compiler returns
an error. No amount of lifetime decorations will make it
compile.
Multiple Arguments #
Functions with a single argument are easy mode. For functions with multiple arguments, Rust will assign each one its own lifetime (rule one), at which point it doesn't know which lifetime to associate the return value with. This is why the version above with two arguments doesn't work without lifetime annotations, because Rust is internally giving it the following signature:
fn return_first<'a,'b,'c>(first: &'a str, second: &'b str) -> &'c strBecause it doesn't know the lifetime of 'c, the compiler is
not able to determine either whether the return value is being
used safely at the call site. We can resolve this issue
as above by explicitly labeling the return value with a lifetime
matching one of the arguments. To take one of the examples from the Rust book, if the function might
return either first or second then you need to
attach the same lifetime to both arguments, with the
result that Rust will verify safety for whatever lifetime
is shorter (recall that 'a only has to be a lifetime that
satisfies all the constraints).
Member Functions #
There is one more special case: when you have a method call,
then Rust assumes that the lifetime of any references returned
will be the same as self. Turning back to get_photo(), this
means that Rust is internally assigning the lifetime.
pub fn get_photo<'a>(&'a self, index: usize) -> &'a PhotoIf you wanted a member function to return another argument, you would need to explicitly annotate the function, like so:
fn get_stuff<'a>(&self, s: &'a str) -> &'a strStructs #
There's one more case worth covering: structs can have members that are references, in which case you have to provide a lifetime for the reference. This looks like:
struct Foo<'a> {
x: &'a i32
}The semantics of this are the same as having a variable with the same
reference label: the lifetime of x and hence Foo has to be shorter
than the lifetime of whatever x is a reference to. This all
works, but things start to get hairy pretty fast because you have to
decorate a lot of stuff with the lifetimes, as in:[8]
#[derive(Debug)]
struct Pair<'a> {
x: i32,
y: &'a i32,
}
impl<'a> Pair<'a> {
fn new(x: &i32, y: &'a i32) -> Pair<'a> {
Pair { x: *x, y }
}
}Now let's try one more thing. Check out the following code:
#[derive(Debug)]
struct Holder<T> {
t: Option<T>,
}
impl<T> Holder<T> {
fn set_value(&mut self, t: T) {}
}
pub fn main() {
let mut holder = Holder { t: None };
{
let tmp: i32 = 10;
holder.set_value(tmp);
}
println!("{:?}", &holder);
}Just to orient you, this code defines a struct called Holder. It's a
generic type parameterized on T so that it can hold an instance of any T. The
actual member value (t) is an Option<T> so that we can create
an empty Holder and then fill it with .set_value()—or at least
in principle can fill it with .set_value(). In practice, .set_value()
has the signature you would expect from the name, but doesn't actually do anything,
so Holder always contains a None. You have to use this Option
trick a lot in Rust because there's no way to have empty object
references like C++ nullptr (or, arguably, that's what Option is for).
If we call .set_value() with an instance of i32, then everything
works as expected. The program compiles and outputs:
Holder { t: None }
Note that even though this is a generic, we didn't need to tell
Rust which type to instantiate it (Rust jargon: monomorphize) with.
Instead, it inferred it from the fact that we called .set_value() with
a type of i32: set_value() is defined as taking an argument of
type T and thus this means we must have a Holder<i32>.[9]
Now let's do the exact same thing but but with one small change:
pass &tmp to holder.set_value():
#[derive(Debug)]
struct Holder<T> {
t: Option<T>,
}
impl<T> Holder<T> {
fn set_value(&mut self, t: T) {}
}
pub fn main() {
let mut holder = Holder { t: None };
{
let tmp: i32 = 10;
holder.set_value(&tmp);
}
println!("{:?}", &holder);
}Surprise (or maybe not?)! This doesn't compile at all.
warning: unused variable: `t`
--> examples/ex10-ref.rs:7:29
|
7 | fn set_value(&mut self, t: T) {}
| ^ help: if this is intentional, prefix it with an underscore: `_t`
|
= note: `#[warn(unused_variables)]` on by default
error[E0597]: `tmp` does not live long enough
--> examples/ex10-ref.rs:14:26
|
13 | let tmp: i32 = 10;
| --- binding `tmp` declared here
14 | holder.set_value(&tmp);
| ^^^^ borrowed value does not live long enough
15 | }
| - `tmp` dropped here while still borrowed
16 | println!("{:?}", &holder);
| ------- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `photos` (example "ex10-ref") due to 1 previous error; 1 warning emitted
We're now seeing the downstream consequences of the lifetime
annotations for structs. As mentioned above, if you have a reference
member in a struct, it needs a lifetime, so when we monomorphized
Holder with an i32, it had to associate a lifetime with it,
so we ended up with something like:
struct Holder<&'a i32> {
t: Option<&'a i32>,
}And when we called .set_value(&tmp), 'a got associated with
the lifetime of tmp. That lifetime ends when the block ends,
but holder extends past the end of the block, so we have
a lifetime error. You'll note that we didn't even have to use
the reference passed to .set_value() to make this happen:
Rust just looked at the function signature and decided that
in principle we could be using it and so that meant
holder had to be treated as if it were holding a reference
to tmp. If we change .set_value() to take a &self instead
of a &self (this is fine because we're not touching
self.t anyway), then the problem resolves itself and the
program will compile just fine.[10]
Bonus: Thread Safety #
Everything in this post has been about memory allocation, but here's the cool part: Rust also provides thread safety, mostly through the same mechanisms that provide memory safety. This post is already quite long, but I want to briefly give you an intuition of how this works.
The basic cause of thread safety issues in software is when you have the same data value being modified by two threads at once. Consider the following trivial function for a bank's accounting system:
function pay_money(payee, amount) {
if (balance < amount) {
throw Error("Insufficient funds");
}
balance = balance - amount;
send_money(payee, amount);
} This looks like perfectly reasonable code, but what happens if we decide to run it in a multithreaded program where requests to pay people can come in in parallel. Suddenly, we have a serious problem because the individual steps of these threads can execute in any order. For instance, we might have the following order of execution:
Thread 1 Thread 2
function pay_money(payee, amount) {
if (balance < amount) {
throw Error("Insufficient funds");
}
function pay_money(payee, amount) {
if (balance < amount) {
throw Error("Insufficient funds");
}
balance = balance - amount;
send_money(payee, amount);
}
balance = balance - amount;
send_money(payee, amount);
} This will (maybe) work fine sometimes but what happens if we have $100
in the account and then we get two transactions for $75 each? The
obvious thing to expect is that we end up with $-50 dollars in the
account—or, depending on the language, maybe
$4294967246 dollars, oops!—because thread 1 checks the balance prior to thread 2 debiting
it. This is what's called a "time of check time of use" bug.
Actually the situation is much much worse than this because
compiler output isn't really anywhere near as neat as I've suggested here, so all
sorts of things could happen. For example, the compiler during the
initial read of balance the compiler could decide to store the
value of balance in a register and then write it back to balance
from that register, with the result that the first write is lost.
To take a more extreme example, the compiler can move values in registers
into your variables if it wants to (this is called a "register spill")
as long as it restores them afterwards; this can cause obvious problems
if you then contaminate one of the values it's using.
This great post by Dmitry Vyukov) goes into a lot more detail here, but the basic
point is that if you ever do uncoordinated writes to the same
data values it's incredibly bad news (again, it's undefined
behavior in C/C++). In general, the compiler is allowed to assume
you never try to access the same value in two threads and so if you
do, all bets are off.
If you've written any multithreaded code, you know that the basic defense against this kind of problem is what's called "locking": one thread "locks" a region of memory and as long as it's holding the lock, no other thread can touch that region.[11] There are a lot of different kinds of lock, but one common one is what's called a "read-write lock". A read-write lock has the following semantics:
-
If you hold a read lock on a particular region, you're allowed to read the memory but not write it. An arbitrary number of threads can hold read locks on a given region as long as no thread holds a write lock.
-
If you hold a write lock on a particular region, you can read or write it. No other thread[12] can hold any kind of lock on a region as long as someone is holding a write lock.
This should sound very familiar because it's precisely the semantics Rust uses for mutability, if you just substitute "immutable reference" for "read lock" and "mutable reference" for "write lock". This is not an accident, but instead it's a sign of a deep connection between memory safety and thread safety.
Moving Data Between Threads #
As we've discussed from the very beginning, Rust is a single ownership language; if a given object is owned by one thread then obviously it cannot be modified by two threads at once. It can, however, be moved between threads, by two basic mechanisms:
-
When you spawn a thread, you provide a function for the thread to run. This function can be a closure, which is a fancy term for an anonymous function defined in line. The closure can capture variables from the environment.
-
Rust provides mechanisms to write from one thread to another, such as channels.
Spawning a Thread #
Let's start with spawning a new thread. The basic code looks like this:
use std::thread;
fn main() {
let val = 10;
thread::spawn(move || {
println!("{:?}", val);
});
}The || {} is the syntax for a closure and when used with the move
keyword, which means that any variable used in the body of
the closure ("captured") is moved into the closure. This means
that val will be unavailable inside main after this point,
but will be available inside the closure, which is why we can
pass it to println!().
Now look what happens if we do the same thing but moving a reference
to val:
use std::thread;
fn main() {
let val = 10;
let val_ref = &val;
thread::spawn(move || {
println!("{:?}", val_ref);
});
}As expected, this doesn't compile at all.
error[E0597]: `val` does not live long enough
--> examples/ex11-ref.rs:5:19
|
4 | let val = 10;
| --- binding `val` declared here
5 | let val_ref = &val;
| ^^^^ borrowed value does not live long enough
6 |
7 | / thread::spawn(move || {
8 | | println!("{:?}", val_ref);
9 | | });
| |______- argument requires that `val` is borrowed for `'static`
10 | }
| - `val` dropped here while still borrowed
For more information about this error, try `rustc --explain E0597`.
error: could not compile `photos` (example "ex11-ref") due to 1 previous error
The lifetime problem here is that main() may exit or
at least start to exit while
the thread is still running, which means that val
get dropped and val_ref becomes invalid. There's no
way to statically verify that main() will wait for
the other thread to complete, so there's no way to
have the thread reference a local variable of main().
As indicated by this error, the only kind of reference
you can pass to a thread is one that has the special
'static lifetime, which means it lasts the entire lifetime
of the program (typically it's a global variable).
You can make val static, as shown in the code below,
but safe Rust forbids mutable static variables, so the result
is that the variable is read only in both the thread
and in main(), which preserves the "arbitrary number
of immutable references" invariant.
use std::thread;
static VAL: i32 = 10;
fn main() {
let val_ref = &VAL;
thread::spawn(move || {
println!("{:?}", val_ref);
});
}While the logic is similar to what we saw above,
the enforcement mechanism for this is slightly different.
The reason for this is that thread::spawn() is just a function
and so even though we're passing it a reference there's nowhere
for it to store it, so once thread::spwan() returns, that
reference should have been dropped which would mean it was safe
to drop the object it pointed to. You know and I know that
what thread::spawn() actually does is to create a new thread
that runs independently from the main thread, but how is the
compiler to know that?
What is happening here is that thread::spawn() is defined with
a specific set of trait bounds (traits which the arguments
and return values have to implement):
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T + Send + 'static,
T: Send + 'static,Focus your attention on the generic parameter F, which is
the type of the closure passed to spawn(). This is defined
as having to implement the following traits:
FnOnce() -> T:- Be a function which can be safely called at least once and
has a return value of type
T Send:- Can be safely [transferred across thread boundaries.
'static:- Lasts for the duration of the program.
It's this last constraint which matters for our purposes, because it
requires that the closure and anything it captures has the
lifetime 'static. Because a reference to a local variable doesn't
have 'static lifetime, it can't be passed to thread::spawn()
so there's no way to use thread::spawn() to create an unsafe
reference.
Channels #
The other main option is to use some sort of messaging system to write data from one thread to another. For instance, Rust has a built-in mechanism called channels, which works like this:
Sender #
let value = Foo { ... };
channel_tx.send(value);Receiver #
let value = channel_rx.recv().unwrap();As with thread::spawn(), we can't use channels to unsafely
send references from one thread to another, though the mechanisms Rust
uses to prevent this are somewhat more complicated, and
I'm not going to go into them here.[13]
With that said, here's an example of the obvious thing that you
might try to do and the compiler will reject:
use std::sync::mpsc::channel;
use std::thread;
fn main() {
let val = 10;
let (tx, rx) = channel();
let _ = tx.send(&val);
thread::spawn(move || {
let _ = rx.recv().unwrap();
});
}Cross-Thread Sharing #
Obviously, there are situations when you do want to share data
across threads, and just as Rust provides a mechanism (RefCell)
for controlled mutation of data shared through immutable references,
it similarly has a set of mechanisms for controlled sharing
of writable data. A full description of how to do this is outside
of the scope of this already long post, but here is a trivial example.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let val = Arc::new(Mutex::new(10));
let val_to_share = Arc::clone(&val);
let t = thread::spawn(move || {
let mut tmp = val_to_share.lock().unwrap();
println!("Inside thread val={:?}", *tmp);
*tmp += 10;
});
let _ = t.join();
println!("Main thread val={:?}", val.lock().unwrap());
}The basic idea here is that we first wrap our shared data in a
Mutex, which allows one reference (either readable or writable)
at once at a time. You obtain the reference by calling .lock(),
and if someone else has it your thread will wait until they
have unlocked it.[14]
A reference to a Mutex can't be shared across threads directly any more
than any other variable can, but we can wrap it in a reference
counted structure, in this case Arc (the thread safe version
of Rc) and move that across threads. The logic here is:
- We have two copies of
Arc, one in each thread, but both pointing to the sameMutex. - Each thread uses
.lock()to access the data inside theMutex.
This allows us to share the data across the threads but guarantees
that only one thread at a time can use it.[15] The call to .join() in the main thread is just waiting for
the other thread to finish to guarantee we have a chance to print both values.
There's a lot more to say about multithreaded programming in Rust, but I'm not trying to teach you how to write parallel programs in Rust; instead I want to make two points here:
-
Writing memory safe and thread safe programs depends on the same basic concepts, namely ensuring single ownership, guaranteed lifetimes, and preventing simultaneous writing and reading, whether that simultaneity is a result of concurrency or not.
-
The mechanisms that Rust uses to provide thread safety are much the same basic mechanisms as those which are used to provide memory safety and similarly are based on clear contracts between components plus local analysis for safety.
As I said this isn't an accident, but rather a result of the connection between memory safety and thread safety, which logical errors related to unclear ownership, and the results of trying to touch the same data in inconsistent ways in multiple places.
Next Up: Garbage Collection #
There's plenty more to say about Rust memory management and in
particular about how to write manageable code that conforms to
Rust's rules—as well as how to break those rules
using unsafe when you have to—but hopefully this gives you
an overall sense of how things are put together. In the next
post, I want to talk about a completely different approach
to memory, namely automatic memory management with garbage
collection, as used in languages ranging from Lisp to Go to
JavaScript.
I was too lazy to dig into this, but I'm pretty sure what's happening under the hood is that
.is basically just syntactic sugar for "call this function withselfas the first argument". This allows Rust to figure out what the right version ofselfto provide is.Metric::size()addresses the function directly, and so you have to provideselfdirectly, and that means you need to also provide the right version ofself. ↩︎This isn't immediately evident, but in this code,
yis of type&i32rather thani32;println!()just takes care of the dereference for you. ↩︎Well, fortunately in that I added
#[derive(Clone)]when I wrote it. ↩︎As an aside, note that we are doing
for photo in new_photosrather thanfor photo in &new_photosbecause we need to consume the vector. If we used&new_photoswe would iterate over references and not be able to move the object behind the reference when callingadd_photo(). ↩︎There's actually an ongoing project called Polonius to replace the borrow checker with one that properly handles some cases which are safe but which it currently rejects. ↩︎
Ignore the
#[allow(unused_mut)]. This just stops the compiler from complaining about howalbumis unnecessarilymut, and I wanted to keep the code the same as before. ↩︎One of the bad habits that Rust seems to have picked up from C++ is the convention of making generic parameters single letters, so you end up with
T,U,V, etc. Just when we'd persuaded people not to name regular variables like that, too. ↩︎And I haven't even gotten to
'_. ↩︎We actually don't even have to tell Rust that
tmpis ani32, because that's the basic type for bare integers. ↩︎On the other hand, if we change
Holder.tto be aRefCell<Option<T>>then we get a compile error even if we make.set_value()take&T. You need to dig pretty deep into Rust internals to understand why, but the logic is clear: you could in principle have used theRefCellto store a reference. ↩︎I'm simplifying here, because there's also a lot of machinery you need to make sure the region is in good shape when the lock is removed, due to the kinds of optimizations I mentioned above. We won't cover that here. ↩︎
I'm being precise here, because some systems let you take recursive locks and some don't. There are pluses and minuses. ↩︎
I spent quite a while working through this and I'm still not done. Potentially the subject for a future post. ↩︎
Note that we don't have to explicitly unlock because we're using RAII, just as with RefCell. ↩︎
Rust also has a read-write lock mechanism that allows for multiple readers at once, but I just decided to show
Mutexhere. ↩︎