The endpoint of Web Environment Integrity is a closed Web
We had to destroy the Web in order to save it
Posted by ekr on 18 Aug 2023
Chrome's Web Environment Integrity (WEI) proposal for remote Web browsing attestation is being justly criticized from a broad variety of perspectives (Mozilla Standards Position, Brave, EFF). I certainly agree that WEI is bad news, and I'll get to that part eventually, but first I'd like to situate it in the broader context, both of the Web and the Internet, starting with some history.
The Bell System #
The first communications network available to regular people was the telephone. Of course, the telegraph already existed, but regular people didn't have telegraphs: you went down to the telegraph office to send messages. By contrast, you could have a telephone in your home and use it to call other people who had phones in their homes. Miraculous!
Bring your own phone #
I didn't know until I started writing this post that it was sort-of possible to buy your own phone and install it but you had to first transfer the phone to AT&T and then rent it back from them.
From the early 1900s until 1983, telephone service in the United states was essentially a monopoly (the Bell System) operated by AT&T. The telephone network included not only the wires and switches that the phone company operates today but also the wire in your house and the phone in your hand, all the way up to your ear. Customers rented phones from a subsidiary of AT&T called Western Electric, and they generally looked something like this:
 [Source: Wikipedia]
[Source: Wikipedia]
{kind=link}
If you wanted to connect something else not made by Western Electric to the phone network, you were mostly out of luck. This doesn't just mean no cooler looking phones, but also no cordless phones, answering machines, or modems; basically anything other than a Western Electric brick. Unsurprisingly, there was not a huge amount of innovation in this market, though Western Electric would sell you a somewhat cooler looking "Princess Phone":
 [Source: Wikipedia]
[Source: Wikipedia]
{kind=link}
It's important to understand that there wasn't any real technical obstacle to connecting your own phone to the AT&T network. Regular telephones (what people used to call POTS for "plain old telephone service") are actually quite simple devices to build, mostly consisting of analog signals over two copper wires; you just weren't allowed to, by which I don't just mean that AT&T would be mad at you but that it was actually prohibited by the FCC:
No equipment, apparatus, circuit or device not furnished by the telephone company shall be attached to or connected with the facilities furnished by the telephone company, whether physically, by induction or otherwise except as provided in 2.6.2 through 2.6.12 following. In case any such unauthorized attachment or connection is made, the telephone company shall have the right to remove or disconnect the same; or to suspend the service during the continuance of said attachment or connection; or to terminate the service.
That changed in 1968 with the Carterfone decision in which the FCC struck this provision and allowed consumers to connect their own equipment[1] to the network as long as it did not cause harm to the network itself. This opened the door for customers to attach their own equipment to the phone network and more importantly for innovation that didn't come out of New Jersey.
Naturally, the first things people wanted to install were local improvements to their experience that worked with standard voice phones on the other end (cordless phones, answering machines, etc.), but the Carterfone decision also implicitly allowed the use of the phone network for data transmission—effectively encoded in sound,[2] because that's all the phone network could carry—which meant fax machines and eventually modems (originally for primitive computer networking like BBSes and eventually for the Internet). Of course, you were still tied to the phone network, which—at least until 1984—was entirely owned by AT&T, but as long as you were calling someone with a compatible system and could cram your data into an 8 kHz channel, you could do anything you wanted without getting permission from the phone company.[3] If you were really fancy, you could even get the phone company to sell you a leased line that would carry data, but that's not something regular people did.
In which the phone company was sort of right #
Ironically, while the phone company was wrong about consumer devices like Carterfone presenting a threat to the telephone network, they were sort of right about the threat of letting anybody interconnect. The basic problem is that the telephone network was designed under the assumption that all the constituent parts were operated by the same people and that those people were trustworthy. When this is not true the security of the system breaks down.
Probably the best publicized example of this is the widespread exploitation of the phone network by phreaks for free phone calls—especially long distance—and general exploration of the phone system. The details of this kind of exploitation are out of scope of this post, but the general problem was that the system wasn't designed to be robust to compromised endpoints, or even, famously, to someone who could inject the right tones into the network. Less famously, the network is still vulnerable to impersonation attacks in which the caller generates a fake number and the callee's network just trusts its representation. These attacks are finally being fixed by a set of technologies known as STIR/SHAKEN.
From the perspective of someone who works on Internet protocols, all of these issues just look like design flaws in the system: we just assume that other components of the system are malicious unless proven otherwise. But from the perspective of the original designers, these were closed systems consisting of trusted elements, and when one of the elements misbehaved then you had problems.
The Internet #
At around the same time all this was happening, the first primitive computer networks were being constructed (the first ARPANET nodes went online in 1969). From nearly the beginning, the ARPANET and then the Internet was conceived of as an open system, a "network of networks" in which each network was independent.[4] All that was required to be part of the Internet was to (1) speak the right protocols and (2) find someone willing to connect with you and route your traffic.[5] And the protocols were of course public, being published in the earliest Requests For Comments (RFCs). This applied not just to the basic protocols like IP itself, but also to the application protocols on top like e-mail (SMTP, RFC 822) and remote access (Telnet). From very early on there were multiple implementations of these systems that would talk to each other; as long as your implementation could send and receive the right messages, everything would work right.
Electronic Mail: The Original Killer App for the Internet #
As an example, let's look at the original Internet communications app: electronic mail.
When the Internet was first developed, personal computers were uncommon and instead what people mostly had was access to bigger computers (e.g., owned by their company or university) in what's called a "time sharing" system, which just meant that multiple people could use the same computer at once, with everyone having their own account and workspace.
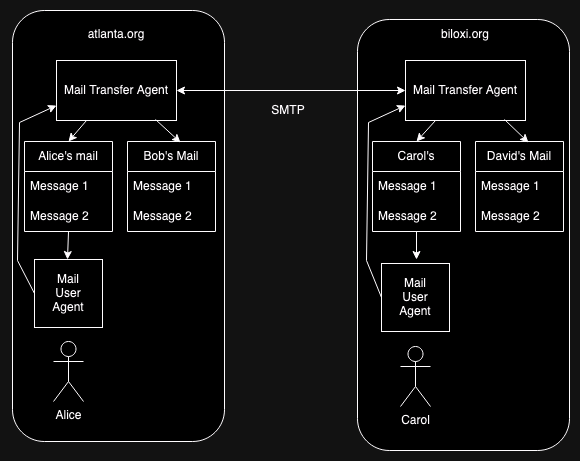
The diagram above shows how mail works in this environment. Each computer has a single system process called a mail transfer agent (MTA), which is responsible for sending and receiving e-mail with other computers. The historical program was called Sendmail. In order to use the system, the user logs into the system (more on this below) and then uses a program called a mail user agent (MUA) (traditionally just a program called "mail").
Alice can send mail to Carol using the MUA, which contacts the MTA[6] and asks it to send it to Carol. The MTA then contacts the MTA—using a protocol called SMTP—on Carol's computer and asks it to deliver it. Carol's MTA then stores it on the disk in Carol's mail file (this is just a single big file with all the messages in it). Carol can then use her MUA to read her messages.
Importantly, both the MTA and MUA are readily replaceable: the system administrator can replace the MTA (other popular MTAs include postfix and qmail) and users can choose their own MUAs (writing new MUAs was a very popular pass-time in the early days of the Internet). In fact, two users on the same computer can run different MUAs without interfering with each other. What makes this work is that both the protocol that the MTAs use to talk to each other and the interface between the MUA and MTA are stable and well-defined. The end result is that people are able to customize their own e-mail experience, including the look and feel, filtering, etc.
Remote Mail #
Back in the really old days, you would log directly into the server, either by using a terminal directly connected to it or over a modem. In either case, you're running the MUA directly on the server, which, recall you are sharing with others. That computer is just displaying stuff on your screen. This typically looked something like this (if you were lucky):
Mailbox is '/usr/mail/mymail' with 15 messages [Elm 2.4PL22]
-> N 1 Apr 24 Larry Fenske (49) Hello there
N 2 Apr 24 jad@hpcnoe (84) Chico? Why go there?
E 3 Apr 23 Carl Smith (53) Dinner tonight?
NU 4 Apr 18 Don Knuth (354) Your version of TeX...
N 5 Apr 18 games (26) Bug in cribbage game
A 6 Apr 15 kevin (27) More software requests
7 Apr 13 John Jacobs (194) How can you hate RUSH?
U 8 Apr 8 decvax!mouse (68) Re: your Usenet article
9 Apr 6 root (7)
O 10 Apr 5 root (13)
You can use any of the following commands by pressing the first character;
d)elete or u)ndelete mail, m)ail a message, r)eply or f)orward mail, q)uit
To read a message, press <return>. j = move down, k = move up, ? = help
Command : @
[Source: ELM user's guide]
This is from a relatively modern UNIX mailer called ELM.
This was fine back in the day, but as people started to get more powerful personal computers, it became increasingly unsatisfactory, for a number of reasons, but principally because it was slow and ugly. Slow because every time you wanted to do anything it required a round trip to the server. This included when you were composing an email and every character you typed had to go up to the server before it was echoed on your screen. Ugly because it was only this kind of text-based display and people (1) wanted a GUI and (2) wanted to be able to display rich content such as emails containing images.[7]
POP versus IMAP #
The major conceptual difference between POP and IMAP is that POP is designed for a scenario where the user downloaded all of their new messages and then deleted them from the server. This works fine if you only have one mail client but if you have multiple devices (say a laptop and a phone) then once one device has downloaded the messages, they won't be available for the other device, which is obviously bad. By contrast, IMAP is designed to leave all of the messages on the server, which means that multiple devices can be used to access the same mail account. IMAP also has support for storing a lot of state (e.g., folders, read versus unread, etc.) on the server, thus providing a more seamless experience for the user.
The obvious fix is to run the MUA on the user's machine and instead have it retrieve the mail from the server and display it locally. In principle, the MUA could just log in as Alice, download all the messages, and process them locally, but that would be inconvenient and slow; what you want is some network protocol that allows you to retrieve messages one at a time. The first popular such protocol was called Post Office Protocol (POP) but POP has been to some extent superseded by Internet Message Access Protocol (IMAP). In either case, there is some program running on the mail server machine which runs POP or IMAP. The MUA on the user's machine contacts that server and uses the relevant protocol to retrieve the user's messages, as shown in the figure below:
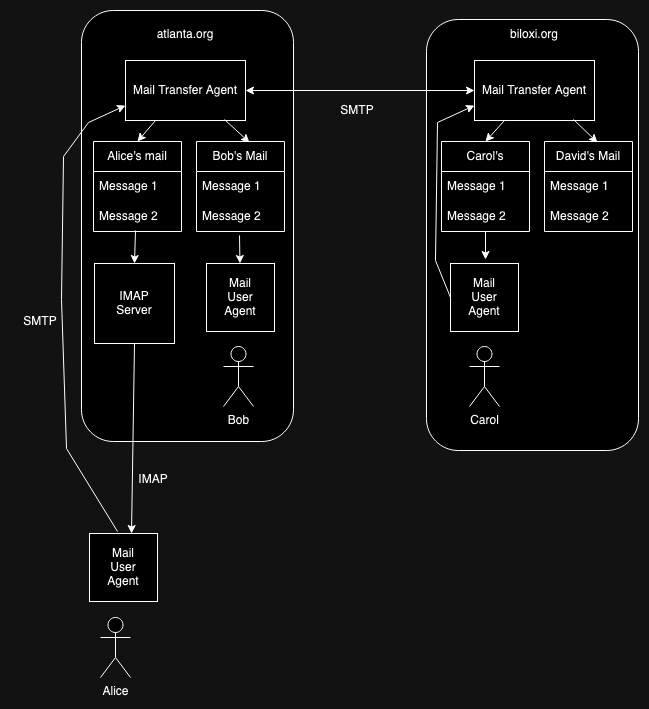
Importantly, nothing had to change on Carol's side in order to allow Alice to read her mail remotely like this. atlanta.org just had to install an IMAP server[8] and then Alice could download an appropriate MUA and use it to talk to the server. Moreover, it's possible for some people on atlanta.org to use remote mail and some to read their mail by logging in as before, as we see Bob doing in the picture above. Of course, the mail provider can choose to offer remote only service without offering the ability to run programs on their servers at all. This is an important operational and security advantage and is how most big mail providers (e.g., Gmail) operate now. However, all of this is invisible to the other side.
Moreover, once atlanta.org has installed an IMAP (or POP) server Alice is free to use any MUA she wants as long as it speaks IMAP (or POP). Because the protocols are published anyone can just write their own MUA that conforms to the protocols. Again, this is critically important because it allows for new mail software to innovate and for Alice to choose the interface and features she likes the best (or even to write her own mail software!). You want all the images suppressed or rendered in black and white? Simple matter of programming? No problem. You want to read your email in a different font? Sounds good. You want it read out loud to you in the voice of Malcolm Tucker? Simple matter of programming. The client is in total control of how things are rendered because it's an open, interoperable system.
In principle, of course, it was always possible to build a totally closed mail system—Microsoft Exchange was like this to some extent—once an interoperable ecosystem had been developed it had a tremendous advantage because it was easy to unilaterally roll out a new mail client or server without changing every other part of the system. Even mail systems which had proprietary elements were still forced to speak standard protocols to some extent, especially for the mail format and delivery parts of the system.
Other Applications #
Of course, e-mail isn't the only application that can run on the Internet. The way the Internet protocols was designed is inherently flexible. providing transport protocols that can carry any kind of traffic, so if you want to build a new application and it can run over IP (these days, TCP and UDP), you can carry it over the Internet, with no need to stuff it into an 8 kHz voice channel. Moreover, you don't need any cooperation from the network itself; you just need to upgrade the endpoints to support your new application, which is a huge deployment for advantage. The result of these design choices was an explosion of innovation, starting in around 1992 with the Web and that is still happening today.
The Web #
This brings us to the topic of the Web which is probably still the most important single application on the Internet. With all that, it's technically just another networked application.
When the Web was designed, it was built on similar principles to the Internet as a whole, with published—though initially without really clear specifications—interoperable protocols that anyone could implement. More or less independent implementations of Web clients and servers started to appear quite soon after Tim Berners-Lee's initial announcement of the Web and everyone just expected that they would talk to each other. In fact, that's what it meant to be part of the Web. Here's how we described this in Mozilla's Web Vision (Emphasis mine):
A key strength of the Web is that there are minimal barriers to entry for both users and publishers. This differs from many other systems such as the telephone or television networks which limit full participation to large entities, inevitably resulting in a system that serves their interests rather than the needs of everyone. (Note: in this document "publishers" refers to entities who publish directly to users, as opposed to those who publish through a mediated platform.)
One key property that enables this is interoperability based on common standards; any endpoint which conforms to these standards is automatically part of the Web, and the standards themselves aim to avoid assumptions about the underlying hardware or software that might restrict where they can be deployed. This means that no single party decides which form-factors, devices, operating systems, and browsers may access the Web. It gives people more choices, and thus more avenues to overcome personal obstacles to access. Choices in assistive technology, localization, form-factor, and price, combined with thoughtful design of the standards themselves, all permit a wildly diverse group of people to reach the same Web.
As of the mid 2000s, the Web was the dominant paradigm for application delivery: if you wanted to build some kind of networked application—and often a non-networked one—you stood up a Web site. This paradigm was so powerful that it even started to absorb standalone applications like e-mail. A full account of this phenomenon would be too long to include in this post, but it seems clear that a huge part of it is due to how easy it is to deploy Web applications to users; there's nothing for them to download or install, they just go to your Web site and the application runs right in the browser. Better yet, when you release a new version you don't need to update the user, they just get the new version whenever they go to your site again.
As with other interoperable applications, the design of the Web allows the client to control how content is rendered and how the user interacts with it. Some important examples of this kind of user control include:
- Accessibility features such as screen readers
- Automatic password and credit-card form-fill
- Ad blocking
- Translating Web pages into a different language
- "Reader" modes
- Downloading pieces of the page (e.g., images) or the whole page
- Developer tools which allow the user to inspect the Web page contents
The Web differs from e-mail in one very important respect, which is that the Web allows the server to run programs on the user's computer and those applications can talk back to the server. The vast majority of Web pages have some dynamic content in the form of JavaScript. By contrast, e-mail content is largely static. This makes the Web a much more powerful deployment platform but also limits the ability of the the client to strictly control every aspect of the user's experience.
A good example of this phenomenon is Web-based mail systems like Gmail. The diagram below shows the high level architecture of this kind of system.
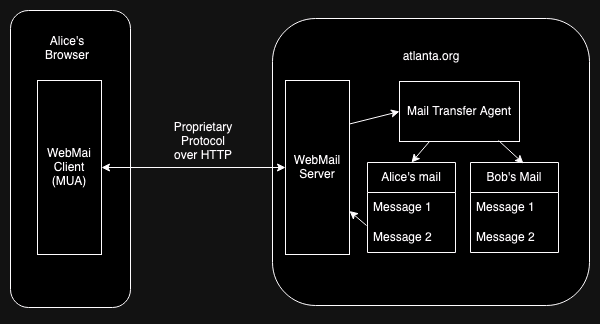
Conceptually, this is exactly the same architecture we had before, with a MUA talking to a server, except that instead of being a standalone app, the MUA is a JavaScript program running in the browser. However, there's one big difference: because the Webmail service controls both the Webmail server and the Javascript based MUA they don't have to use a standardized protocol like IMAP; they can just build a proprietary protocol. And because deploying new JS code on the Web is so close to frictionless, they can change it whenever they want. So even though it's all running on a standardized substrate of the HTTP and HTML/JS/CSS, systems like this are actually fairly closed because all the important stuff is happening in the downloaded JS code rather than in the standardized pieces.[9]
Even so, the browser itself still maintains a fair amount of control over how the application behaves. Aside from the examples above, such as Firefox Picture-in-Picture or add-ons like such YouTube Enhancer which modify the behavior of popular sites such as YouTube even though they are to a great degree JS applications.
Mobile Apps and App Stores #
In the early 2000s it looked like the Web model had totally won and native apps were toast but that changed in 2008 with the opening of the iOS app store.[10] The app store standardized the process of downloading, installing, and updating mobile applications—at least on iOS—resulting in a system with almost as frictionless as the Web and with a number of important technical advantages. The result was a rapid takeoff of the use of mobile apps to the point where they are the dominant mode of mobile usage.
 [Source Wikipedia]
[Source Wikipedia]
{kind=link}
Because of the app store, mobile apps have many of the deployment advantages of the Web but are far less open. Just like a Web app, the vendor controls both the client and the server, but unlike on the Web, there is no browser intermediating the app's interaction with the user, and so there's no opportunity to modify the behavior of the app, e.g., for ad blocking or translation. Of course, the operating system could in principle decide to do this kind of stuff—and the mobile OSes do do some technical enforcement of their policies—but the platform just isn't engineered for this kind of user agent the way the Web is.[11] As a practical matter, then, if you want to use some network-based service that hasn't gone out of their way to open their interfaces you're mostly going to be using their app without any real opportunity to control your own experience except in ways designed into the app. This is why, for instance, you have to have five different apps on your Roku, one for each streaming service (including separate ones for Disney and Hulu, even though they are owned by the same company!), rather than a single app which will work with any streaming service.
Closed versus Open #
There are a number of reasons why application vendors might prefer closed versus open systems:
- Flexibility.
- If you control both ends of the system, then you can evolve it much more quickly because you don't need to wait for anyone else to change. This is the argument made by Jonathan Rosenberg and also in this post by Moxie Marlinspike on why Signal isn't federated.
- Barriers to entry.
- In an open system a potential competitor can enter the market by standing up a new endpoint (e.g., a new client) without having to displace the entire ecosystem. As a concrete example, when Google launched Chrome they didn't have to displace every Web server in the world because Chrome automatically worked with them.
- Control.
- If you control the clients then you know that they behave the way you want them to. To some extent this is just a matter of system stability and not having to deal with potential problems from broken clients, but it's also a way to enforce your preferences when they might differ from those of the users.
The important point for the purposes of this post is "control". There are a number of situations in which the user's preferences and those of the site aren't in alignment, such as:
- Ad blocking.
- Sites and apps make money by showing ads, but users don't like to see ads, which is why they often run ad blockers. Obviously, the providers would prefer that users actually saw the ads.
- Access to content (digital rights management).
- Web pages can of course play audio and video, but historically the providers of that content have been very concerned about unauthorized downloading and reproduction. In an open system, however, nothing stops the client from storing the raw media.
Encrypted Media Extensions #
This last issue was responsible for the one major case in which the Web has deviated from the principle of openness, namely HTML Encrypted Media Extensions (EME). In the early days of the Web, media was largely played through Adobe Flash, which had Digital Rights Management (DRM) mechanisms designed to prevent exporting content. These mechanisms took in encrypted media and decrypted and displayed it, but were designed to resist user tampering to exfiltrate the media.
Starting in the early 2010s browsers gradually
started to deprecate Flash, both in response to concerns
about security and as more and more of its capabilities
started to be added to the Web platform.
One of those capabilities was the ability to play video,
but the large video streaming services (especially Netflix)
were concerned about people using the browser to save
media and so were unwilling to use the HTML5 <video> tag
as-is. Instead they proposed a new technology called
Encrypted Media Extensions (EME),
in which a closed DRM Content Decryption Module (CDM) was embedded in the browser to
decrypt and display the media.
EME was highly controversial but eventually every major browser included it. I can't speak for other browsers, but I was at Mozilla when they decided to implement EME in Firefox and the conclusion was that given that other browsers were going to implement EME it was better to have people able to watch videos—which we knew they wanted to do—in Firefox than that they switch to another browser. The implementation of EME in Firefox was designed to limit the capabilities of the CDM, so that it had limited access to the user's computer and couldn't be used to track users.
Back to Web Environment Integrity #
This all brings us back to WEI, which is a proposal for attestation for the Web. For more background on attestation see here, but briefly the idea with attestation is that you have some "trusted" piece of hardware on the user's device (in this case "trusted" means "not controlled by the user but rather by the manufacturer", so it's trusted by the web site, not by the user) which is able to vouch for the software that runs on the user's computer. Most modern mobile devices and many if not most laptop devices now have such a piece of hardware.
The motivation for the proposal is described as follows:
Users like visiting websites that are expensive to create and maintain, but they often want or need to do it without paying directly. These websites fund themselves with ads, but the advertisers can only afford to pay for humans to see the ads, rather than robots. This creates a need for human users to prove to websites that they're human, sometimes through tasks like challenges or logins.
Users want to know they are interacting with real people on social websites but bad actors often want to promote posts with fake engagement (for example, to promote products, or make a news story seem more important). Websites can only show users what content is popular with real people if websites are able to know the difference between a trusted and untrusted environment.
Users playing a game on a website want to know whether other players are using software that enforces the game's rules.
Users sometimes get tricked into installing malicious software that imitates software like their banking apps, to steal from those users. The bank's internet interface could protect those users if it could establish that the requests it's getting actually come from the bank's or other trustworthy software.
The high level idea is that there would be a JS API that the site could call which would cause the browser to ask the OS—and presumably transitively the aforementioned trusted hardware—to attest to some properties of the browser[12] The spec is silent on what is being attested to and the Explainer is pretty fuzzy:
The proposal calls for at least the following information in the signed attestation:
- The attester's identity, for example, "Google Play".
- A verdict saying whether the attester considers the device trustworthy.
These two pieces of information basically serve to guarantee that the code is running on some device made by a manufacturer that the Web site trusts. This already means that we don't have a completely open system: because it's not possible to build a new piece of hardware yourself that will be able to provide the correct attestation: you instead need to have some closed third party module. You probably also need a trusted and locked-down operating system, because otherwise the OS can tamper with the behavior of the browser, so good luck if you want to run Linux!
Moreover, this attestation isn't very useful in and of itself: the first three use cases are ones in which the browser connecting to the server is controlled by the attacker, and so all they demonstrate is that the attacker was able to afford a single device made by such a manufacturer. However, they could be running any software they want on it. They don't even need to be using the device to run their browser. They can use a single trusted device to generate an arbitrary number of attestations up to the performance of the device—and modern hardware is very very fast—so the effectiveness of this limited attestation seems fairly low. In order to effectively address these use cases, you need the attester to provide more information.
The explainer goes on propose two other types of information:
- The platform identity of the application that requested the attestation, like com.chrome.beta, org.mozilla.firefox, or com.apple.mobilesafari.
- Some indicator enabling rate limiting against a physical device
The basic intuition behind rate limiting is that it prevents the kind of large-scale attacks I mentioned above in which the attacker has a lot of browsers connected to a single trusted device. This might be useful in terms of preventing ad fraud attempts where the attacker pretends to have a large number of devices representing a large number of legitimate users, though it could be tricky to set the rate limits correctly: some people do a lot of browsing and you don't want them to suddenly run up against a rate limit. So at best this multiplies the attacker's costs by making them buy more trusted devices.
Rate limits, do not, however, address the game anti-cheating use case
because the problem isn't that the user is doing an unreasonable number
of attestations but rather that they are running cheating software on
a legitimate device. The only way to address this is to have the
attestation cover the software itself, in this case the Web
browser. This is where the proposal to indicate the identity of the
application (e.g., com.chrome.beta) comes in. Presumably the relier
would have a list of browser software that it trusts behaves correctly
and would reject any requests from other pieces of software, or at
least flag them for special handling (and inconvenience). This means
that if you want to run something other than a major browser or
even build your own, you're totally out of luck.
Moreover, in order for this to work, the software—and probably the operating system—needs to be unmodified and not to have affordances that allow the user to adjust its behavior in an undesired fashion. This is an incredibly strong condition because a browser is a very complex and configurable piece of software. For instance Firefox has hundreds of configuration parameters that users can set, some supported and some unsupported; it's very likely that some of them would let users modify behavior in ways the site wouldn't want. Beyond configuration, most browsers allow you to install extensions/add-ons which substantially change the behavior of the browser, so any add-ons need to be part of the trusted list. The WEI proposal says that this should be fine because:
Web Environment Integrity attests the legitimacy of the underlying hardware and software stack, it does not restrict the indicated application’s functionality: E.g. if the browser allows extensions, the user may use extensions; if a browser is modified, the modified browser can still request Web Environment Integrity attestation.
I don't see how this can be the case, though. I suppose it's possible that as a technical matter, you could get an attestation (e.g., "This is a version of Firefox with unknown modifications" or "This is a version of Firefox with the 'I am cheating at this game'" add-on), but the site clearly can't treat this attestation as meaningful without defeating the security guarantees of the system.
Of course, you might decide to abandon the anti-cheating use case—and any others that don't involve pretending to be a lot of different devices—but that would be much more limited system than this, more similar to Apple's Private Access Tokens, which are supposed to just attest to the device itself (this is also bad, but not as bad as WEI). However, if you want to ensure that individual users' machines behave in some specific way, you need the attestation to cover the software on the user's machine, not just to attest that they had some limited amount of control of a trusted device.
I know a lot of people care about cheating in games, but it's a bit of a niche use case. However, the elephant in the room here is advertising: a lot of people use ad blockers and many sites try to detect this case and refuse service to them. One potential application of WEI is forcing users to prove that they're not running an ad blocker. The explainer doesn't list this as a use case, but also doesn't really disclaim it and once remote attestation exists there is going to be a huge financial incentive to deploy it for this purpose. Obviously, preventing ad blocking in the browser would require attesting to the whole browser stack, not just that the browser is running on a trusted device, as if the user controls their browser they can just disable ad display, since ad blocking is typically a modification, or sometimes a feature, of the browser.
The bigger picture #
The basic property of an open system like the Internet and the Web is that you can only be assured of the properties of the elements you directly control. The elements that belong to other people work for them and not you. In a closed system, by contrast, the software on the end user device works for the provider, not for them, whether it is officially owned by the user (as in mobile apps) or it actually belongs to the provider (as with the old Bell System monopoly).
WEI and similar attestation technologies represent an attempt to impose an alien model, that of a closed system, onto the open system of the Web. As with any closed system, the net impact will be that users don't control their own experience of the Web but rather have only the experiences that sites are willing to let them have. That seems bad.
Ironically, the Carterfone didn't actually plug into the wall socket. Instead, it used an acoustic coupler that tied into the phone handset. However, the decision was broad enough to allow for electrical interconnection. ↩︎
Yes, I'm simplifying here, because the phone network just carries analog signals in a given frequency and amplitude range. ↩︎
Obviously, the phone company could tell that this wasn't voice traffic, they just had to pass it through anyway. ↩︎
The jargon in routing is "autonomous system". ↩︎
I'm simplifying a bit because for some time there were actually restrictions on commercial use, but these were gone by the early 1990s. ↩︎
Actually, back in the day, it just executed
sendmaildirectly. ↩︎And yes, I do I know about X, but remote X is not the answer. ↩︎
In principle Alice could have installed one just for herself, but that's not how it's typically done. ↩︎
See this 2011 presentation by VoIP pioneer Jonathan Rosenberg (JDR) and this Internet Draft by Tschofenig, Aboba, Peterson, and McPherson for an argument that this phenomenon meant the end of application-layer standards. ↩︎
Ironically, Steve Jobs initially didn't want an app store and instead had in mind something more like what you'd now call a Progressive Web App but demand for real apps was overwhelming and here we are. ↩︎
In addition, because of the way that the Web evolved, many JS applications operate by changing elements on the Web page (e.g., "now render this new piece of HTML") which means that the browser can generally figure out what the page is doing; a property called "semantic transparency". In principle, those applications could just write pixels onto an HTML canvas but that's more difficult and not the standard approach. ↩︎
This might also involve calling out to some server, but everything here is rooted in the trusted hardware on the device. ↩︎