Everything you never knew about NATs and wish you hadn't asked
In which I talk about NAT, but mostly dunk on IPv6
Posted by ekr on 03 Apr 2023
The Internet is a mess, and one of the biggest parts of that mess is Network Address Translation (NAT), a technique which allows multiple devices to share the same network address. In this series of posts, we'll be looking at NATs and NAT traversal. This post is on NATs and the next one will be on NAT traversal techniques.[1]
Background: IP addresses and IP address exhaustion #
You may recall from previous posts that the Internet is a packet switching network which works by routing self-contained messages (datagrams):
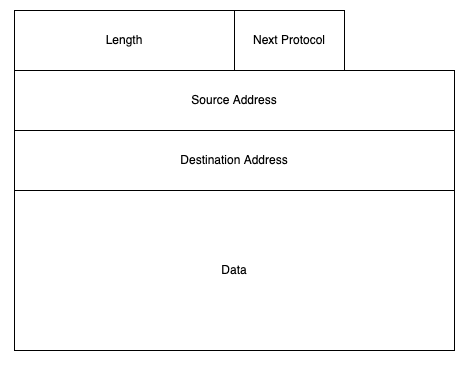
Writing IP Addresses #
IPv4 addresses are 32 bits, hence 4 bytes. It's conventional
to write them in what's called "dotted quad" format, which
consists of writing each byte value (from 0 to 255) separately,
followed by a dot. For instance, 10.0.0.1 corresponds to
the bytes 0x0a 0x00 0x00 0x01.
Because IPv6 addresses are so much longer, writing them
is unfortunately kind of a pain, and you end up with
goofy stuff like 2607:f8b0:4002:c03::64 (for google.com)
where the :: means that everything in between is a 0.
Each packet has a source and destination address, which are just numbers, and each device has its own address, which is how packets get sent (routed) to it and not to other devices. In the original version of the Internet Protocol (IP version 4 or just IPv4), these addresses were 32 bits long, which means that there are a total of 232 (about 4 billion) possible addresses. There are rather more than 4 billion people on the planet and many of them have more than one device, so it's not actually possible for each device to have a unique address.
This problem has been known about for more than 30 years, and the the Internet Engineering Task Force (IETF), which maintains most of the main networking protocols on the Internet, has an official fix, which is for everyone to upgrade to a new version of IP called IP version 6 (IPv6). IPv6 has 128 bit addresses, which, at least theoretically, means that there are plenty of addresses. Unfortunately, for reasons which are far too long—and depressing—to fit into this post, the transition to IPv6 has not gone well, with the result that over 25 years after IPv6 was first specified, significantly less than half of the Internet traffic is IPv6. The graph below shows Google's measurements of the fraction of its traffic that is IPv6, reflecting client-side deployment. Server-side deployment is also fairly bad, with ISOC reporting that about 44% of the top 1000 sites support IPv6.
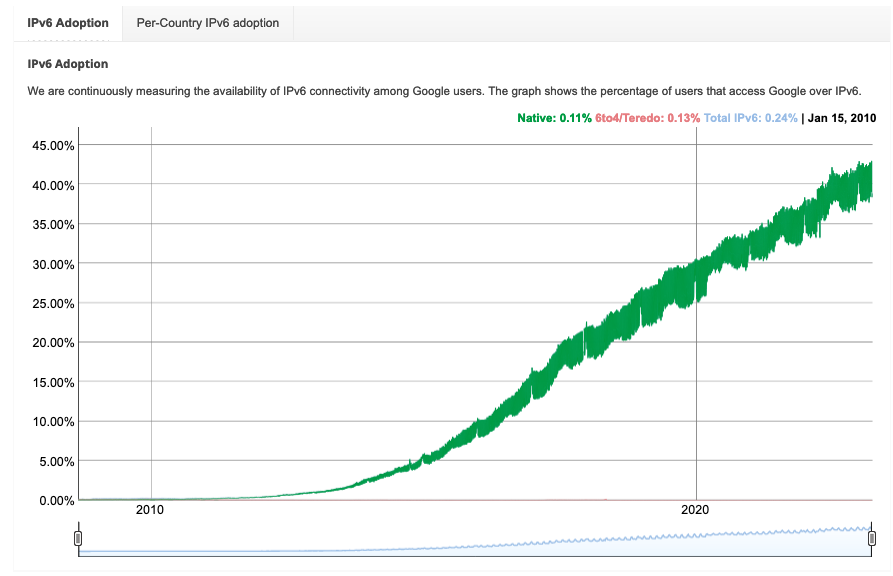
[Source: Google]
This is, needless to say, not good. As a comparison point, TLS 1.3 shipped in 2018 and at this point ISOC's numbers show 79% support among the top 1000 sites. At some level this is a slightly unfair comparison because transitioning to IPv6 means changing your network connection whereas transitioning to TLS 1.3 just requires updating your software, but in any case, we're nowhere near full IPv6 deployment, even though we no longer have enough IPv4 addresses. Actually, addresses have been scarce for quite some time, as shown in the timeline below:
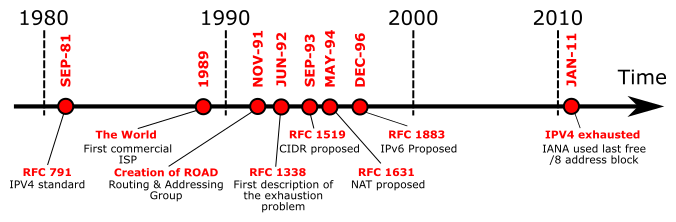
[Source: Michael Bakni via Wikipedia]
{kind=link}
IP addresses are centrally assigned, with the overall pool being managed by the Internet Assigned Numbers Authority (IANA) which provides them to Regional Internet Registries (RIRs), which then hand them out to network providers, on down to hosts.[2] IANA allocated its last block to the RIRs back in 2010, but addresses were already starting to get scarce before then. As you can see on the chart above, an immediate transition to IPv6 in which we just turn off IPv4 is implausible today but was out of the question in the early 2000s back when deployment was effectively zero. Another technical solution was needed, one that would be incrementally deployable rather than simultaneously replacing big chunks of the Internet (technical term: forklift upgrade). And the Internet delivered in the form of NAT.

Network Address Translation (NAT) #
The basic idea behind NAT is simple: you can have multiple machines share the same address as long as there is a way to demultiplex (i.e., separate out) traffic associated with one machine from traffic associated with another. Fortunately, such a mechanism already existed: ports.
Port Numbers #
Consider the case where you just have two computers, a client and a server, but where there are two simultaneous users on the client. This feels like an odd situation in 2023 when basically all computers are individual, but all of this stuff was designed back in an era when multiple users timesharing on the same computer was the norm. If both users want to connect to the same server, they will have the same IP address, so how does the server tell them apart?
The answer is to have another field, the port number, which is is just a 16-bit integer that can be used to distinguish multiple contexts on the same device (IP address). Port numbers have two main uses:
- on clients
- to distinguish multiple similar processes connecting to the same server.
- on servers
- to distinguish multiple different services. Conventionally, services will have specific assigned port numbers, such as 80 for HTTP, 443 for HTTPS, etc.
Port numbers don't exist at the IP layer but rather at the TCP or UDP layers, but virtually all the traffic we'll be talking about uses UDP or TCP, so that's usually not an issue.
NAT #
Port numbers allow two users on the same machine to share an IP address. The intuition behind NAT is that you can use the same mechanism to allow two machines to share an IP address, as long as you can ensure that they won't also try to use the same port.[3] The basic way to do this is by having the network gateway device (e.g., your WiFi router) do the work. The basic scenario is shown below:
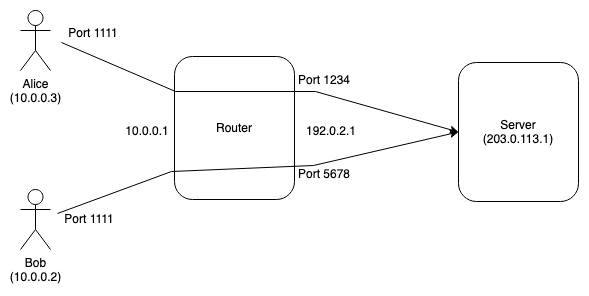
In this example, Alice and Bob are both on the same network
and have addresses 10.0.0.3 and 10.0.0.2 respectively.
The WiFi router has two addresses, one on the inside which
it uses to talk to Alice and Bob (10.0.0.1) and one
on the outside which it uses to talk to machines on the
Internet (192.0.2.1).
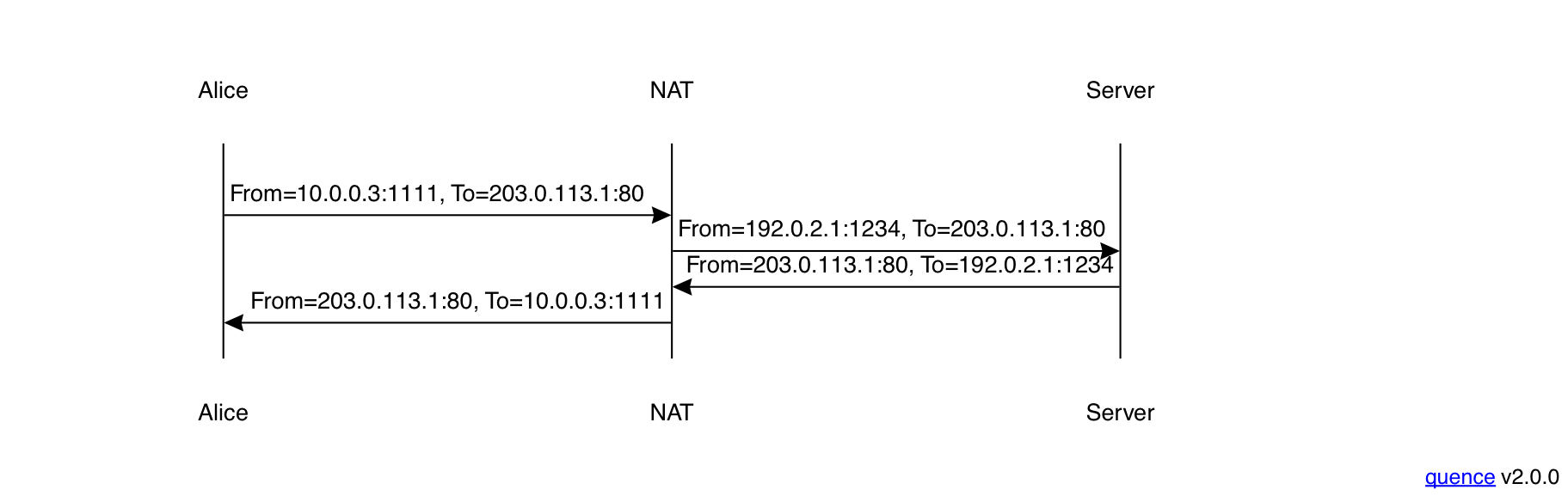
When Alice wants to talk to the server, she sends a packet
from her IP address and uses local port 1111 (this is
usually written 10.0.0.3:1111), as shown above. This packet gets sent
to the WiFi router, which rewrites the source address and port
to 192.0.2.1:1234 and sends it along to the server.
When the server responds, it sends the packet to
192.0.2.1:1234 (this is the only address that it knows),
which routes it back to the WiFi router. The router
duly rewrites the destination address to 10.0.0.3:1111
and sends it to Alice. The story is the same for Bob
(he even uses the same port number!)
except that the packets he sends are from
192.0.2.1:5678. In order to make this work, the router
needs to maintain a mapping table of which external
ports correspond to which internal machines. Each
entry in the table is called a "NAT binding"
and associates the external address and port to the internal
one.
From the server's perspective, this looks exactly the same
as if there were a single machine with address 192.0.2.1
talking to it; NAT is just something that happens unilaterally
on the client side. This is a very important feature because
it enables incremental deployment. A network that can't
get enough IP addresses can use NAT without any change
on the servers. Perhaps less obviously, it doesn't require
changing the clients either: they just use their
ordinary IP addresses and the NAT translates them.[4]
NAT isn't magic, of course, and it can't create IP addresses out of nowhere; what it does is stretch them by using the port number as an extension of the IPv4 address space. In fact, we used to joke about the IPv7 packet header, in which the IPv4 address fields were the "high order" bits of the address and the transport port fields were the "low order" bits:[5]
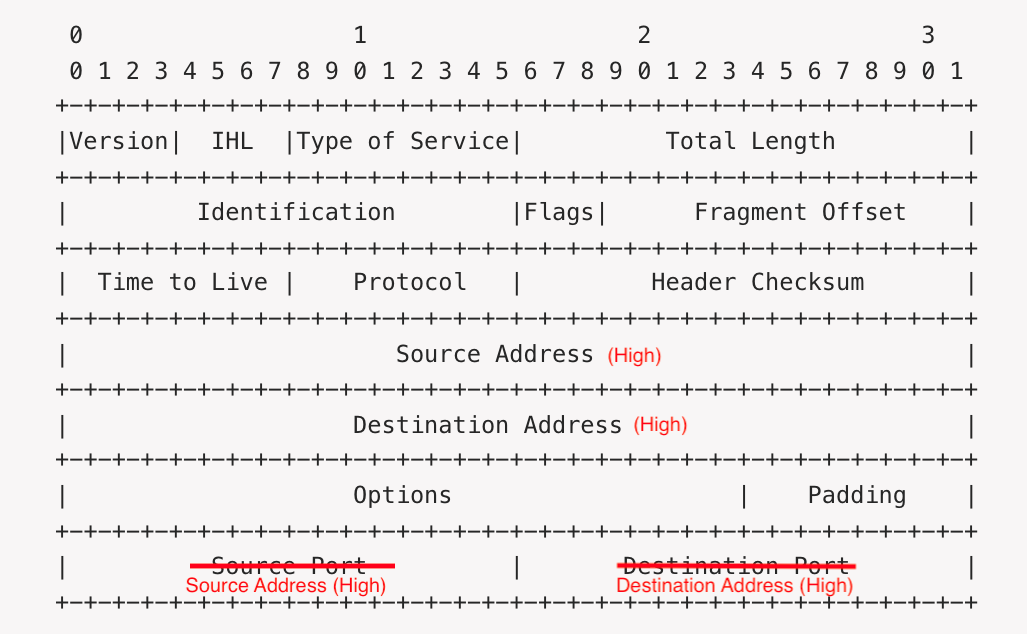
It's still possible to run out of ports on the NAT device
if it has enough clients behind it, but because
the NAT can use the same port to talk to two different server
at the same time (though this turns out to be bad news
for reasons we'll get into below) and there are around 65000 possible ports,
you need a lot of clients to want to concurrently
talk to the same server before this becomes a problem.
As a general matter, NATs will reuse ports once they
are no longer active, so that NAT bindings aren't
stable over time: port 1234 might be Alice now but
Bob in 20 minutes.
As a practical matter, you don't usually use NAT for servers,
at least not this way, though it's not technically impossible. In particular,
HTTP(S) URIs have a port number field, so you can
say (for instance) https://example.com:4444 to
indicate that the client should use port 4444 but this
just isn't common practice, partly because the result
is ugly and partly because there are other mechanisms
for sharing multiple servers on the same client, such
as TLS Server Name Indication (SNI).
RFC 1918 Addresses #
Of course, even if they are behind a NAT, each client still needs its own IP address, so how does this help? The answer is that these addresses don't need to be globally unique but just locally unique within a given network. This means that the local address of a machine on your network might be the same as one on my network, but they get translated to different addresses on the public Internet.
The IETF has reserved a number of address blocks for
"Private" usage in RFC 1918.
These addresses are never supposed to appear on the public
Internet and so it's safe to use them on your network,
as long as you translate them to a routable address
on the way out to the Internet. The example above
uses addresses from one such address block: 10.0.0.0/8, which
means "all the addresses with the 8-bit prefix 10, i.e.,
10.0.0.0 to 10.255.255.255 inclusive. This block
has around 16 million possible addresses in it, so you
can have a very large network behind a NAT.
Maintaining NAT Bindings #
Internally, a NAT needs to keep a mapping table that stores the bindings between internal and external addresses. In the example above, you would have a table something like:
| Internal Address | External Port |
|---|---|
| 10.0.0.3:1111 | 1234 |
| 10.0.0.2:1111 | 5678 |
Note that the external address is constant, so we don't need it in the table. Some larger NAT systems (see carrier-grade nat below) have multiple external IP addresses, but we don't need to worry about that right now.
When the NAT receives a packet on the outgoing interface, it needs to do a table lookup. If a binding already exists for the packet, then the NAT just uses the entry in the table. If no binding exists, it creates a table entry with an unused port and forwards the packet. In this example, I've described what's called an "address-independent" NAT in which you have a single binding for a given local address/port combination, no matter what the remote address is. There are also "address-dependent" NATs, which use a different binding. This will become relevant when we talk about NAT traversal in Part II.
When the NAT receives an incoming packet on the external interface, it also does a table lookup. If a table entry exists, it forwards the packet as expected, but if no entry exists then there's no way of knowing which host the packet is intended for; the sensible thing to do in this case is to just drop the packet. The result of this is that most consumer NATs only really support flows in which the machine behind the NAT speaks first to initiate the flow. This is usually conceptualized as an "outgoing-only" set of semantics and corresponds well to TCP connections, in which the client sends the first packet (a SYN). Indeed, some NATs rely on the TCP SYN to create bindings, and will just drop mid-connection TCP packets that correspond to unknown flows. This doesn't work with UDP so you just have to look at the first outgoing packet, ignoring whatever markings it has.
This "outbound connections only" semantic is often viewed as a security feature because it means that even if you have devices behind the NAT that have "open TCP ports", meaning that they listen on those ports for connections, external attackers may not be able to connect to them. This kind of device is surprisingly common, especially for things like printers or scanners which you want to be accessible to anyone on the local network, so a NAT is really providing a valuable function here. However, it's important to realize that unlike a firewall, which is explicitly designed to block certain kinds of connections, many NATs just do this as a sort of accidental side effect of their architecture—although others do so explicitly, as we'll see later—so it's not a guaranteed property that you should rely on.
Binding Lifetimes #
This brings us to the obvious question of when the NAT should delete bindings. Cleaning up old bindings is an important function because otherwise the NAT would quickly use up its available port space. There are a number of ways to manage this:
- Keep the binding open until the connection is torn down,
- either by a TCP FIN or a TCP RST. This doesn't work with many UDP-based protocols, which either don't have messages indicating connection closing (such as RTP) or where those messages are encrypted (such as QUIC or DTLS 1.3). This method also isn't sufficient even for TCP, because the client might have shut down without sending a FIN, for instance if it crashed or the user put their laptop to sleep.
- Use a timeout
- and tear down connections which are idle for too long. This guarantees that eventually the resources will be released, because if the client shuts down, it won't be sending packets. However, "too long" is just a heuristic. Network protocols are often designed so that if there is no data flowing they don't send any packet (TCP is this way), in which case you may just be tearing down a connection right as the client was about to send something. More modern protocols incorporate "keepalive" packets to keep the NAT bindings open, but remember that the idea here is that a NAT should work with protocols that were designed before the NAT was deployed, so this is not an ideal solution.
- Delete the least-recently-used connections
- once some maximum number of connections is reached and a new one needs to be allocated. This has many of the same problems as the timeout but is a slight improvement in some respects because it doesn't delete old connections unless the table is full.
It's of course also possible to use more than one of these mechanisms at once. For instance, you might look at the TCP control packets to drop TCP connections but use timers as a backup for client shutdown and for other protocols.
Non-TCP/UDP Protocols #
Of course, TCP and UDP are not the only protocols which it is possible to run on the Internet. The IP datagram's "next protocol" field is an 8-bit value and only about half of these are assigned so in principle it's possible to introduce new protocols that run directly over IP. In practice, however, NATs make this extremely problematic because the port field is not in the IP header but rather in the header of the protocol that sits above IP (e.g., TCP or UDP), which means that the NAT needs protocol-specific logic for each new protocol.
A good example here is SCTP, a TCP-like protocol that introduces a number of new features like multiplexing on the same connection. SCTP was intended to run over IP, just like TCP, and SCTP's header actually has the source and destination ports in the same location as TCP and UDP, as shown below:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port Number | Destination Port Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Verification Tag |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Firewalls #
The situation is actually much worse than I'm making it out here, because network security devices like firewalls are often configured to reject any traffic that they don't understand. Even if a new protocol magically worked with NATs without modification, it would be blocked by many firewalls.
You might think, then, that a NAT which just always rewrote whatever bytes were in location for the source/destination port fields for UDP or TCP would work fine with SCTP, but that's not correct. It's true that it would rewrite the fields, but that would just create another problem, because the SCTP packet also includes a checksum (the last field in the header shown above) which is computed over the entire packet and is designed to detect any change to the packet, including the port numbers. This means that any NAT which rewrites the source and destination port also needs to rewrite the checksum, otherwise the checksum verification will fail at the receiver and the packet will be discarded.[6] The SCTP checksum is in a different place than the TCP (or UDP checksum) and is computed using a different algorithm, so even if you just went ahead and used the TCP rewriting code—which isn't a good idea for other reasons—you'd just end up damaging some other part of the packet. The bottom line, then, is that it's not safe for NATs to just rewrite packets they don't understand (even though in some cases it might be safe), and instead NATs need to be modified in order to support each new protocol, which means that any such protocol starts out broken on a huge fraction of clients, making it very hard to get traction.
Fortunately there is a well-known solution to this problem, which is to run your new protocol over UDP. The UDP header is comparatively lightweight, consisting of 8 bytes, 4 of which are the host and port, which you'd need anyway. The other two are a two-byte length field, which you'd generally want and a kind of outdated checksum, which only takes up two bytes, so there's not that much overhead.
0 7 8 15 16 23 24 31
+--------+--------+--------+--------+
| Source | Destination |
| Port | Port |
+--------+--------+--------+--------+
| | |
| Length | Checksum |
+--------+--------+--------+--------+
If you run your protocol over UDP, then NATs will generally work mostly correctly—again with the caveat that the NAT doesn't know when a connection stops and starts—you start out from a position of things mostly working rather than them mostly failing (when QUIC was first rolled out, Google found that around 95% of connections succeeded.) Of course, 95% isn't 100%, and experience with new protocols such as QUIC and DTLS (with WebRTC) suggests that any new protocol will experience some blockage; in practice this means that you need to arrange some way to fall back to an older protocol such as HTTPS if your new UDP-based protocol fails. There are a number of possible approaches here, including trying both in parallel (a technique often called Happy Eyeballs), trying the new protocol first and seeing if it fails, or trying the old protocol first and then in the background trying the new protocol.
For this reason, the only really practical way to deploy new transport protocols on the Internet is over UDP,[7] and this is what recent protocols such as QUIC (running directly over UDP) or WebRTC data channels (SCTP running over DTLS running over UDP) do.[8] This principle was forcefully enunciated by voice over IP pioneer Jonathan Rosenberg (JDR) in an IETF session where someone was presenting a mechanism for running SCTP over NATs. JDR's response was something to the effect of:
There are some hard truths in the world and this is one of them. TCP and UDP are the new waist of the IP protocol stack.
In this context, "waist" refers to a famous analogy for the IP protocol suite illustrated by this image from a talk by IPv6 designer Steve Deering:
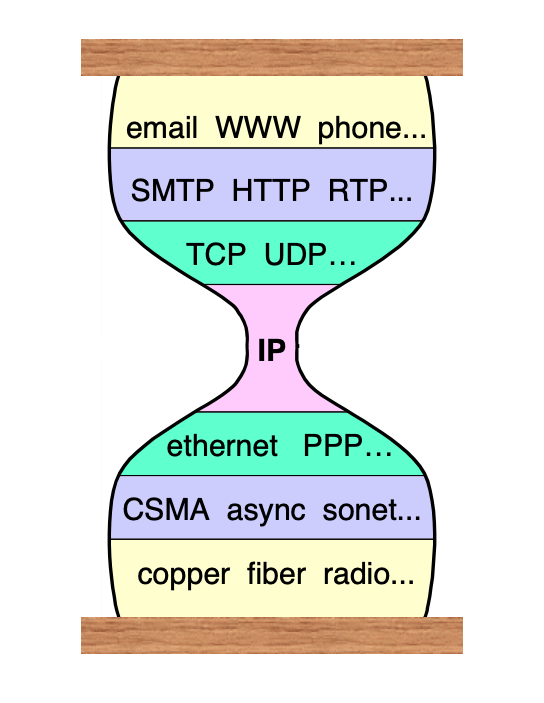
[Source: Steve Deering]
The idea is that IP can run on any kind of transport (radio, copper, whatever) and that you can run lots of protocols on top of it, but that IP is the common element hence the narrow "waist" of the hourglass. Rosenberg's point (which I agree with) is that this place is now occupied by UDP (and to a lesser extent TCP). Arguably, the situation is worse than this: it's so common to deploy new technologies over HTTP that I've seen arguments that HTTP is the new waist, but we're not there yet!
Application-Layer Gateways #
NAT works quite well for simple protocols which just consist of one connection (e.g., HTTP). However, there are some protocols which have a more complicated pattern. As an example, the File Transfer Protocol (FTP) is part of the original protocol suite and was widely used for downloading data prior to the dominance of the Web and HTTP. FTP had an unusual (to modern eyes) design which used two connections:
- A control channel
- which the client used to give instructions to the server.
- A data channel
- which was used to actually transmit data.
A download using FTP [edited from "UDP" — 2023-04-17] looks like the following:

The client would first connect to the FTP server and then issue instructions about what file to download. The server would then connect to the client (by default using the port number one lower than the one the client used, but the client can provide a port number) and send the file.
Of course, this won't necessarily work if you have a NAT, because the port number probably won't be right; even if the client uses the default, the NAT might not have two adjacent ports spare. Instead, the NAT would use what's called an application-layer gateway (ALG) and rewrite the client's request, like so:
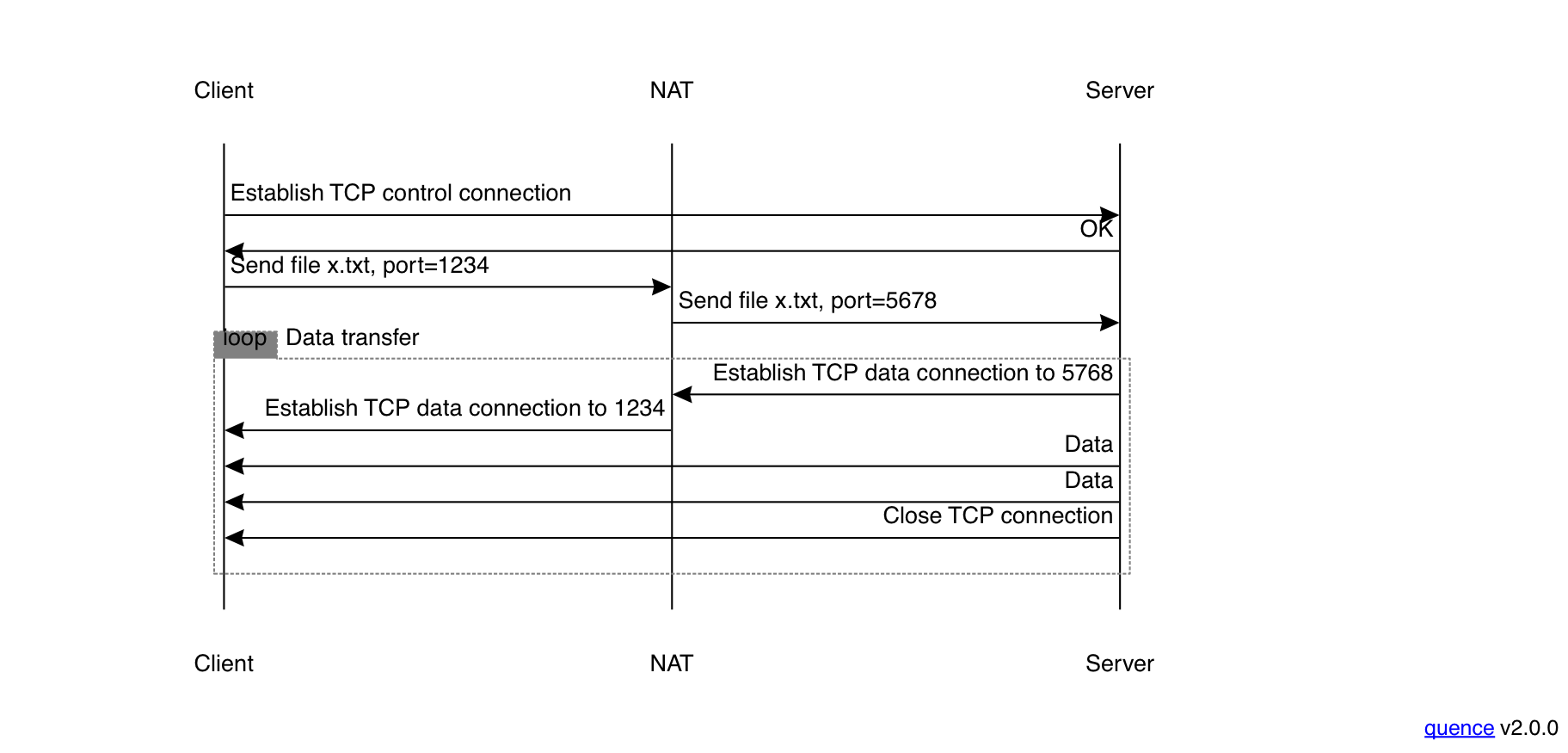
An aggressive ALG #
Sometimes ALGs aren't so careful, however. The FTP ALG only works
because the NAT knows about FTP, but what about unknown protocols?
One possible implementation is to just pattern match by replacing
any occurrence of the IP address (e.g., 10.0.0.1) or the
IP address and port (e.g., 10.0.0.1:1111) with the NAT's
address and port (and maybe even make a new NAT binding to
go along with it.) This is a general mechanism but also a brittle
one. In one hilarious case, Adam Roach (another VoIP pioneer)
was trying to download a Linux disk image and kept getting checksum
errors.
He eventually tracked it down by comparing the right image and the one he was getting and found a 4 byte difference, where the right value corresponded to his public IP address and the value he was getting was his internal address. What was happening was that the ALG in the NAT was just rewriting anything that looked like his external IP into his internal IP, regardless of where it was in the data stream. Not good!
Note that the NAT mostly doesn't interfere with the client's data: it just knows enough about FTP to know where the port number is, create the appropriate incoming NAT binding, and then replace it on the control channel. This of course won't work as well on unknown protocols and won't work at all on encrypted ones (in fact, any tampering with an encrypted protocol will generally just cause some kind of failure). At this point FTP is mostly gone (due to a combination of being insecure, being superseded by HTTP, at least in the case of Web browsers, concerns about the quality of the implementations), and newer protocols don't adopt this pattern because they want to work well with NATs. The reason that ALGs of this kind were needed was to avoid breaking existing protocols when NATs were first introduced, but now that NATs are widespread, the opposite dynamic is in play and new protocols have to avoid breaking when run over existing NATs.
Carrier-Grade NAT #
Initially, NATs were largely deployed at the boundary of consumer or enterprise networks (where they are now ubiquitous). However, as IP address space got more and more scarce, ISPs found themselves in the position where they were not able to get enough IP addresses for each customer to have one. The solution, of course, was to have a giant NAT (usually called carrier-grade nat (CGN) which multiplexes multiple subscribers onto the same IP address. Of course, the customer may still have their own NAT, so with CGN you can have multiple layers of NATting and address rewriting, which of course couldn't possibly go wrong.
In a CGN scenario, the addresses assigned to subscribers can either be from unroutable address space (either from RFC 1918 or from the new RFC 6598 block), or can be IPv6 addresses. In the latter case, subscribers would just have IPv6 addresses and the NAT would rewrite things to IPv4 on the way out the door, in a technique called NAT64. This scenario isn't as simple as with IPv4 because the network also needs to rewrite IPv4 addresses in DNS A records to IPv6 AAAA records (a technique called DNS64) so that the IPv6-only clients can send to them; this comes with its own problems, but that's a topic for another post.
The IETF and NAT #
For a long time, the IETF was basically in denial about NAT, for two major reasons:
- Any packet rewriting (let alone ALGs) violates the end-to-end design of IP in which packets just go untouched from A to B.
- It was seen as a technique to extend the lifetime of IPv4 when everyone should just be transitioning to IPv6 (sharpen the contradictions!)
The general attitude at the time was that standardizing NAT behavior would just encourage it and instead one ought to ignore NATs and hope they would go away, when the IPv6 rapture finally arrived. You can see this attitude as late as 2012, when RFC 6598 was published with the following statement:
A number of operators have expressed a need for the special-purpose IPv4 address allocation described by this document. During deliberations, the IETF community demonstrated very rough consensus in favor of the allocation.
While operational expedients, including the special-purpose address allocation described in this document, may help solve a short-term operational problem, the IESG and the IETF remain committed to the deployment of IPv6.
This all worked out about as well as you would think: NATs are everywhere and we still don't have anything like full deployment of IPv6. To make matters worse, in the absence of any guidance, NAT behavior became extremely variable and idiosyncratic, leading to ever more complicated workarounds. Eventually, in 2007, the IETF published RFC 4787 document describing how NATs ought to behave; by that time there were of course a huge number of NAT deployments which didn't follow these guidelines, though they're hopefully useful for developers of newer devices.
Final Thoughts #
NATs provide a particularly good example of the way the Internet evolves, which is to say workaround upon workaround. The reason for this is what Google engineer Adam Langley calls the "Iron law of the Internet", namely that the last person to touch anything gets blamed. The people who first built and deployed NATs had to avoid breaking existing deployed stuff, forcing them to build hacks like ALGs and unpredictable idle timeouts. Now that NATs are widely deployed, new protocols have to work in that environment, which forces them to run over UDP and to conform to the outgoing-only flow dynamics dictated by the NAT translation algorithms. Of course, there is a whole class of applications that don't fit well into that paradigm, in particular peer-to-peer applications like VoIP and gaming. In the next post we'll look at techniques to make those work anyway, even with existing NATs.
Yes, I know I still have two unfinished series, one on transport protocols and one on Web security. I got a bit distracted, and, in the case of the transport protocol series, a bit carried away with one of the posts, but I do plan to get back to them. I'm already partway through Part II, so I should have that up relatively soon. ↩︎
In theory IANA could just assign numbers directly, but this allows for regional governance. ↩︎
Technically this mechanism is known as "Network Address/Port Translation" (NAPT) but as this is the most common approach, NAT is the common term. ↩︎
I've omitted one detail, which is that you need to give the clients all new addresses from the RFC 1918 space, but in modern networks, the client addresses are centrally assigned by the local network, so this is typically straightforward. ↩︎
We actually had shirts made, with the front saying "32 + 16 > 128", with the joke being that the 32 bit address + 16 bit port of IPv4 was better than the 128-bit IPv6 address. Cafe Press seems to have lost the design though. ↩︎
At one point there was a draft to make SCTP work better with NATs, but it doesn't seem to have ever been standardized. ↩︎
A big reason to have a new transport protocol is to have your own rate limiting and reliability mechanisms, and that doesn't work if you run them over TCP, which has its own mechanisms. ↩︎
NATs aren't the only reason to deploy new protocols over UDP. It's also helpful that you can implement new UDP-based protocols entirely in application space rather than by modifying the operating system. ↩︎