Understanding The Web Security Model, Part IV: Cross-Origin Resource Sharing (CORS)
Posted by ekr on 19 Apr 2022
This is part IV of my series on the Web security model (parts I, II, outtake, III). In this post, I cover cross-origin resource sharing (CORS), a mechanism for reading data from a different site.
As discussed in part III, the Web
security model allows sites to import content from another site but
generally isolates that content from the importing site. For instance,
example.com can pull in an image in from some example.net and display it to
the user, but it can't access the contents of the image. This is
a necessary security requirement because it prevents attackers
from exploiting ambient authority to access sensitive data
but it also prevents legitimate uses for cross-origin data,
such as a cross-origin API.
Cross-Origin APIs #
Consider the case where there is a Web service that has an API, like Wikipedia or Bugzilla, and you want to write a Web application which takes advantage of that API. For instance, suppose I have a little Web service which lets you get the weather at a specific location indicated by ZIP code. This service might have an API endpoint at the following URL.
https://weather.example/temperature?94303
With the response being a JSON structure:
{
"temperature":"25",
"units":"C"
}A Web site could access this API and display the local temperature using the fetch() API like so, with the zip code being 94303 (Palo Alto).
fetch("https://weather.example/temperature?94303")
.then(a => a.json()).then(a => {
console.log("Temperature is "+ a.temperature + " degrees " + a.units);
})
.catch(a => {
console.log("Error " + a)
});Obviously, a real application would do something more interesting, but I'm just giving an example here; as with many things Web, the platform capability is simple but the complexity is in the application logic.
Server-to-Server APIs #
It's mostly possible to replace all of these client-side APIs with server-to-server APIs in which the API-using Web site talks directly to the Web service. This is a pretty common pattern on the Web: the user authorizes site A to perform operations on its behalf on site B (typically using OAuth) and then send the data to the client. This is, for instance, how Github integrations work.
However, there are plenty of situations where it's more efficient to send the data directly to the client, especially if there is a lot of data. Note that from the perspective of site B it's not really safer to have the data sent to to a Web page served off of site A than it is to send it to site A directly, because the JS is of course under control of site A and can always just send it back to A.
This all works fine if the site that is consuming the temperature API is the same as the one hosting it, but what if it's not? There are a number of ways this can happen:
-
The sites are operated by the same entity, but they site is built as a Web app that runs in the browser and consumes data from the API. The app might be downloaded from one server and the API be on another server.
-
The sites are operated by different entities, for instance if the Web service is public, as in my temperature example.
However, if the sites are different, then this
request violates the the same origin
policy, as described in part III.
If I try to do this, the browser will generate an error (on
Firefox, TypeError: NetworkError when attempting to fetch resource)
triggering the catch clause
in the code above.
This restriction exists for a good reason. Even though this particular application seems safe, because the temperature API is public, others might not be. Because (1) the Web threat model assumes that any site can be malicious and (2) requests from the browser contain the ambient authority of the client. If you allow an attacker to use the ambient authority of the client, you are asking for problems. For example, Gmail is a "single page app" in which the server loads a JS program onto the browser and then that browser uses Web APIs to read your messages. If other Web sites can do that, then this would obviously be bad!
Instead of restricting what you can do with the cross-origin
requests, you might think that browsers could get away with
just removing cookies whenever you use cross-origin fetch().[1] This is
only a partial solution though, because cookies are not the only
kind of ambient authority. A particularly important case is
where the victim browser is able to connect to network resources
that the attacker cannot directly, for instance if the
browser is on the same local network as the server and there
is a firewall preventing external access, but the server
doesn't use cookies for access control. In this case, if
an attacker could do cross-origin fetch() then they
might be able to steal data from the server even if the
browser strips cookies.
Even with the same-origin policy it is still possible to attack machines behind
the firewall under certain conditions. For instance, if
they are not using HTTPS, then it is possible to mount
something called a DNS rebinding
attack in which the attacker loads their page and then
changes their DNS to
point their site (e.g., attacker.example) to point
to the server behind the firewall. This causes the
browser to think that the behind-the-firewall server
is actually the attacker's server and hence same-origin
to the attacker's site (another reason to use HTTPS).
What we need here is a controlled way of allowing cross-origin requests that ensures they can't be used for attack.
JSONP #
It turns out that even without CORS, the Web platform actually had a mechanism that lets you make cross-origin requests; it's just super-hacky. You may recall from part III that JavaScript executes in the context of the loading page, even when it's loaded from another origin. This means that you can simulate a Web services API by having the main Web page load a script from the Web services site. That script then inserts the data into the context of the loading Web page.
In order to make this work, you need to do two things:
-
Instead of using
fetch()the API-using page needs to use<script src="">to load the API point from the server. -
Instead of returning JSON, the server needs to return actual JavaScript which the inserts the data in the page.
For instance, the API-using page might do:
<script>
function temperatureReady(a) {
console.log("Temperature is "+ a.temperature + " degrees " + a.units);
}
</script>
<script src="https://weather.example/temperature?94303&callback=temperatureReady">And then the Web service API would return:
temperatureReady(
{
"temperature":"25",
"units":"C"
}
});This code just calls the temperatureReady() function that already exists in
the page (the way the Web service knows which function to call is that it's
passed in query parameter in the URL) with the data as the argument to the function.
Because the script runs in the context
of the page, this is permitted and the result is that the data gets
imported into the page as well. Mission accomplished!
Note that in the real world the API-using page wouldn't just statically include the script. Rather, when you wanted to make an API call, JS on the page would dynamically insert the script tag (remember that JS can manipulate the DOM), inserting whatever URL was necessary to make the correct API call.
This idiom, invented (or at least popularized) by Bob Ippolito, is conventionally called JSONP, because it's commonly used to wrap APIs which use JSON-formatted data and that JSON data is "padded" by wrapping it to make it valid JavaScript (otherwise it will be rejected by the browser as JSON is not well-formed JavaScript). However, there is no rule that the JavaScript returned by the site has to have embedded JSON in it. For instance it could return XML and invoke the XML parser, or just return a bare value such as the temperature as an integer. The API contract just requires that the JS served by the server calls the callback function that the API-using page indicates; as long as it does that everything will work.
Attacks by the API Server #
Moreover, nothing restricts the Web services server from doing other things besides calling the indicated callback: it can do anything it wants, including changing the DOM in any way it pleases, stealing the user's cookies, or making API calls to the Web site that the page was served off of. In other words, a naive use of JSONP requires large amounts of trust in the Web service you are using; this is obviously not ideal.
It's possible to address these issues by adding a third origin into the mix, as shown in the diagram below:
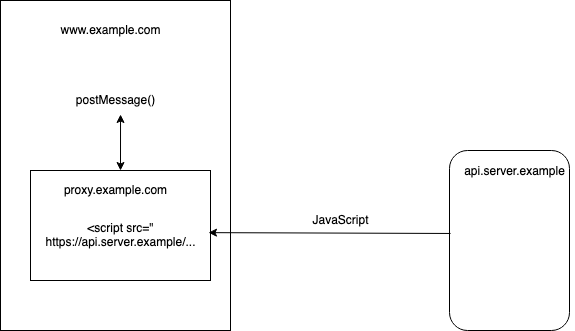
The idea here is that instead of loading the JavaScript directly
from the API server into your page, you instead load it into
an IFRAME which is hosted on a second origin that you control
(e.g., proxy.example.com). That IFRAME ends up with
the data but because it's cross-origin to your site it
can't impact your site, and thus
it is safer to load potentially malicious JS into it.
You then use the postMessage() API
to talk to the IFRAME to get the data in and out. Effectively,
this creates a little proxy which protects you against the Web services
API JS.[2]
I've actually never seen this trick written down (readers: if you're
aware of a published description, please send me pointers) but I'm pretty confident
it will work.
Of course, this is all a bit clunky, but it work (to quote Spinal Tap, "it's such a fine line between stupid and clever."). If you wanted to do cross-origin queries before CORS you didn't have a lot of options.
Attacks by the API Client #
Maybe the API-using site trusts the Web service site or uses something like the proxy technique above to protect itself, but that just gets us back to where we were without JSONP, with the need to find some way to protect the Web service from the API client.
There are actually two related problems:
- Preventing the API client from reading data it shouldn't from the service.
- Preventing the API client from causing unwanted side effects on the service.
The way to think about both of these is that the attacker is abusing the user's authority to talk to the Web service, and so is able to cause the Web service to do things on behalf of the user. It's important to understand that the server is trusting the browser to follow the rules; if the browser behaves incorrectly then all bets are off. The reason this is (mostly) OK is that the threat model is that the attacker is attempting to abuse the user's access to the service. Nothing stops the user from extracting the cookies themselves and making any requests they want. The server has to have its own access control checks that prevent abuse by the user.
The basic defense here is to ensure that the client site which is making the request is authorized to do so. A common pattern is for the service to require you to authorize that site, with a dialog like the one below. Note: this dialog is actually for a different kind of access where CircleCI talks directly to GitHub, but the idea is the same and how would you know if I didn't tell you?
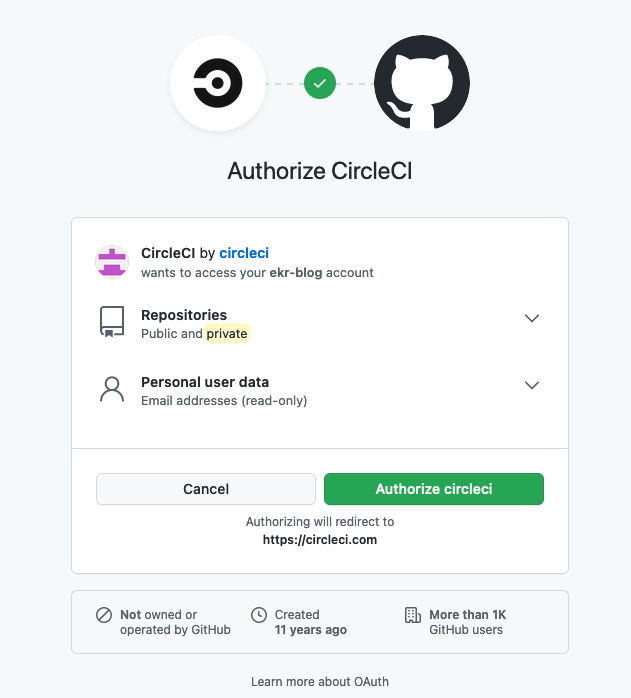
If you approve access for site circleci.com, then the Web service
(in this cases GitHub)
would add an access control entry to your account that indicated that
the other site (in this case circleci.com could make requests on your behalf. Of course, then it
to actually enforce those rules, which is where
things get a little bit tricky. This is done using either
the Referer
header or the newer Origin
header to determine which site is making the request. The service then
looks that up against the access control list to determine whether to
allow the request or not. Neither of these headers can normally
be controlled by the attacker (they are on the forbidden header list of headers which
JS cannot modify)
and therefore can be trusted by the server (remember, that you're
worried about attack by a site, not by the user, who can of
course make their browser do whatever they want).
The major drawback of using Referer or Origin in this
way is that they are sometimes missing and the checks can be
tricky to get right
in which case you will inadvertently deny service to
a legitimate client. As far as I can tell, however, they fail
"safe" in that if you implement them correctly
you won't accidentally give access to someone who should not have
access.[3]
From one perspective, JSONP solves our problem: it lets us make
cross-origin API requests. In principle, we probably could build
everything we want with JSONP, but in practice it's a seriously
clunky mechanism—especially the part where we
inject<script> tags into the DOM—that takes a huge amount of care to use correctly,
and has big risks if used incorrectly. A lot of that can be hidden
with libraries but we still know it's there.
With that said, many
big sites (e.g., Google, Twitter, LinkedIn, etc.) deployed JSONP
APIs which just shows how useful a capability it is. What we needed
was a mechanism that did much the same thing but was simpler and
safer. This brings us to CORS.
CORS #
The basic idea behind CORS is that it allows the site from which the resource is being retrieved to make limited exceptions to the same-origin policy.
Simple Requests #
The simplest version of CORS allows the API-using site to
read back the results of its cross-origin requests, which, you'll
recall, is normally forbidden. In order to allow this, the server
sends back an Access-Control-Allow-Origin
header listing the origin that is allowed to read back the data.
There are two main options here:
*indicating that any origin is permitted- An actual origin, such as
https://example.comindicating that only that origin is permitted
For example, here is an example of a successful CORS request, in which
example.com serves a page that makes a fetch() request to
service.example. In this case, the service wants to allow the
request so it sends an appropriate Access-Control-Allow-Origin
header, with the result that the browser delivers the data to the
JS.

Sites use the * value when they don't care who can read
their data—effectively for public data—and an actual origin if they want to restrict it
to certain origins (or to authenticated users, as described below).
You're only allowed to specific a single origin, so as a practical
matter the server needs to look at the client's Origin header
and provide something matching in response. This is already useful
as it allows for effectively public data, and it mostly doesn't
enhance the attacker's capabilities as in most cases the attacker
can just connect directly to the server and retrieve the data
(with the exception of topological controls as described above).
Where things get interesting is if the client provides a cookie,
because that cookie is (likely) tied to the user's authentication
and therefore is not something that an attacking Web site could
get unless they had compromised the user's credentials. Allowing
cross-origin reads in these circumstances is more dangerous and
CORS requires the service to add another header,
Access-Control-Allow-Credentials,
in order for the data to be readable. By default, cross-origin
requests don't include a cookie, which means that if the
server sets a cookie for some other reason (this is quite common)
and no authentication
is required, things will still work even if the server doesn't
set this header.
Non-Simple Requests #
This all works fine for situations where the security property you need to enforce is one where the client can't read data from the server, but what about cases where you what you're concerned about is not about the site reading back the data but that the request itself is dangerous even if the client can't read back the response (for instance, the request might delete some of the user's data).
For this category of requests, CORS requires what's call a "preflight", which is basically an HTTP request in which the browser asks "Is it OK if I were to make this request?", and then only makes the request if the server says "yes", as shown in the diagram below.
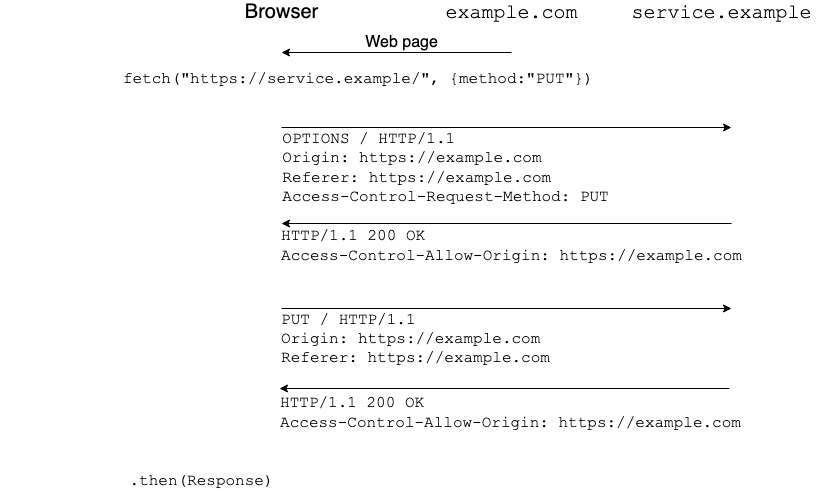
Note that the preflight uses the OPTIONS method. Because
OPTIONS is not used for ordinary HTTP requests, this
prevents side effects from the preflight itself.
So, what requests need preflighting? Those which meet any of the following conditions:
- Using an HTTP method other than
GET,HEAD, orPOST - Using non-automatic values for any headers other than
Accept,Accept-Language,Content-Language,Content-Type,Range - Having any media type other than
application/x-www-form-URL-encoded,multipart/form-dataortext/plain - Not having any event listeners for the upload
- Not using a
ReadableStreamon the request
This is a sort of odd list, isn't it? Take the method for example.
You can do plenty of damage using the POST method? And why can
you do POST and not PUT, for instance? For many of these
properties, the answer is that these are the capabilities that JavaScript
already had pre-CORS. For example, if you have an HTML form, you can generate
a HTTP request with any of these methods and the allowed media
types. I haven't checked the other restrictions in detail, but I believe they
map onto similar "you can already do it" contours: for instance, HTTP
forms let the site upload stuff, but if you can track the process of the
upload, then you can see if the server processed some part of it and
then took some action (for instance, rejected it). This
would let you learn some information about the behavior of the
server in response to this request, which you otherwise would not be permitted to do.
In other words, simple requests are (approximately) those you could do without CORS, which means that they are safe to do with CORS, as long as the server agrees to the JS having access to the data. However, if you couldn't have done it without CORS the client needs to do a preflight.
Failing Safe #
One thing that's key to note here is that the server has to opt-in to any of the new CORS behavior. For simple requests, if the server doesn't respond with the appropriate header, then the response won't be available to the JS, as shown in the example below.

For non-simple requests, if the server doesn't accept the preflight, then the request never happens at all. Because not sending these headers is just the existing pre-CORS behavior, this means that CORS fails safe: if you have a server which you didn't update then the browser just falls back to the pre-CORS behavior. This is a really critical property when rolling out a new Web feature: we don't want that feature to be a threat to existing sites.
The Web's Design Values #
Pulling back, the story of CORS is a good example of how the Web platform evolves.
Don't Break Anything #
As detailed in part III, the basic structure of the same-origin policy and the capabilities it gives sites was well in place before we really understood the security implications. This means that sites had come to depend on those properties and that made them really hard to change. Because those properties were hard to change, sites had to build defenses under the assumption that browsers weren't going to change their behavior, hence compatible hacks like anti-CSRF tokens rather than more principled solutions like SameSite Cookies that depended on the browser changing.
Conversely, when we are rolling out a new feature, it's critically important that it not create a new security threat for the Web. In particular, sites depend on the existing browser behavior, so you can't change that in a way that would make existing behavior unsafe.[4] However, this means that it's generally safe to deploy new functionality as long as it stays within the existing assumptions that sites have made about browser behavior, which is how you get to the design of CORS.
Paving the Cowpaths #
If there's any consistent pattern in the Web, it's that if there is something people want to do and there is a way to do it—no matter how hacky—people will find that way and use it; hence JSONP (see also, long poll).

Much of the job of evolving the Web platform consists of looking at people do with the Web in a hacky way and designing better mechanisms that (1) does what people want and (2) is convenient, or at least more convenient than whatever they are doing now (3) doesn't create new risks. If this is done right, the new mechanism will gradually replace the old hacky one and the Web gets a little better.
Next Up: Side Channels #
Everything I've written so far assumed that browsers actually do enforce the guarantees that they are supposed to enforce. Unfortunately, this turns out to be a lot harder to do than you might think. In particular, there are a number of of situations where attackers can use side channels (e.g., timing) to learn information that it can't learn directly. I'll be covering that in the next post.
Removing them from any cross-origin load would break cases where sites load cross-origin images and the like. ↩︎
I believe it's also possible for the Web Service to know that it will be loaded inside an IFRAME and thus dispense with the extra site, but I'm not 100% sure. ↩︎
Refererchecking is also common defense in depth measure against Cross-Site Request Forgery (CSRF) attacks, but it's not entirely sufficient because of the way HTTP handles redirects. Specifically, if a victim site redirects a page to an attacker site and the attacker-re-redirects back to the victim site to mount a CSRF, theRefererheader will be the victim site, which creates an attack vector. This is not really an issue for JSONP because if you load JS off an attacker site, you already have much bigger problems than CSRF. ↩︎WebSockets was delayed for some time after Huang, Chen, Barth, Jackson, and I found low a incidence risk from deploying it as-is and the WG had to add a defense called "masking". ↩︎