DNS Security, Part IV: Transport security for DNS (DoT, DoH, DoQ)
Posted by ekr on 05 Jan 2022
This is Part IV of my series on DNS Security (parts I, II, III). In this part I cover transport security for DNS.
For years most of the DNS security effort went into DNSSEC, which provides authenticity for DNS data by signing the DNS records themselves. This left two big gaps. First, DNSSEC has seen fairly low levels of deployment, leaving the majority of DNS resolutions unprotected and most of the resolutions which benefit from DNSSEC only do so as far as the recursive resolver. Second, DNSSEC doesn't provide confidentiality, so DNS query data, which is naturally extremely sensitive, is wholly unprotected. In this post I go into the various technologies to address these gaps.
Disclaimer: I was (am) heavily involved in the design and deployment of the Firefox DNS over HTTPS (DoH) deployment. The opinions below are mine and not Mozilla's.
Overall Situation #
Recall the DNS resolution process from Part I, shown below:
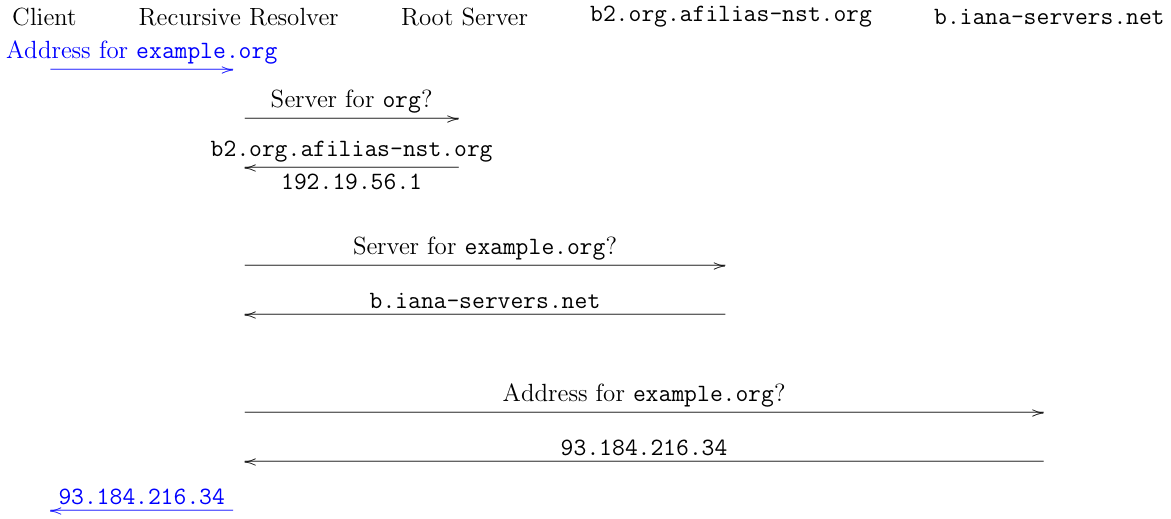
It's easiest to think of this as just consisting of four independent sets of transactions:
- Client to recursive
- Recursive to root
- Recursive to
b2.org.afilias-nst.org - Recursive to
b.iana-servers.net
Each of these transactions is a request/response exchange, typically done over UDP, but sometimes over TCP.
If you want to protect this system, a natural thing to do is just to encrypt each transaction, resulting in a set of encrypted links to and from the recursive resolver. This isn't a complete solution because the recursive resolver learns what queries you are performing and unless you also do DNSSEC validation at the client, the recursive resolver can simply lie to you when it sends you its results. However, it's also a significant improvement in security and privacy because it protects the user from attacks outside the recursive resolver. Moreover, we already have plenty of experience with protecting this kind of data (just run it over TLS, or in the case of UDP, perhaps DTLS) and so it's—at least in theory—technically straightforward. In practice, however it turns out not to be so, though for reasons that aren't really about the protocol itself.
In this post, we'll focus on the (by comparison) easier problem of protecting the client-to-recursive transaction, colored blue in the diagram above. While this is a fast evolving area, there are a number of large-scale deployments of encryption of this link. The problem of recursive-to-authoritative is essentially unsolved and is the topic of a separate post. For now, you can just assume that link is in the clear.
Server Authentication #
The basic problem here is authentication. Forming an encrypted connection is relatively easy—especially if you have a pre-made protocol like TLS[1] to start with—but if you want security against an on-path attacker then you need to authenticate the server; otherwise the attacker can just impersonate the server and capture your queries. If they forward the queries to the server themselves and the responses back (in a so-called "man-in-the-middle attack") then this will be invisible to the client. It's generally not necessary to authenticate the client to the server because the server's response doesn't depend on the client's identity.[2] In order to prevent this kind of attack, the client must know (1) that the server supports encrypted transport and (2) the expected identity of the server. We discuss these both below.
Note: there are three major protocols being used for secure DNS transport: DNS over TLS (DoT), DNS over HTTPS (DoH), and DNS over QUIC (DoQ). While there are important technical differences, they are irrelevant for most of the discussion below and it's conventional to refer to them collectively as DoX and to refer to old unencrypted DNS as Do53.[3]
Securing the Stub-to-Recursive Link #
As described in Part I, endpoints typically learn about the resolver via the network, which provides them with an IP address for the resolver. This is a perfectly good identity and it's possible to securely connect to that IP address as the WebPKI supports IP addresses in certificates, but that doesn't actually help very much, for two reasons.
First, there's no way to know that the server actually supports encrypted transport. You can configure the client to just try encrypted transport and fall back to unencrypted transport if that fails, but that means that any on-path attacker can just simulate failure (e.g., by sending a TCP reset (RST)) and force you back to unencrypted transport. Second, if the attacker is on your local network, however, they can often interfere with that discovery process and substitute their own resolver, in which case you form an encrypted connection to the attacker, which isn't very useful.[4]
When the IETF originally standardized secure transports for DNS—and specifically for stub to recursive—they defined the protocols themselves but mostly punted on this problem. Here's what RFC 7858, defining DNS over TLS (DoT) has to say:
This protocol provides flexibility to accommodate several different use cases. This document defines two usage profiles: (1) opportunistic privacy and (2) out-of-band key-pinned authentication that can be used to obtain stronger privacy guarantees if the client has a trusted relationship with a DNS server supporting TLS. Additional methods of authentication will be defined in a forthcoming document [TLS-DTLS-PROFILES].
This is IETF language for "we don't have a good solution to this problem, so we're going to give you some not very good options". However, when people went to actually do large-scale deployments, they had to actually do something. So far, we are seeing two main models evolve.
Same Provider Auto-Upgrade (SPAU) #
The first model, used by Chrome and Windows, is what's called Same Provider Auto-Upgrade (SPAU). The basic idea is that the client (either the browser or the OS) has a list of which recursive resolvers support secure transport. If the IP address of the configured resolver is on that list, then the client attempts to use secure transport;[5] otherwise it just uses regular insecure DNS.
This design has two nice properties. First, it lets you quickly upgrade a lot of people because there is a fair amount of concentration in the resolver ecosystem. For instance about 15% of people use Google Public DNS, though not all of them will actually get upgraded, for reasons we'll see below. Second, it doesn't interfere with people's existing configurations: for instance if they use an enterprise resolver that does filtering or split horizon then they'll just continue using it without change. As we'll see, the converse property is a challenge with other models such as Trusted Recursive Resolver (TRR).
The main disadvantage of this design is that the level of security it offers is quite limited because when (as usual) the client learns about the resolver from the local network. If that local network is malicious—or there is an attacker on it—then they can just redirect you to their own resolver and this design provides no security at all. Where it does provide security is when your local network is secure (e.g., a home network) but the uplink to the recursive resolver may be insecure. But if you don't trust the local network (e.g., you're in an airport or a coffee shop) then SPAU doesn't provide much additional security or privacy.
There are also several practical deployment problems. First, even if the real recursive resolver you are using supports secure transport, it's quite common for people's local networks to have some sort of DNS resolver endpoint in the WiFi gateway or customer access router (the technical term here is customer premises equipment (CPE)), in which case even if the upstream resolver supports secure transport, you won't get it until the CPE upgrades (which does not happen often). I've seen estimates that in some countries over 80% of people have this kind of configuration. Second, this design requires the software vendor to keep a list of recursive resolvers that support secure transport, which doesn't scale well. This mode is on by default in Chrome.
Trusted Recursive Resolver (TRR) #
Firefox uses a different model, called a Trusted Recursive Resolver (TRR). The idea here is that instead of accepting the resolver provided by the network, Firefox has a list of resolvers which have agreed to comply with strong privacy and transparency requirements. These include very short data retention periods and strict limits on how the data can be used. When possible, Firefox will automatically select one of those resolvers and securely connect to it.
This design has two main advantages when compared to SPAU. First, it works even if the local resolver is insecure or untrustworthy (e.g., in a coffee shop) because the browser picks a "known good" resolver. Second, it provides encryption even if the local resolver doesn't. However, because a TRR model often bypasses the local resolver, this creates a number of challenges, as detailed below.
Information Leakage #
There is an inherent privacy tradeoff in changing from the network's resolver to a separate resolver because the network already has a fair bit of information about your activity from observing the rest of your traffic. Specifically, the network already gets to see the IP addresses you are connecting to, which often only reflect a single site (e.g., Facebook). Even in cases where there are a lot of sites on the same IP address pool (as with some CDNs), the TLS handshake can reveal the expected server through the Server Name Indication (SNI) field[6]. Finally, it's possible to learn about which Web site people are going to via traffic analysis of the connection.
Adding a third party resolver creates a second entity besides the network which knows about your browsing history, which creates some additional risk, even if that entity has good policies. On the other hand, these alternate mechanisms of learning about browsing history are less efficient than just collecting DNS query logs, and there is active work on closing most of these holes, so this reduces your exposure to the network at the cost of increasing your exposure to the TRR. However, unlike your local network, the TRRs are required to have strong privacy policies; by contrast, it is known that many local networks do not. Nevertheless, this isn't an ideal situation and one that is potentially addressable via proxying as discussed below.
Local Policy #
DNS is often used to apply various kinds of local—or national—policies, for instance filtering adult content, logging user behavior (e.g., for law enforcement), or providing special "internal" domain names which aren't publicly resolvable. For obvious reasons, if the client selects a different resolver from that offered by the network, that resolver may adopt different policies
The difficult problem here is that it's hard to distinguish between situations where the user wants some sort of special policy treatment (e.g., blocking potentially malicious sites) and ones where the user doesn't but the network operator does (e.g., filtering out adult content). From a technical perspective, these both look like interference/attack by the network. Part of the value of securing DNS lookups is to protect against network attacks, and so a naive TRR deployment simply bypasses these policies, even if they were what the user wanted. Firefox in particular has some mechanisms to minimize this kind of impact, as discussed below.
Server Topology #
Most big server operators and CDNs have multiple points of presence at different places in the network. These all have the same name but different IP addresses. Because an ISP resolver knows the actual location of the client in the network topology, if it also knows something about the server's network, it can provide a server that is topologically closer to the client, theoretically providing better performance or making more efficient use of the ISP's network. However, if the client uses a centralized recursive resolver—or even one which doesn't know the ISP's topology—then this kind if optimization may not be possible.
This issue was a big concern when Firefox originally deployed the TRR model, but measurements suggest that in fact there is no real negative impact on performance from using a trusted recursive resolver. It may still be possible that there is an impact on network efficiency; but this is more of an issue for the ISP than for users.
The way that Firefox currently addresses this is to allow local networks to "steer" queries to specific TRRs. The idea here is that the local network might operate a TRR or have an arrangement with one which they share topology information with and so would prefer that clients use that. Currently, Comcast operates such a TRR and Firefox uses a DNS-based technique to determine whether such a resolver is available/preferred. Note that this doesn't allow the network to pick any resolver, just to select between TRRs. I discuss a more generalized solution below.
National Boundaries #
As Mozilla was first looking at launching Firefox with its TRR program, feedback from users indicated that many wanted to have a TRR that was in their jurisdiction (or, for many in Europe, a resolver in the EU). Another issue is that policymakers in some countries were concerned that resolvers would not comply with local regulations. Because of these concerns, Firefox has been somewhat cautious with its encrypted DNS rollout, and currently only has it on by default in North America, using Cloudflare in the US and CIRA in Canada. As of this writing, work is underway on expanding the program, though no specific plans have been announced.
Firefox Heuristics #
For the reasons discussed above, if Firefox just enabled DoX for everyone, this would cause problems for people's deployments. In order to address, this, Firefox uses a set of heuristics designed to address three important cases.
-
Enterprise-managed devices. In many cases, an enterprise will manage a user device and install their own DNS server or make other configuration changes. If Firefox detects this, it assumes that the enterprise won't want to use a TRR and disables DoH (though the enterprise can explicitly turn it on).
-
Parental controls. Some ISPs offer "parental controls" services which use the DNS to filter out adult content (with the consent of the parents if not the children). Firefox tries to detect this by checking to see if certain "canary" domains (domains which don't actually correspond to adult content but are used to test filtering) are blocked and if so, disabled DoH.
-
Local domains/Blocking. Some networks will serve domains that only resolve inside their own corporate network. If Firefox uses a TRR, then these domains fail. Firefox addresses this by falling back to Do53 if a domain is not found or if DoH just generally fails.
These heuristics are imperfect in two ways. First, they do not detect some cases where the user or device administrator might want DoH disabled. One important case is enterprise-owned devices where the operator doesn't remotely manage them. Unfortunately, there is no good way to detect this because any signal that is sent by the network could have been sent by an attacker. This is why Firefox requires evidence that the device is being managed before disabling DoH.
Second, they sometimes disable DoH when they shouldn't. In particular, networks can block the canary—or just block DoH generally—and cause Firefox to use Do53. This allows the network to disable encryption, which is obviously contrary to the goal of protecting the user from the network. For the moment, Mozilla has been treating this as a necessary compromise, but is monitoring the rate at which it happens and in future may make it more obvious to the user when DoH has been disabled and allow them to require secure resolution.
Local Network Discovery #
One important feature of the DoX deployments by Firefox, Chrome, and Windows is that they were something that clients could do on their own without any cooperation from the network. The reason for this is simply that it was the only way to get significant incremental deployment of a solution that addressed a real threat to user privacy. However, a number of network operators—and some governments—objected that they were losing their ability to control their networks. The result was months of of extraordinarily contentious debate, both in the IETF and in the press.
At the same time, it was clear that neither the existing SPAU nor TRR approaches were ideal, even from the perspective of the browser/OS vendors:
-
SPAU-style approaches required a centralized list of secure transport-compatible resolvers and had no way of detecting that the local network actually had such a resolver.
-
TRR-style approaches just bypassed the network resolver even in cases where it might be usable (e.g., in cases where that resolver was a TRR).
After months of loud discussion, the IETF decided to charter the Adaptive DNS Discovery (ADD) Working Group to work on mechanisms to allow the client to discover resolvers and their properties without saying anything about what they would do when they found them.[7] In principle, such a solution could be used to feed into either an SPAU solution (by saying that the local network supports an encrypted resolver) or a TRR solution (by saying that it preferred one or more TRRs), without requiring vendors to change their basic policies, even if network operators wish they would.
There's nothing particularly surprising about the approaches that the ADD WG has come up with. Roughly speaking, they allow the network to indicate (either via DHCP or via a DNS query) that an encrypted resolver is available. When the indication is over DNS, the encrypted resolver has to have a WebPKI certificate for the IP that the client would ordinarily use for Do53 resolution, although it can actually operate on a different IP address.[8] This is a very important requirement because it prevents an attacker from advertising a totally unaffiliated encrypted resolver that just steals your queries. Unfortunately, it is also extremely limiting: It's very common for home network routers/WiFI APs, etc. to have a DNS proxy which takes DNS queries and forwards them to the ISP resolver. This proxy will usually have an unroutable IP address[9] which it's not possible to get a certificate for, in which case the existing ADD solutions won't work for SPAU-type designs (they work fine for TRR-style designs). There is active work on trying to address this use case, but not consensus on an approach or even that one is feasible. With the DHCP-based system, you can use a standard domain name—because DHCP is where you learn about the resolver in the first place—but this still won't work well if the actual resolver is just some local router because it probably won't have a globally resolvable name. [Updated 2022-01-17. Thanks to Neil Cook for pointing out that the original text just covered the DNS version.].
Transport Protocols #
We've gotten quite far without talking about the details of the various protocols, but now it's time. There are three major secure transport protocols which have been or are being standardized[10] for DNS:
-
DNS over TLS (DoT). This is what you would expect, namely you open a TLS channel to the server and send DNS queries over it. There is also a DNS over DTLS, but that has gotten almost no usage and will probably be deprecated.
-
DNS over HTTPS (DoH). This maps DNS queries onto HTTP request responses and runs them over HTTP over TLS.
-
DNS over QUIC (DoQ). This sets up a connection over the QUIC secure transport protocol and sends DNS queries over it. Note that you can also run HTTP over QUIC (HTTP/3), so it's possible to do DoH over QUIC (DoHQ?) but this is something clients can do automatically without any new standards work, because from the perspective of standards, it's just HTTP.
Conceptually these are all very similar and indeed, it's not really clear why one needs both DoT and DoH (DoQ has better performance properties, as would DoHQ). DoT was designed before DoH—though unfinished when work on DoH started—but DoH has become more popular, largely because browsers such as Chrome and Firefox chose to deploy DoH rather than DoT (a decision made at least in part because browser vendors are comfortable with HTTP). On the other hand, DoT was designed primarily by the DNS community and is more popular there.
There has been a lot of criticism of DoH from operators who are concerned about the use of DNS transport for bypassing their network-based controls (Paul Vixie has been particularly vocal on this topic). The primary relevant technical difference from the perspective of a network operator is that DoT contains two pieces of protocol metadata that make it easier to distinguish from other kinds of TLS traffic: it typically runs over port 853 (rather than 443 as for HTTP over TLS) and has an Application Layer Protocol Negotiation (ALPN) identifier of "dot" rather than "h2". By contrast, DoH traffic just looks like HTTP traffic. The result is that it's somewhat easier to have your network block DoT traffic. However, it's not clear how long this will be true if there is a lot of blocking. The DoH servers currently commonly used by clients are also identifiable by IP and SNI so they're relatively easy to block, and if server operators want to conceal DoT, they can run it on port 443 and use ECH to conceal the ALPN. Fundamentally, these are policy not technical questions.
Security and Privacy Properties #
Whatever the transport protocol, at the end of the day what DoX is designed to give you is a secure channel to the resolver so you know that:
- Nobody but the resolver is seeing your query to the resolver.
- You are getting the result that the resolver is sending you.
How valuable this is depends in part on how much you trust the resolver: a secure channel to the resolver in your local coffee shop doesn't do you much good because you have no reason to trust that that resolver isn't lying or publishing your queries (this is a lot of the rationale for Mozilla's TRR design).
Even if you are connected to a resolver you trust, the level of security and privacy you get is limited by that resolver, especially if it's queries aren't encrypted, which seems quite likely (again, see a future post). First, if that resolver isn't validating DNSSEC (or you are trying to resolve one of the majority of domains which aren't DNSSEC-signed) then a network attacker might forge responses to that resolver, which will happily pass them on. Second, an attacker who is able to observe queries by the recursive resolver may be able to infer which of them are yours by looking at timing. This form of attack is somewhat limited by the fact that recursive resolvers cache responses and so won't necessarily issue new queries to authoritative resolvers for every query, but it will probably issue some of them. It's also possible to do traffic analysis on the encrypted query stream from your machine to the recursive resolver itself based on packet size and timing.
Oblivious DoH #
Even if you are connected to a known and trusted resolver, it's still not ideal that that resolver gets to see all of your queries as well as your IP address. One way to address this is to proxy your encrypted DNS queries through a proxy which conceals your IP address from the DNS server. That way, your queries and IP address are never in the same place. Apple is already doing this with Oblivious DoH and the IETF is standardizing a system called Oblivious HTTP which can be used to proxy DoH traffic (there is no equivalent for DoT).
DoX and DNSSEC #
If your problem statement is "how do we secure the DNS", then you might think of DoX and DNSSEC as competitors, and to some extent this is true: resources being spent on DoH—and in this case it is DoH and not DoT—in endpoints are not being spent on endpoint DNSSEC. Moreover, because local networks are a powerful point of attack and so a secure channel to a trusted resolver reduces the need for DNSSEC validation. In addition, to some extent DoX reduces the need for endpoint DNSSEC verification because it allows endpoints to take advantage of DNSSEC verification in the recursive resolver (assuming they trust it).
However, from another perspective, DNSSEC and DoX are complementary: DoX does something that DNSSEC does not, which is to provide confidentiality. Even if every client did DNSSEC validation, DoX would still serve an important privacy purpose; I certainly don't see clients implementing DNSSEC validation and then deciding to turn off DoX, especially given that it provides important security for the vast majority of domains which are not currently DNSSEC-signed. On the other hand, DNSSEC does something DoX does not, which is to provide end-to-end integrity.
Second, DoX is actually an enabling technology for DNSSEC: one of the big concerns about DNSSEC deployment is that network intermediaries will not convey DNSSEC records directly, thus creating false positive failures when DNSSEC validation fails. However, any resolver which speaks DoX is quite likely to also handle DNSSEC correctly—this can be guaranteed in a TRR system—and thus DoX has the potential to make the risk of deploying endpoint DNSSEC lower and thus perhaps modestly increase the chance of it happening.
Next Up: Recursive to Authoritative #
So far I've really focused on the endpoint perspective, but of course DNS resolution actually involves much more than the stub to recursive link. In the next post I'll address the difficult problems of encrypting the link between the recursive and authoritative servers.
Appendix: How DDR Works #
The IETF has proposed two main protocols for discovery of encrypted resolvers Discovery of Designated Resolvers (DDR), which is DNS-based and DHCP and Router Advertisement Options for the Discovery of Network-designated Resolvers (DNR), which uses the same mechanisms that clients use to autoconfigure themselves for a given network. From my perspective, DDR is the more interesting one because it (sometimes) works without changing customer premises equipment, a process which takes a long time.
The basic setting here is one in which the ISP has both a traditional Do53 resolver and an encrypted resolver (of any flavor, whether DoH, DoT, etc.). However, they don't control the customer premises equipment, which means that they can't change the DCHP or IPv6 RA-type configuration provided by that equipment. The way around this is that the client asks the resolver whether it has an encrypted version. The basic flow looks like this:

When the client joins the network, it is provided with
the IP address of the Do53 server in a DHCP option (this assumes
DHCP). This is just the normal situation without DoX.
Next, the client makes a request to the Do53 server for
a special domain (resolver.arpa). The Do53
server responds with the address of the DoX resolver
and the client can then connect to it. There are two
important points to note here.
First, the identity that the client expects the DoX server to present is the IP address that it was configured with via DHCP. Recall that the threat model here is that the attacker is able to interfere with your connection to the Do53 server—otherwise you wouldn't need encryption—and so you can't trust the new IP address you get from it. This way at worst you end up encrypting to someone who controls the IP address you were going to send your Do53 traffic to anyway. Second, this explains why DDR doesn't work if the CPE has a DNS proxy: in that case you will get the IP address of that proxy and therefore the ISP's DoX server won't have a valid certificate to use to authenticate as that server.
As should be clear from the above, DDR is mostly useful for SPAU models, but you can also use it for steering in a TRR system.
Though actually designing such a protocol is not easy. A topic for another day. ↩︎
One exception here is outsourced cloud-based "enterprise" DNS offerings like OpenDNS (now called Umbrella) which but may want to authenticate that users are actually employees before providing answers. ↩︎
Because it runs on UDP and TCP port 53. ↩︎
There are situations in which someone manually configures the resolver address for instance to bypass the network resolver, but they are comparatively infrequent. ↩︎
I'm not sure if the clients hard fail if they can't successfully connect, but in principle you could. ↩︎
Though the TLS working group is hard at work on fixing this. ↩︎
This is a pretty typical IETF "mechanism not policy" type of compromise. ↩︎
I know this feels counterintuitive, but it's actually the way that HTTPS works now. If I go to
www.example.comand there is a CNAME towww.cdn.example, the client checks the certificate forwww.example.com. The reasoning here is that the original identity is what the client wanted and the redirect is just some behavior by an untrusted network. ↩︎These are drawn out of blocks designed for local use, such as those defined by RFC 1918. The key point is that these addresses will be shared and therefore cannot get certificates. ↩︎
There are also two non-standard protocols in use, DNSCrypt and DNSCurve but for various reasons, the IETF opted to start with its existing secure transports. ↩︎