First impressions of Web5
Interoperability is hard
Posted by ekr on 13 Jun 2022
Recently Jack Dorsey announced a new project called Web5 which is billed as "an extra decentralized web platform". I've now had time to take a look at the pitch deck and some of the specifications. This post provides some initial impressions.
Overall Idea #
Although Web5 bills itself as for the "decentralized Web", it seems to be addressing a somewhat different set of applications than those I explored previously (helping to make the case that "decentralized Web" is an unhelpful term). In that post, we mostly looked at the problem of how one could publish Web sites and apps without having to use some kind of centralized service. Web5, however, seems to be trying to solve the problem of how to use various Web services (e.g., Spotify or Twitter) while still maintaining control of your data. To that end, the site lists two main use cases:
Control Your Identity Alice holds a digital wallet that securely manages her identity, data, and authorizations for external apps and connections. Alice uses her wallet to sign in to a new decentralized social media app. Because Alice has connected to the app with her decentralized identity, she does not need to create a profile, and all the connections, relationships, and posts she creates through the app are stored with her, in her decentralized web node. Now Alice can switch apps whenever she wants, taking her social persona with her.
Own Your Data Bob is a music lover and hates having his personal data locked to a single vendor. It forces him to regurgitate his playlists and songs over and over again across different music apps. Thankfully there's a way out of this maze of vendor-locked silos: Bob can keep this data in his decentralized web node. This way Bob is able to grant any music app access to his settings and preferences, enabling him to take his personalized music experience wherever he chooses.
The system defines a number of technical components to address these use cases.
Decentralized Web Nodes #
The core idea seems to be that instead of storing your data on the service, you instead store it in a Decentralized Web Node (DWN), which is a network element that is somehow associated with you and that you trust with your data. When services want to use your data—for instance, when Spotify wants to look at your playlist—they contact your DWN and request it. Because the data is stored on your DWN, you nominally control it and how it is used. In other words, this is a federated system.
The diagram below shows the main idea:

In a conventional Web application, each site has its own storage, typically some kind of database (see here for an overview of this kind of Web app). The site stores all of your data/state and you don't have any real access to it. In Web5, each Web site will instead store its data on your DWN. This gives you access to and control of the data but also in theory means that it's portable and/or shareable. For instance, if you want to change from using Spotify to using Apple Music, you just give Apple access to the playlist data on your DWN—and, I suppose, revoke Spotify's access. It's also intended to allow multiple sites concurrent access to the data. There certainly are use cases where this would be valuable, for instance, sharing your travel reservations between Kayak and TripIt.
Note that this kind of element isn't a new idea. For instance Tim Berners-Lee's Solid project has a very similar concept called "Pods":
Solid is a specification that lets people store their data securely in decentralized data stores called Pods. Pods are like secure personal web servers for data. When data is stored in someone's Pod, they control which people and applications can access it.
Of course the technical details of Web5 and Solid are completely different (for instance, the APIs are different and Web5 is based on DIDs whereas Solid uses OIDC for authentication[1]) but at the big-picture level these ideas seem to be pretty similar.
More generally, the basic idea of Bring Your Own Storage (BYOS) is quite old. Prior to the great Webification of everything—closely followed by the mobile appification of everything—this is how applications were generally built: you would have some network protocol like IMAP (for mail) or CalDAV (for calendaring) that everyone implemented, you would sign up for an account with a service, and then separately download a client. You could switch clients at any time because the whole system was interoperable.
One thing that the Web5 documentation is pretty vague on is where the DWNs come from. What I mean here is not the code (they have some open-source implementation you can download) but the server. It's important to recognize that this system depends on trusting the DWN. Although there is some cryptography the primary security and privacy protections are provided by the DWN doing access control and so this isn't something you can just run on some totally decentralized system. I think it's a safe assumption that most people aren't going to run their own physical DWN server—the inconvenience of that sort of thing is what kicked off our current round of centralization—so we need some other alternative. I guess the idea is that there will be some DWN service that you can subscribe to like you do with Dropbox or gSuite, but it would be nice if the plan here were clearer. There's also some stuff in the spec about how DWNs should be based on IPFS, but I don't really understand that at all. As far as I can tell, how the DWN stores data should be largely invisible.
Data Model #
A DWN mostly presents a fairly generic data storage interface, with two main concepts:
-
Collections of objects attached to a given JSON "schema" (i.e., a definition of the elements that need to appear in a JSON object, such as a playlist).
-
Threads of messages attached to each other. It's not entirely clear to me how these are supposed to work, but the idea seems to be to provide a generalized peer-to-peer messaging facility (the slide deck says "send and receive messages over a DID-encrypted universal network").
- There's also the concept of Permissions
- an entity can request access to a given set of objects (such as a collection) and the owner of the DWN can grant and revoke access.
I won't want to spend too much time on the details here other than to say that this whole part of the system seems fairly thin and would probably benefit from engaging more with prior work. For example, WebDAV provides a fairly sophisticated data management and access control model that is quite a bit more advanced than that presented here, including hierarchical collections, locking, metadata, and access control lists. This isn't to single out WebDAV as ideal but merely to observe that there's a lot of prior art in terms of what kind of capabilities distributed data stores need and my sense is that what's presented here is largely insufficient. As a specific example, real data stores need some way to deal with conflict resolution and concurrent editing—especially if you have multiple uncoordinated applications writing to the same data, and Last-Write Wins, which is the only specified mechanism, is really not enough.
Similarly, the whole threads concept seems pretty underspecified. If the idea is to provide some kind of generic secure messaging structure, there's a lot more to do here than just encrypt to people's DIDs—which I think is how it is supposed to work. Modern secure messaging systems like IETF Messaging Layer Security (MLS) incorporate a whole bunch of security and interoperability features (e.g., ratcheting).
My point isn't that these are fatal flaws—all of these are details which could in principle be fixed—but rather that building a system like this correctly is very complicated and that there's a big difference between what we've seen so far and a real system. Moreover, the fact that this initial specification is so incomplete should not inspire confidence that it can be turned into something as generic as it seems to aspire to be.
Distributed Web Apps (DWAs) #
The other big idea here is that apps will be written as what the document calls Distributed Web Apps (DWAs). This part is pretty handwavy, but the basic idea seems to be that they are an extension of what's called a Progressive Web App (PWA). PWAs are a sort of confusing topic, but at a high level, a PWA is a Web app that has been designed to act more like a native app. This means things like:
- An icon on the home screen
- Working offline
- Storing data on the client (this is required to work offline)
While PWAs run in the user's browser, they still ultimately depend on
the main Web site for their data and potentially for some of their
logic. It seems that a DWA will instead directly access the DWN
to get the user's data, but under the authority of the site.
So, for instance, if you granted example.com access to your
music playlists, it could either contact the DWN directly or empower
the DWA to do it directly from your browser. The technical details
here are a bit fuzzy, but this also seems pretty clearly doable via
some combination of tokens, delegation, etc.
so I don't think we should worry too much about that.
DWAs seem like kind of a separable idea from DWNs. Looking at PWAs, we see that some sites build native apps and not PWAs, some build both, and some build neither (my impression is that it's quite uncommon to build just a PWA); it's really a design choice by the site. Similarly, if you managed to make the shift from site-based storage to DWNs, I would expect sites to do some combination of native apps, DWAs, and regular Web sites based on what worked best for them (there's no reason why DWNs can't be used with native apps, even though that's not how it's presented). I don't think DWAs make or break the vision of Web5.
DIDs #
Finally, I should mention that all the identities in Web5 are phrased as Decentralized Identifiers (DID) (see here for some background on DIDs). At some level, this is just a detail: you need some way to talk about principals, there are a lot of potential options here, and DIDs are entirely generic.
In order to participate in Web5, the DID document has to contain
DecentralizedWebNode service endpoint that contains one or
more HTTPS URLs, like so:
{
"id": "did:example:123",
"service": [{
"id":"#dwn",
"type": "DecentralizedWebNode",
"serviceEndpoint": {
"nodes": ["https://dwn.example.com", "https://example.org/dwn"]
}
}]
}[Source: DWN specification]
Note that because the security of this system depends on the security of the DWN, and the DWNs, and the DWNs are accessed over HTTPS, this means that the security of this system depends on the DNS. This means that the security value you are getting out of generic DIDs is somewhat limited. The cost of supporting generic DIDs is the interoperability risk of having a DID method that isn't supported by one of the services you want to use. As a practical matter, if Web5 takes off, I'd expect those services to mostly converge on a small number of methods.
How to present new technical proposals #
As an aside, the way Web5 is presented requires a fairly large amount of filling in the blanks. Basically we have a Web site, a slide deck with an overview of the system as a whole, and then some detailed protocol specifications and code on Github. This is all fine, I guess, but what's really needed is a document describing the system architecture, how the technical components fit in, and how it meets the use cases. Over the years I have reviewed a lot of early-stage specifications and the details of those specifications rarely matter, as they usually get extensively revised during development and standardization. What's necessary at this stage is to give readers enough of an understanding of your overall vision that they can see how it's going to work, figure out if it's worthwhile, know how you've solved the hard problems, and know what problems remain to be solved. Too many details actually gets in the way of that, and a slide deck like this is way too high level. What's required is a document describing the system architecture. My put on how to write these is found in RFC 4101, but there are obviously lots of ways to do that. But a slide deck isn't it.
Building a Full System #
I said a number of times above that this is pretty thin on details. That's not uncommon with early stage proposals, but can make it very hard to assess the viability of the ideas because you don't know what's hiding behind the vagueness. Things can be vague for at least three major reasons:
-
It's obvious how to fill them in but someone needs to do so. For instance, you are pushing around JSON and so you'll need some formal definition of the contents. Nobody thinks that's impractical, but it's just work.
-
There are a number of viable ways to do something and it's a lot of engineering to work it out, often because there are conflicting requirements which have to be balanced, so you've put it off.
-
You actually don't know how to do it.
Reason (1) isn't a problem at this stage, though it will eventually be one if you actually want people to build interoperable systems. Reason (2) is generally a sign that it's going to take quite some time to get to production. Reason (3) potentially represents an existential threat to the project, especially if you actually have to solve the problem in order for it to succeed.[2] It can often be hard to distinguish cases (2) and (3), and it's also very often the case that people think they have case (2)—or even case (1)—but they actually have case (3).
It's clear that this document has a bunch of case (1), which, as I said, I'm not too worried about. More worrisome, however, is that it has a lot of (2) and some stuff that's either actually in category (3) or at least requires so much work that it's practically in (3), even though we sort of could figure out how to do it.
Interoperability #
My first concern here is interoperability. One of the primary use cases seems to be that two similar sites will share the same data on your DWN. The slide deck gives two examples: (1) two music services sharing your music playlist and (2) sharing your travel reservations between sites. In order for this to work properly, the sites that are sharing the same data need to agree on the data format and semantics.
Data Model #
In the examples provided in the slide
deck, the data format is identified by a link to a JSON schema
on schema.org, which is a registry
of schemas (definitions of data structures).
For instance, in the music playlist example, playlists would
be rendered as MusicPlaylist.
Here's a slightly trimmed version of the example from
schema.org (I also fixed their misspelling of "Lynyrd Skynyrd").
{
"@context": "https://schema.org",
"@type": "MusicPlaylist",
"name": "Classic Rock Playlist",
"numTracks": "2",
"track": [
{
"@type": "MusicRecording",
"byArtist": "Lynyrd Skynyrd",
"duration": "PT4M45S",
"inAlbum": "Second Helping",
"name": "Sweet Home Alabama",
"url": "sweet-home-alabama"
},
{
"@type": "MusicRecording",
"byArtist": "Bob Seger",
"duration": "PT3M12S",
"inAlbum": "Stranger In Town",
"name": "Old Time Rock and Roll",
"url": "old-time-rock-and-roll"
}
}This is actually not what I expected to see, because the
definition of the byArtist in track is actually of
type Person, but "Lynyrd Skynyrd" is
clearly a text field. This appears to be a known problem
in schema.org.
We expect schema.org properties to be used with new types, both from schema.org and from external extensions. We also expect that often, where we expect a property value of type Person, Place, Organization or some other subClassOf Thing, we will get a text string, even if our schemas don't formally document that expectation. In the spirit of "some data is better than none", search engines will often accept this markup and do the best we can. Similarly, some types such as Role and URL can be used with all properties, and we encourage this kind of experimentation amongst data consumers.
This sort of makes sense in a system which seems to be mostly
devoted to publishing metadata that can be consumed if
available and ignored if not, but it's not sufficient for bidirectional
interoperability.
Obviously, if Spotify expects to use personal names and TIDAL
expects to use Person we're going to have problems. It
gets worse, though. There are at least three separate ways to
render the artist who performed "Old Time Rock and Roll":
- Bob Seger
- Seger, Bob
- Bob Seger & The Silver Bullet Band (this is what Amazon Music uses, incidentally).
You could also have "and" instead of "&" in both the name of the
band and the name of the song. This isn't a problem with
playlists produced and consumed by the same entity because
they can be consistent about their choices—or more
likely have the identifiers refer to actual assets
(e.g., Spotify has resource identifiers that look
like this 6rqhFgbbKwnb9MLmUQDhG6) and just
have human-readable metadata—but it's critical for
interoperability, where mismatches will result in mysterious
failures.
The situation with Reservation is equally bad. To take
one example, it contains departureAirport (nested
under reservationFor which is of type Airport).
Airports can be listed either by IATA code or ICAO code,
so what happens if site A uses the IATA code (YYZ) and the other site uses the ICAO code
(CYYZ)? I guess you need to be prepared to accept both. At a higher
level, how do you link up multiple reservations attached to the same
trip? The schema doesn't tell you, so you have to invent something
(use Trip? Create an identifier that
you attach to each reservation?)
and you can expect different providers to invent different things.
Similarly, if Expedia and United create separate trips, how do you
join them?
The point isn't that this kind of schema is bad but that it's insufficient in that it mostly defines syntax and not semantics and there are many structures that are compatible with these schema (to some extent deliberately because it allows for flexibility!). If you want to have interoperability, you need to rigorously define the semantics of everything. As a good example of how this plays out in practice, look at the CalDAV specification, which contains 99 pages of specification about how precisely calendaring systems should interoperate, all assuming that you already have a WebDAV-based data store. This is the kind of thing you need to do if you actually want multiple sites to interoperate with the same data values, and you'll need to do it one at a time for each application, not just point at schema.org and hope. It's not impossible, it's just a lot of work, and it has to be done for every single application domain where you want to interoperate.
It's worth noting that these are actually the easy cases because they mostly involve multiple sites computing on your data. The problem of how to have a consistent data model for something complicated like Twitter or Facebook where people's viewing experience is assembled out of other people's data and you want to have a consistent experience when viewing a mixture of content sourced by services A, B, and C—even when you are on service D—is likely to be a lot harder.
Application Architecture #
Consider the case of photo sharing, which seems like an obvious example of owning your own data. So you have all your photos on your DWN and now you want to give Flickr access to them so that you can share them with other people. What now?
The first question we have to answer is where the data will be served from when people go to look at your albums. One answer is that it's served off of your DWN, but this actually puts enormously high requirements on the DWN in that it has to be able to serve very high volumes of traffic. Serving that amount of traffic is one reason you use a photo sharing site like Flickr in the first place, so that's no good. This means that the data has to be served off of Flickr, not your node,[3] but how does that work?
The obvious thing for Flickr to do is to just suck all the data off of your DWN and replicate it locally. So, instead of having the architecture I showed above, we actually have something more like the diagram below:
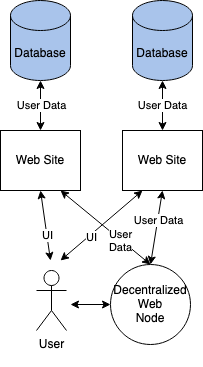
In this case, Flickr has a copy of your data which is what it uses to serve to other people, and then—at least in theory—it periodically syncs your data with the DWN. This sync has to be bidirectional, so that Flickr can discover when new pictures have been created, and in practice, it will actually need some way to be notified when that has happened. This probably means some kind of publish/subscribe framework for these notifications. Again, not impossible, but it needs to be specified.
Note that even in cases where the site doesn't need to serve high volumes of traffic, it's extremely convenient to have a site-local copy of the data. For instance, it lets you run algorithms (face recognition, machine learning, etc.) over the data quickly without having to constantly retrieve it from the DWN.
Another advantage of having a local copy is that it allows you to make changes that happen immediately without being dependent on the DWN for performance (remember that users will blame the site when it's slow, not the DWN). But then you have to worry about what happens when the user makes a big pile of changes on one site that conflict with changes on some other site and those changes have to somehow be resolved each site will have to implement all of this logic. The situation is somewhat better if you just write everything right to the DWN but you still have to deal with conflict resolution for any change that's not instantaneous.
This is of course a problem for any system that has multiple readers and writers, and while we do see systems that have shared data that multiple clients can concurrently write to (e.g., the Strava API), application authors have to take real care not to step on each other. One common pattern you see in practice is for site A to import data from site B but not to write it back and just to keep any changes locally. For obvious reasons, this is a lot easier, especially if you already have to keep a local copy anyway for other reasons.
Access Control #
Next, we need to ask how access control will work. As noted above, the DWN is responsible for denying or granting access to your data, but the unit of access control is the site, not the user. Consider the case of the photo site from the previous section: once you have shared your photos with the site it is free to show them to anyone it wants without any involvement from your DWN. Of course, the site will likely have its own access control settings, but you're trusting the site to enforce those, not the DWN.
Moreover, those access control settings have to be stored somewhere. If it's in the site's database, then you've just lost control of some of your data; if it's in the DWN then we have to specify how access control is stored, which is likely to be very complicated given that each site has its own access control model (share with friends, share with specific people, etc.) Of course, the site could just store some site-specific blob on the DWN, but that's hardly better than storing it locally.
It's possible to imagine having the DWN make every access control decision somehow, either in an "advisory" capacity by serving as an oracle for the site, or in a "mandatory" capacity by requiring cryptographic controls for every action. For instance, every photo could be encrypted and if the site asks to share a photo with DID XYZ, you (or the DWN) then shares the encryption key with that DID. People have tried to build this kind of system (e.g., Tahoe-LAFS), but the results are technically complex and likely not easy to map onto everyone's existing access control systems. To take just one problem: how do you map the existing identifier space of Flickr (or Twitter) to DIDs?
This is just a specific instance of a general situation, which is that even if the data is stored on a device you control, the behavior of an application is dictated by the application logic, which is largely out of your control.
Final Thoughts #
I certainly understand the motivation for this work. Having all of your data locked up in various silos sucks—don't even get me started on streaming apps—and it would be great to have interoperability. With that said, I don't think this is a very promising technical direction. Long experience with standardizing protocols for applications as diverse as e-mail, calendaring, directories, and telephony teaches us that if you want to have interoperability you need to produce detailed specifications that encode the semantics of the application domain, and that this, not the mechanics of data storage and retrieval, is the hard part. The Web5 specifications—at least at present—almost exclusively focus on those generic mechanics, leaving the real problems unsolved.
In my opinion a better way to attack this problem would be to attempt to solve some specific set of application domains (start with Twitter-like microblogging, perhaps?) and see if you can build a protocol or protocol suite that would enable interoperability there. This would also require getting actual buyin from the various sites that you expect to be consumers of this protocol, which seems like it will be very challenging under the best of circumstances. Once you've done a few application domains, you can try to figure out what the common ideas are and perhaps try to build them into some generic infrastructure that makes future protocols easier. This is obviously a lot more effort, but I think it's far more likely to succeed than trying to build a generic system and hoping people will somehow make it work.
Though Solid apparently has a DID method as well. ↩︎
sometimes you can not know how to build some feature but at the end of the day you could ship without it. This is what happened with TLS Encrypted Client Hello, but then we actually figured out how to do it later. ↩︎
See here for some problems with more decentralized options. ↩︎