Fantastic memory issues and how to fix them
Posted by ekr on 22 Sep 2021
Last week everyone with an Apple device got told they needed to install an emergency update to defend themselves against a "zero-click exploit" that was apparently being used in the wild.
ATTENTION: If you aren't on the latest software, stop reading this and update right now.
The update has fixes for two issues:
- CVE-2021-30860 -- an integer overflow in the PDF parser.
- CVE-2021-30858 -- a user-after-free vulnerability in WebKit (Apple's Web engine)
Apparently both of these can lead to what's called remote code execution (RCE) which means pretty much what it sounds like -- the attacker gets to run their own code on your device -- and were being actively exploited. It's not just Apple either: On the same day Maddie Stone from Google Project Zero tweeted about Chrome fixing two vulnerabilities of their own, an out-of-bounds write and a use-after-free (thanks to HelpNet's article for the links here.)
While the precise details of these issues vary, they're all (with the potential exception of the integer overflow, but probably that too) what's called "memory safety" issues. These are generally quite bad and often lead to RCE, and unfortunately they're also quite common; pretty much any complicated piece of systems software regularly has to release fixes for memory safety stuff. The rest of this post provides an overview of what's going on and what we can do about it.
What's a computer's memory anyway? #
In order to understand what's going on, you need to first have some idea of how computer software works. Feel free to skip this section if you already know this stuff. At the very highest level, a computer looks like this:
The central processing unit (CPU) is responsible for actually running the programs you load onto the computer (e.g., adding numbers up, drawing stuff on the screen, etc.) It does that by reading those programs from the computer's memory. A program is just a series of instructions that the CPU should follow.
The computer's memory is effectively just a giant table of numbers. Each location in the table is pointed at by a memory address which is just a number that tells you where it is in the table. Addresses are laid out in the obvious way so that the stuff in address 2 is right after the stuff in address 1, etc. For instance, we might have the following program, with the numbers on the left being the memory address and the text being the thing to do (the technical term is "instruction"). Note that I'm taking a lot of liberties here: the instructions aren't in English but are just numbers and each memory address is the same size, so you couldn't fit "Hello" and "Goodbye" in the same size place, but we can ignore those issues for now.
001 Write("Hello")
002 Write("Goodbye")
003 Exit
Normally, the instructions are read in sequence, so this program would print out "Hello", then print out "Goodbye", and then exit.
This is all fine if you only want to write really boring programs, but if you want to write interesting programs, you're obviously going to need some more stuff. In particular, you're going to want to do two things:
-
Store temporary data (e.g., pictures, text, etc.) somewhere so you can work on it.
-
Have the program exhibit conditional behavior rather than always running the same instructions in the same order every time.
For example, here's another simple program that counts from 1 to 100.
001 Store(50, 0)
002 Write(Data(50))
003 If Data(50) = 100 go to 6
004 Store(50, Data(50) + 1)
005 go to 2
006 Exit
This is a little harder to read because I was struggling a bit with
the notation. The basic idea here is to use memory location 50 as a
counter. Line 1 says "put the value 1 in memory location 50".
Data(50) refers to whatever is in location 50 and so line 2 says
"Write whatever is in 50". Line 3 checks to see if the counter is at
100 and if so goes to line 6 which eventually exits the
program. Otherwise, line 4 increments the counter by 1. Then the
program goes to line 5 which sends it
back to line 2.
The most important thing to note here is that the program and its
data share the same memory, so whether a piece of memory is a program
or data is just a matter of convention. For instance, if the
computer gets hit by an ill-timed cosmic ray and line 5 gets
changed to go to 50 then the CPU would diligently jump
to memory address 50 and try to interpret whatever was
there as an instruction (remember, it's all numbers anyway),
This is what's called
a Von Neumman Architecture
and it's how nearly all computers work. The alternative,
in which programs and data are separate, is called a
Harvard Architecture.
It's unusual to have a modern computer with a Harvard Architecture,
but actually that's kind of bad for reasons we're about to see.
Although from a hardware perspective the memory is undifferentiated, there is a conventional way to lay things out, as shown in this diagram I borrowed from Geeksforgeeks:
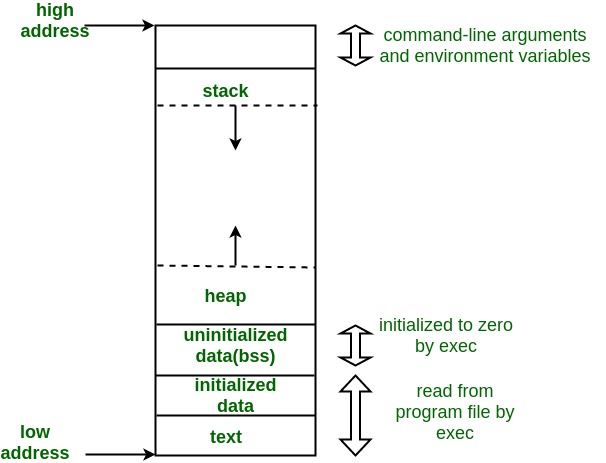
To orient yourself, address zero is at the bottom of the diagram and higher addresses are at the top. The program is actually split up into two pieces: the program itself ("the text segment")[1] and its data ("the data segment).[2] There are also two different parts of memory where the program's data is stored call the "stack" and the "heap". I'll get to them shortly.
Remote Code Execution #
The core thing that allows for memory safety issues to arise is this intermixing of the program and its working data into the same memory region, Here is a very silly program which shows what I am talking about:
001 Read(10)
002 go to 10
What does this program do? It reads some stuff from somewhere (the Internet?!!!) into memory location 10 (again, I'm pretending that these can just be arbitrary sized) And then it goes to (the technical term here is "jumps") to location 10 and then starts executing whatever it read--from the Internet!--as a program instead of whatever program was originally loaded. And if that program that you just loaded does something dangerous like deleting all your files or causing your computer to explode, well that's what happens. This is what we mean when we say "remote code execution": your computer is executing the code that some remote person sent it.
At this point you could be forgiven for asking why anyone would write a program that did this, and even though I said it was silly, this is actually something Web browsers do a lot: Web pages are just little (or big) programs and the browser's job is to load and run those programs, although for obvious reasons they don't do it this directly. [3] But what does happen is that the program you are running has defects (vulnerabilities) that allow the attacker to execute code on your computer without having such an obvious problem as this program.
There are a large number of possible ways to have this kind of defect, and I'm just going to explain one, though it's a classic: the buffer overflow.
Buffer Overflows #
Unlike the trivial programs I've been showing above, real programs are written as a set of subroutines, which is just the jargon for an independent piece of code that that does something and can run on its own. For instance, suppose that I want to write a simple program that reads strings from the keyboard and then echoes them back. In the C language, this program might look something like this (though of course it's eventually converted into a set of machine-level instructions as described above).
void read_print() {
char temp[8];
gets(temp);
puts(temp);
}
puts("Enter string 1\n");
read_print();
puts("Enter string 2\n");
read_print();read_print() is a subroutine (thouch C calls them "functions).
It can be invoked ("called") from anywhere else in the program and
will do whatever it's supposed to do and then "return" back to
where it was. The syntax for this is just to write it with
parentheses, like read_print().
So, in this case, when you call read_print() the
first time, it reads a string, then prints it, and then goes to the
next line, which prints Enter string 2. By the way, gets()
and puts() are also functions: gets() reads from
the keyboard and puts() writes to the output. These
functions are built into the C standard library.
Unfortunately, this program has a bug. In order to use the gets()
function, you need to tell it where you want it to stuff whatever
it is reading from the keyboard, which means passing it some memory
location. The line line char temp[8]; allocates a region
of memory (a buffer) of size 8 and then we pass it to gets().
But what happens if someone types more than 8 characters at the
keyboard?[4]
Nothing good! Because gets() does not know how long
the memory region is, it just keeps writing stuff, overwriting
whatever happens to be there already. This is what's called a
buffer overflow and it's really bad news. Buffer overflows
are one of the main kinds of vulnerability that eventually
leads to program compromise.
Smashing the Stack #
I don't want to get into too much detail about how to exploit a buffer overflow, but I'm just going to give one example of how this can happen, the classic smashing the stack attack described by Aleph One in Smashing the Stack for Fun and Profit, setting off two waves, one of exploitation and one of papers describing how to do X "for fun and profit". In order to understand the stack overflow, you need to understand a little more about how programs are laid out in memory. When you make a function/subroutine call, the computer needs to remember which memory address to go back to when the function completes ("returns"). In order to do this, it stores that information in the stack area of memory. For instance, suppose I have the trivial program:
void bar() {
puts("I am bar");
}
void foo() {
puts("Start of foo");
bar();
puts("End of foo"); // Will go in memory address Y
}
puts("Before foo");
foo()
puts("After foo"); // Will go in memory address XNote: the // means a "comment", a section of code that doesn't
do anything, it's just there to help you know what's
going on.
At the start of the program, the stack is more or less empty[5]
Then when we call foo() the stack now contains the
address of the line of code after we called foo, which is
to say X, like this:
+-+-+-+-+-+-+-+-+
| X |
+-+-+-+-+-+-+-+-+
I've done something a little sneaky here, which is that I've drawn
this to scale, with the address taking up 8 "units" with
each little +-+ representing one unit. This matches
the size of addresses that most modern machines have. Each
little +-+ represents one unit.
Then when foo() calls bar(), we have to add the
address of the line after the call to bar() on
the end, so it looks like this, with memory addresses
going up as we go left to right.
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| X | Y |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Here's the thing, though: the stack isn't just used to store
the return address, it's also used to store memory that's
just used by the function being executed. So, if we go back
to our read/print program above, when the computer calls
the read_print() function, the stack looks
like this:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| buffer |1 2 3 4 5 6 7 8|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
^
return address
If we read a short string into the buffer, say "hello", then we get something like this, with each character filling one memory unit for a total of 5.[6]
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|h e l l o |1 2 3 4 5 6 7 8|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
^
return address
However if instead the user types in something longer, like "hello world!", then the computer will just happily keep writing into the return address because it doesn't know how long the buffer is, like so:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|h e l l o w o|r l d ! 5 6 7 8|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
^
return address
When the function is finished, instead of jumping back to where it's supposed to (the line of code right afer the function was called), it will jump to whatever the attacker has stuffed in the return address, which, obviously, is bad. For extra credit, the attacker can use the buffer overflow to write the code they want executed into memory somewhere (maybe in the buffer itself, or maybe after the return pointer) and then jump right to it. Mission accomplished: remote code execution.
How did this happen? #
The core problem here is actually quite simple:
C is a horrifically dangerous language that encourages you to write bad code (C++, too)
The situation is actually fractally bad. At the first level, we have the fact
that a lot of the original C library functions are awful.
The design of the gets() function is a great example here. Because gets()
has no way of knowing how much memory it has to work with, there is simply
no way of using gets() safely. Here's what the manual page for gets() says:
The gets() function cannot be used securely. Because of its lack of bounds checking, and the inability for the calling program to reliably determine the length of the next incoming line, the use of this function enables malicious users to arbitrarily change a running program's functionality through a buffer overflow attack. It is strongly suggested that the fgets() function be used in all cases. (See the FSA.)
The replacement function recommended here fgets() is slightly better, in that
it allows you to pass a length value, but of course it's possible to get the
length wrong at which point you're back in the soup. And because
code is written by people, if you have a lot of coude you probably have
a lot of bugs.
Even if you eliminate the unsafe library functions -- and there are checkers you can get which will detect them and stop you -- C is still really hard to use correctly. Another source of problems is that C actually requires you to manage memory directly. Suppose that you want to read some data from the network but you don't know how long it's going to be. For instance, it might be in "length-value" format where the first thing you read is the length and then you read that much data. In this situation, the idiom we used above of just having a fixed-size buffer won't work: any value you choose will be too short some of the time[7] and if you choose a really long value you are wasting memory.
In C, the way you handle this is that you can allocate a block of memory of a given size (this goes in the heap region) and then use it to store data in. When you're done with the memory, you then free (deallocate) the memory so that it can be allocated again for some other purpose. Now, what happens if you have a bug in your program where you use the memory after it is freed (this happens surprisingly often in complex programs)? The answer is that you have what's called a use-after-free bug (remember I said that above?) and this can often be exploited to compromise the program.
Unfortunately, because C is fast and portable (i.e., you can write C for a lot of different kinds of computers), it is used all over the place and so we have giant piles of code written in C or its descendent, C++. Much of this code has undetected memory safety issues just waiting to be exploited, which brings us back to our main story.
Fixing Memory Safety Issues #
There are a number of different approaches to fixing memory safety issues, some of which have been more successful than others.
Fix all the issues #
One thing you might think you could do is just fix all the defects, potentially with the assistance of tooling that detected them. Unfortunately, while fixing any particular defect is generally difficult, there are such a large number of defects and they are so difficult to find that I don't think anyone thinks that this is a practical approach.
Memory-Safe Languages #
The second major approach is to write in a "memory-safe" language. For a long time, C/C++ (and on Apple platforms, Objective C) were the only game in town for systems programming.[8] While C++ and Objective C have some mechanims to let you write somewhat safer code, it's still quite possible to shoot yourself in the foot unless you're very careful to follow a strict subset of the language (and arguably not even then).
There certainly have been languages that let you write "memory-safe" code in which it was difficult or impossible to write the kind of defects I was showing above. Typically the way this works is that you're not allowed to handle raw memory like you do in C. For instance, instead of just having a "block of memory of unknown size" you might have a "higher-level" abstractions like "block of contiguous memory of size X" and the language would forbid you from reading or writing outside of that block. However, for a variety of reasons (principally rooted in real or fake performance concerns), these languages have never really taken off for systems programming until relatively recently. Probably the closest is Java, which saw a bunch of use for enterprise software but wasn't really that successful for end-user applications like operating systems, word processors, and the like.[9]
Over the past 5-10 years, however, two new languages have emerged that are getting real traction in this space:
Both of these are memory safe and occupy a similar niche to C/C++. with Rust probably being a closer match and Go being a little more like Java. It's credible to write a new piece of systems software in either language and even to integrate it with a code base written largely in C/C++ (this part works somewhat better with Rust than with Go).
While a very important tool, Rust and Go aren't really a general solution because we have huge amounts of code already written in C and C++ and it's very expensive to rewrite. There's been a lot of energy in the Rust community behind this kind of rewrite (so much that "rewrite it in Rust" is a catchphrase) but realistically and while there have been some successful projects, it's hard to see any major software system being replaced with a Rust version any time soon, though of course we might see new replacement programs written in Rust displace their older counterparts just through the normal process of new product/software development. As a practical matter this means that we're going to be living with software with memory safety issues for quite some time. For this reason, there has been a lot of focus on containing the damage.
Anti-RCE Countermeasures #
The past 20 years or so has seen a long series of countermeasures designed to prevent RCE, or at least make it harder, including:
A number of processors have hardware support for anti-exploitation mitigations, such as the NX bit, Intel CET, or ARM PAC.
Generally, these techniques are not designed to actually prevent memory issues such as buffer overflows (if you're going to work in C this turns out to be quite difficult), but rather to prevent them from being easily exploited. Unfortunately, there has also been a long series of attack techniques (e.g., return oriented programming) developed to defeat these countermeasures, resulting in a never-ending arms race of attack and defense which is good news for computer security researchers but perhaps less good news for users. I don't want to leave you with the impression that these techniques don't do anything: they do make exploitation harder but at the moment sophisticated attackers seem to usually be able to defeat them. Some--though not all--of the problem is that the strongest techniques have a very negative performance impact and developers have been generally unwilling to accept that.
Process Separation + Sandboxing #
The industry standard approach for addressing this kind of memory issue is to just accept that you will have insecure code and that it will get compromised (including RCEs) and focus on limiting the damage that the code can do. The general procedure is as follows:
- Take the most dangerous/vulnerable code and run it in its own process (process separation)
- Lock down that process so that it has the minimum privileges needed to do its job (sandboxing)
- If the process needs extra privileges have it talk to another process which has more privileges but is (theoretically) less vulnerable.
For instance, in a Web browser the most dangerous code is the stuff that talks directly to servers, such as the HTML/JS renderer. In modern browsers, the HTML/JS renderer runs in its own process that has very limited capabilities (e.g., it cannot talk directly to the network). This strategy was introduced in SSHD and then adopted for browsers by Chrome but has more or less been universally adopted in browsers -- as well as a similar mechanism in iMessage called Blastdoor -- and while reasonably successful is not a panacea. What it mostly means is that an attacker needs to not only attack the vulnerable process and get an RCE but then use that to attack the higher-privileged process or otherwise get out of the sandbox (e.g., with an operating system vulnerability), which still happens reasonably often.
The more serious problem with this kind of approach is that it's very expensive, both operationally (processes aren't free) and to implement (disentangling all that code is hard). This means that every time you want to sandbox some new piece of code it's a lot of work and so even after years of this approach the major browsers still only have relatively few different sandboxed components.
Software Fault Isolation #
Over the past few years, Firefox has been working with a new hardening strategy developed by researchers at UCSD, the University of Texas, and Stanford. This system, called RLBox, is on more sophisticaed software fault isolation techniques and is designed to provide a similar if not greater security level to operating system sandboxing while being much lighter weight, both in terms of implementation and operation.
RLBox has two major pieces:
-
A system that allows you to run a specific software component in a lightweight sandbox.
-
Wrapper tools for checking the output of the components.
The second of these is a bit out of scope for this post, but the first is quite interesting. The general idea is to compile the original code (written in C or whatever) into WebAssembly and then into machine code. This process doesn't prevent all memory issues but instead ensures that the code can't read or write outside its own memory and also that it can't jump to other parts of the program. It does not ensure that attackers cannot change the execution path of the program, though the attacks are not quite as good as with native binaries, but because of the Web Assembly compilation process their influence is confined to the sandboxed component.[10]
The nice thing about RLBox is that it's very easy to convert existing code. Because RLBoxed code runs in the same process as the code which uses it, it's a relatively simple matter of wrapping the RLBoxed function calls using the RLBox wrapping tools. Depending on the size of the code -- really the number of functions that you used the RLBoxed component -- this can take a few hours or a few days, but is generally pretty easy. Firefox already has a number of RLBoxed components including the Graphite font library and the hunspell spelling library with several more underway.
Summary #
Memory safety issues are likely the most severe class of software vulnerabilities. Unfortunately, they're also extremely common and not going away any time soon. We have a variety of techniques that can be used to help mitigate their effect and each has their place but none of them is sufficient alone.
Yes I know these names are ludicrous ↩︎
Incidentally, this is how you get around the problem I mentioned earlier of stuff not being the same size. You put the string "Hello" in the data segment and then just have the
Writeinstruction use the memory address of wherever you put it. ↩︎You shouldn't feel too good about this because it's absolutely the case that people have defined mechanisms to load and run arbitrary code people sent them off the Internet, but it's also not a good idea. ↩︎
The way
gets()works is that it reads until someone hits the return/enter key. ↩︎It probably actually has a function called
main()on it, because C programs start with that function, but we can ignore that. ↩︎Technical note: I'm omitting the
\0line ending thatgets()uses because it just confuses things right now. ↩︎Mostly, that is. Unless you restrict the length values somehow. ↩︎
This is kind of an ill-defined term, but roughly it means stuff that has to be low-level and relatively fast like operating systems and Web browsers. ↩︎
One very notable exception is that Android apps are generally written in Java or Kotlin, another language that runs on the Java platform, even though much of Android is still C/C++. ↩︎
The original work on RLBox used Google's really cool Native Client (NaCl) technology for safely running arbitrary binaries, but was transitioned to WebAssembly because Google stopped maintaining NaCl and Firefox already had extensive WebAssembly support. ↩︎