Internet Transport Protocols, Part I: Reliable Transports
Out of the crooked timber of IP no straight thing was ever made
Posted by ekr on 18 Jan 2023
Most people who use the Internet just have some vague idea that it carries data from point A to point B (famously, through a series of tubes). Even people who regularly work on Internet systems tend to work with it through many layers of abstraction, without a clear understanding of the infrastructure components that make it work. This post is the first of a series about one such piece of infrastructure: the transport protocols such as TCP that are used to transmit between nodes on the Internet.
Background: Network Programming #
If you've done any programming of networked systems, you've probably written code that looks something like this:
socket = connect("example.com", 8080);
write(socket, "Hello");
response = read(socket);
print(response);Even if you don't have much experience with networking, this code should be fairly self explanatory:
-
The first line forms a "connection" to the server named "example.com" (see my series on DNS) for how these names work.
8080is what's called "port number" and we can ignore it for now. This function returns an object called a "socket" which represents that connection.[1] Conceptually, this is like dialing the phone and calling "example.com". -
The next line writes the string "Hello" to the server. Note that because we already are connected to the server, we can just pass in the socket, rather than the address of the server.
-
The next two lines reads the response from the socket and then print it out. As before, we don't need to specify the server's address because that's encapsulated in the socket.
As another example, here's a simple server that works with
this client. This server just takes whatever the client
writes to it and sends it back in upper case. The main
difference here is that instead of using connect(), the
server uses accept() which tells the computer to wait
for a client to connect to it on port 8080.
socket = accept(8080);
loop {
result = read(socket);
print(result);
write(socket, result.toUpperCase);
} If we run this client/server pair, we would expect the server to print:
Hello
And the client to print:
HELLO
Of course, the client could write multiple messages, like so:
socket = connect("10.0.0.1", 8080);
write(socket, "At midnight all the agents");
write(socket, "And the superhuman crew");
write(socket, "Come out and round up everyone");
write(socket, "Who knows more than they do");
...In this case, we would expect all of the messages to be delivered and that they will be delivered in order, so that the server prints:
At midnight all the agents
And the superhuman crew
Come out and round up everyone
That knows more than they do
Rather than
And the superhuman crew
That knows more than they do
or
And the superhuman crew
Come out and round up everyone
At midnight all the agents
That knows more than they do
Again, just like a phone call.
What we're seeing here is just the programming interface, though, which is to say it's a set of abstractions that the operating system and the programming language provide to you to write your programs. They don't tell us anything about what's actually happening on the network. That's the subject of this post.
Background: A Packet Switching Network #
The Internet is what is known as a packet switching network. What this means is that the basic unit of the Internet is a self-contained object called an Internet Protocol (IP) packet or datagram. An IP packet is like a letter in that it has a source address and a destination address. This means that when you send an IP packet on the network, the Internet can automatically route the packet to the destination address by looking at the packet with no other state about either computer. A simplified IP packet looks like this:
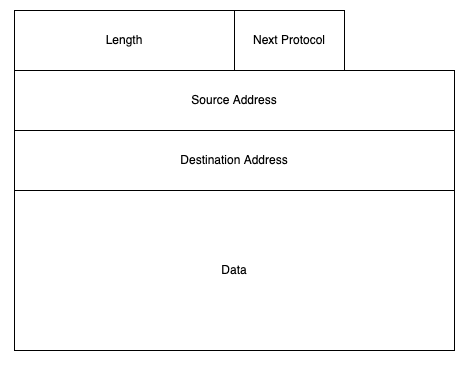
The main thing in the packet is the actual data to be delivered from the source to the destination, also called the payload. The payload is variable length with a maximum typically around 1500 bytes. Using IP is very simple: your computer transmits an IP packet and the Internet uses the destination address to figure out where to route it. When someone wants to transmit to you, they do the same thing. Importantly, for reasons we'll see shortly, packet switching is unreliable: when you send a packet to the other end it might or might not get there ("packet loss"). Moreover, packets don't always arrive in the order they were sent ("reordering").
Circuit Switching #
The alternative to packet switching is what's called "circuit switching". In a circuit switched network, the basic unit of operation is a connection between two endpoints called "circuit". In a circuit switched system, you set up the circuit and then just start sending and everything goes to the entity on the other end of the circuit, like in a telephone call (more on phones later).
In the original telephone network, this was actually a literal electrical circuit:[2] phone service came into your house on a pair of copper wires and when Alice wanted to call Bob, the central office would connect Alice's wires to Bob's wires (there's some more electronics here, but you can ignore this). Originally this was done by having an actual person at a switchboard, which is just a board with a bunch of jacks corresponding to each outgoing circuit from the central office. When Alice wanted to call Bob, she would ring up the operator and tell them who she wanted to call. The operator would plug a patch cable from Alice's jack into Bob's jack, like so:

When the first automatic switches were invented (an amazing story), they worked much the same way: you'd pick up your phone and dial and the equipment at the exchange would connect your wires to the wires of the person you were trying to call. From then on, signals just went from your microphone to their speaker and then their ears and vice versa. Circuit switching is conceptually convenient but has a number of inconvenient properties. In the simplest version, it doesn't allow you to talk to more than one person at once (the second caller gets a busy signal!) and even if you arrange to connect more than one person as in a conference call, you have no way of distinguishing who is who (ever had to ask who was talking?). But of course in a modern computer network your computer is constantly talking to multiple computers at once ("multiplexing"). This works badly with circuit switching but just fine with packet switching because each packet is self-identifying.
The problem with packets #
Packet switching has a number of nice properties, but small self-contained packets are very limiting for the obvious reason that most things that people want to send are more than 1500 bytes, whether they be videos, phone calls, or large files; even Web pages are almost always more than 1500 bytes. Moreover, because packet switching is unreliable and packets might get lost or delivered in the opposite order from the order they were transmitted in, if you just break up your file into a set of packets and send them over the network, the other side may not receive exactly what you sent.
In other words, what we really want is circuit switching, but what we have is packet switching. If you know any computer people, you've probably guessed what I'm going to say next because it's the standard thing to do: we're going to emulate circuits on top of packet switching to build what's often called a reliable transport protocol. What a reliable transport protocol does is provide a service that looks like a circuit (usually called a "connection") but built on top of the unreliable substrate of packet switching. Designing these protocols so they work well turns out to be very substantial undertaking and we've been basically evolving them for the past 40+ years, starting with TCP, which has been used from the early days of the Internet, is one such protocol and more recently with a newer protocol called QUIC, which is built on similar but more modern lines.
The world's simplest reliable transport #
The obvious thing to do here would just be to break up whatever data you want to send into a series of packets and send them to the other side. However, as should be clear from the above, this won't work reliably, because the packets might be lost or reordered, preventing the receiver from reconstructing the data. Thus the minimal set of problems we need to solve is:
- Allowing the receiver to reconstruct the order that the data was sent in, even if the network reorders it.
- Ensuring that data is eventually delivered from the sender to the receiver.
We'll take these one at a time, reordering first.
Reordering #
The reordering problem is fairly easy to solve: we just
add a field to each packet which contains its number.
The receiver just sorts the packets as they are received,
and delivers them to the application once it has all
previous packets. So, for instance,
if the receiver receives packets in order
1 3 2 4 then it will behave like so:
| Packet | Action |
|---|---|
| 1 | Deliver 1 |
| 3 | Store 3 |
| 2 | Deliver 2, Deliver 3 |
| 4 | Deliver 4 |
This is actually not how TCP works, however. Instead, it numbers not packets but bytes. Specifically, each TCP segment (i.e., packet) comes with a sequence number which indicates the first byte in the packet, and a length, which indicates the last byte of the packet. This allows the sender to re-frame data when it retransmits it. For instance, suppose that a TCP connection is carrying typed characters: you want it to send each character as soon as it is typed, so each will be in its own packet, but if you need to retransmit a set of consecutive characters, it's more efficient to put them in their own packet. This only works if the packets contain an indication of which byte is which. For the purposes of this post, however, we'll think of packets as being fixed size and assume there's no reframing.
Packet Loss #
There are a number of reasons that packets can be lost in transmission. For instance, some network element could malfunction and drop them or damage them, or, as we'll see later, an element could explicitly drop them because they exceed available capacity. In either case, if a packet is dropped, the only thing for the sender to do is retransmit it, but how does it know whether to do so? In other words, how do we detect packet loss? One potential approach would be for the malfunctioning element to send some kind of signal indicating that it dropped or damaged the packet. But of course that signal itself might be dropped or damaged by the network. Additionally, the problem might be in a passive element such as a piece of wire which isn't able to send its own messages. Finally, if the problem is a malfunctioning element, then it might malfunction in such a way that it doesn't correctly send a message. In any case, no mechanism where the sender receives a message informing it of a lost packet will work reliably.
The end-to-end principle #
This is a case of what's called the end-to-end principle. The basic observation is that there are a lot of places for things to wrong between point A and point B, and so if you want to ensure that a piece of data arrives at point B, then trusting intermediate elements isn't enough; you need A and B to work together. This doesn't mean that you can't have reliability mechanisms between intermediate elements, but merely that they're not sufficient to guarantee delivery all the way to the other end. Rather, they act as an optimization that allows you to detect failures more quickly than they would have been detected by an end-to-end mechanism.
Instead of having a signal that a packet was dropped, we're going to instead have a signal that the packet was received, called an acknowledgments (often abbreviated ACK). When the receiver receives a packet, it sends an acknowledgment of receipt. This tells the sender that the packet got all the way to the receiver. Of course, acknowledgments have a number of obvious drawbacks:
-
They only tell you when a packet was received, not that it was lost, so the only way you know a packet was lost is by waiting until you expected to see an acknowledgment and then not getting one.
-
The acknowledgment can get lost in transit, so the packet might have been delivered, but this still looks like packet loss.
The reason to use acknowledgments is that they are robust: no matter what is going on in the middle of the network, if the acknowledgment is received, you know the packet got through. If you just keep sending until you get an acknowledgment, eventually the packet should get through (unless of course, the network is totally broken).
The way this works is that after the sender sends a packet it waits for a period of time (see below for how long) for the corresponding acknowledgment. If the timer expires before the sender receives the acknowledgment, then it retransmits the packet, like so:
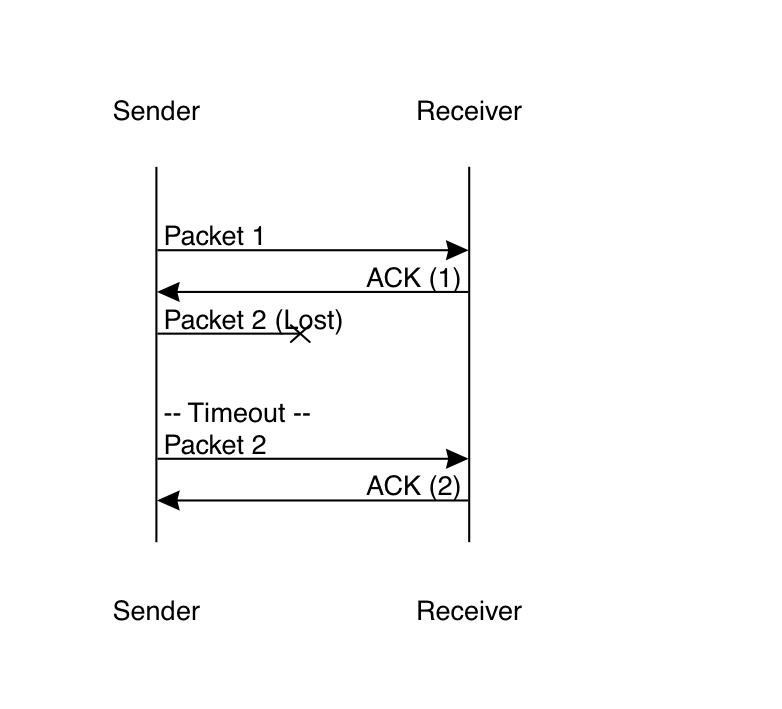
In this diagram, the sender sends the first packet, which arrives successfully, and is acknowledged. However, the second packet gets lost in transmission. Eventually, the sender's timer expires and so it retransmits packet 2. This time it gets through and so does the acknowledgment, so everything is good.
In the simplest version of this protocol, the sender sends one packet at a time. Once that packet is acknowledged (potentially after one or more retransmissions), then the sender sends the next packet. This is what is called a stop-and-wait protocol, because the sender doesn't do anything until it hears from the receiver. The basic problem with this design is that it's slow. The reason for this is round-trip latency: the diagram above shows packets as being sent and received at the same time, but in practice they take some time to get from point A to point B: even on a very fast Internet connection, it can take a few milliseconds for a packet to get delivered, and if the server is around the world, latency can be on the order of a 100 milliseconds. If the sender is waiting for the receiver's acknowledgment, then it's just idle during this period, as you can see in the diagram below, where the sender has to wait for a full round trip before it can send the next packet.
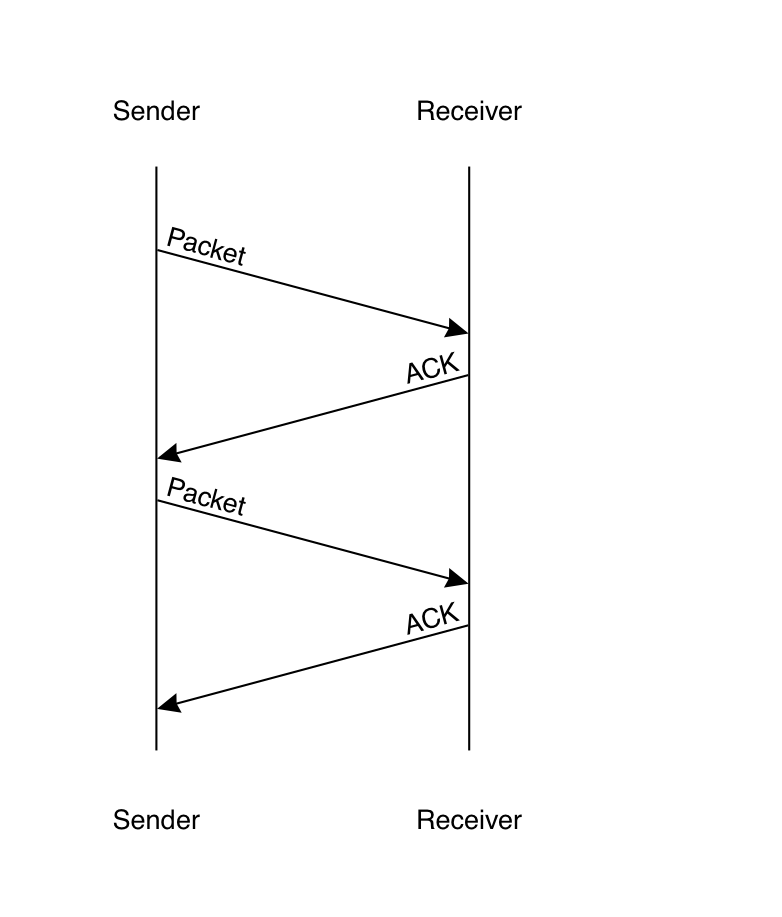
The obvious thing for the client to do is just to send data as soon as it's available but this has two big problems:
-
The sender may be able to transmit the data faster than the receiver wants to consume it. Think about the case of streaming video: the sender could send the whole video to the receiver but this would be really inefficient because the receiver would have to store it all until it was ready to play, and the viewer might decide to only watch part of it.[3] Even in cases where the user wants to receive the whole file, their device might not be able to process the incoming data as fast as the sender can transmit it.
-
The network might not be able to handle the data at the rate the sender can send it. This happens frequently in cases where the sending device is attached to a very fast local network but the end-to-end connection to the receiver is slower. As we saw before, this eventually will overwhelm the slowest network link in between the two endpoints.
We'll deal with the first problem in this post and the second problem in the next post.
Flow Control #
In order to prevent the sender from over-running the receiver, we need a flow control mechanism. The standard approach is for the receiver to advertise the total amount of data it is willing to receive at once (see buffering). The technical term here is the "receive window". The sender can send as many packets as it wants as long as they fit within the window, as shown in the diagram below.
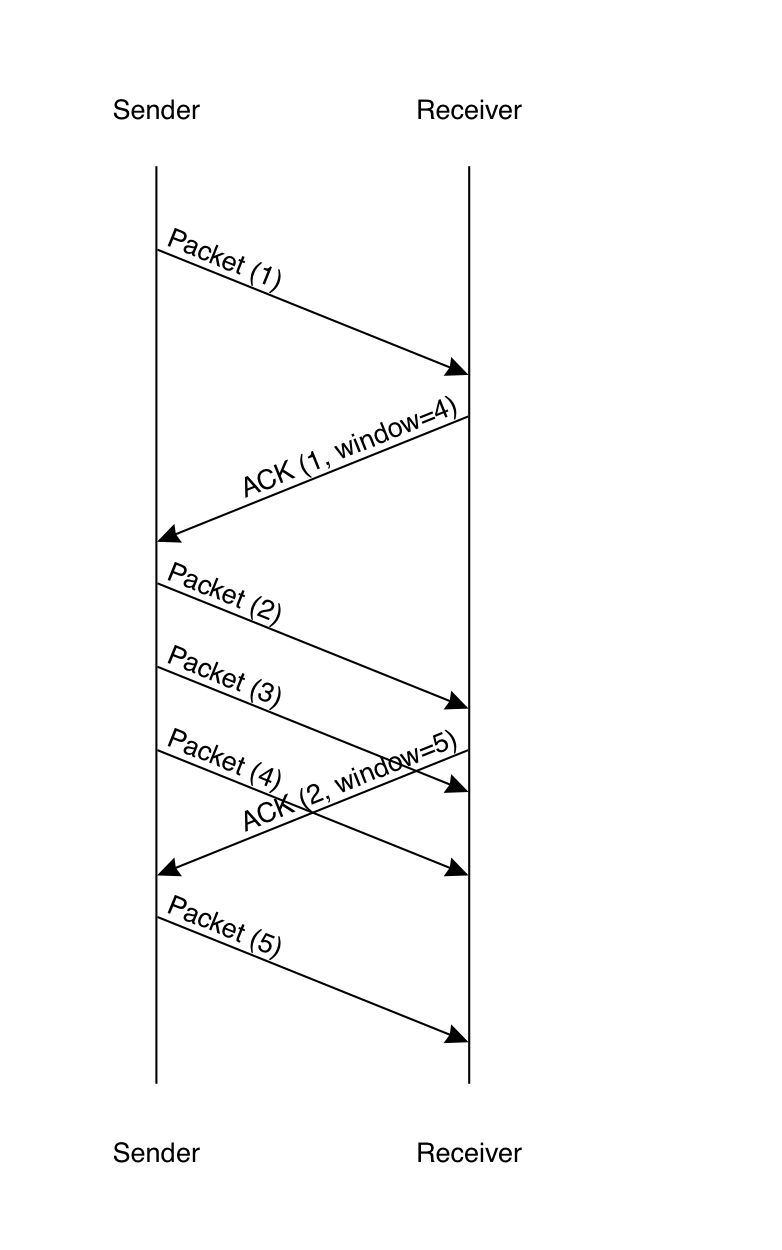
In this diagram, the sender starts out by assuming the
receiver's window is 1, so it sends a single packet.
The receiver acknowledges this packet with the message
ACK (1, window=4), which means "I have received
all packets up to 1 and you can send up to packet 3"
(this is called a "cumulative ACK"). The sender
responds by sending packets 2 through 4, and then waits
for the receiver's ACK. However, in the time that
packet 3 is in flight, the receiver has received
packet 2 and so it sends an ACK acknowledging it and
advancing the window to packet 5. This isn't received
until after the sender has send packet 4, but it
is receives shortly thereafter, allowing the sender
to send packet 5.[4]
This mechanism is usually called "sliding windows", with the idea being that the window of data the sender can send is continuously sliding forwards as ACKs are received. In this example, the sender still has to wait briefly before it can send packet 5, but if the window had been slightly larger, then it might have been able to send continuously, with the ACK advancing the window being received before the sender was ready to send its next packet. This is especially true if the sender isn't sending as fast as its network will support, for instance if it's sending data that depends on user input.
Buffering #
At this point, you may have noticed that there's a lot of waiting here. For instance:
- The sender can't transmit until it has room in the window.
- Once the sender transmits, it has to wait until it receives an acknowledgment, because it might have been lost or damaged.
- If the receiver receives packets out of order it has to wait to deliver the packets to the application until it has received the ones before them.
- If the sender transmits packets faster than the receiving application, the receiving operating system needs to store the packets until the application is ready.
During these waiting periods, it's necessary to store (technical term: buffer) a copy of the packet. For instance, when the program asks the operating system to write something, but there's no available window, the operating system just buffers the packet until window is available. Moreover, during this period the system may be trying to send more packets, which it may or not be able to send immediately. For instance, if an application tries to upload a file, it may send 10 or more packets at once, which the sending system needs to slowly meter out as window becomes available. The sender needs a significantly-sized buffer to store these packets. Similarly, when a packet has been received out of order, it needs to be buffered until the earlier packets are available.
This isn't the only place that buffering happen: not all links on the Internet are the same speed, so it's common to have a situation in which network A wants to send faster than network B can send. In this case, the computer connecting those networks (a router) has to buffer the packets until space becomes available (often this is called a queue). In addition, the user's devices need input buffers where they store packets that have come in but the operating system or application has not yet had time to handle.
In general, all devices on the Internet have some level of buffering to deal with mismatches between the rate at which it receives packets and the rate at which it can handle them, whether that means processing them locally or forwarding them to some other device. Buffering allows these devices to deal with situations where the incoming rate temporarily exceeds the processing rate (which happens all the time) but the longer it goes on, the more packets have to be stored. Most devices maintain a maximum buffer size—if nothing else, limited by the total amount of memory on the device, but typically far less than that—and when that size is reached, then they have to drop packets; either by discarding some of the packets already buffered or by discarding the new packets (or both).
Retransmit Timers #
I've been handwaving a bunch about how the sender sets a timer and waits for the acknowledgment, but that doesn't tell us how long the timer should be. In general, we want the timer to be based on the round-trip time (RTT) between the sender and receiver, which is to say the time it takes a packet to go from sender to receiver, the receiver to respond, and the respond to make it back. If we set the timer shorter than the RTT, then the ACK won't make it in time and the sender will retransmit even if packets aren't lost; if we set it much longer, then we're waiting too long to declare packets lost, which slows down the connection. In practice, you want the retransmit timer to be somewhat longer than the RTT because there's some variation in network speeds, etc., but not too much longer. There's a long literature on how to set the retransmit timer, which I won't go into here.
There's just one problem: we don't know the round trip time, because it's not a property that the sender can see directly. Instead it's a function of the speed of all the network links in between the sender and receiver. Even if I have a fast network, I might be connecting to someone with a slow network. It also depends on how heavily loaded they are at any given moment, because I'm competing for network capacity with other users, which means that it can change over time. Worse yet, RTTs can vary dramatically: the RTT from my house in Palo Alto to the nearest Cloudflare server is about 10ms. The best-case RTT from Australia to the US is around 150ms (300,000 km/s is not just a good idea, it's the law). If you pick a single value for your retransmit timer, you're going to have seriously suboptimal performance on many networks.
The way that transport protocols handle this is to measure the round trip time during the connection by looking at how long it takes the other side to send an ACK. For instance, if you sent packet 10 at T=2000ms and you get an ACK for it at T=2050ms, then the estimated RTT is 50ms. Each time you get an ACK, you update the RTT estimate. The typical approach is to maintain a smoothed estimate (effectively a weighted moving average) of the recent measurements to average out the noise in each individual measurement while also favoring more recent measurements. Of course, you don't have any measurements at the time you start transmitting, so the typical approach is to use a somewhat conservative starting point (QUIC uses 333/ms), but obviously if the path between you and the other side has a low RTT, you want to update that as soon as possible.
Set-Up And Tear-down #
So far I've just covered the steady-state case where the sender is already magically communicating with the receiver, but in practice, but how do we get into this state, and how do we stop?
Set-up #
In most transport protocols, there's some kind of initial setup handshake before data is transmitted. For instance, here's what TCP's handshake looks like:
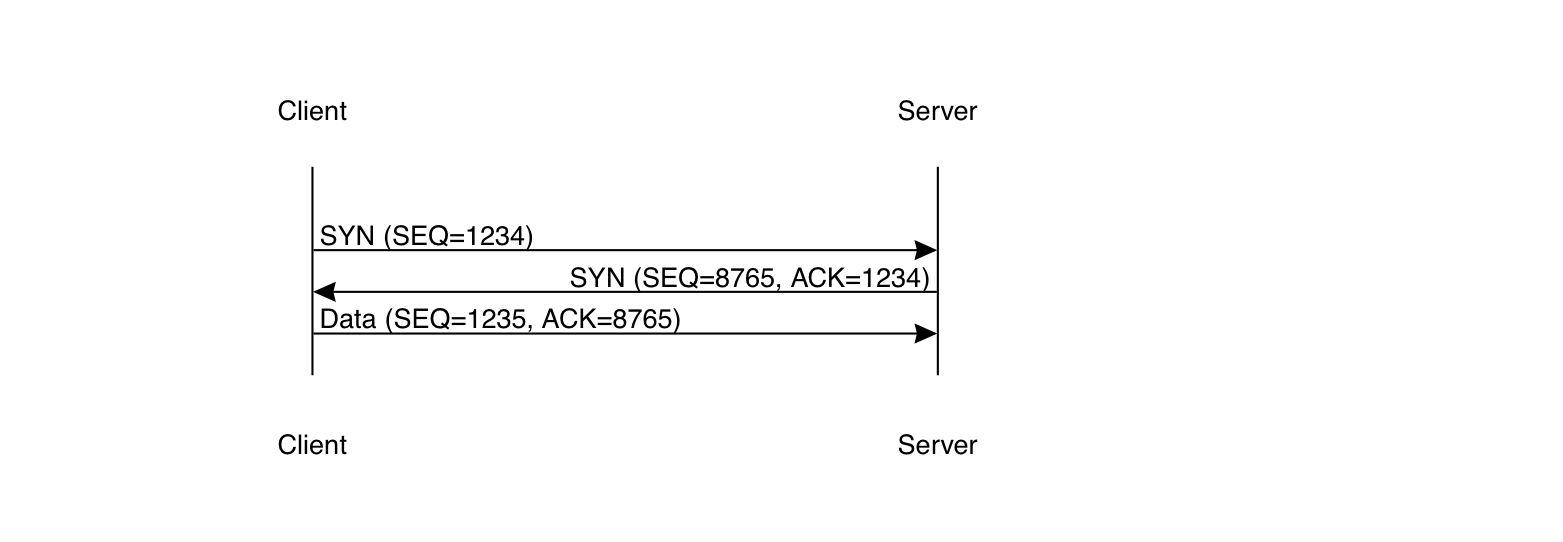
As I said above, TCP doesn't number packets, but instead labels each byte with a sequence number. So, what's going on here is that the client sends an empty SYN (for synchronize) packet with sequence number 1234. The server acknowledges it with its own SYN packet with sequence number 8765), and if it wants can send data to the client at this point (though this isn't the usual thing). Upon receiving the server's SYN, the client can also send traffic, starting with sequence number 1235. In the same packet, it acknowledges the server's SYN. Why is this necessary, though? Why not just start sending? And why not just start the sequence number at 1 (or, as C programmers would expect, at 0)?
The problem here is that it's possible for there to be two separate connections between client and server. Suppose, for instance, that a client initiates a connection and sends some data over it, and then ends it and starts a new connection, as in the diagram below.
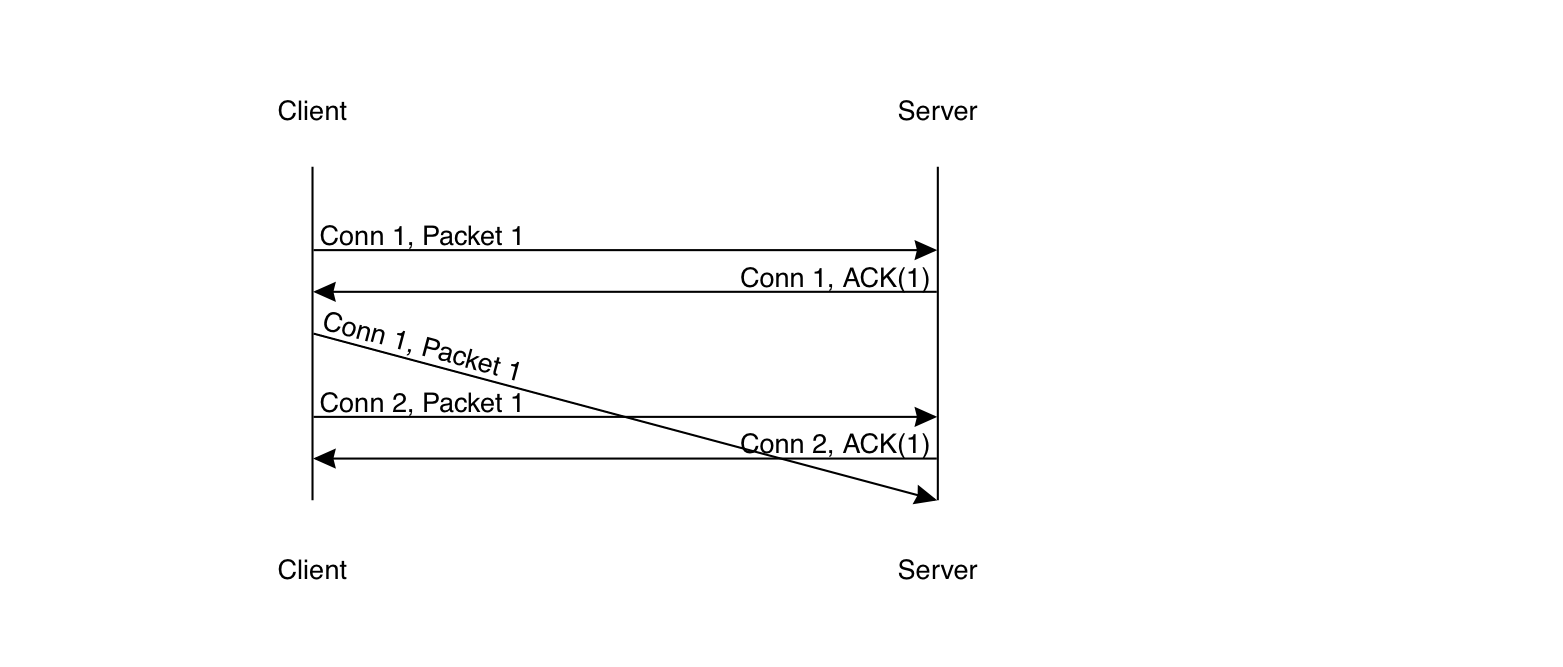
If a packet from connection 1 is delayed on the network for a long period of time, it may be received by the server after connection 2 starts and accepted as part of that connection. Disaster! The way TCP handles this is by having the new connection start with a sequence number which is intended not to overlap with valid sequence numbers from the previous connection. Sequence number selection is actually a somewhat complicated topic that I won't get into here, The 3-way handshake is needed to ensure that the client and the server agree on the initial sequence numbers for the connection. Otherwise, you could have a situation where the server was acting based on a delayed SYN from a previous connection, leading to problems (I'll spare you the details of the pathological cases).
The problem with the 3-way handshake in TCP[5] is that the client has to absorb a full round trip before it can send anything, which is a real performance cost. This wasn't really seen as a big deal when TCP was first designed, but as Internet speeds have increased generally and latency has become a big deal, it's become much more important. It's possible to send data on the first packet as long as you can guarantee that the server can distinguish this connection from others. For instance, QUIC does this by having the client choose a long (minimum 64 bits) random connection ID value, which distinguishes this connection from all other connections (I'm simplifying here, as the QUIC connection ID logic is also quite complicated), thus allowing the server to know that this is a new connection and not a replay. There's still a setup handshake, but the client and server are able to send during it, which saves round trips. I plan to cover the complexities of getting this right later, but wanted to mention it here for context.
Tear-Down #
What happens when the endpoints are finished communicating? In principle, they can just stop sending, but then what? The problem here is that both sides have to keep state: in order to be able to process Alice's packets, Bob needs to remember the last packet she processed so that she knows whether a received packet is a replay (to be discarded) or new data (to be processed). This takes up memory and eventually Bob is going to want to clean up. But how does Bob know when Alice is really done and so it's safe to clean up versus Alice just went quiet for a while?
The obvious thing to do here is to have an in-band signal that says that the connection is closing. This signal would itself be acknowledged, so it would be delivered reliably. This is what TCP does, but experience with newer protocols such as QUIC has shown that this is not always the best approach. This is another topic I plan to cover in a future post.
Common Themes #
Aside from the technical details, you should be noticing a few high level themes.
First, the design of these protocols doesn't really depend on any information about the internals of the network. It could be built out of copper wire, optical fiber, microwave links, two tin cans and a string, or all of the above. Similarly, you don't need to know how fast any individual link is, how big the buffers are in the routers along the path, etc. From the perspective of the transport protocol, the Internet is just this opaque system where you put packets in one side and they come out the other end. So, when we measure the RTT, for instance, we're just measuring the aggregate RTT of the system as a whole.
Second, none of this needs any cooperation from the elements in the middle. This means that (1) it's robust against any technical changes in the network and (2) you can make changes to the transport protocol without first having to change those elements. These are key properties for deployability: the Internet takes a really long time to evolve, and if we needed to change every element between point A and point B before we could use a new transport protocol on that path, we'd be waiting a very long time.
Finally, we constantly have to think about what happens if the network misbehaves in some way, for instance by dropping our packets or delivering them way out of order. A properly designed transport protocol has to be robust to all reasonable kinds of network misbehavior—the bar for what this means has gone up over the years to include active attack—and operate properly, or at least fail safely. This is just the price of trying to build a reliable system out of unreliable components.
Next Up: Congestion Management #
What we have so far is basically a simplified version of what TCP was like in 1986, when the Internet link between Lawrence Berkeley Labs (LBL) and UC Berkeley (about 400 yards apart) abruptly suffered what's come to be known as "congestion collapse", in which flaws in the TCP retransmission algorithms caused the effective throughput of the link to drop by a factor of about 1000. In the next post, I'll be talking about congestion collapse and how to avoid it.
The term sockets goes back to the original BSD sockets programming interface which was commonly used on early Internet systems and is now nearly universal. ↩︎
Ironically, in the modern phone network, it's fairly likely that we're carrying the data over some packet-based transport, very often IP. ↩︎
Yes, I know that in practice it's common to actually download smaller chunks of the video. ↩︎
Note that it's usual not to acknowledge ACKs, otherwise you get into a situation where the sides are just ping-ponging ACKs at each other. ↩︎
TCP does have a new mode called TCP Fast Open which allows sending immediately, but this is comparatively modern and there are a number of deployment challenges. ↩︎