Challenges in Building a Decentralized Web
Posted by ekr on 25 Apr 2022
There's been a lot of interest lately in what's often termed the Decentralized Web (dWeb), though now it's quite common to hear the term Web3 used as well. Mapping out the precise distinctions between these terms—assuming that's possible—is outside the scope of this post (though it seems that Web3 somehow involves blockchains), but the common thread here seems to be replacing the existing rather centralized Web ecosystem with one that is, well, less centralized. This post looks at the challenges of actually building a system like this.
The infrastructure of the Web is centralized in at least two major ways:
-
There are relatively few major user-facing content distribution platforms (Google, YouTube, Facebook, Twitter, TikTok, etc.) and they clearly have outsized power over people's ability to get their message amplified.
-
Even if you're willing to forego posting on one of those content platforms, the easiest way to build any large-scale system—and almost the only economical way unless you are very well-funded—is to run it on one of a relatively small number of infrastructure providers, such as Amazon Web Services, Google Cloud Platform, Cloudflare, Fastly, etc., who already have highly scalable geographically distributed systems.
In this context, decentralizing can mean anything from building analogs to those specific content platforms that operate in a less centralized fashion (e.g., Mastodon or Diaspora) to rebuilding the entire structure of the Web on a peer to peer platform like IPFS or Beaker. Naturally, in the second case, you would also want to make it possible to reproduce these content platforms—only better!—using a mostly or fully peer-to-peer system; at least it shouldn't be required to have a bunch of big servers somewhere to make it all work. This second, more ambitious, project is the topic of this post.
Distributed Versus Decentralized #
An important distinction to draw here is between systems which are distributed (also often called federated) and those which are decentralized (often called peer-to-peer). As an example, the Web is a distributed system: it consists of lots of different sites operated by different entities, but those sites run on servers and operating a site requires running a server yourself or outsourcing that to someone else. Those servers have to be prepared to handle the load for all your users, which means they have to be somewhere with a lot of bandwidth, scale gracefully as more users try to connect, etc.
By contrast, BitTorrent is a decentralized system: it uses the resources of BitTorrent users themselves to serve data, which means that you don't need a giant server to publish data into the BitTorrent network, even if a lot of other people want to download it. This has some obvious operational advantages even in a world where bandwidth is cheap, but especially if you want to publish something which others would prefer wasn't published, perhaps because of government censorship or more frequently for copyright reasons. If you run a server, it's pretty hard to conceal that a million people just connected to download John Wick: Chapter 3 - Parabellum (a pretty solid outing by Keanu, btw), and you should expect the copyright police to come after you (see here, Kim Dotcom) but if you just publish your copy into the BitTorrent network, it's a lot harder to figure out who it was, especially if 50 other people did the same.
Note that it's possible to have mixed systems that are largely decentralized but depend on centralized components. For instance, in a peer-to-peer system, new peers often need to connect to some "introduction server" to help them join the network; those servers need to be easy to find and one—though not the only way—to do that is to have them be operated centrally.
Historically, peer-to-peer systems have seen deployment in relatively limited domains, mostly those associated with some kind of deployment outside of the aforementioned censorship-resistance use case. However, there has certainly been plenty of interest in broader use cases, up to and including displacing large pieces of the Web. This is a very difficult problem, in part because this kind of system is inherently less efficient and flexible than a centralized or federated system. This post looks at the challenges involved in building such a system. This isn't to say it's not also challenging to build something like Twitter or Facebook in a more federated fashion, but the problems are of a different scale (and perhaps the subject of a different post).
Peer-to-Peer versus Client/Server #
The opposite of peer-to-peer is client/server, i.e., a system in which the elements take on asymmetrical roles, with one element (often that belonging to the user[1]) being the "client" and the other element (often some kind of shared resource associated with an organization) being the "server". This is, for instance, how the Web works, with the client being the browser. By contrast, peer-to-peer systems are thought of as symmetrical.
In practice, however, the lines can be quite blurry. For instance, common to have systems in which the same protocols are used to talk between clients and servers and also between servers, with the second mode more like a typical "peer-to-peer" configuration. For instance, mail clients use SMTP to send e-mail but mail servers also use SMTP to send e-mail to each other, with the sender taking on the "client" role; obviously in this case, each "server" is both client and server, depending on which direction the mail is flowing. Even in systems which are nominally peer-to-peer, it's common to use protocols which were designed for client/server applications (e.g., TLS), in which case the nodes may take on client/server roles for those protocol purposes even if the application above is symmetrical.
Basics of Peer-to-Peer Systems #
We all (hopefully) know how a client/server publishing system like the Web works (if not, review my intro post, but how does a peer-to-peer (hence-forth P2P) publishing system work? Let's start by discussing the simplest case, which is just publishing opaque binary resources (documents, movies, whatever). This section tries to describe just enough basics of such a system to have the rest of this post make sense.
In a client/server system, the resource to be published is stored on the server, but in a P2P system, there are no servers, so the resource is stored "in the network". What this means operationally is that it's stored on the computers of some subset of the users who happen to be online at the moment. In order to make this work, then, we need a set of rules (i.e., a protocol) that describes which endpoints store a specific piece of content and how to find them when you want to retrieve it. A common design here is what's called a Distributed Hash Table, which is basically an abstraction in which every resource has a "key" (i.e., an address) which is used to reference it and a "value" which is its actual content. The key determines which node(s) are responsible for storing the value and is used by other nodes to store and/or retrieve it.
As an intuition pump, consider the following toy DHT system. This is an oversimplified version of Chord, one of the first DHTs, so let's call it "Note". In Note, every node in the system has a randomly generated identifier which is just a number from $0$ to $2^{256}-1$ (sorry for the LaTeX notation, newsletter folks). It's conventional to think of these being organized in a circle, with the ids being assigned clockwise, so that node $2^{256}-1$ is right next to (before) node $0$, as shown in the following diagram:
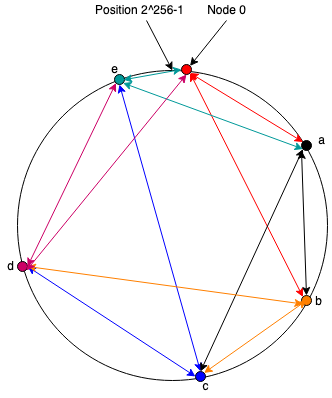
Each node in the network (the "ring") maintains a set of connections to some other set of nodes in the ring (the arrows are colored according to the node maintaining the connection). I won't go into detail about the algorithms here, except to say that having that work efficiently is a lot of the science of making a DHT. In Note, we'll just assume that each node has a connection to the next node (i.e., the one with the next highest identity) and to some other nodes further along the ring, as shown in the figure above.
In order to communicate with a node with id $i$, a node sends a message to the node that it is connected to with id $j$ that is closest to but not greater than $i$ (i.e., that if you went around the circle clockwise, there would be no node that you were connected to that was in between them). Node $i$ does the same. When you finally reach a node that is connected directly to $j$, it delivers the message. For instance, if node 0 wanted to send a message to node c it would send it to b who would send it to c. When c wants to reply, it sends it to node e which is connected to node 0 and so sends it directly. Note that this means that a request/response pair takes an entire trip around the ring.
Storing Data #
So far we just have a communications system, but it's (relatively) easy to turn it into a storage system: we give each piece of data an address in the same namespace as the node identifiers and each node is responsible for storing any data with an address that falls between it and the previous node. So, for instance, in the diagram below, node c would be responsible for storing the resource with address k and node e would be responsible for storing the resource with address l.
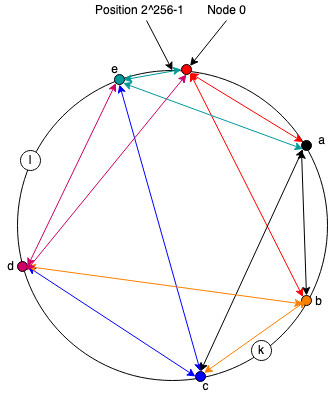
If node a wants to store a value with address k it would craft a message to c asking to store it. Similarly, if node d wants to retrieve it, it would send a message to c.
Of course, there are several obvious problems here. First, what happens if node c drops off the network? After all, it's somebody's personal computer, so they might turn it off at any moment. The natural answer to this is to replicate the data to some other set of nodes so that there is a suitably low probability that they will all go offline at once. The precise replication strategy is also a complicated topic that varies depending on the DHT, and we don't need to go into it here.
Second, what if some value is both large and popular? In that case, the node(s) storing it might suddenly have to transfer a lot of data all at once. It's easy for this to totally saturate someone's link, even if they have a fast Internet connection. The only real fix is to distribute the load, which you can do in two ways. First, you can shard the resource (e.g., break up your movie into 5 minute chunks) and then store each shard under a different address; this has the impact that different nodes will be responsible for sending each chunk and so their share of the bandwidth is correspondingly reduced. You can also try to make more nodes responsible for popular content, which also spreads out the load.
Finally, if every message has to traverse several nodes in order to be delivered, this increases the total load on the network proportional to the path length (the number of nodes) as well as decreasing performance due to latency. One way to deal with that is to have the two communicating nodes establish a direct connection for the bulk data transfer and just use the DHT to get the in contact so they can do that. This significantly reduces the overall load.
Naming Things #
In the previous description, I've handwaved how the addresses for things are derived.
One common design is to compute the address from the content of the object, for instance by hashing it. This is what's called Content Addressable Storage (CAS) and is convenient in a number of situations because it doesn't require any additional content integrity in the DHT. If you know the hash of the object you can retrieve it and then if the hash comes out wrong, you know there has been a problem retrieving it.
Of course, given that you need the object in order to compute its hash, this kind of design means that you need some service to map objects whose names you know (e.g., "John Wick") onto their hashes, so now we either have a centralized service that does that or we need to build a peer-to-peer version of that service and we're back where we started.
Another common approach is to have names that are derived from cryptographic keys. For instance, we might say that all of my data is stored at the hash of my public key (again, maybe with some suitable sharding system). When the data gets stored we would require it to be signed and nodes would discard stored values whose signatures didn't validate. This has a number of advantages, but one critical one is that you can have the data at a given address change because the address is tied to the cryptographic key not the content. For instance, supposing that what's being stored is my Web site; I might want to change that and not want to have to publish a new address. With an address tied to keys this is possible.
Obviously, cryptographic keys don't make great identifiers either, because they are hard to remember, but presumably you would layer some kind of decentralized naming layer on top, for instance one based on a blockchain.
Security #
Any real system needs some way of ensuring the integrity of the content. Unlike the Web, it's not enough to establish a TLS connection to the storing node, because that's just someone's computer and it could lie (though you still may want to for privacy reasons). Instead, each object needs to be somehow integrity protected, either by having its address be its hash or by being digitally signed.
Aside from the integrity of the content, there's still a lot to go wrong here. For instance, what happens if the responsible node claims that a given object (or a node you are trying to route to) doesn't exist? Or what if a set of nodes try to saturate the network with traffic via a DDoS attack? How do you deal with people trying to store or retrieve more than their "fair share" (whatever that is) of data. There are various approaches people have talked about to try to address these issues, but our operational experience with DHTs is at a smaller scale than our operational experience with the Web, and in a setting that was much more tolerant of failure (Disney doesn't lose a lot of money if people suddenly can't download Frozen from BitTorrent) and so it's not clear that they can be made to be really secure at scale.
A Decentralized Web Publishing System #
Now that we have a way to store data and find it again, we have the start of how one might imagine building a decentralized version of the Web. As we did when looking at how the Web works let's just start with publishing static documents.
Recall the structure of URIs:

What we need to do is to map this structure onto resources in our P2P storage system. So we might end up with a URL like the following:

The Origin #
A critical security requirement in this system is that
data associated with different authorities has different
origins (see here for
background). If data published by multiple users has
different origins the same origin [2022-04-25 -- EKR], then they could attack each other
via the browser, which is an obvious problem.
The note: at the start tells us that we need to retrieve
the data using Note and not via HTTP. In the middle
section, instead of having a "host" field which tells us where
to retrieve the content in an ordinary HTTPS URI, we instead
have an "authority" field which just tells us the identity
of the user whose key will be used to sign the data for the
URL. As above, I'm assuming we have some way of mapping
user friendly identities to keys; some systems don't have that,
which seems pretty user-hostile, but feel free to just think of
the authority as being a key hash if you prefer.
The resource itself is stored at an address given by Hash(URL)
(this is a small but simple change from my description above),
and as above, is signed by key associated with the authority.
This is all pretty straightforward if you assume the existence of the P2P system in the first place. In order to publish something, I do a store into the DHT at the address indicated by the URL and sign it with my key. I can then hand the URL to people who can retrieve the data from the DHT by computing the address and then verifying the signed resource. Note that because the address is computed from the URL and not from the content, it can be updated in place just by doing a new store.
Taking a step back, this really does sort of deliver on the value proposition I described above: anyone can publish a site into the network without having to have a room full of computers or pay Amazon/Google/Fastly, etc. And so if you don't look too closely, it seems like mission accomplished and it's easy to understand the enthusiasm. Unfortunately this system also has some pretty serious drawbacks.
Performance #
Performance—in this case the time it takes a page to load—is a major consideration for Web browsers and servers. What mostly matters for Web performance is the time it takes to retrieve each resource. This is different from, say, videoconferencing or gaming, where latency (the time it takes your packets to get to the other side) or jitter (variation in latency) really matter. In the Web it's mostly about download speed.
Connections #
In order to understand the performance implications of a shift from client/server to peer-to-peer it's necessary to understand a little bit about how networking and data transfer works. The Internet is a packet-switched network, which means that it carries individually addressed messages that are on the order of 1000 bytes. Because Web resources are generally larger than 1K, clients and servers transfer data by establishing a connection, which is a persistent association on both sides that maps a set of packets into what looks like a stream of data that each side can read and write to. The sender breaks the file up into packets and sends them and the receiver is responsible for reassembling them on receipt. Historically this was done by TCP, though are now seeing increased use of QUIC, which operates on similar principles, at least at the level we need to talk about here).
The figure below shows the beginning of an HTTPS connection using TCP and TLS 1.3 for security.

Increasing the number of HTTP Requests on a Connection #
When HTTP was originally designed, you could only have one request on a single connection. This was horribly inefficient for the reasons I've described here, and—in large part due to the work of Jeff Mogul—a feature was added that allowed multiple requests to be issued on the same connection. Unfortunately, those requests could only be issued serially, which created a new bottleneck. In response, browsers started creating multiple connections in parallel to the same site, which let them make multiple requests at once (as well as sometimes grab a larger fraction of the available bandwidth, due to TCP dynamics). In 2015, HTTP/2 added the ability to multiplex multiple requests on the same TCP connection, with the responses being interleaved, but still had the problem that a packet lost for response A stalled every other response (a property called head-of-line blocking), which didn't happen between multiple connections. Finally, QUIC, published in 2021, added multiplexing without head-of-line blocking, even over a single QUIC connection.
As you can see, the first two round trips are entirely consumed with setting up the connection. After two round trips, the client can finally ask for the resource and it's another round trip before it finally gets any data. Depending on the network details, each round trip can be anywhere from a few milliseconds to 200 milliseconds, so it can be up to 600ms before the browser sees the first byte of data. This is a big deal and over the past few years the IETF has expended considerable effort to shave round trips from connection setup time for the Web (with TLS 1.3 and QUIC).
Once the connection has been established, you then need to deliver the data, which doesn't happen all at once. As I mentioned before, it gets broken up into a stream of packets which are sent to the other side over time. This is where things get a little bit tricky because neither the sender nor the receiver knows the capacity of the network (i.e., how many bits/second it can carry) and if the sender tries to send too fast, then the extra packets get dropped. To avoid this, TCP (or QUIC) tries to work out a safe sending rate by gradually sending faster and faster until there are signs of congestion (e.g., packets getting lost or delayed) and then backs off. Importantly, this means that initially you won't be using the full capacity of the network until the connection warms up (this is called "slow start"), so the data transfer rate tends to get faster over time until a steady state is reached.[2]
The implication of all this is that new connections are expensive and you want to send as much data over a single connection as you can. In fact, much of the evolution of HTTP over the past 30 years has been finding ways to use fewer and fewer connections for a single Web page.
Peer-to-Peer Performance #
This brings us to the question of performance in peer-to-peer systems. As I mentioned above, if you want to move significant amounts of data, you really want to have the client connect directly to the node which is storing the data. This presents several problems.
First, we have the latency involved in just sending the first message through the P2P network and back. This will generally be slower than a direct message because it can't take a direct path. Then, it's not generally possible to simply initiate a connection directly to other people's personal computers, as they are often behind network elements like NATs and Firewalls. So-called "hole punching" protocols like ICE allow you to establish direct connections in many cases, but they introduce additional latency (minimum one round trip, but often much more). And once that's done you then still have to establish an encrypted connection, so we're talking anywhere upward from 2 additional round trips. To make matters worse, there will be many cases where the storing node is quite topologically far from you and therefore has a long round trip time; big sites and CDNs deliberately locate points of presence close to users, but this is a much harder problem with P2P systems. And of course, even once the connection has been established, we're still in slow start.
This is all kind of a bad fit for Web sites, which tend to consist of a lot of small files. For example, the Google home page, which is generally designed to be lightweight, currently consists of 36 separate resources, with the largest being 811 KB. If each of these resources is stored separately in the DHT, then you're going to be running the inefficient setup phase of the protocol a lot and will almost never be in the efficient data transfer phase. This is by contrast to HTTP and QUIC, which try to keep the connection to the server open so that they can amortize out the startup phase.
It's obviously possible to bundle up some of the resources on a site into a single object, but this has other problems. First, it's hard on the browser cache because many of those objects will be reused on subsequent loads. Second, it makes the connection to a single node the rate limiting step in the download, which is bad if that node—which, recall, is just someone else's computer—doesn't have a good network connection or is temporarily overloaded. The result is that we have a tension between what we want to minimize individual fetch latency, which is to send everything over a single connection, and what we want to do in order to avoid bottlenecking on single elements, which is to download from a lot of servers at once, like BitTorrent does.
All of this is less of an issue in contexts like movie downloading, where the object is big and so overall throughput is more important than latency. In that case, you can parallelize your connections and keep the pipe full. However, this isn't the situation with the Web, where people really notice page load time. As far as I know, building a large P2P network with comparable load-time performance to the Web is a mostly unsolved problem.
Security and Privacy #
Even if we assume that the P2P network itself is secure in the sense that attackers can't bring it down and the data is signed, this system still has some concerning properties.
Privacy #
In any system like the Web, the node that serves data to the client learns which data a given client is interested in, at least to the level of the client's IP address. This isn't an ideal situation in the current Web, hence IP address concealment techniques like Tor, VPNs, Private Relay, etc., but at least it's somewhat limited to identifiable entities that you chose to interact with (though of course the ubiquitous tracking in Web advertising makes the situation pretty bad).
The situation with P2P systems is even worse: downloading a piece of content means contacting a more or less random computer on the Internet and telling it what you want. As I noted above, you could route all the traffic through the P2P network but only by seriously compromising privacy, so realistically you're going to be sharing your IP address with the node. Worse yet, in most cases the data is going to be sharded over multiple nodes, which means that a lot of different random people are seeing your browsing behavior. Finally, in many networks it's possible for nodes to influence which data they are responsible for, in which which case one might imagine entities who wished to do surveillance trying to become responsible for particular kinds of sensitive data and then recording who came to retrieve it; indeed, it appears this is already happening with BitTorrent.
Access control—putting the public in publishing #
Much of the Web is available to everyone, but it's also quite common to have situations in which you want to restrict access to a piece of data. This can be the site's data, such as the paywalls operated by sites like the New York Times, or the user's data, such as with Facebook or Gmail. These are implemented in the obvious way, by having an access control list on the server which states which users can access each piece of data and refusing to serve data to unauthorized users. This won't work in a P2P system, however, in that there's no server to do the enforcement: the data is just stored on people's computers and even if the site published access control rules, the site can't trust the storing node to follow them. It might even be controlled by the attacker.
The traditional answer to this problem is to use to encrypt the content before it's stored in the DHT. Even if the data in the DHT is public, that's just the ciphertext. This actually works modestly well when the content is the user's and they don't want to share it with anyone because they can encrypt it to a key they know and then just store it in the DHT. This could even be done with existing APIs (e.g., WebCrypto), and the key is stored on the user's computer. It works a lot less well if they want to share it with other people—especially with read/write applications like Google Docs—because you need cryptographic enforcement mechanisms for all of the access rules. There has been some real work on this with cryptographic file systems like SiRiUS and Tahoe-LAFS, but it's a complicated problem and I'm not aware of any really large scale deployments.
The paywall problem is actually somewhat harder. For instance, the New York Times could encrypt all its content and then give every subscriber a key which could be used to decrypt it, but given the number of subscribers, and that only one has to leak the key,[3] the chance that that key will leak is essentially 100%.[4] Of course, people share NYT passwords too, but what makes this problem harder is that the password then has to be used on the NYT site and it's possible to detect misbehavior, such as when 20 people use the same password. I'm not aware of any really good P2P-only solution here.
Non-Static Content #
Access control is actually a special case of a more general problem: many if not most Web sites do more than simple publishing of static content and those sites depend on server side processing that is hard to replicate in a decentralized system.
Non-Secret Computation #
As a warm-up, let's take a comparatively easy problem, the shopping site I described in part II of my Web security model series. Effectively, this site has three server-side functions that need to be replicated:
- Product search
- Shopping cart maintenance
- Purchasing
The second and third of these are actually reasonably straightforward: the shopping cart can be stored entirely on the client or, alternately, stored self-encrypted by the client in the P2P system, as described in the previous section. The purchasing piece can be handled by some kind of cryptocurrency (though things are more complicated if you want to take credit cards). However, product search is more difficult. The obvious solution would just be to publish the entire product catalog in the network, have the client download it, and do search locally. This obviously has some pretty undesirable performance consequences: consider how much data is in Amazon's catalog and how often it changes.
Obviously, the way this works in the Web 2.0 world is that the server just runs the computation and returns the result, and at this point you usually hear someone propose some kind of distributed computation system a la Ethereum smart contracts (though you probably don't want the outcome recorded on the blockchain). In this case, instead of publishing a static resource, the site would publish a program to be executed that returned the results (often these programs are written in WebAssembly).
Aside from the obvious problem that this still requires the node executing the program to have all the data, it's hard for the end-user client to determine that the node has executed the program correctly. Even in a simple case like searching for matching records: if those records are signed then the node can't substitute their own values, but they can potentially conceal matching ones. There are, of course, cryptographic techniques that potentially make it possible to prove that the computation was correct, but they are far from trivial. So, this doesn't have a really great solution.
Secret Information #
A shopping site is actually a relatively simple case because the information is basically public—though in some cases the site might not want their catalog to be public—but there are a lot of cases where the site wants to compute with secret information. There are two primary situations here:
-
The site's secret information, for instance Twitter's recommendation algorithm is not public.
-
The user's secret information, for instance which other users they have "swiped right" on in a dating app, or even just users' profile details.
In Web 2.0, the way this works is that the server knows the secret information and uses it for the computation but doesn't reveal it to the users. As with the search case, though, that doesn't port easily to the P2P case because it's not safe to reveal the information to random people's personal computers.
There are, of course, cryptographic mechanisms for computing specific functions with encrypted data. For instance, Private Set Intersection techniques make it possible to determine whether Alice and Bob both swiped right on each other and only tell them if they both did, but they're complicated and more importantly task specific, so you need a solution for each application, and sometimes that means inventing new cryptography (to be clear, this is far from all that is required to implement a secure P2P dating system!).
This is actually a general problem with cryptographic replacements for computations performed on "trusted" servers. The positive side of cryptographic approaches is that they can provide strong security guarantees, but the negative side is that essentially each new computation task requires some new cryptography, which makes changes very slow and expensive. By contrast, if you're doing computation on a server, then changing your computations is just a matter of writing and loading it onto the server. The obvious downside is that people have to trust the server, but clearly a lot of people are willing to do that.
Hybrid Architectures #
One idea that is sometimes floated for addressing this kind of functional issue is to have a hybrid architecture. For instance, one might imagine implementing the shopping site by having the static content of the catalog served via the P2P network but having a server which handled the searches and returned pointers to the relevant sections of the catalog. You could even encrypt each individual catalog chunk so that it was hard for a competitor to see your entire catalog. You could even imagine building a dating site with—handwaving alert!—some combination of P2P and server technology, with the logic for determining which profiles you could see and which to match you with implemented on the server, but the (encrypted) profiles distributed P2P.
At this point, though, you have pretty substantial server component that is in the critical path of your site and so you're mostly using the P2P network as a kind of not-very-fast CDN (see, for instance, PeerCDN). This gives up most of the benefits of having your system decentralized in the first place: you still have the problem of hosting your server somewhere, which probably means some cloud service, and at that point why not just use a CDN for your static content anyway? Similarly, if you're worried about censorship, then you need to worry about your server being censored, which makes your site unusable even if the P2P piece still works.
Closing Thoughts #
It's easy to see the appeal of a more decentralized Web: who wants to have a bunch of faceless mega-corporations deciding what you can or cannot say? And there certainly are plenty of jurisdictions that censor people's access to the Web and to information more generally. It's easy to look at the success of P2P content distribution systems—albeit to a great extent for distributing content for which other people hold the copyrights—and come to the conclusion that it's a solution to the Web centralization problem.
Unfortunately, for the reasons described above, I don't think that's really the right conclusion. While the Web sort of superficially resembles a content distribution system, it's actually something quite different, with both a far broader variety of use cases and much tighter security and performance requirements. It's probably possible to rebuild some simpler systems on a P2P substrate, but the Web as a whole is a different story, and even systems that appear simple are often quite complex internally. Of course, the Web has had almost 30 years to grow into what it is, and it's possible that there are technological improvements that would let us build a decentralized system with similar properties, but I don't think this is something we really understand how to do today.