Architectural options for messaging interoperability
Some hard earned lessons from the interop trenches
Posted by ekr on 10 Mar 2023
As I mentioned in some previous posts, the EU Digital Markets Act (DMA) requires interoperability for number independent interpersonal communications services (NICS), which is to say stuff like messaging (what we used to call "Instant Messaging") as well as real-time media (voice and video calling). Specifically Article 7 says that:
2. The gatekeeper shall make at least the following basic
functionalities referred to in paragraph 1 interoperable where
the gatekeeper itself provides those functionalities to its own
end users:
(a) following the listing in the designation decision pursuant to Article 3(9):
(i) end-to-end text messaging between two individual end users;
(ii) sharing of images, voice messages, videos and other attached
files in end to end communication between two individual end
users;
(b) within 2 years from the designation:
(i) end-to-end text messaging within groups of individual end
users;
(ii) sharing of images, voice messages, videos and other attached
files in end-to-end communication between a group chat and an
individual end user;
(c) within 4 years from the designation:
(i) end-to-end voice calls between two individual end users;
(ii) end-to-end video calls between two individual end users;
(iii) end-to-end voice calls between a group chat and an individual
end user;
(iv) end-to-end video calls between a group chat and an individual
end user.
The European Commission (specifically the Directorate General for Communication (DG COMM)) has been holding a series of workshops on how to structure the compliance requirements for the DMA. Last week, I attended the workshop on messaging interoperability to serve on a panel along with Paul Rösler (FAU Erlangen-Nürnberg), Stephen Hurley (Meta), Alissa Cooper (Cisco), and Matthew Hodgson (Element/Matrix). (video here; my presentation starts at 13:24:10; slides here). Nominally the panel was about the impact of end-to-end encryption on interoperability (see here for some earlier thoughts on this), but in the event it turned into more of an overall discussion of the broader technical aspects.
The rest of this post expands some on my thinking in this area. Note that while I work for Mozilla, these are my opinions, not theirs.
Overview of Technical Options #
At a high level, there are three main technical options for providing this kind of interoperability, in ascending order of flexibility for the competitor product:
- Gatekeeper-provided libraries.
- The gatekeeper provides a software library (ideally in source code form, but perhaps not) which implements their interfaces. The competitor builds their app using that library and doesn't have to know—and maybe doesn't get to see—any details of those interfaces.[1]
- Gatekeeper-specified interfaces.
- The gatekeeper publishes a set of interfaces (Web APIs, protocols, etc.) that competitors can use to talk to its system. The competitor implements those APIs themselves—or maybe someone writes an open source library to implement them—and talks to the gatekeeper's system that way.
- Common protocols.
- The gatekeeper implements interfaces based on some common—preferably standardized—protocol. The competitor implements that protocol and uses it to talk to the gatekeeper.
We'll take a look at each of these options below.
Requirements Scope #
The big question lurking in the background of the entire workshop was the scope of the requirement that the EC would levy on gatekeepers. I'm not a legal expert, but the above quoted text seems to require that the gatekeepers make this functionality available but not dictate any particular means of doing so. In particular, they might opt to just publish some libraries or specifications that anyone who wants to interoperate with them must conform to (the EU technical term here is "reference offer"). The Commission would then be responsible for ensuring that this reference offer was compliant, which is to say that:
- It provides the required functionality.
- It is sufficiently complete to implement from.
For reasons that will occupy most of the rest of this post, this is not really an ideal state of affairs, and it would be easier for competitors (technical term "access seekers") if there were some single set of interfaces (protocols) that every gatekeeper. However, the tone of the workshop is that the Commission is not eager to require a single set of standards at this stage and that there's some question about exactly what the DMA empowers them to require in this area. For the purposes of this post, I'm going to put that question aside and focus on the technical situation as I see it.
Interoperability is Hard #
The first thing to realize is that interoperability is really difficult to achieve, even when people are trying hard. The basic problem is that protocol specifications tend to be fairly complicated and it is difficult to write one that is sufficiently precise and complete that two people (or groups) can independently construct implementations that interoperate. In fact, some standards development organizations require demonstration that every feature has two independent implementations that can interoperate in order to advance to a specific maturity level (in IETF, "Internet Standard", though as a practical matter, even many widely deployed and interoperable protocols never get this far, just because it's a hassle to advance them). Part of the process of refining the protocol is finding places where the specification is ambiguous and modifying the specification to clarify them.
Over the past 10 years or so, I've been heavily involved in the standardization and interop testing of at least three major protocols (and a number of smaller ones):
In each case, we discovered issues with just about every implementation, in many cases leading to interoperability failure.
A full description of how interop testing works is outside the scope of this post, but at a high level each implementor sets up their own endpoint and you try to make them communicate; in most cases this will initially be unsuccessful. If you're lucky, one of the implementations will emit some kind of error, but sometimes it just won't work (e.g., you just get a deadlock with neither side sending anything). What you do next depends on precisely what went wrong. As an example, if a message from implementation A elicited an error from implementation B, then you look at the message and the error it generated and try to determine if the message was correct (in which case it's B's fault), if it was incorrect (in which case it's A's fault), or if the specification is ambiguous (in which case it needs to be updated). Once the implementors have decided on the correct behavior, then one (or sometimes both!) of them change their implementations, and you rerun the test, hopefully getting a little further before things break. This process repeats with increasingly more difficult scenarios until everything works.
There are several important points to remember here:
-
The specification is frequently unclear; even when there is a best reading, it's often not entirely obvious.
-
Even when the specification is clear, implementors make mistakes, leading to interoperability problems.
-
Interop testing is a high-bandwidth process that requires close collaboration between implementors. In particular, it's vital to be able to understand what the other implementation didn't like about what your implementation did, rather than just knowing that it didn't work.
This last point is especially important: if you just send a message to the other side and get an error, then you're left scrutinizing your code over and over to see if you did something wrong, even when it turns out the problem is on the other side.
When I was working on WebRTC and trying to get interoperability between Firefox and Chrome, I spent quite a few days in Google conference rooms with Justin Uberti, the tech lead for Chrome's WebRTC implementation, doing just what I described above. It also helped that both Firefox and Chrome were open source, so we were able to look at each other's code and figure out what must be happening. Getting this to work would have been approximately impossible if all I had had was a copy of Chrome and no insight into what was happening internally, or if we hadn't been right next to each other. This problem is especially acute for cryptographic protocols, where any error tends to lead to some sort of opaque failure such as "couldn't decrypt" or "signature didn't validate". If you can't see the intermediate computational values (e.g., the keys or the inputs to the encryption), you're back to trying to guess what you did wrong (and good luck if it's the other side!).
More recently, the IETF has developed something of a system for this (thanks to Nick Sullivan from Cloudflare for kicking this process), starting with TLS 1.3 and now with QUIC. Basically, everyone gets in the same room (to the extent possible) and stands up their implementation and other people try to talk to it.[2] There's a lot of back-and-forth of the form of "Hey, I'm getting error X when I talk to your implementation, can you take a look". The end result of this is an interoperability matrix showing which implementations can talk to each other and with which tests. For instance, here's the interop matrix for one of the later QUIC drafts:
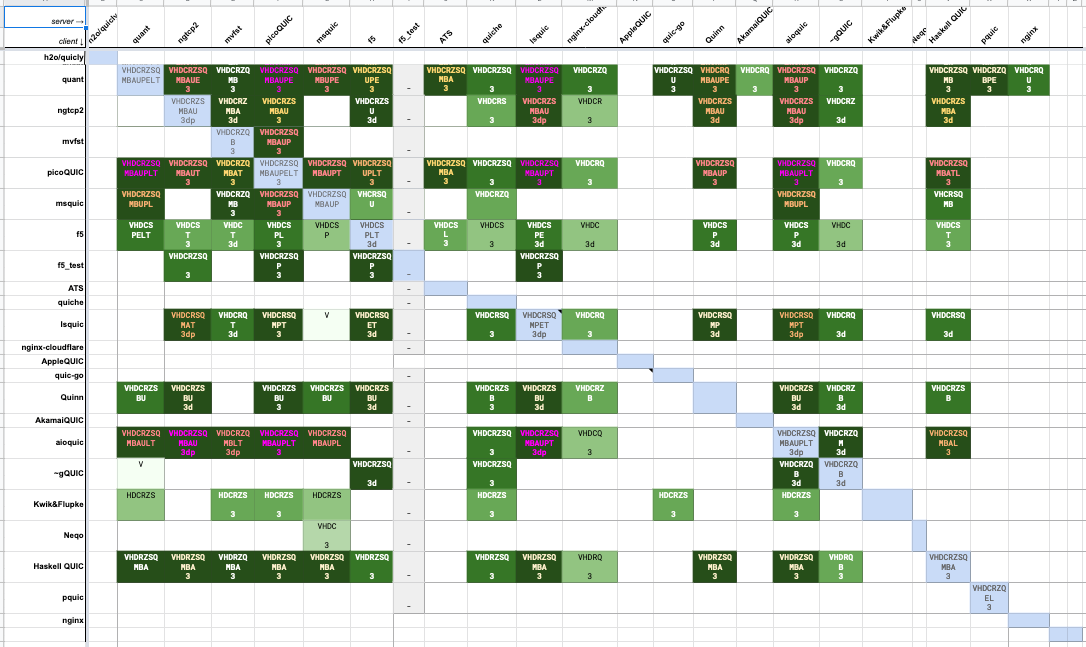
Each cell is a single client/server pair, with the client down the left and the server across the right. The letters indicate which tests worked, with the color indicating how well things are going, the darker the better.
This is all an enormous amount of work, and it's important to remember that this is a best-case scenario in that the people writing the specification are trying very hard to make it as clear as possible and generally the implementors are trying to be helpful to each other. The situation with messaging is quite different: the gatekeepers could have provided interoperable interfaces at any time but chose not to. Instead, they're just being required to provide them by the DMA, so their incentive to make it work is comparatively low. Moreover, they may not even have their own internal documentation; in my experience it's quite common for engineering organizations to just embody their interfaces in code with minimal documentation which is insufficient to implement from.
The first 10% is often easy #
It's often relatively easy to get things to sort of work in simple configurations (what is sometimes called the "happy path"). For instance, the first real public demonstration of WebRTC interop between Chrome and Firefox was in early 2012, at a point where it just barely worked and needed handholding from Justin and myself. Firefox didn't work with Google Meet until 2018, which required changes on both sides. A particular issue was around multiple streams of audio and video (see here for background on the "plan wars of 2013").
In a similar vein, during the workshop Matthew Hodgson showed a demo of Matrix interoperating with WhatsApp via a local gateway,[3] which serves as a good demonstration that interop is possible, but but as he mentioned himself, shouldn't lead anyone to conclude this is a trivial problem. Sending messaging back in forth is probably the easiest part of this problem, it's all of the details (group messaging, media, ...) that will be the hard part to get right and are also essential to it being ready for real users.
It gets better #
Note that the scenario I'm talking about here is mostly what happens with early protocol development and deployment. Once there are widespread open source implementations that are fairly conformant, you can just test against those implementations and debug them directly when you have a problem; of course, that's not likely to be the case for messaging interoperability, at least initially, and especially if the gatekeepers just publish their specs without any reference implementation.
The surface area is enormous #
The number of different protocols that need to be implemented in order to build a complete messaging system along with voice and video calling is extremely large. At minimum you need something like the following:
- Messaging
- A protocol for end-to-end key establishment (e.g., MLS, OTR, Signal)
- The format for the messages themselves (e.g., MIME)
- A transport protocol for the messages (e.g., XMPP)
- Voice and video. Everything above plus
- Media format negotiation (e.g., SDP)
- NAT traversal (e.g., ICE) if you want peer-to-peer media
- Media transport (e.g., RTP/SRTP)
- Voice and video codecs (e.g., Opus, AV1, H.264, etc.)
Every one of the things I've named above is a very significant piece of technology, often running to hundreds if not thousands of pages of specifications.[4]
As a concrete example, let's look at WebRTC. At the time WebRTC was being designed, there was an existing ecosystem of standards-based voice and video over IP that used Session Initiation Protocol (SIP) for signaling and RTP/SRTP for media. Those protocols were in wide use but often not on an interoperable basis. Although many of the people who designed WebRTC had also been involved in building that ecosystem, there was also a feeling that many of those protocols were due for revision, so there was a fair amount of updating/modification. By the time the overarching protocol specification document JavaScript Session Establishment Protocol (JSEP) was published in 2021, the set of relevant documents had grown to 10s of RFCs running to thousands of pages. Moreover, these RFCs themselves depended on other previously published RFCs defining stuff like audio and video codecs (for instance, the specification for the mandatory to implement Opus audio codec is 326 pages long, though at least part of that is a reference implementation).
Of course, these are specifications for general purpose systems and so you could almost certainly build a single system that had less complexity. For instance, a lot of the complexity in WebRTC is around media negotiation: suppose that one side wants to send two streams of video and one stream of audio, but the other side only wants to receive one stream of video. An interoperable system needs to specify what happens in this case, but if you have a closed system you can just arrange that your software never gets itself into that state. There are quite a few other cases like this where you can get away with a lot less in a closed environment, but even then there will still be quite a bit of complexity.
At the same time, it's increasingly possible for small teams to quickly build quite functional voice and video calling systems. This apparent contradiction is explained by realizing that there are widely available software libraries (for instance, the somewhat confusingly named WebRTC library) that implement most of these specifications and provide an API that hides most of the details. The result is that as long as you're willing to take whatever that library implements, it's possible to build a functional system, but you're pulling in the transitive closure of all the specifications it depends on. The same thing is true for other protocols such as TLS, XMPP, Matrix, etc.
The key point to take home here is that actually having interoperability between the gatekeepers and competitive products requires nailing down an enormous number of details, even if those details are hidden behind software libraries. To the extent to which this uses the existing interfaces and protocols, then this is a somewhat more straightforward problem, but if a gatekeeper has built a largely proprietary system from the ground up, then the effort of specifying it in enough detail that someone else can build their own interoperable implementation—not to mention the effort of building that implementation—is likely to be very considerable.
It has to be implemented on the client #
If you want to have end-to-end encryption of the communications, then this means that much of the complexity has to be implemented on the client. Specifically:
-
You need to have end-to-end key establishment so the key establishment protocol needs to run on the client.
-
Text messages are encrypted and so they need to be constructed on the sender's client software and decrypted on the receiver's.
-
Similarly, audio and video need to be encoded and decoded on the client.
This is different from (for instance) e-mail, which is typically not end-to-end encrypted, or non-E2E videoconferencing systems, in that you can centrally transcode the media. For instance, if Alice can only send audio with the Opus codec and Bob can only receive with G.711, then the central system can transcode it, but if the data is end-to-end encrypted, that's not possible (the whole point of end-to-end encryption is that the central system can't modify the content). Instead, you need to ensure that every client has the necessary capabilities. It is possible to implement some of the system on the server. For instance, because the transport is generally not end-to-end encrypted (though it should be encrypted between client and server), you might be able to gateway transports between systems, such as if you want to connect an XMPP client to a system that isn't natively XMPP.
Gatekeeper Libraries #
Technically, gatekeepers don't need to actually publish their
interfaces to achieve interoperability. Instead, they could
just build a software library
that implements their system. The idea here is that if I
build EKRMessage and I want it to talk to WhatsApp, I just
download their library and build it into EKRMessage. There
will be some set of functions that I need to call
(e.g., sendMessageTo() to send a message) to implement
the interoperability.
The obvious advantage of this design is that it hides[5] lot of complexity from the new implementor: the gatekeeper doesn't need to document the details of any of their protocols in the kind of excruciating detail I mentioned above; they just build that into their software. Of course now they have to document the library, but that's usually a lot easier (after all, this is why people use libraries). This kind of library can be a huge force multiplier: as I mentioned above, the existence of Google's WebRTC library has made it much easier for people to build powerful A/V apps. However, if every gatekeeper has their own library, this is a lot less attractive, as Alissa Cooper from Cisco pointed out in her workshop presentation. To just briefly sketch a few of the problems with this approach:
-
Code bloat. Each competitor application will need to build in a copy of every gatekeeper's library, which is extremely inefficient. As an example, the WebRTC.org library is over 800K lines of code. Imagine that times 5.
-
Code architecture. Each library is going to have its own particular API style, which is going to make architecting your app different. As a concrete example, consider what happens if one library is asynchronous and event-driven and another is synchronous and uses threads. Building an app that uses both cleanly is going to be architecturally difficult (typically you end up trying to force fit one control flow discipline into the other).
-
Portability. If the gatekeeper provides their library in binary (compiled) form, then it will only be usable on the specific platforms the gatekeeper builds it for. Even if they provide source code, that often will not work on one platform or another without work (portable code is hard!). Of course, someone could port the library, but if they aren't able to upstream them to the gatekeeper's source, then the porting work needs to be repeated whenever the gatekeeper makes changes. In addition to questions of platform, we also have to think about questions of language: if the library is written in Java and I want to write my application in Rust, I'm going to have a bad day.
-
Dependency. The competitor's application is dependent on the gatekeeper's engineering team, with little ability to fix defects—and all software has defects—and mostly has to wait for the gatekeeper to do it. This is true even if the library is nominally open source, because it's a huge amount of effort to find and fix problems in other people's code. Additionally, whenever the gatekeeper changes their library, you just need to update, even when it's a big change.
-
Security. The competitor is taking on the union of all the vulnerabilities in each library they bring in. This creates problems whenever a defect is found because every competitor needs to upgrade (this is always a problem with vulnerabilities in libraries, of course, which is one reason why people try to minimize rather than maximize their dependencies). Effectively, the security of the competitor's app becomes that of the weakest of the gatekeepers they interoperate with, which is obviously bad.
All of these problems of course exist any time you take a dependency on another project, which is why engineers are careful about doing it. However, in most of those cases the provider of the dependency wants you to use their code—you may even be paying them—and so is motivated to help. That's not really the case here. The bottom line is that I think this is a pretty bad approach, so I'm not going to spend much more time on it in this post.
Common versus Gatekeeper-Specific Interfaces/Protocols #
The big question here is whether gatekeepers will use (or be required to use) a common set of protocols/interfaces or whether they would be able to just dictate their own interfaces that anyone who wanted to interoperate with them would have to use. Often this was phrased as whether the gatekeepers would be required to implement "standards", but "standards" can mean anything from "this is what everyone does" to "this is ratified by the International Telecommunications Union (ITU)", so I'm not sure how helpful that term really is. The key question is whether everyone is going to do more or less the same thing or whether connecting to each gatekeeper will require doing something new. As I said above, I think this has some obvious technical advantages.
Implementor Complexity #
The biggest advantage of a common set of protocols/interfaces is that it makes life much easier for access seekers/competitors. If you need to build to entirely different interfaces for each gatekeeper, it's going to be a lot of work to add a new gatekeeper, which obviously doesn't promote interoperability on the broad scale, and is likely to lead to lower service quality because you have to spread your effort out across all the implementations. Alissa Cooper had a great slide showing what this looks like, where every competitor has a little—or actually not so little—copy of every gatekeeper's system in their app:
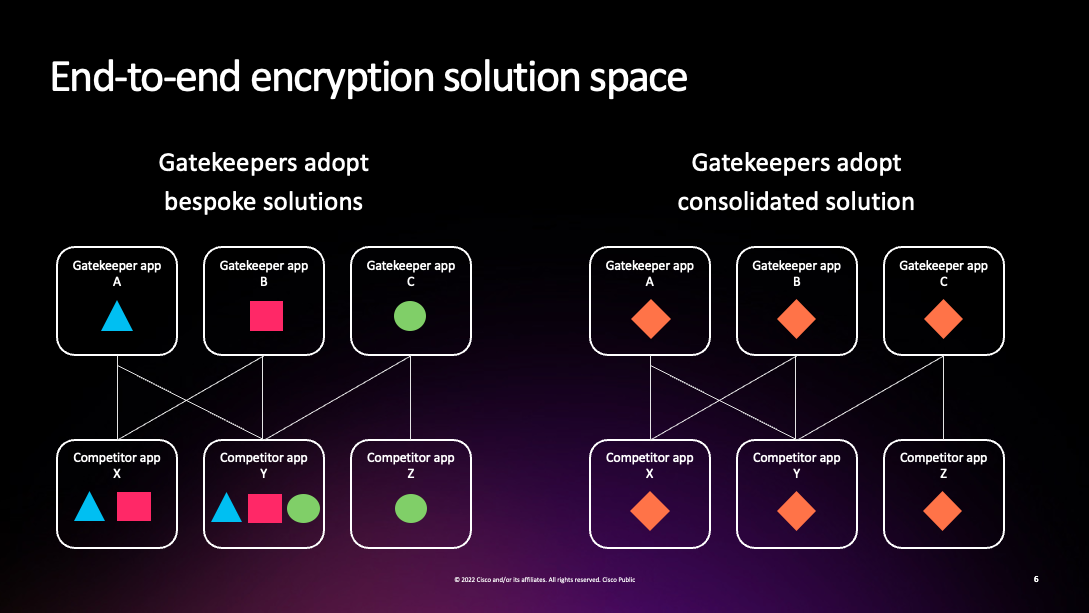
This model, where an app speaks a bunch of different protocols but tries to present a unified user interface (what Matthew Hodgson was calling a "polyglot app") used to be reasonably common back in the early days of instance messaging, where there were multiple open (XMPP, IRC) or semi-open (AIM), messaging systems. This means we know it's possible but we also know it's a lot of work. By contrast, with a single set of protocols/interfaces each app only has to have a single implementation that it can use everywhere and can focus on making it really good.
Clearer Specifications #
As described above, one big barrier to interoperability is lack of clear specifications. It's just incredibly hard to write an unambiguous document, and it's even harder when you're documenting some pre-existing piece of softwarethat never really had a written specification—as is most likely the case for many of the systems in this space—it's just way too easy to implicitly import assumptions about how your system actually behaves without clearly documenting them.
Standards development organizations like IETF and W3C have gotten a lot better at this over the years and have developed a set of practices that contribute to specification clarity. These include:
- Early implementation and interop testing.
- Automated test harnesses, both for interoperability and for conformance (e.g., WPT).
- Widespread review using code collaboration tools (e.g., Github) that make it easy for people to report small issues.
- Formal review and analysis for the most security critical pieces (for instance, TLS 1.3 had at least 9 separate papers published on its security before it was published).
These practices aren't a panacea, of course, and many IETF and W3C specs are still impenetrable, but in my experience the ones where the community really agreed they were important (TLS, QUIC, etc.) are reasonably clear. The main idea here is about getting as many eyes on the problem and from as many different perspectives as possible. This is only possible in an environment of collaboration across many organizations and it's hard to see how it will work when gatekeepers just publish specifications and throw them over the wall to competitors.
Developer Experience #
As discussed above, much of the experience of developing a protocol implementation is trying to interpret the specifications and figure out why your implementation is misbehaving. This is obviously much easier if there are open source implementations and a community of other implementors you can work with. If instead we're going to have gatekeeper published interfaces, then the gatekeepers will need to provide quite a bit of support to developers who want to talk to their systems. At minimum, this looks something like:
- Detailed specifications
- that really are complete enough to implement, ideally including example protocol traces and "test vectors" for the cryptographic pieces.
- Public test servers
- that developers can talk to. These need to be separate from production servers because testing in production is too dangerous. Moreover, they need to have a much higher level of visibility (at minimum very detailed logs) so that developers can see what is going wrong.
- Live support
- from engineers who understand how things are implemented and can help with debugging when log inspection fails.
- Stable interfaces
- that remain live once published, so that developers aren't constantly having to update their code.
Without this level of support it's going to be extremely difficult for competitors to make their code work in any reasonable period of time, let along update them as the gatekeeper makes changes.
Deployment Issues with Multiple Gatekeepers #
Most of the scenarios people seem to be considering involve one or more competitors interoperating with a single gatekeeper, e.g., Wire and Matrix talking to WhatsApp. This is a good first step and it's of course not straightforward, but it's really playing on easy mode, because the competitors have a real incentive to do whatever it takes to interoperate with any gatekeeper. What happens when someone on gatekeeper A wants to talk to gatekeeper B? If everyone just publishes their own protocols, then one of the gatekeepers has to implement the other side's version. It's not clear to me that this is required by the DMA. And if it is required, who will have to do it?
This issue is particularly acute in group message contexts. As a number of panelists mentioned, group messaging is now the norm and 1-1 is just a special case of a small group. Once you have large groups, you have the possibility of a group which involves more than one gatekeeper. Consider the case shown in the diagram below:
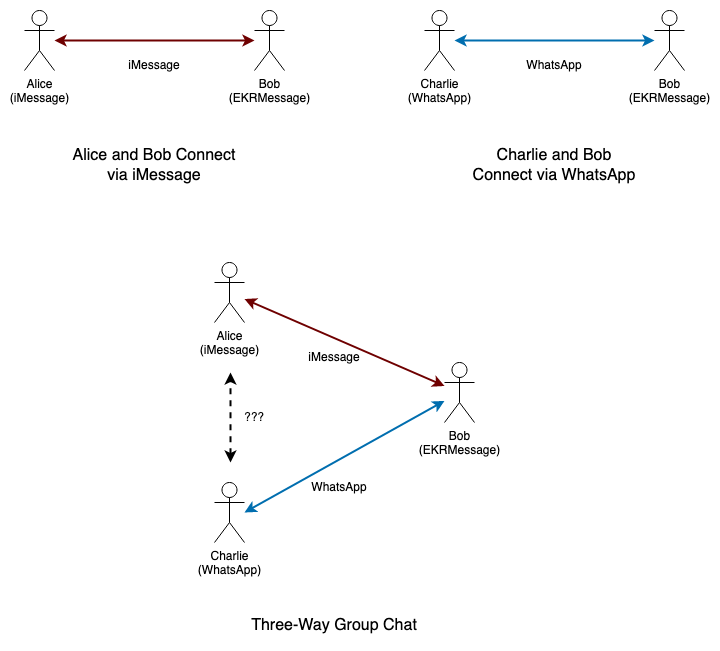
In this example, Alice and Charlie are on iMessage and WhatsApp respectively. Bob is on EKRMessage and is able to individually communicate with them because that client implements those interfaces. As noted above, this is inconvenient, but will work.
Now what happens when Bob wants to create a chat with Alice and Charlie? He can send and receive messages to each of them individually, but if neither WhatsApp nor iMessage implements compatible interfaces, then when Alice or Charlie sends a message, the other side can't receive it. Importantly, unlike the simple 1-1 case between gatekeepers, this looks to Bob like a defect in his messaging system, not like noncooperation by the gatekeepers. There's not much that Bob's client can do about it: it could presumably decrypt the messages and reencrypt them, but this destroys end-to-end identity, which is undesirable.
The point here is that in order to have interoperable messaging work well in group contexts, basically everyone has to implement the protocols of anyone who might be in the group.[6] This will sort of work if there are a pile of protocols, but obviously it would be a lot easier and cheaper if instead everyone implemented something common.
Having a common protocol is even more important in videoconferencing situations: video tends to take up a lot of bandwidth and sending an individual copy of the media to each receiver can easily overrun consumer Internet links. Instead, large conferences typically use what's called a "star" configuration in which each endpoint sends one copy of the video to a central server (a media conferencing unit (MCU)) which then retransmits it to each receiver. But if a group with N gatekeepers means that I need to send in N different formats, then this will be dramatically less efficient. However, this is even true to some extent for messaging: the new IETF Messaging Layer Security (MLS) protocol was designed to work well in large groups, but won't work as well if you have to do pairwise associations.
Identity #
Identity presents a special problem for reasons I've discussed previously. Those posts have more detail, but briefly each endpoint needs to be able to discover and verify the identity of every other endpoint. As with everything else, this can be done either with a common protocol or with pairwise implementations of gatekeeper protocols. However, the situation is more complicated here because many messaging systems use overlapping namespaces.
In particular, it's quite common to use phone numbers (E.164 numbers) as identifiers, as (for instance) both iMessage and WhatsApp do. This raises a number of questions:
-
When someone from iMessage sends a message to someone from WhatsApp, how does their identity appear?
-
How do messaging apps know which service to use when given a bare E.164 number?
-
What happens if someone has an account on two phone-number using services.
There are several possible approaches to addressing these issues (as discussed in the above-linked posts) but we're going to need to have some kind of answer, and if each system is left to solve it itself, there is likely to be a lot of confusion.
I did want to call out one particular risk: it's natural—at least to some—to want this to be as seamless as possible, for instance by using phone number identifiers and automatically identifying the right service to use, but this increases the attack surface area so that multiple providers can assert a given identity. There are potential ways to mitigate this (see previously), but they would actually need to be specified and deployed. This is also an area where it would be advantageous to have a single solution everyone agreed on, both because it's hard to get this right, and because it would make it easier to address questions of who owned which identity.
Timeline #
One of the big concerns that I've seen raised about having a system based on common protocols is that the DMA sets a very ambitious timeline and that standards can take a long time to develop. There certainly is some truth in this, but the good news is that many of the pieces we need already exist (indeed, we often have several alternatives):
| Function | Protocols |
|---|---|
| End-to-end key establishment | MLS, OTR, Signal (and variants) |
| Identity | X.509, Verifiable Credentials, OIDC |
| Messaging format | MIME, Matrix |
| Message transport | XMPP, Matrix |
| Media format negotiation | SDP |
| NAT Traversal | ICE |
| Media Transport | SRTP |
| Voice encoding | G.711, Opus |
| Video encoding | VP8, AV1 |
Some of these pieces are in better shape than others—I'd really prefer not to use SDP if I can avoid it!—and they don't all fit together cleanly, so it's not just a simple matter of mixing and matching, but it's also not like we're starting from scratch either. Moreover, the pieces that are earliest in the timeline are also the ones that are the best understood.
My sense is that the best way to proceed is to have what might be called a hybrid approach: use standardized components where they exist and temporarily fill in the gaps with proprietary interfaces specified by the gatekeepers while working to develop standardized versions of those functions. Once those versions exist, then we can gradually replace the proprietary pieces. The highest priority here should be getting to common formats for the key establishment and everything inside the encryption envelope (messages, voice, video), because those are the pieces where incompatibility causes the biggest deployment problems, as discussed above; fortunately, these are also some of the most baked pieces and—at least in the case of voice and video—where I expect there is a lot of commonality just because there are only a few good codecs.
I do think it's true that it's probably easier to get to some level of interoperability—especially at the demo level—by just having gatekeepers publish interfaces, but it's a long way from something to real reliable interoperability (we learned this the hard way with WebRTC), and there's going to be a long period of refining those interfaces and the corresponding documentation. That's time that could be spent building out common protocols instead, with a much better final result.
Final Thoughts #
Having multiple non-interoperable siloes is clearly far from ideal and it's exciting to see efforts like the DMA to do something about that. We know it's possible to build interoperable messaging systems and we've got multiple worked examples going back as far as the public switched telephone network and e-mail. Even WebRTC is partially interoperable in the sense that multiple browsers can communicate on the same service but not on different services. To a great extent our current situation is due to a particular set of incentives for gatekeepers not to interoperate; the way to get out of that hole is to give them the incentives to build something truly interoperable.
Some current bridging systems actually rely on the user having a copy of the gatekeeper's app on the local system and remote control that app. This doesn't seem like a very good solution for reasons which should be obvious. ↩︎
For client/server protocols, people will often stand up a cloud server endpoint. For extra credit, you can have an endpoint which will publish connection logs so that the other side can see your internal view on what happened. ↩︎
I don't think that local gatewaying is a good technical design because it requires terminating the encryption from the gateway in the local server and then re-encrypting it to the user's client, which destroys a lot of information, such as end-to-end identity. This can be a useful prototyping technique, but I don't think it's a great way to build a production system. ↩︎
Though the IETF's practice of using 72-column monospaced ASCII does make things longer. ↩︎
In the "information hiding" sense of avoiding the consumer having to think about it, rather than keeping it secret, though of course they might also want to keep the details secret. ↩︎
Technically you can get away with less than a full mesh, by having some kind of tiebreaker for each pair, but it's going to be fairly close to a full mesh. ↩︎