How NATs Work, Part II: NAT types and STUN
It's a miracle anything works at all
Posted by ekr on 17 Apr 2023
The Internet is a mess, and one of the biggest parts of that mess is Network Address Translation (NAT), a technique which allows multiple devices to share the same network address. This is part II in a series on how NATs work and how to work with them. In Part I I covered NATs and how they work. If you haven't read that post, you'll want to go back and do so before starting this one. This post starts to discuss NAT traversal, covering the different types of NATs and how to build peer-to-peer applications that still work from behind NATs.
As IP addresses became increasingly scarce, more and more of the client devices on the Internet started to move behind NATs. I don't have any real data here, but pretty much every consumer level WiFi router I've ever used is also a NAT, sharing a single externally assigned IP address amongst all the devices behind it. By contrast, servers typically have stable public IP addresses.[1] This arrangement works reasonably well in client-server situations because the client initiates the connections, and so doesn't need an address/port pair that's stable for more than the life of the connection. However, it doesn't work for peer-to-peer applications.
Peer to Peer Applications #
Although much of the Internet is client-server, there are a number of more or less important peer-to-peer (P2P) applications in which data flows directly between end-user machines rather than via a server (as in e-mail, Web, etc.). Some examples are:
- 1-1 video calling
- File distribution (BitTorrent or IPFS)
- Some Web3/blockchain systems
- Games
In principle, P2P systems have a number of advantages, including:
- Reduced cost
- because you don't need to pay for a server somewhere. This is an especially big deal for high-bandwidth applications like video calling or file sharing.
- Reduced latency
- because you don't need to send traffic up to the server and then from the server to the other side, which will generally be slower than sending it directly.
- Censorship resistance/avoiding centralized control
- because there's no central server to attack.
In practice, some of these advantages often come with disadvantages, which is why you see a lot of client/server applications and not a decentralized Web, but there is still a fair bit of P2P. The application I'm most familiar with is voice and video over IP: it's moderately expensive to run a centralized system like Meet or Zoom where you have to process all the media, but much cheaper to run one where the endpoints just talk to each other.[2]
P2P Challenges #
The way that a Web server works is that the server operator knows the IP address of the server and publishes it in the DNS. The port number is just 443 or 80 depending on whether the traffic is encrypted or not. Unfortunately, this won't work for P2P systems for two fairly obvious reasons (and also a number of non-obvious ones, as we'll see below):
-
Machines behind the NAT don't know their own IP address. If your machine has a public IP address, you can just look at how its configured and know what to publish in the DNS. In managed systems, the operators have some mechanism for assigning addresses and storing the data in the DNS. But when you connect your laptop to the WiFi, the IP address that the laptop sees is likely in some private range, e.g.,
10.0.0.*, which isn't useful for other people to connect to unless they happen to be on your network. -
Public IP addresses and ports aren't stable. In general, the NAT will only have a single public IP address, so that's reasonably stable (though see here), but the port is not. As I mentioned previously, the NAT creates a binding in response to outgoing traffic and then deletes it when there isn't any traffic. As a result, even if you knew the mapping of internal to external ports at some time in the past, that mapping may no longer be valid.
For these reasons, clients can't just publish their IP addresses like a server does (there is also the question of where you would publish them, but put that aside for a moment). Instead, you need some kind of server to help them.
Background: Voice over IP Architecture #
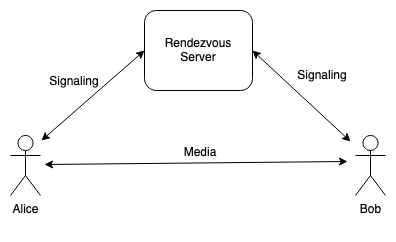
Just for convenience, let's focus on voice over IP. The diagram below shows what you might call the "reference architecture" for a voice or video over IP system like you might build with WebRTC:
Video Conferencing Topologies #
Ironically, despite all the work that has gone into NAT traversal, many video conferencing systems, the media doesn't actually go directly but rather goes through the server. The reason for this is that if you have many people in the call, then the sender needs to send a copy of their media to each other person, which means that if there are N people in the call, and their video is M megabits/second, they need to send (N-1) * M megabits/second of media, which can quickly overrun a consumer Internet link. Instead, it's conventional to use a star topology where the user sends their media to a server which replays it to everyone else in the call. This is expensive for the server, of course, but cheaper for the user. Some conferencing systems do send media directly for smaller conferences to minimize costs. Sending media directly also currently works better with end-to-end encryption for video, though that's a problem that's being actively worked on because you'd like to have end-to-end encryption even in large conferences where a mesh design isn't practical.
In a system like this, Alice and Bob both connect to a signaling server which is responsible for orchestrating the calls. In the case of a traditional VoIP system like you would design with SIP, Alice and Bob would each have a device or an app (often called a "softphone") that had the actual calling logic, presented the user interface, etc., and would exchange SIP messages via the server. In a WebRTC system such as Google Meet or Microsoft Teams, there is a Web server which hosts the Web app and carries messages back and forth between the Web browsers, even though much of the actual calling logic is built into the browser.
In either case, you would ideally like the media (i.e., the actual voice and video) to go directly between Alice and Bob (though see below). There are two main reasons for this. First, it is cheaper: real-time video involves transmitting a lot of data and if Alice sends all that data to the server and then the server sends it to Bob, then the server operator has to pay for all that data transmission. Second, it generally takes longer for the data to go from Alice to the server and then the server to Bob, than it would for Alice to send the data to Bob directly, especially if, as is relatively common, Alice and Bob are geographically close and the server is not. But now we have to contend with NATs.
STUN #
As noted above, the first problem we have is that the client machine may not know its own IP address. The NAT knows, of course, but there's no universally deployed protocol for it to tell the client. Instead, the client has to measure it directly. The standard protocol for this is called Session Traversal Utilities for NAT (STUN). STUN works by having the client talk to some server on the Internet (unsurprisingly called a STUN server). Typically, this server will be provided by the calling service, and configured into the clients somehow. For instance, WebRTC provides an API to tell the Web client which STUN server to use.
In order to discover its IP address, the client sends the server a STUN Binding Request, and the server responds with the IP address and port that the server saw (technical term: reflexive address) like so:
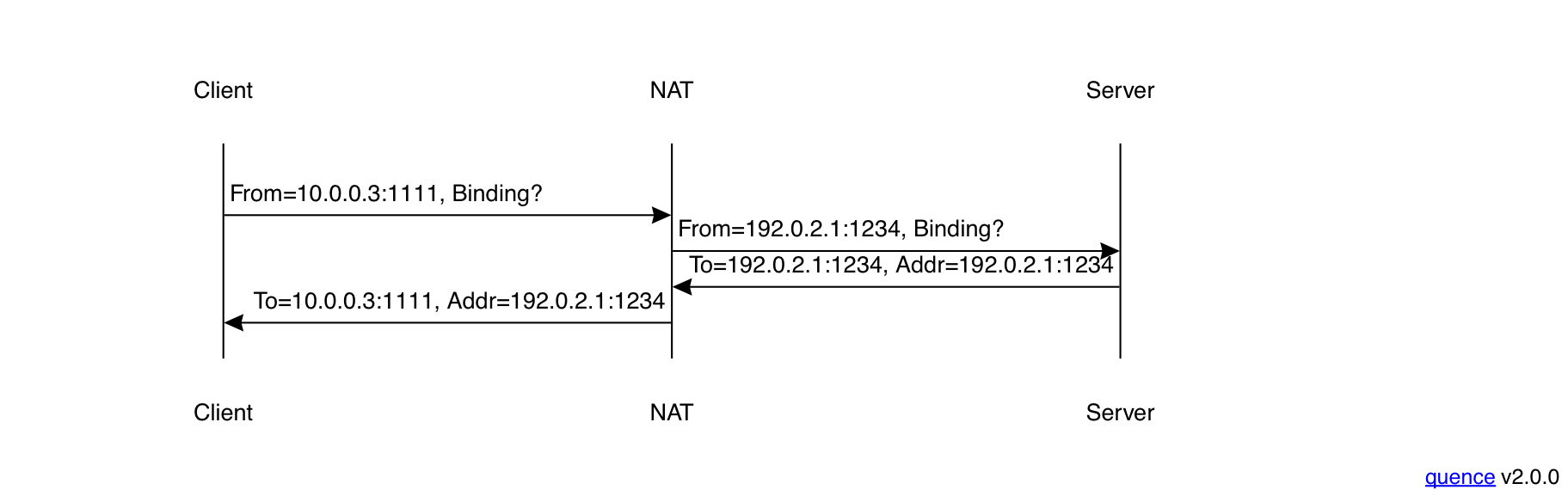
This is how the original version of STUN, published in 2003, behaved. Unfortunately, it is impossible to make things foolproof because fools are so ingenious. As you may recall from the discussion of Application Layer Gateways (ALGs) in Part I, some NATs will rewrite messages coming in from the Internet, rewriting the external (reflexive) address to the internal (host) address. If you have such a NAT, what you will instead see is a flow like below, where the client gets a response that just contains its own local address rather than the external one.
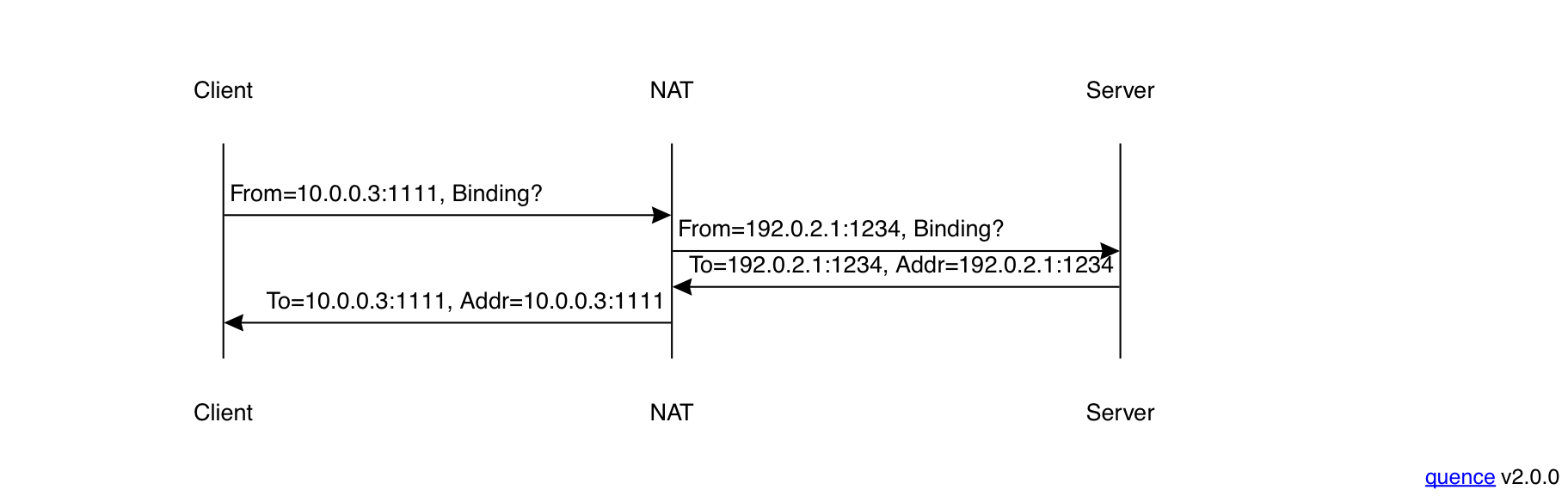
This is not useful! Unfortunately, we have to traverse the
the NATs we have, not the NATs we wish we have, so a way
around this was needed. The second version of STUN, published
in 2008, added a new way to return the reflexive address in
what is called the XOR-MAPPED-ADDRESS attribute. This
attribute worked by XORing the host and port with other
values from the packet. This is pretty weak sauce as encryption
goes but it's usually good enough to break up the simple-minded pattern
matching that NAT ALGs were using at the time (the idea
here isn't to avoid NATs which know about STUN and want
to rewrite values, but just to prevent accidental breakage).
This is mostly how STUN works today.
One thing that may not be immediately obvious is that you need to do the STUN queries from the same address and port that you want to receive media on. The reason for this is that each port you send from will have a different NAT binding, and so if you know the binding for port A this doesn't tell you about the binding for port B.[3] This is the same reason why you can't just have the Web server send you your reflexive address and use that: you're contacting the Web server from a different port (and when this stuff was designed, TCP rather than UDP) and so the binding that the Web server sees doesn't help you for your media. Instead, what you do is allocate a port to use for media, discover the reflexive address with STUN, and send that reflexive address to your peer, and then subsequently use that port to send and receive media.
NAT Types #
If only things were that simple. There are in fact NATs for which this will work, but many where it will not. There are two basic problems:
-
NATs which use different mappings for different remote addresses (and ports). Note: As a convenience, I am going to start saying "address" when I mean "address and port", because the alternative is clunky. For instance, if Alice sends packets to both Bob and Charlie, Bob and Charlie might see different reflexive addresses (or more likely ports, as your typical consumer NAT only has one IP address) even if Alice uses the same local address and port. These NATs are said to have address-dependent mappings or address and port-depending mappings, depending on which differences trigger variation. The alternative is called endpoint-independent mapping (these terms come from RFC 4787).
-
NATs which have consistent mappings but filter packets from addresses that the client hasn't sent to. For instance, Alice might send a packet to Bob, creating a mapping, but if Charlie sends a packet to Alice on the same reflexive address, the NAT would drop it. If Alice then sends a packet to Charlie, he will see the expected address, and if he responds to this packet, the NAT will deliver it. These NATs are said to have address-dependent filtering or address and port-dependent filtering. The alternative is endpoint-independent filtering.
The bottom line here is that there are a lot of different types of NAT, and depending on what kind of NAT you (and the person on the other side) have, you need to do different things in order to establish a connection.
How to get through a NAT #
As a notational convenience, I'm going to describe NATs using the following abbreviations:
| Behavior | Abbreviation |
|---|---|
| Endpoint-Independent Mapping | EIM |
| Address-Dependent Mapping | ADM |
| Address and Port-Dependent Mapping | APM |
| Endpoint-Independent Filtering | EIF |
| Address-Dependent Filtering | ADF |
| Address and Port-Dependent Filtering | APF |
A NAT is defined by the pair of mapping and filtering behaviors, so, for instance, EIM:APF is a NAT that has consistent mappings across addresses but filters based on address and port.
I'm also going to simply addresses and ports by writing them
as A:a, A:b, etc. where the first letter is the address
and the second is the port. Alice's local address will always
be A:a and Bob's will be B:b. The STUN server's will be S:s.
EIM:EIF ↔ EIM:EIF #
A NAT which has endpoint-independent behavior for both mapping and filtering is the easiest type to traverse: it's basically like having a public IP address except that the binding may not be stable over long periods of time. You can traverse this kind of NAT by just having each side publish its address and the other side can send directly, as shown in the figure below:
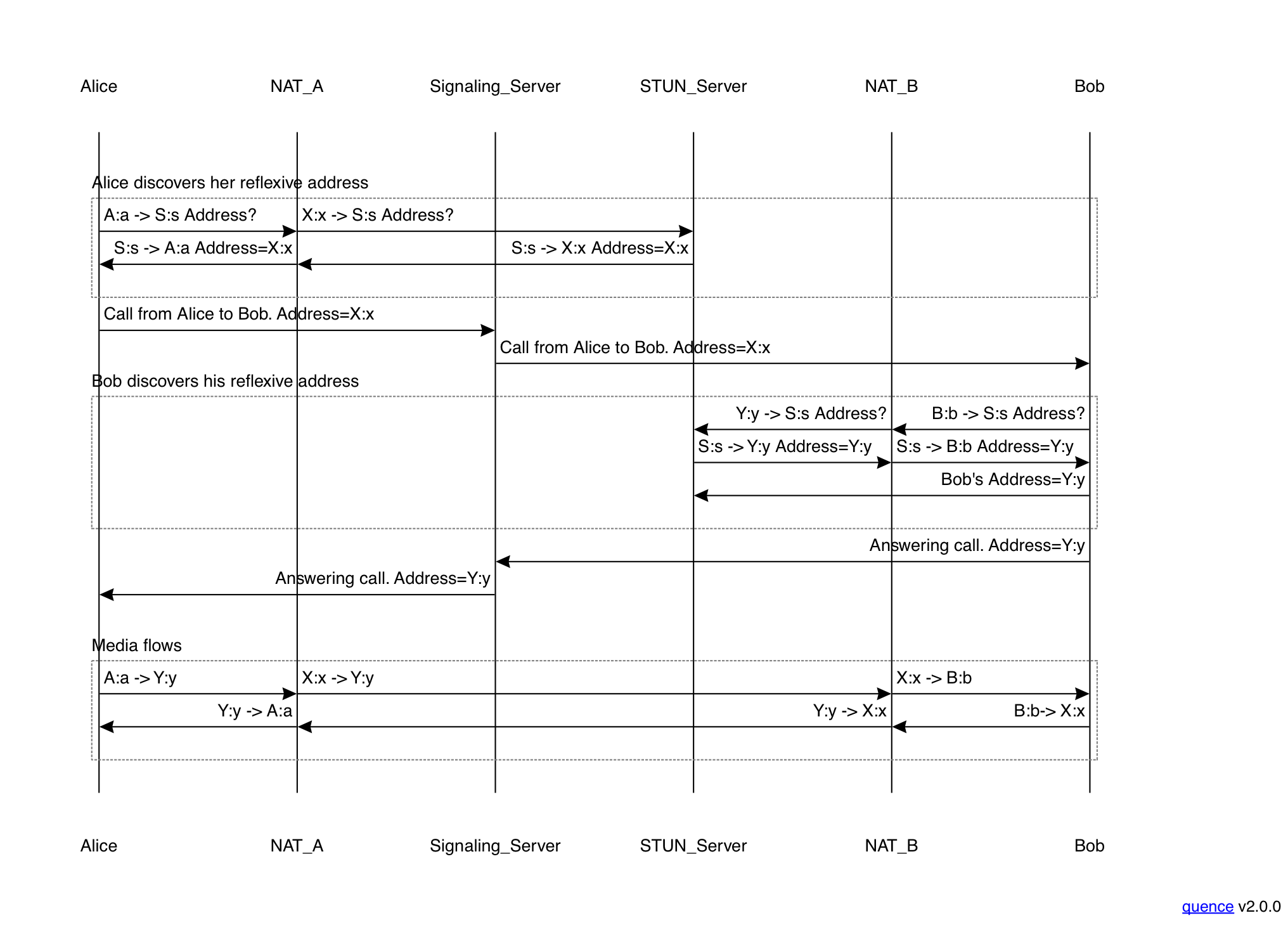
This diagram shows about the simplest possible NAT traversal
scenario. It starts with Alice deciding to call Bob. She uses the STUN
server to discover her reflexive address by sending a Binding Request
from A:a. The STUN server responds with her reflexive address:
X:x. Alice then sends a message to the signaling server to initiate
the call (the details of this depend on whether you are doing WebRTC,
SIP, etc. In SIP this would be an INVITE).
The signaling server notifies Bob of the incoming call. When
he decides to accept it, then he will also contact the STUN
server to discover his reflexive address (Y:y). His response
to the signaling server to answer the call will include this
address. At this point, Alice and Bob know each other's addresses
and can start sending media to each others reflexive addresses,
as shown in the final block. Because the NATs have endpoint-independent
mapping, the same binding will be in effect when the
peer sends a message as they did for the STUN server, even
though the message from the peer comes from a different IP
address. Similarly, because they have endpoint-independent
filtering, the NAT will accept an incoming packet directed
to the reflexive from any source.
This is already a pretty complicated process, but it's conceptually fairly simple: each side discovers its address and sends it to the other side. If all NATs had endpoint-independent behavior for both mapping an filtering, then we could just stop here. Unfortunately they do not.
EIM:EIF ↔ EIM:APF #
Now let's look at the next most complicated case, in which Alice has the same NAT as before, but Bob has a NAT with endpoint-independent mapping but address and port-dependent filtering, as shown in the figure below. To keep things simple, I've omitted the opening phases where each side discovers their address and sends it to the other side, just showing the media phase. Note that the early phases look the same for every NAT type, which is part of what makes things difficult.
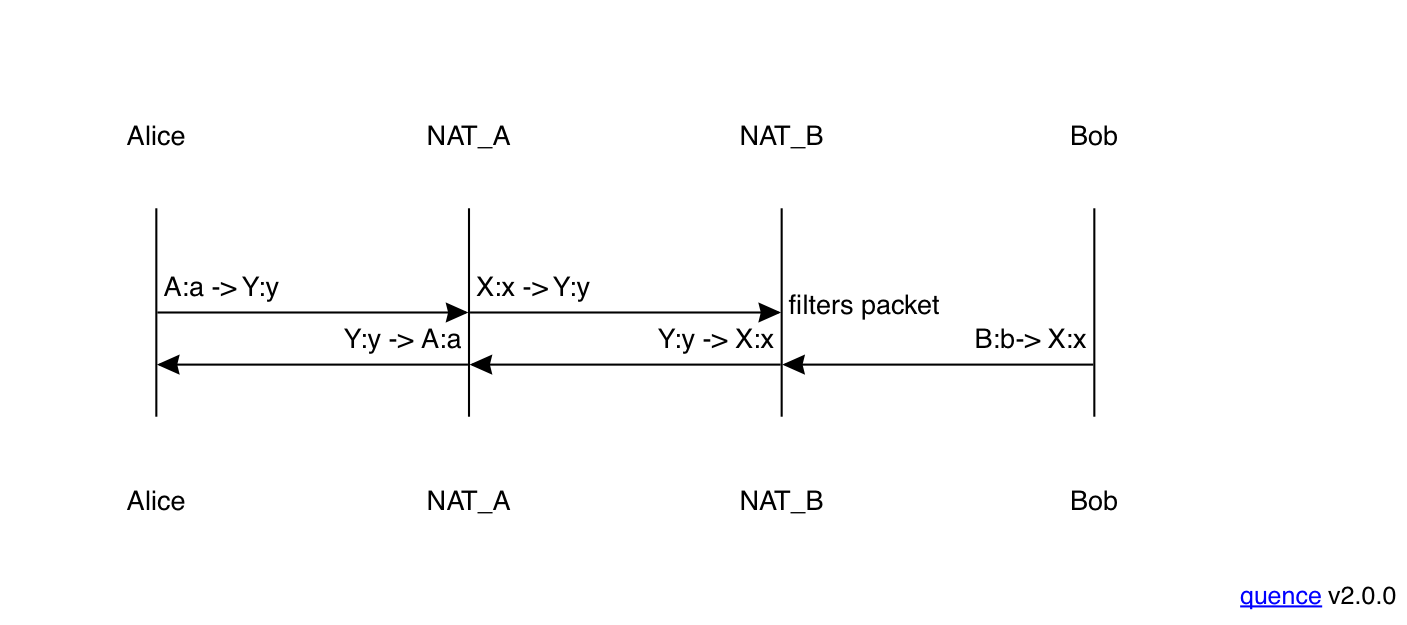
Unlike in the previous setting, when Alice sends her first packet of media to Bob, his NAT discards it. Because Bob's NAT has address and port dependent filtering, it has an access control entry only for the STUN server, but not for Alice's address, so when Alice's packet arrives, the NAT just drops it. By contrast, because Alice's NAT has address-independent mapping and filtering (as in the previous example), the packet is delivered correctly to Alice.
You might think at this point that we're just going to have media flowing one way (from Bob to Alice), but that's not what happens: when Bob sends his first media packet to Alice, it creates a new access control entry in his NAT for Alice's address, so that when Alice's second packet (either a retransmit or reflecting a later part of the media stream) arrives, it is delivered correctly:
From this point forward, you have two-way media.
The following table representing Bob's NAT's state might help visualize what's happening here.
| Event | Mapping | Access Control List |
|---|---|---|
| Start | - | - |
| Address discovery | B:b ↔ Y:y | S:s |
| Packet 2 sent | B:b ↔ Y:y | S:s, X:x |
Initially, Bob's NAT doesn't contain any mappings. After he sends
a Binding Request to the STUN server, the NAT creates a mapping
from B:b to Y:y and an access control entry for that mapping
associated with just the STUN server. Thus, when Alice's packet 1
comes in, it is associated with a valid mapping, but is rejected
because it doesn't match a valid access control entry. When
Bob sends his first media packet (number 2), a new access control
entry is added to the same mapping (recall that Bob can always
send outgoing packets and they just add the appropriate access
control entries). Then when Alice's packet 2 arrives, there is
an appropriate access control entry and it can be delivered.
Obviously, this introduces a little latency before media starts flowing, but given that the Internet is already subject to packet loss anyway, this isn't necessarily that big a deal, especially with voice and video applications which will be sending packets every 20 milliseconds or so. It's potentially a slightly bigger issue for reliable transport protocols if they only send one packet at a time and have long retransmit timers, but even then the connection will eventually be established; it just takes a little while.
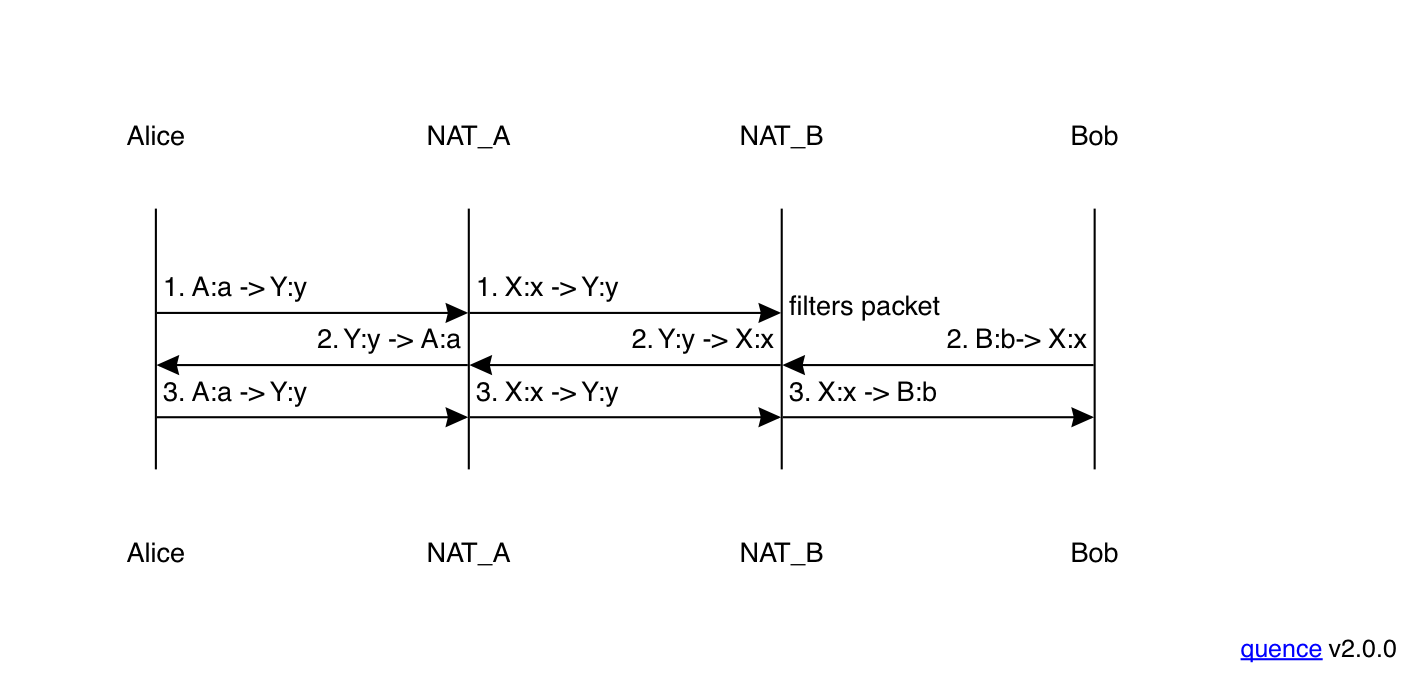
EIM:APF ↔ EIM:APF #
Now let's look at what happens when both Alice and Bob have NATs with endpoint-independent mapping but address and port-dependent filtering. This actually behaves identically to the previous scenario:
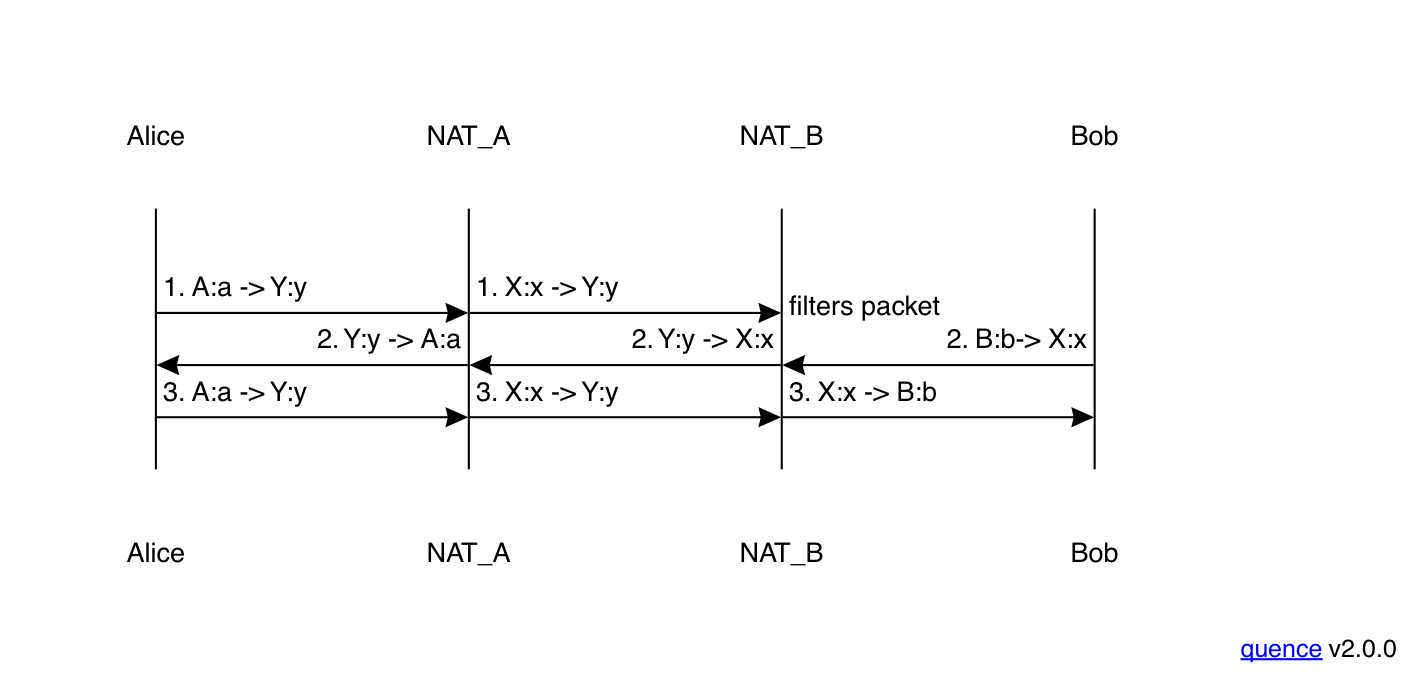
As before, the first packet from Alice to Bob is dropped by Bob's NAT but on its way out it establishes the access control entry in Alice's NAT in the opposite direction, thus allowing the next inbound packet to pass through the NAT. Here's Alice's table:
| Event | Mapping | Access Control List |
|---|---|---|
| Start | - | - |
| Address discovery | A:a ↔ X:x | S:s |
| Packet 1 sent | A:a ↔ X:x | S:s, Y:y |
All of this happens before the first packet from Bob arrives, and so even though Alice does have address and port-dependent filtering, the right access control entry is in place before that packet is received, and so the packet is just delivered.
One important feature to notice about all the scenarios we have seen so far is that they don't depend on knowing what kind of NAT the other side has: Alice and Bob just start transmitting and eventually the right access control entries will be established and the packets will flow properly. Now let's look at a scenario where that isn't true: when one side has address and port-dependent mapping as well as filtering.
EIM:EIF ↔ APM:APF #
Suppose we have a situation where Alice has the address-independent mapping and filtering but address and port-dependent filtering as before, but Bob has both address and port-dependence for both mapping and filtering. This produces the situation shown below:
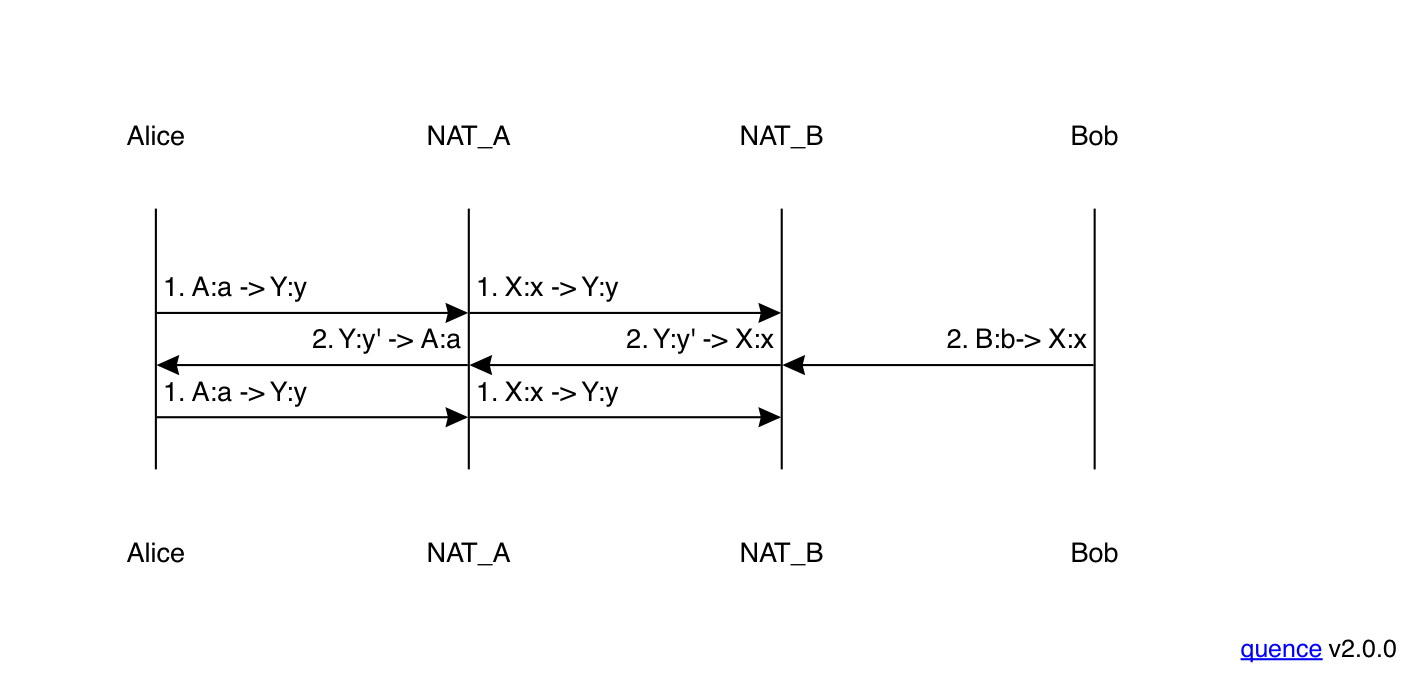
As with the previous scenario, the first packet from Alice to Bob
is dropped by Bob's NAT. This actually happens for a slightly
different reason than in the previous examples. In those, there
was a valid mapping for Alice's packet, but no corresponding
access control entry. However, in this case,
because Bob's NAT has address and port-dependent mapping,
the packet from Alice (X:x) to Y:y doesn't match any
mapping at all.
When Bob sends his first packet (2) to X:x, it creates a mapping
for X:x but on a different outgoing port Y:y'. At this
point, his NAT has the following mapping table:
| Local Address | Remote Address | External (Reflexive) Address |
|---|---|---|
| B:b | S:s | Y:y |
| B:b | X:x | Y:y' |
Packet 2 is still deliverable to Alice because her NAT has endpoint
independent mapping and filtering. However, when Alice sends her next
packet, it still goes to Y:y and not Y:y', and so just gets
dropped. This one-way communication will persist throughout the
connection: every packet Bob sends uses the X:x ↔ Y:y' mapping
and every packet Alice sends goes to Y:y, so none of them will ever
be delivered. Most likely, eventually one of Alice or Bob will
get tired of not being able to communicate and hang up.
This scenario is actually recoverable, but it requires some cleverness on Alice's part. What Alice has to do is look at the source address of packets that Bob is sending her (the peer reflexive address) and if it differs from the one that Bob sent her over the signaling channel (the server reflexive address), try sending packets to that address instead, as shown below:
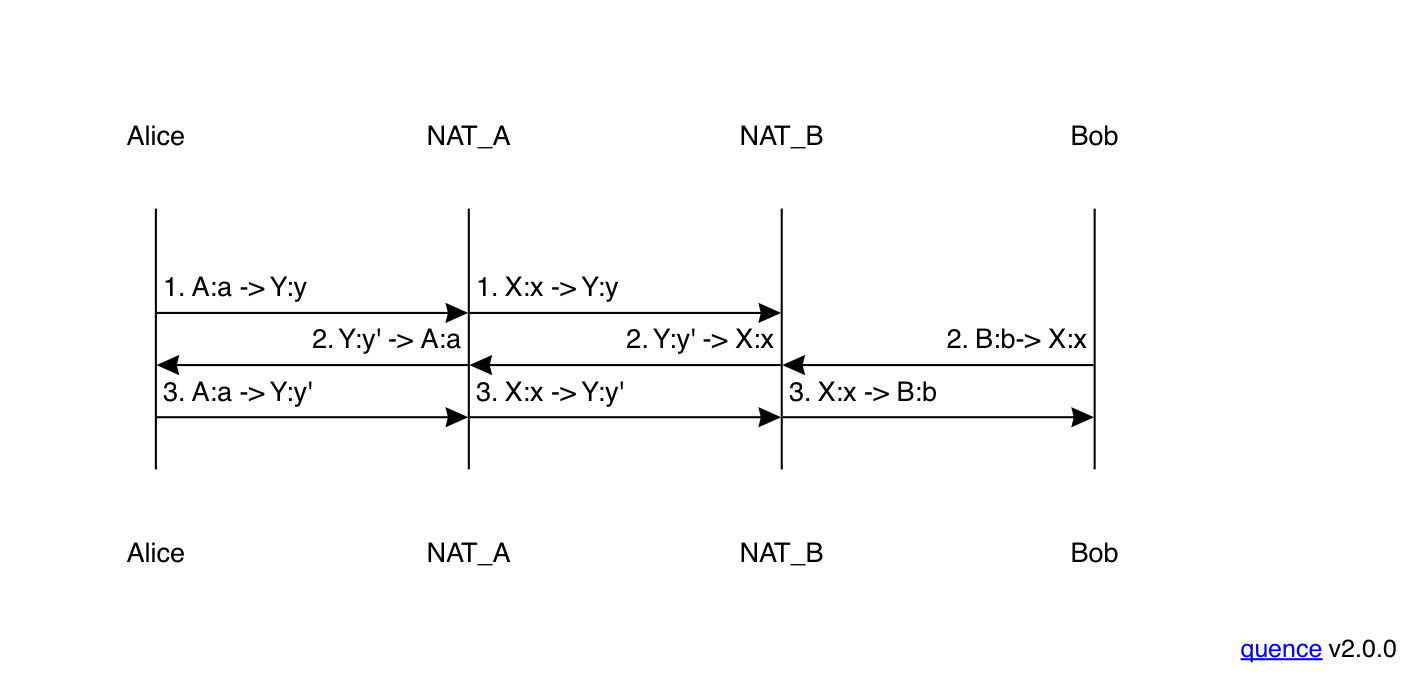
The first two packets here are the same as before, but for the
third packet, Alice switches from sending to Y:y to sending
to Y:y'. This corresponds to a mapping on Bob's NAT (and also
an entry in his access control table) and so the packet will
be delivered as expected. From here on, things work normally.
This technique works, but it requires care to use correctly. For instance, consider what happens if an attacker sends a bogus packet from a different address:
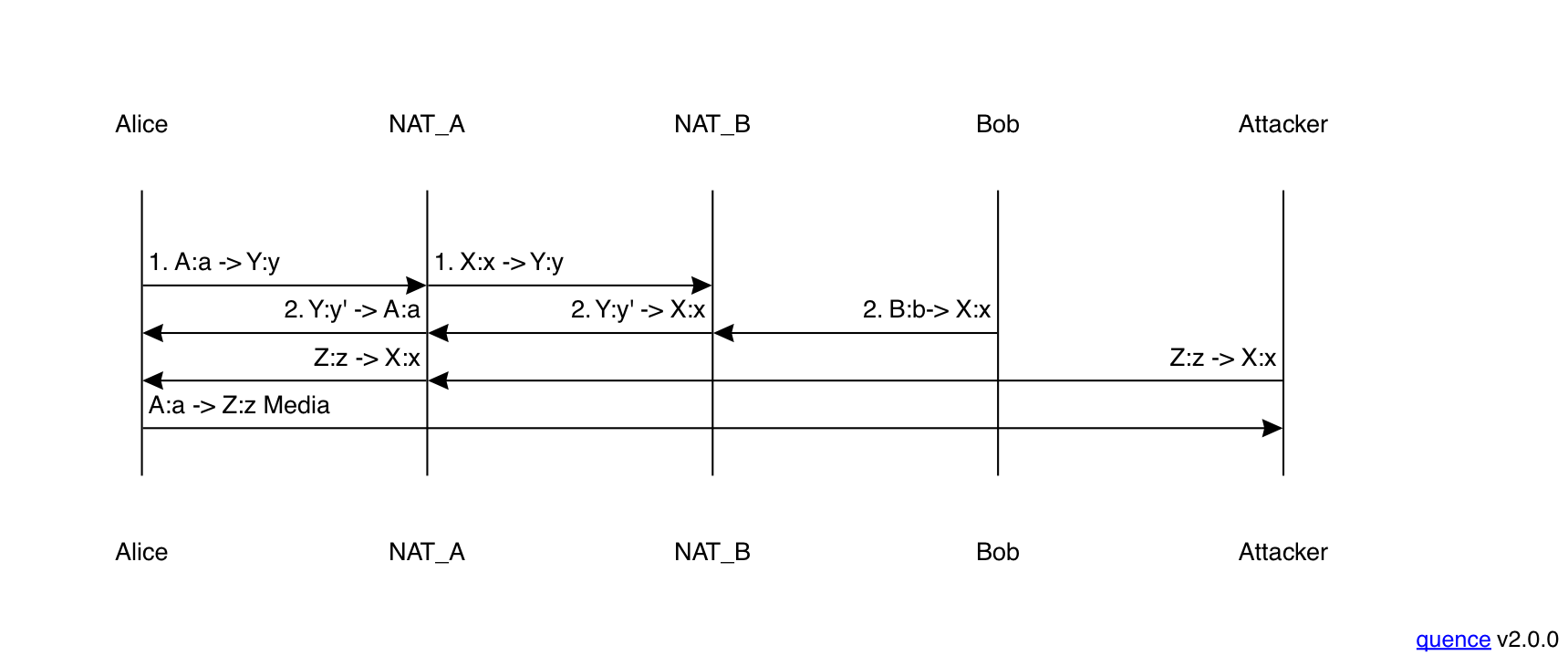
If Alice is naive, she will notice that Bob seems to have switched
his address and just switch to sending to the attacker at Z:z.
Importantly, this attack can be mounted
by an attacker who cannot read packets en route from Alice to
Bob; he just needs to know the address and port Alice expects
packets on.
In the best
case, if encryption is in use, then the attacker won't be able
to read the packets but he will have disrupted the connection. In
the worst case, if encryption is not in use—and when
all this stuff was designed, VoIP encryption was fairly rare—the
attacker will be able to listen in on the Alice → Bob side of the call. Depending on Bob's
NAT configuration (e.g., if it's actually endpoint-independent),
the attacker may even be able to do so without noticeably
disrupting the call, by forwarding the packets to Bob.
There are a number of defense against this form of attack, as
we'll see in the next post.[4]
EIM:APF ↔ APM:APF #
Let's look at one more case, in which Bob has the same APM:APF NAT as before but Alice has a NAT that does address and port-dependent filtering. This produces the result shown below:
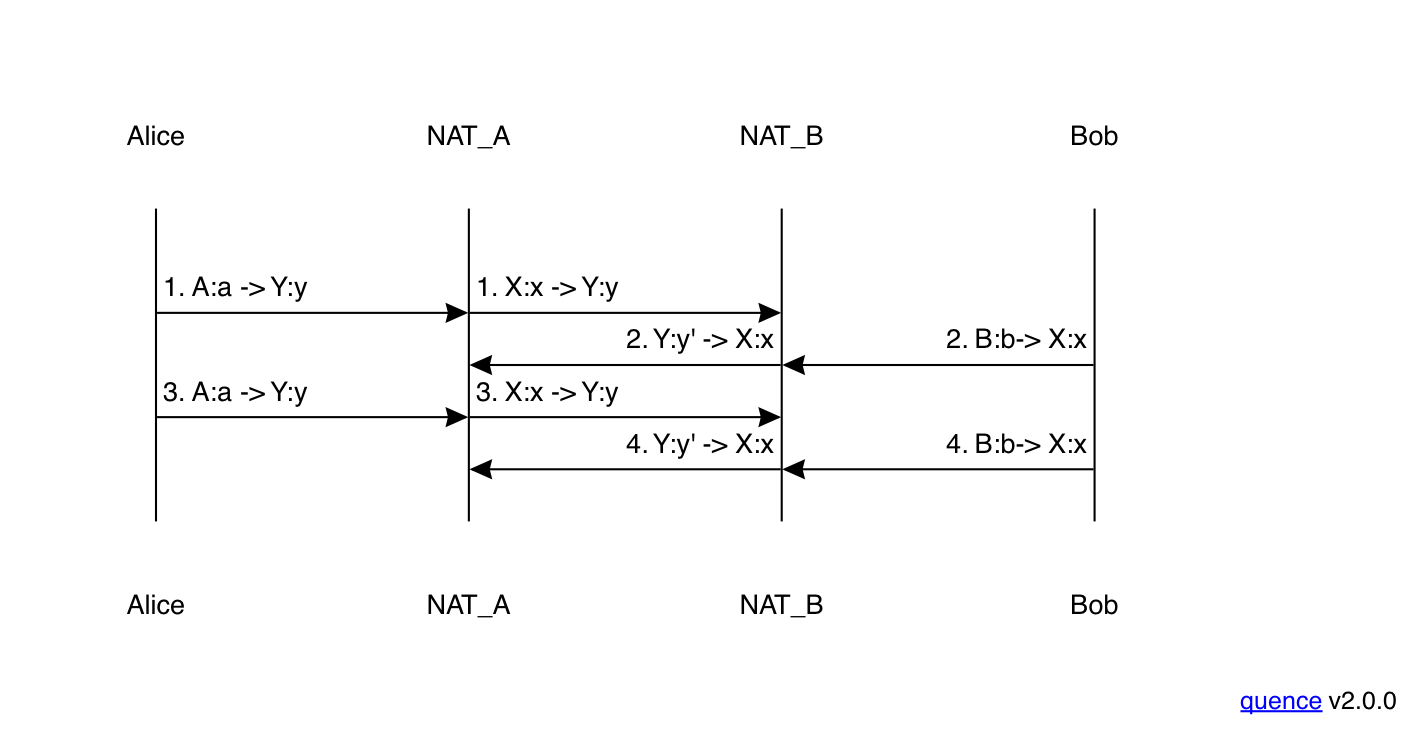
As in the previous example, Alice's packet gets dropped
by Bob's NAT because there is no corresponding mapping
for X:x, only one for the STUN server. However, unlike
the previous example, Bob's packet is also dropped, because
there is no corresponding access control entry. As you'll
recall from above, Alice has the following mapping and
access control entries:
| Mapping | Access Control List |
|---|---|
| A:a ↔ X:x | S:s, Y:y |
However, because the incoming packet is coming from Y:y'
and not Y:y, Alice's NAT discards it. And because
Alice never gets packet 2, she is unable to change the
destination of her packets to Bob's peer reflexive address Y:y'
and so just keeps transmitting packets to Y:y which Bob's
NAT drops because it does not have a corresponding mapping.
Similarly, Bob keeps transmitting packets to Alice,
which her NAT drops because it doesn't have the
corresponding access control entry.
What we have here is deadlock: Bob can't receive packets from Alice until she adjusts the address she is sending to, and Alice can't receive packets from Bob (thus learning about the new address) until she has sent one to the new address (thus creating the access control entry). The result is both sides transmitting and neither side receiving. This is not a recoverable situation.
Relays #
Getting out of this hole requires the use of a relay server. More on this later, but briefly a relay is some server on the public Internet that Bob can send his traffic through. Because this relay is something that Bob explicitly uses and has a relationship with—unlike his NAT, which just does whatever it does—it can have deterministic properties which facilitate NAT traversal. For instance, the most common relaying protocol, Traversal Using Relays Around NAT (TURN), provides endpoint-independent mappings and so effectively fixes the problem we see in this section.
As with STUN servers, it's conventional for the calling provider to provide a TURN server—indeed, they are typically the same endpoint. However, TURN is much more expensive to provide than STUN, so ideally if its possible for two endpoints to communicate without using TURN, you want them to do so. Fortunately, most client pairs can communicate without TURN, so it's still cheaper to operate a calling service that tries to send data peer-to-peer than one that sends everything through a central conferencing server, as long as you use non-TURN where possible. We'll discuss how to do this in the next part of this series.
Hairpinning #
There's one more scenario I want to cover here, which is what's called "hairpinning". Consider the case where Alice and Bob are actually on the same network, as shown below:
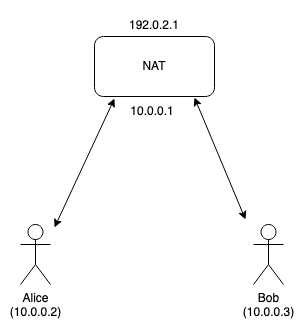
Recall that the NAT has two addresses, the internal address
(10.0.0.1) which Alice and Bob communicate with and the external one
(192.0.2.1) that is used communicate to the outside world. Just as
in the scenarios before, Alice and Bob can connect to the STUN server
and get their server reflexive addresses. For example, Alice might
get 192.0.2.1:1111 and Bob 192.0.2.1:2222 (naturally, these
use the NAT's external address).
The problem comes when Alice tries to send a packet from inside
the network to Bob's external address. If the NAT handles this
properly, it will deliver this packet (technical term: hairpinning)
but some NATs do not do so, and will just drop the packet.
In this case, Alice and Bob will
not be able to communicate.
Of course, Alice and Bob can communicate directly using
their local addresses in the 10.0.0.* space, but it's hard
for them to detect this case because many different networks use
those addresses (that's the point of RFC 1918 addresses, after
all). They could look to determine if they have the same
server-reflexive address, but that might or might not
be a reliable indicator, depending on what kind of NATs are
in use. For instance, Alice and Bob might have their own NATs
but also be behind a carrier grade NAT that causes them
to have the same address. In this case, they will probably
not be able to communicate directly.
Ideally, NATs would properly support hairpinning (this is what RFC 4787 recommends), but, as we've seen throughout this series, NAT behavior is inconsistent and the endpoints have no good way of asking the NAT what it does.

What a mess #
Back in 2003 when STUN was first being developed, the idea was that you would characterize your NAT. RFC 3489 had a whole algorithm you used that involved multiple STUN queries and tried to determine what your network configuration was (remember that you can't ask it any questions, you have to measure). The RFC described a whole menagerie of different NAT types ("full cone", "restricted cone", "port restricted cone", and "symmetric"),[5] with the idea that you would classify your NAT according to one of these types. Based on what kind of NAT you had, you could then provide an appropriate address to the other side—or, in the case of the worst type ("symmetric NAT") potentially declare failure. This turned out not to work very well, in part because the ecosystem was just a lot more complicated than people expected. In the words of the revised STUN RFC:[6]
STUN was originally defined in RFC 3489 [RFC3489]. That specification, sometimes referred to as "classic STUN", represented itself as a complete solution to the NAT traversal problem. In that solution, a client would discover whether it was behind a NAT, determine its NAT type, discover its IP address and port on the public side of the outermost NAT, and then utilize that IP address and port within the body of protocols, such as the Session Initiation Protocol (SIP) [RFC3261]. However, experience since the publication of RFC 3489 has found that classic STUN simply does not work sufficiently well to be a deployable solution. The address and port learned through classic STUN are sometimes usable for communications with a peer, and sometimes not. Classic STUN provided no way to discover whether it would, in fact, work or not, and it provided no remedy in cases where it did not. Furthermore, classic STUN's algorithm for classification of NAT types was found to be faulty, as many NATs did not fit cleanly into the types defined there.
Instead, the IETF devised a solution which was intended to work with any NAT type by the time honored technique of trying a lot of stuff and seeing what works. That solution is called Interactive Connectivity Establishment (ICE), and I'll be covering it in Part III.
They may also be NATted, but that's an operational convenience, because you still need a stable public IP. ↩︎
There are also reasons why centralized videoconferencing systems are good, but that's another post. ↩︎
Except that it it won't be the same as for A, at least for the same server. ↩︎
Note that some of the obvious defenses don't work. For instance, you can't just "latch" to the first packet you see because the attacker might be faster. Similarly, you can't just compare the peer reflexive address to the address Bob sent over the signaling channel because if Bob has address and port-dependent mapping, then the true peer reflexive address will also not match. ↩︎
This was before people came up with this "endpoint-independent", "address-dependent", etc. taxonomy. ↩︎
Which also includes a totally different expansion for STUN. In RFC 3489, STUN stood for "Simple Traversal of User Datagram Protocol (UDP) Through Network Address Translators (NATs)" and now it stands for "Session Traversal Utilities for NAT". The IETF loves its acronyms (and backronyms). ↩︎