Do you know what your computer is running?
Posted by ekr on 07 Sep 2021
A relatively common problem in computing is to determine what software is running on some device. As I mentioned in a previous post, this turns out to be a much harder problem than you would intuitively think it is, as we'll see below.
DRM and Attestation #
Let's ease into the problem by starting with what's probably the best known application for verifying what piece of software is running, namely Digital Rights Management (DRM), which is the industry jargon for copy protection for music, movies, etc. Suppose that a video streaming service wants to let you watch a movie but prevent you from sending a copy to someone else, saving it[1], etc. The first thing they are going to do is encrypt it, but at some point it has to get decrypted by a computer on your end and displayed on a screen. The problem from their perspective is that it's your computer, not theirs, so what stops you from loading new software onto your computer that records the movie on disk somewhere? In order to make this work, the service needs to somehow verify what software your computer is running.
One thing you might think that the service could do is just ask your computer to tell it what software it's running, like so:
The obvious problem here is that whatever viewing software you have installed on your computer can just lie about its version number; how would the service know better? Another thing that people often suggest is that the client send a hash of the player software, but this has the same problem; your computer can just lie about it. At one level, this is just the same problem that you have authenticating any endpoint over the Internet, namely that the only information you have is what the person on the other end sends you, and they could be lying.

All of the standard solutions to Internet authentication involve the endpoint proving its identity (the authenticating party (AP)) demonstrating knowledge of some secret information (password, cryptographic key, etc.) to the endpoint who wants to authenticate them (i.e., the relying party (RP)). In some cases the RP and the AP will share the information and in others the RP will just have something (a "verifier") that lets them verify that the AP's message is correct. In either case, the AP has to have a secret value and has to be able to keep it secret. This isn't unreasonable in the ordinary authentication context because, as described in RFC 3552, we normally assume the endpoint is secure:
The Internet environment has a fairly well understood threat model. In general, we assume that the end-systems engaging in a protocol exchange have not themselves been compromised. Protecting against an attack when one of the end-systems has been compromised is extraordinarily difficult.
That's all fine when we're talking about a web site authenticating them to you or you to the site, but the problem in the DRM context is that the computer on which the player runs belongs to the attacker which is to say you. Remember that the purpose of DRM is to stop you from doing what you want with the the media, whether that's saving a copy, forwarding it to a friend, screenshotting it, or even skipping past the annoying FBI warning at the start. So, pretty much by definition the end-system on which the player is running is compromised, which makes it hard for it to keep a secret. The attacker can reverse engineer the program to extract the key, as famously happened with DVD copy protection. [2]
There are two basic approaches that people who make DRM systems use to address this problem. Obfuscation and "trusted computing".
Obfuscation #
"Obfuscation" is the blanket term for a variety of software
engnineering techniques designed to prevent someone in possession of
your program from figuring out what it does (in this case, from
extracting whatever secret it's using to authenticate).
In general, it's reasonably straightforward -- though often
a lot of work -- to figure out what a given program does
The usual situation is that you have a program binary
(i.e., something the computer can run)
which has been compiled
from source code written
in some nominally human-readable -- or at least writable by humans -- language like C, Java, etc. This
is a lossy transformation in that it may remove comments, the names of functions,
variables, etc. There are tools such as decompilers
that allow you to go from the binary back to compilable code,
but often the result isn't ideal (e.g., you get function names like func123a).
Even when you do have the source code, it can be quite difficult
to figure out what a large system does, just because programs can
be very complicated; this is one reason it takes a while for
even experienced programmers to be effective when moving to a new
job and a new code base.
However, it's possible to make this process a lot harder by transforming the program appropriately. A detailed description of this process is outside the scope of this post, but for instance, you might break up and separate logical units such as functions, merge unrelated units into the same function, conceal constants, etc. You can also automatically generate code which is executed at runtime. There are of course tools for doing this kind of thing and the result of all this can be very difficult to read. And of course, there are tools to assist in removing obfuscation.
The big challenge for obfuscation is that the analyst/attacker can just execute your program and see what it does. Moreover, they can execute it under instrumentation such as a debugger or a virtual machine and trace how individual values are computed. This is a real challenge to keeping secrets because the secrets have to eventually be used to do something or other and so the analyst can work backward from the data that gets written to the network to how those values were computed. For this reason, it's not uncommon for obfuscated programs to also have some mechanism to detect when they are being analyzed in this fashion and to behave differently (e.g., to abort).
At the end of the day, however, obfuscation is an arms race: unlike ordinary cryptographic protections which are designed to provide security under certain mathematical assumptions, obfuscation is just about making analysis really annoying. With enough work, a determined attacker will nearly always be able to deobfuscate a given piece of software.[3] This has motivated interest in techniques which are intended to be harder to attack, namely what's called "trusted computing".
Trusted Computing #
Conceptually, what trusted computing does is to replace obfuscation with hardware. The general idea is to add a new chip (often called a trusted platform module (TPM)) to your computer that you don't get to run code on. That chip has a secret embedded in it that lets it authenticate itself so you can't just impersonate it with code you write yourself. The usual practice is to have each chip have its own secret[4], which makes it possible to blocklist a given chip if you determine that the secret has been compromised (for instance, if someone releases a software player with that secret in it). Sometimes the chip will have some sort of technology to prevent someone from breaking into it and stealing the secret. For instance, it might detect when the case is removed and erase (the technical term here is "zeroize") the embedded secret, but even if you don't do that, it's supposed to require physical attack to extract the key,[5] and this is difficult for people to do at home and may also destroy your device. By contrast, for software-based obfuscation, it's much easier to just write some program that you can run to extract the keys from everyone's player, even if they have different keys.
The challenge with TPMs is that they tend to be fairly limited. You already have a fast processor on your device and you don't want to put a second fast processor in the TPM, which means that it's going to be a challenge to do expensive compute tasks like video decoding in the TPM. Moreover, once you've decoded the media it's got to go somewhere, and that somewhere is usually the video card or whatever, which is connected to the main processor. The usual solution is to do the media decoding on the CPU but use the TPM for attestation. What this means is that the TPM is able to look at the computer's memory and determine what program is running and then tell the other side.
It's important to remember that this still requires a secure channel (i.e., encryption) between the Service and the Player. Otherwise, the attacker will just mount a man-in-the-middle attack, like so:
A secure channel prevents this because the service knows that they are talking to the player (even if the attacker is in the middle).
Verifying Devices #
Now that we've covered DRM, we can finally talk about verifying the software on devices.
Why this is really hard #
The good news is that you can use exactly the same techniques to verify the device in front of you that you can to verify a device over the Internet. The bad news is that it doesn't help very much. The reason for this is that you aren't interacting with the device over a cryptographically secure channel; instead you're just pushing buttons, swiping on the touch screen, etc. But how do you know that you are actually talking to the real device? For instance, suppose that the attacker takes an iPhone, jailbreaks[6] it, and then installs some software that remotes a real iPhone, forwarding all of your touches to that iPhone and then taking what it displays and showing it on your screen. Then the attacker can steal your passwords (when you key them in), your photos (when you take them), just by capturing stuff en route to the real device. This is obviously an artificial example (though not too different from an attack demonstrated by Wolchok et al. on India's voting machines), but as we'll see, not as artificial as you might think. The same thing applies if you plug in a cable (as with the iPhone lightning cable) because that interaction too is potentially controlled by the attacker.
Unlike the DRM case, then, if you have an interactive device with a user interface, and you want to verify the software that's running on it, you can't just use attestation: you actually need to convince yourself that everything in between your hands/eyeballs and the processor is doing what it's supposed to do. In the most general form of the problem, you are given some totally unknown device and have to determine what is running on it. This is an incredibly difficult problem because it more or less requires tearing down every component in the device to ensure that it's what it appears to be (you're not trusting whatever's printed on the package, right?). This is incredibly expensive and time consuming and not really practical for your average person -- I, for one, don't own an electron microscope -- and worse yet, it destroys the device, so you've just convinced yourself that this unit is OK, but now you need another unit, and how do you know that one is OK?[7]
Obviously, this isn't going to happen -- though that should make you pretty nervous about assuming your devices are secure, and is one reason for concerns about foreign chip manufacturing -- but it's useful to look at a simpler problem: assume that the hardware is what it appears to be and just verify that the software is fine.
Verifying Software #
Let's start with the simplest case: we've got a simple computer with a CPU attached to a storage device like a solid state drive (SSD), as shown below:

The CPU loads its program off the flash drive and executes it. This is great! We can just take the computer apart, read the data off the SSD and we know exactly what the CPU is going to do (assuming, again, that we know what the software ought to look like) right? Wrong. The problem is that that picture I just showed you is simplified. A more accurate picture is shown below:
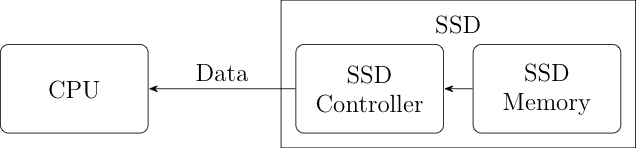
The thing is that an SSD isn't just dumb storage. It's actually a little computer of its own attached to the dumb storage. That computer takes care of interfacing with your computer as well as managing the use of the memory for things like wear leveling. Because this is a computer, it's got its own software (though the technical term is firmware) and (surprise!) that software can be updated from the computer. This means that an attacker who subverts the computer can then reprogram the SSD controller firmware to lie about the contents of the SSD. Moreover it can give different answers at different times; for instance the firmware can recognize the typical access pattern associated with the CPU loading software and give one set of answers (the malicious software) and the pattern associated with just reading the SSD contents and give another set (innocuous data).
It's not impossible to solve this specific problem. For instance, you could attach a protocol analyzer to the connection between the CPU and the SSD to verify that the right data was being loaded (though of course it's probably some work to reassemble it). Another option would be to tear down the SSD and directly read the firmware. But neither of these are really straightforward techniques available to your average user. I, for instance, own neither a PCIe protocol analyzer nor an electron microscope.
More importantly, this problem is replicated all throughout your computer, which is full of these little processors (PCI controllers, USB controllers, baseband processors, graphics cards, power controllers, etc.). It's not uncommon for even keyboards to have their own processors (so you can reprogram the keys, for instance). Not all of these are reprogrammable from the CPU, but a lot of them are, and many have a fair amount of access to what's happening on the computer. For instance, the graphics card gets to see -- and control -- everything that's shown on the display. If you want to be sure what your computer is doing, you need to be able to examine each and every one of them, and I haven't even mentioned that the CPU itself may have microcode which that controls aspects of its behavior and can be updated. The point here is that all your interactions with the computer are mediated by a pile of other processors whose code you can't directly inspect.
Applications #
This is already pretty long, but I did want to tie it back to two other topics.
First, we have the question of verifying the software on Apple devices, as Apple suggests in order to ensure that the device has the right CSAM database. As should be clear from the above, this is highly impractical. The purpose of this attack is to verify that Apple hasn't deliberately given you special software with a different database, but your only way of verifying any of this is through Apple's own interface. In order to do better, you'd need to more or less totally disassemble your iPhone and then start digging through the pieces; obviously not something your average user is going to do.
Second, we have voting machines. As I've mentioned before, they're really just general purpose computers, but that means that they're programmable and so an attacker can reprogram them. For the same reasons as with the iPhone, if the machine is potentially compromised, there's no practical reason to make sure that it's not actually been compromised. This makes chain of custody of the machines extremely important: if the machine is ever in the hands of a potential attacker, you need to assume it's been compromised (hence the decision by Maricopa County to replace voting machines that were improperly secured during the Cyber Ninja "audit").
None of this is to say that if computer is compromised by the average attacker that they're going to overwrite all of these processors. However, it does mean that it's very hard to convince yourself that your computer is secure if it's been compromised by a dedicated and sophisticated attacker. And of course if it's been physically in the hands of such an attacker, you'd be best served to take the data off via some kind of airgapped mechanism and then destroy the device, because you can't really every trust it again.
The obvious reason to do this is to disable viewing when your subscription runs out. ↩︎
Note that there are a number of cases where commodity applications keep "secrets", such as when they embed API keys which are used to access Web services. Generally, these secrets are only intended to deter attackers who aren't trying very hard. ↩︎
Technical note: I am omitting here discussion of indistinguishability obfuscation, a cryptographic technique for doing obfuscation. I don't understand it well enough to have an opinion on how well it works, but as far as I know, is not currently in production use. ↩︎
Typically, this would be some sort of private key, with the public key being signed by the hardware manufacturer. ↩︎
Though in practice there's a long history of people figuring out how to attack this kind of device using only software. ↩︎
iPhones already make use of another form of trusted computing, which is that they will only run software authorized by Apple. Jailbreaking is the process of removing these protections so you can install software of your choice. You actually probably could get away without jailbreaking the device by taking it apart and just forwarding the signals to and from the remote touchscreen. ad ↩︎
If you were really serious, you could buy a pile of units and randomly select a bunch for teardown, and if they all turned up fine, feel reasonably confident that most of the units in the batch were also OK. ↩︎