Network-based Web blocking techniques (and evading them)
You can't block what you can't see, and modern protocols are designed to hide what users are doing
Posted by ekr on 09 Feb 2023
Via Joseph Lorenzo Hall, Patrick Breyer, and EDRI, I see that the EU's Internet Filtering requirements (sometimes called "chat control") are continuing to move forward. The legal language is a bit hard to wade through, but it appears to require Internet Service Provider (ISPs) to block specific content on Web sites, identified by URL.
Article 16 lays out the scope of blocking order:
The competent authority shall also have the power to issue a blocking order requiring a provider of internet access services under the jurisdiction of that Member State to take reasonable measures to prevent users from accessing known child sexual abuse material indicated by all uniform resource locators on the list of uniform resource locators included in the database of indicators, in accordance with Article 44(2), point (b) and provided by the EU Centre
And then Article 18 lays out requirements for user notification and redress:
Where a provider prevents users from accessing the uniform resource locators pursuant to a blocking order issued in accordance with Article 17, it shall take reasonable measures to inform the users of the following:
(a) the fact that it does so pursuant to a blocking order;
(b) the reasons for doing so, providing, upon request, a copy of the blocking order;
(c) the users’ right of judicial redress referred to in paragraph 1, their rights to submit complaints to the provider through the mechanism referred to in paragraph 3 and to the Coordinating Authority in accordance with Article 34, as well as their right to submit the requests referred to in paragraph 5
Unfortunately, as EDRI observes, this kind of filtering is not really technically practical in today's Web. In this post I talk about the technologies which are used for Web filtering, as well as some of the privacy and security technologies which make that sort of blocking harder. This post is intended to be self-contained, but you might find previous posts on tracking and browser privacy features (tracking and blocking are closely related) and IP concealment useful background.
Get EG in your mailbox #
If you like what you're reading here, you can, as they say "smash that subscribe button" to get the newsletter version delivered right to your mailbox.
Threat Model #
In many security situations there's pretty broad consensus on who is the attacker (e.g., the person trying to steal your credit card number), and who is the defender (the person who doesn't want their credit card stolen), and traditionally in the design of security protocols we think of the network as the attacker and the job of the protocol to be to defend you against the network. However, in this situation, the entities trying to block certain content usually think of themselves as the defenders, either because they are trying to block content which is illegal (such as Child Sexual Abuse Material (CSAM)) or because they want to control the use of their own network (e.g., to protect it against malware-infected machines or to stop their employees from exfiltrating company secrets in what's called Data Leak Prevention (DLP)), and the endpoint trying to evade filtering as the attacker.
Debates in this area tend to quickly devolve into questions about the legitimacy of various kinds of blocking and how sympathetic participants are to them. In my experience such debates don't usually get very far and I don't propose to engage with them here;[1] the purpose of this post is just to lay out the technical situation of that is and is not possible given the current and anticipated future state of the Web.
Note that it's not always the case that the interests of the user and the interests of the blocker are opposed. For instance, consider the case where the network wants to block access to sites which host frauds or malware: the user presumably doesn't want to download malware, and so would potentially benefit from the network preventing access. intended to protect the user from fraud and malware. However, these technologies are value neutral: the same mechanisms that might allow the network to block access to CSAM or malware also allow it to block access to Facebook or to Google search; the same goes for technologies for evading blocking.
Endpoint Status #
The most common and familiar situation is when the endpoint isn't really trying to evade blocking but also isn't actively cooperating with it, as is the case with most consumer devices. The software on the device usually implements some set of default protections (e.g., HTTPS), as discussed below, but they're ones that are suitable for full-time use, rather than fancy ones that would be expensive, inconvenient, or slow. They might also contain some filtering mechanisms, though usually ones that the vendor has judged users will want (e.g., Safe Browsing) and in many cases these can be disabled:

Another quite common case is one in which the device is managed, for instance, one used by employees of a company but which actually belongs to the company and where the company controls the software on the device (e.g., via Mobile Device Management (MDM). For obvious reasons, it's much easier for the network to control the behavior of managed devices. Most consumer devices are of course unmanaged; this didn't always used to be true for mobile devices, where it was common for carriers to install various kinds of software before selling them, but Apple's direct sales, their insistence on a standard software load, and the subsequent changes in industry practice mean that in many of not most cases smartphones are not meaningfully under control of the carriers. Many work devices are managed, but not all; of particular concern to many enterprises is what's called bring your own device (BYOD), in which people use their own devices for work purposes; unsurprisingly, employees are often unwilling to allow their employers to control the software on these devices and so in many cases they will be unmanaged.
On the other side of the spectrum, we have endpoints which are deliberately trying to avoid monitoring. This could be something the user wants, for instance because they are in a jurisdiction that restricts Internet access and are using something like a VPN or Tor. It could also be because there is malware on their machines. In many cases, that malware will want to talk to its command-and-control (CNC) servers. However, this software only needs to be able to talk some prearranged set of servers and thus doesn't need to speak standard protocols—though it might impersonate them!—and might share secret information with those servers. This makes evasion easier.
Blocking Techniques #
The difficult part of blocking traffic isn't really the blocking itself but rather knowing what traffic to block. It's fairly straightforward to just disconnect the Internet, but that makes the network useless. What you want is selective blocking in which you block only the traffic of interest and allow the rest of the traffic to pass through (conversely, many anti-blocking techniques are designed to degrade the visibility necessary for selective blocking, thus forcing the network into a position of blocking all traffic or none of it). There are a number of ways to get the information of what content the endpoint is trying to access.
DNS-Based Blocking #
One very common place to do blocking is at the DNS layer (see my series on DNS for background here). DNS-based blocking is very technically straightforward because the client directly asks the DNS server for the contact information (IP address) of the Web server it's trying to contact, so it's easy to add a filtering step. Moreover, there are a number of DNS providers (e.g., Umbrella/OpenDNS or Cloudflare) which offer filtered DNS servers. Umbrella will even let you configure which sites you want blocked. The DNS server has a number of options if a blocked domain is requested, including returning an error to the client or returning a bogus IP address which can then be blocked; in either case, the client will not be able to contact the ultimate server.
Network-imposed DNS-based filtering works because the network typically provides the DNS server used by endpoints (notifying them about it via DHCP). However, it's also possible for users to configure their devices to use a different server or for endpoint software to do its own resolution via a non-network resolvers. For instance, it's quite common for people to configure their devices to use Google Public DNS (8.8.8.8) or Cloudflare DNS (1.1.1.1),[2] and Firefox is increasingly using DNS over HTTPS in a mode which bypasses the local resolver in favor of a "trusted recursive resolver" that has agreed to comply with Mozilla's policy requirements around user security and privacy. Obviously, malware can do the same.[3]
Historically, if the user just pointed their device at a public resolver, the network could still do DNS filtering by intercepting the communication to the resolver. However, if DNS traffic is encrypted to the server, that prevents this kind of filtering. Ultimately, if networks want to enforce DNS-based filtering in these circumstances, they need to prevent connections to the public DNS resolvers, which, given that they run DNS over HTTPS, brings us back to the same problem of blocking Web traffic, at least for unmanaged endpoints; for managed endpoints, it's generally possible to just disable encrypted DNS; in fact Firefox does this automatically if it thinks the endpoint is managed.
Even where DNS-based blocking is effective, it's a fairly limited mechanism. Specifically:
-
It can only block on domain name and not URI.[4] For instance, if you want to block
https://example.com/contrabandand nothttps://example.com/totally-cool, that's not possible because the browser just asks for the address ofexample.com. -
It usually can't provide any notification to the user of what happened; the server can just make it look like the name doesn't exist or the server isn't offline. It's of course possible to provide the address of a server controlled by the network, but if the client is trying to connect via HTTPS, then this will result in a connection failure (more on this later), not a comprehensible message to the user.
On this second point, I've seen proposals for allowing the server to send back a more detailed error message telling the endpoint that a site was blocked, for instance.
{
"c": ["tel:+358-555-1234567", "sips:[email protected]",
"https://ticket.example.com?d=example.org&t=1650560748"],
"j": "malware present for 23 days",
"s": 1,
"o": "example.net Filtering Service"
}This is in theory possible, but there are several obstacles that prevent unilateral deployment by ISPs or enterprise networks. First, no existing Web client supports this new message, so at present they will just show a failure as described above. Second, if the browser uses the operating system resolver (as, for instance, Firefox does when it's not using DoH; Chromium uses its own resolver), then it will only be able to get this message once the operating system is updated to support it, which is likely to take a very long time. Finally, the browser would need to figure out some way to present the information so that it's clear what's happening and that it can't be used to fool the user into accepting the error message as coming from the valid site ("please enter your social security number here!"); this problem is presumably soluble if there is enough interest otherwise.
IP Filtering #
If you're not doing DNS-based filtering, your next opportunity to filter is at the IP layer. IP-layer filtering is exactly what you think it is: the network blocks connections to certain IP addresses. There are a number of possible alternatives here (drop the packets, send a TCP RST, BGP poisoning) but they all amount to the same basic idea, which is to render certain IP addresses inaccessible. Unlike DNS-based filtering, it's not straightforward for clients to just opt out of IP-based filtering: the network has to be able to see the server's IP address to deliver the packets, so if you want to bypass it, you need to get a new network.
Ignoring the Great Firewall #
In general, once the network has identified your connection for blocking, that's it but in at least one case, this was easy to avoid. China famously uses a blocking system often called the Great Firewall, which operated in part by sending TCP RSTs when it detected things it didn't like. This is cheaper technically than blocking all the packets. Some time back, Clayton, Murdoch, and Watson discovered that clients could just ignore the TCP RSTs, in which case the traffic would continue to flow. I don't know if this is still true.
On the other hand, IP-based filtering is even less precise
than DNS-based filtering. Obviously, it can't see the specific
resource you are connecting to, but it can't even always tell
which Website is being accessed: it's very common for multiple
Web sites to share the same IP address (for instance,
every Github Pages site seems to have the same IP,
as does every Substack that has an address ending
in substack.com), and so you can't IP block one site without
blocking others. Even in situations where there isn't
IP sharing, but where many sites share the same hosting
provider, the hosting provider can readily change which
IP addresses correspond to which sites, making it
hard for the blocker to keep up. Thus, IP blocking is
good for blocking access to big sites which don't share
infrastructure, such as Google or Facebook, but not so
good for smaller sites.
Like DNS-based filtering, IP-based filtering isn't able to provide any feedback to the user about what went wrong: it just looks like a network failure. Unlike DNS-based filtering, I haven't even seen credible proposals for how to add such a function and most of the obvious avenues seem fairly unattractive to browser makers.
Content Analysis #
The next major approach is to inspect the application layer traffic (e.g., HTTP or TLS), and filter based on that. This is a very powerful technique when applied to HTTP because it allows you to see all of the data being exchanged, including the URL being requested and all of the content being returned, so you can do some fairly fancy filtering. For instance, you could not only check the URI but scan the returned content for malware or CSAM.
However, this sort of filtering is increasingly impractical because the vast majority of Web traffic is now encrypted, as shown in the figure below:
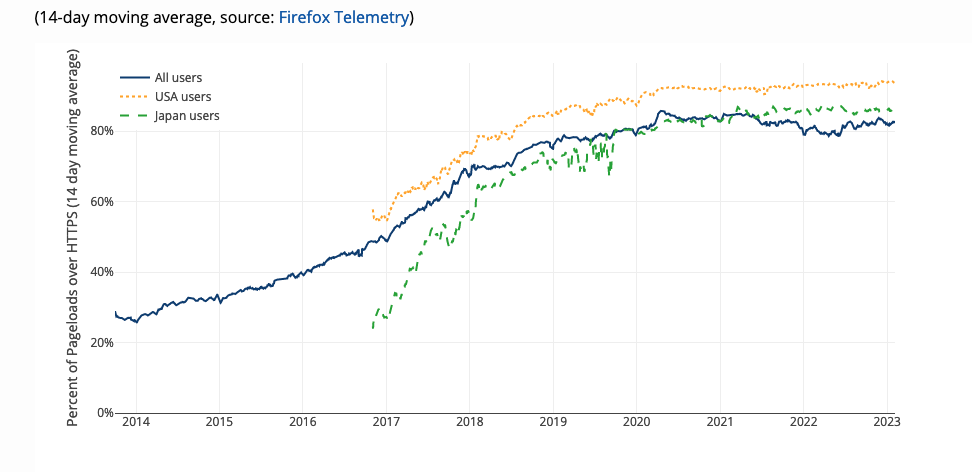
[Source: Let's Encrypt]
When the traffic is encrypted, the network can't see the content of the HTTP connection, which means it can't see either the URL or the response—this is the point of encryption!—so the amount of filtering possible is quite limited.
The main piece of information that the network can see is the hostname of the Web server. This is carried in two places in the TLS handshake:
-
In the Server Name Indication (SNI) field of the client's first message (the ClientHello). (This is the field that allows you to have multiple servers on the same IP).
-
In the server's Certificate message, although this may not be unique, as a server may have a certificate that covers multiple sites. For instance, there is a single "wildcard" certificate for
*.github.iothat works for any site ending in.github.io.
In TLS 1.3, the server's Certificate message is encrypted, which means that the only information about the server's identity available to the network is in the SNI in the ClientHello. You shouldn't be surprised to hear that there is now work underway to encrypt the ClientHello message to conceal the SNI, using a technology called (surprise!) Encrypted Client Hello (ECH). ECH hasn't been widely deployed yet, but it's under active development by browser vendors and some server operators, such as Cloudflare. If ECH is in use, then the network will not be able to use TLS to distinguish between any of the servers on the same IP address, reducing the filtering granularity to that of IP blocking.
Browsers and MITM Proxies #
MITM proxies are a difficult problem for browsers: generally you want to allow users to add their own trust anchors to permit so-called "Enterprise CAs" in which the enterprise has its own private names that it issues certificates for but it doesn't want to have publically accessible. This is still somewhat common, though arguably less necessary in the era of free certificates. However, it would be possible for browsers to detect and prevent the use of these enterprise CAs for any site which also had a public certificate, thus more or less preventing MITM proxies from working. However, the consequence of this would be to break the browser on any network which had such a proxy, which is obviously not a desirable outcome. The result is that we're in a not-great equilibrium that is hard to get out of without causing a lot of breakage.
MITM/Intercepting Proxies #
Many enterprise networks use what's called a "man-in-the-middle" or "intercepting" proxy. This is a network device which sits in between the client and the server, impersonating the server to the client and the client to the server. It decrypts the traffic between client and server, inspects it, and then re-encrypts it. "But wait" I can hear you say. "Isn't the whole point of TLS to prevent this kind of attack?!" Ordinarily yes, but the organizations who deploy these proxies also install their own trust anchors on the client, which allow the proxy to issue certificates which are acceptable to the client.
Obviously, this doesn't work in consumer settings where the network doesn't control the client. Of course, one could imagine a nation requiring users to adopt a new trust anchor, enabling them to intercept any connection, but this obviously has extraordinary risks in terms of surveillance. In the one case where a country went as far as trying it (Kazakhstan), browsers responded by explicitly blocking the trust anchor, so you couldn't install it.
Even in an enterprise, MITM proxies aren't really a great system: they're expensive to operate and because they have access to the plaintext of the connection, present a security and privacy risk to users of the system. There is also evidence that the implementation quality of these proxies is less good than that of browsers, which creates additional risks.
In order to address some of these issues, enterprises will sometimes (often?) configure their proxy to selectively decrypt traffic. The idea here is that the proxy looks at the SNI field and only decrypts traffic so some destinations (e.g., Facebook but not your bank). These enterprises (and the vendors who sell these devices) are worried about ECH because it has the potential to make this sort of selective decryption impossible. I don't believe that this is likely to be a problem in practice, however: if you are able to install your own trust anchor, you should also be able to configure the browser to disable ECH. Moreover, ECH information is delivered over DNS, so as long as you can control DNS (or, in the case of Firefox, disable DoH, which happens automatically when it detects a new trust anchor) you can just suppress the use of ECH.
I did want to flag one point here about this kind of selective
decryption, which is that it only works if you are dealing
with an endpoint which is standards compliant and sends the
correct SNI value. If you are dealing with malware, it can
put whatever it wants (e.g., www.bankofamerica.com in the SNI) but then connect to
its own CNC server. Selective decryption based on SNI only
works with clients which aren't themselves malicious, like
Web browsers. This is true whether or not the client
is using ECH. Note that this form of evasion only works
because of prearrangement between the malware and the CNC
server, so it's not deployable as a general mechanism for
Web browsers.
Traffic Analysis #
In principle it's possible to learn about the content of on encrypted traffic by looking at packet size, timing, etc. For instance, the traffic pattern associated with watching video (a lot of big packets sent continuously to the client) looks very different from that associated with using Webmail (small, relatively intermittent, chunks back and forth). This approach is often called "traffic analysis". Goldberg, Wang, and Wood provide a good overview of the situation for website identification, and Cisco actually sells technology for doing this (academic paper by Anderson and McGrew here) that tries to identify malware.
My understanding of the current state of traffic analysis is somewhat powerful as an attack on privacy: you certainly can learn more about people's browsing behavior than people might want you to learn, and is useful as part of an enterprise threat response system that attempts to detect malicious behavior, but is less useful at distinguishing precise behavior (e.g., which exact images did someone view on a specific site). It's also comparatively expensive to operate technically, doesn't scale that well, and requires seeing more behavior over a longer period than other techniques (e.g., SNI), which can make a decision very early in the connection. Thus, my sense is that it's less useful for making large scale content-based decisions for things like CSAM detection or DLP.
Client-Side Agents #
It's also possible to install a piece of software (an "agent") on the endpoint itself that monitors that behavior of the device. These agents sit into a variety of different and somewhat overlapping categories (anti-virus, DLP, endpoint detection and response (EDR), etc.) but basically they all do the same kind of thing, which is to say spy on other programs and report back or otherwise act on behavior it thinks is suspicious. These agents typically have elevated privileges and so can in some cases observe the internal details of other programs, for instance, by actually injecting their own code (this is a persistent problem for browser vendors because it can negatively impact the stability of the product). For instance, this would allow the agent to see the plaintext associated with encrypted traffic, including the URI, the content, etc.
In some cases, this software is something that users install themselves (e.g., antivirus), but in others it's something that is required by their employers, schools, etc. In the latter case, it may be deployed in parallel with network monitoring techniques to provide multiple views of the same activity. For instance, you might have a client-side agent but also do MITM interception This approach provides defense in depth: if you have such an agent on your work computer, the natural way to avoid monitoring is to use an unmonitored personal device. Network-level monitoring can help detect this, even if it can't see precisely what's happening, though it's obviously far less powerful in an age of ubiquitous fast mobile Internet: people can just turn off the WiFi and bypass your monitoring.
In general, if you have a third party monitoring agent installed on your computer, it's safest to assume it can do anything at all on that device (Microsoft's "Immutable Law of Security #1"). In particular, if you have an agent on your computer that is operated by someone else, the safest assumption is that they have complete control of your computer. In some cases, these organizations will have policies about (for instance), what data they look at, but that doesn't mean that there is any technical enforcement mechanism that prevents them from violating those policies. The few times I've actually looked at this I came to the conclusion that there weren't any meaningful technical controls; it's possible someone has built something safer in this space, but given the current state of computer security it's a very difficult problem.[5]
Client-side agents are a popular technique in enterprise settings, but actually requiring their installation on everyone's non-work devices seems like it would be a major policy change, and I don't think it's likely that the EU would require it (at least I hope not!).
VPNs, Proxies, etc. #
As should be clear from the above, in the absence of cooperation from the endpoint, the network only has fairly limited abilities to selectively block traffic. More or less all it can do is to block specific sites, but not control what content people access on those sites. As technologies like encrypted DNS and ECH become more common, even that level of blocking will start to become more difficult. It will still be possible to block large sites which have their own IP space (e.g., Facebook or Google), but it will be harder to block just one site hosted by a given service, such as one Github pages account or a single site hosted by a CDN.
Encrypted DNS and ECH are designed to be "always on" technologies which people can just use for their regular browsing; this means that the protection they can offer is limited. However, it is also possible to provide a higher level of protection at greater cost by proxying traffic to another network which is not subject to blocking/filtering. This is what technologies like VPNs, Tor, and iCloud Private Relay do (see here for an overview of these techniques). The only really feasible way to prevent people from bypassing blocking using these mechanisms is to block access to the proxy/relay/VPN service entirely, which you would typically do by the same kind of mechanisms I've been discussing above. I've also seen some research designs for making that kind of blocking more difficult (e.g., Telex), but that's out of scope for this post.
What is technically feasible #
With this technical background, we can now look at the EU proposal. Assuming I am reading it correctly (and EDRI reads it the same way), it seems to have two requirements that are technically problematic.
First, as noted above, it's not really possible to block based on a list of specific Uniform Resource Locators, but only on sites. It's not clear to me how useful this really is: if there are specific sites which are just acting as hosts for CSAM, then there are a number of potential avenues for having them shut down directly, rather than filtering at the customer level (this happens fairly often with sites which engage in various kinds of copyright and trademark abuse). The primary reason why URL blocking is useful is that it allows you to selectively block part of a site—though here too it's not quite clear to me why the authorities can't have that content taken down once they are aware of it—but as noted above, that kind of selective blocking is simply not practical to do at the network level once traffic is encrypted.
For similar reasons, it's also not really possible to provide notice to users as required in Article 18 because there's no channel for the provider to do so. In most cases the client will be trying to establish an encrypted channel to the server. The network can instead reroute that connection to its own servers, but those servers cannot properly authenticate as the server, so all they can manage to do is cause the browser to show the user an error, but can't control the error. Depending on exactly what the provider does, it might look like this:

or like this:
But what it definitely will not have is some message from the provider about why the site is being blocked; there's simply no mechanism to communicate that. It's presumably possible to invent something here, but it's not something that the providers can do unilaterally.
Final Thoughts #
This brings us to the broader point, which is that the network providers are simply the wrong place to situate this kind of blocking. A basic assumption of communications security is that the network is under control of the attacker and 30+ years of work has gone into protecting Internet traffic from potentially hostile networks. This work isn't done, but there's been a huge amount of progress and at this point it's really not practical to do effective fine-grained blocking of traffic without the cooperation or coercion of one of the endpoints.
This is also why I am using the term "blocking" instead of the common term "censorship", which while technically accurate in my opinion, tends to just get us into debates about the definition of "censorship" from those who think that certain forms of blocking are good and that the term "censorship" has negative connotations. ↩︎
However, data from Huston and Damas indicates that most of the use of the big public resolvers is due to ISPs pointing their users to them, rather than users configuring it themselves. ↩︎
The public debate about the use of DoH and DoT has sort of conflated use by browsers with use by malware. The problem with malware use of encrypted DNS exists because there are public DNS servers which offer encrypted service, independently of whether browsers use it. To the extent to which browsers make the problem worse it's because their use of those servers makes it less attractive to just block them entirely. ↩︎
I once explored a design where the DNS server would send the client a list of blocklisted URIs on the requested domain, but this of course requires the client to cooperate, so it's more like Safe Browsing than like a unilateral blocking mechanism. ↩︎
The basic problem here is that if you don't trust the system you are monitoring to behave correctly, then you need access to its internals to be sure that it's not lying to you about its behavior. But that access is inherently abusable. ↩︎