How NATs Work, Part IV: TURN Relaying
It's STUN all the way down
Posted by ekr on 17 Jul 2023
The Internet is a mess, and one of the biggest parts of that mess is Network Address Translation (NAT), a technique which allows multiple devices to share the same network address. This is part IV in a series on how NATs work and how to work with them. You may want to go back to and review part I (how NATs work), part II (basic concepts of NAT traversal) and part III (ICE).
As discussed earlier there are some configurations where it is not possible to establish a direct connection between two endpoints. For instance, if Alice has a NAT with address-dependent mapping and Bob has a NAT with address-dependent filtering, then the packets from Alice will never match any filter on Bob's NAT and will just be dropped. Similarly, the packets from Bob will not match any mapping on Alice's NAT and will be dropped. The only way to send data between these two endpoints is with the assistance of a server, as shown in the blue path in the diagram below.
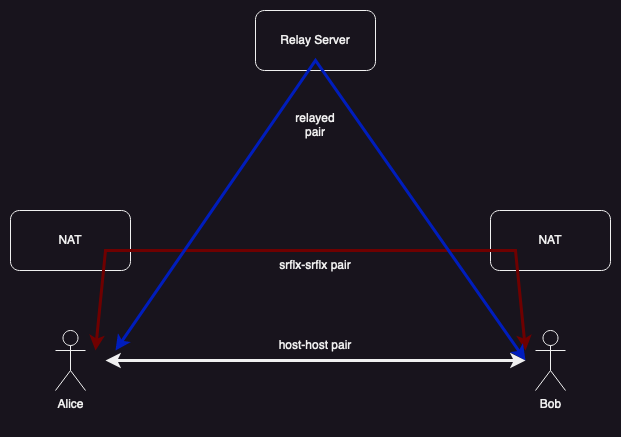
There are any number of possible protocols one might use to send data through a server. For instance, you could connect through a VPN or even send each individual packet as an HTTP request to the server. However, the IETF has standardized a specific protocol which is designed to be used with ICE, Traversal Using Relays Around NAT (TURN).
TURN #
Conceptually, TURN is an application layer relay protocol: the TURN client (i.e., the user's device) sends packets to the TURN server addressed to the other side and the server forwards them, as shown below:

In this example, Alice is communicating with Bob through her TURN server (generally each client will have an associated TURN server, as described below):
-
When she wants to send a packet to Bob, she sends it to the server's address (198.51.100.1) but with a label telling the server to forward it to Bob. The server removes the label and sends the packet to Bob.
-
When Bob wants to send a packet to Alice, he sends it to the TURN server, which forwards it to Alice. The packet will arrive at Alice's machine with the TURN server's IP address, so the TURN server has to add a label telling Alice that it originally came from Bob. Otherwise Alice wouldn't be able to distinguish between packets from Bob and Charlie when they come through the TURN server.
It's important to see that there is an asymmetry here: Alice has a relationship with the TURN server and is explicitly communicating with it. From Bob's perspective, however, it's just as if the packets came from the TURN server, and unless he has some external knowledge, he has no way of seeing that he's actually communicating with Alice through the TURN server, rather than the server itself (because from an IP layer perspective that's actually what's happening).
The opacity of the TURN server from Bob's perspective has an important consequence, which is that the server has to keep state in order to distinguish multiple endpoints that Alice is talking to. Consider what happens if the server has two clients, Alice and Charlie. The packets from Alice and Charlie are labeled with where to send them, but the packets from Bob are not, so do they go to Alice or Charlie? The only way for the TURN server to know is to keep some state. For instance, it can assign outgoing packets from Alice one port and packets from Charlie a different port, so that when Bob replies it can look up incoming port and know where to send it. If this sounds familiar, it's because this is exactly what a NAT does and for the same reason: it has more than one client sharing the same external IP address, in this case the address of the TURN server. All application relays have to do something like this, because otherwise they wouldn't be able to talk to unmodified peers, which is a hard requirement for incremental deployment.
Allocations and Permissions #
In order for Alice to send and receive data from Bob, TURN requires that she explicitly create state on the relay (unlike a NAT where the state is implicitly created by sending packets). This is done using two transactions, allocating an address and creating a permission, as shown below:
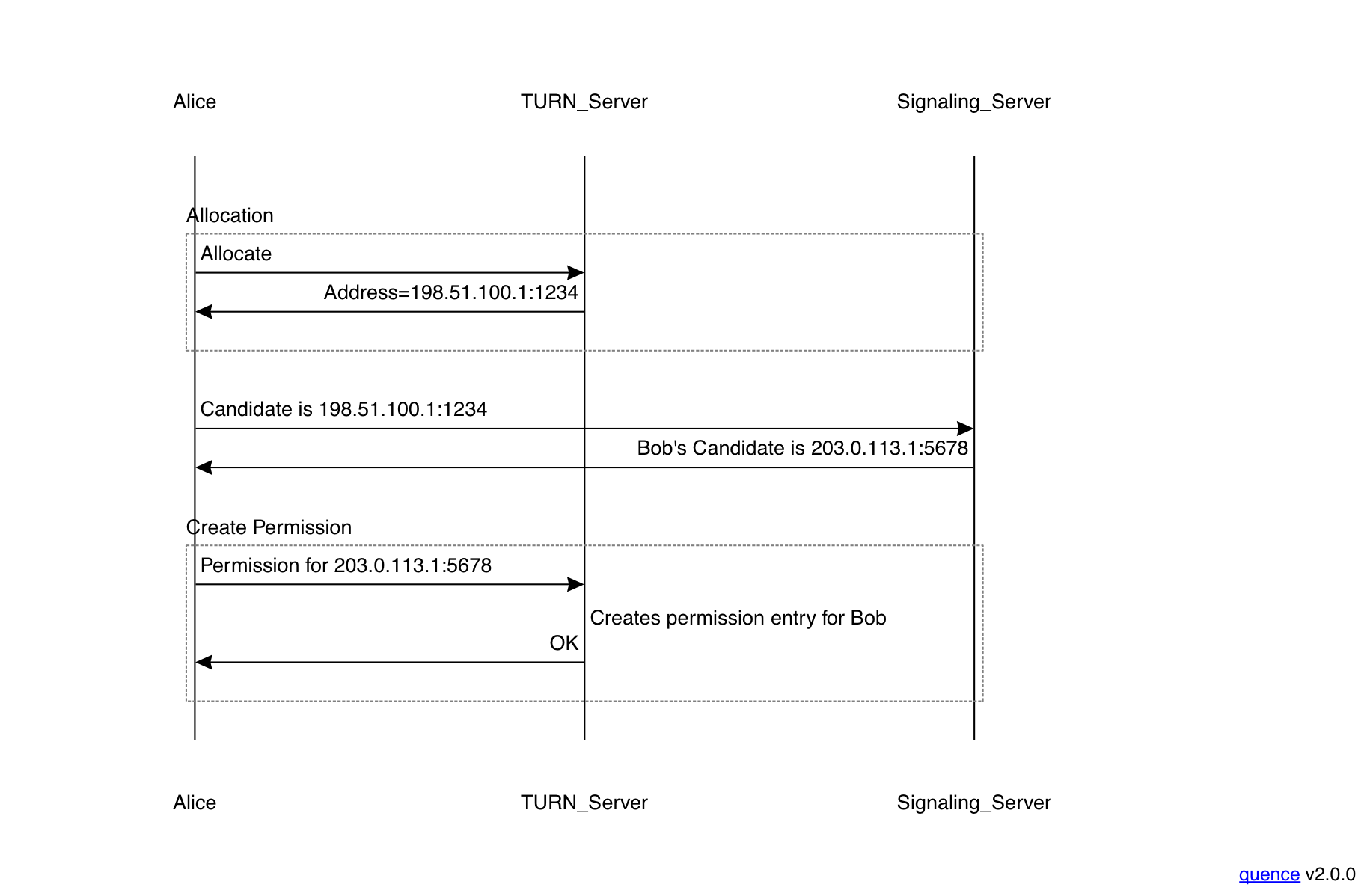
The first thing Alice does is to allocate an address (really a port, because the server probably only has one address, or maybe one each for IPv4 and IPv6) on the TURN server that she will be using to send and receive packets. The TURN server replies with the address and port that has been allocated. Alice can immediately send this entry to peers so they know what it is.
Alice can use this address to send to multiple peers, as described above, but it's not yet associated with any individual peer. In order to actually send packets, Alice needs to next create a permission entry for a specific peer. Until Alice has created a permission for a given peer, packets to from that address will just be dropped by the TURN server. With ICE Alice learns peer addresses because those peers send their candidates and then Alice would create a permission for each candidate address before sending packets to it.
Note that this is effectively an address-independent mapping with an endpoint independent filtering policy: Alice uses the same address and port to talk to everyone but the TURN server blocks incoming packets from anyone that Alice hasn't explicitly identified. This analogy isn't perfect because the permission is explicitly created and Alice can't even send packets to those endpoints either before sending a permission request, but it's close enough as a mental model. However, this isn't port-dependent filtering; the TURN server will accept packets from any port once a permission has been created for a given address. This produces better results with endpoints which have address-dependent mappings.
To put this all together, here is what TURN looks like as part of an ICE transaction, showing a complete connectivity check.

The initial part of this example is the same as the previous one: Alice contacts the TURN server, gets an allocation, and send it to the signaling server. That signaling server forwards it to Bob, who sends back his own candidate. At the same time, Bob also tries to do a connectivity check to Alice's candidate, just as he would any other candidate. However, this fails because Alice hasn't created a permission for Bob. Once Alice creates that permission, then she sends her own check to Bob, which succeeds, as does Bob's in the other direction. Note that there is a race condition here: it's possible for Alice's permission request to complete before Bob's connectivity check arrives, in which case that packet would get delivered, even though Alice hadn't send a connectivity check to Bob. Either way, ICE will eventually succeed.
You should notice that Bob doesn't need to be aware of the fact that Alice's candidate is actually from a TURN server; it just sends to it as if it were any other candidate. In ICE, candidates are actually labeled by type, but this isn't necessary for ICE to work.
I can't believe it's STUN #
Believe it or not, TURN is actually an extension for STUN: TURN data is encapsulated in STUN packets. For instance, you do allocation by sending a STUN message of type "Allocate" and you send packets by sending a message of type "Send". This is actually not quite as strange a design decision as it might initially appear, for several reasons:
-
You really really want to run TURN over UDP rather than TCP (see below).
-
Because UDP is unreliable you need some transaction mechanism to allow the client to make requests from the server, retransmitting those requests when lost. STUN already has this.
-
ICE implementations already have STUN stacks. As one nice side effect, though the TURN server will actually tell you your server reflexive address, so you don't need to do a separate request to a STUN server to learn it.
If one were designing this protocol today, you would probably base it instead on some protocol that added reliability to UDP (e.g., QUIC), but TURN was originally designed in 2010, so things were different back then.
Channels #
One real drawback of using STUN is bloat. Sending a single packet with a Send (outgoing) or Data (incoming) indication adds 36 bytes of overhead. Here's an example packet diagram, based partly on the one from the STUN RFC:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|0 0| STUN Message Type | Message Length |\
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
| Magic Cookie | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Header
| | |
| Transaction ID (96 bits) | |
| | /
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type=XOR-PEER-ADDRESS | Length=8 | \
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Peer
|0 0 0 0 0 0 0 0| Family | X-Port | | Address
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
| X-Address (32 bits for IPv4) |/
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type=Data | Length |\
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Data
| Variable data .... |/
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Most of this is overhead. First, every packet has a fixed 20 byte header, which mostly acts to identify it as STUN and tell you what message type it is (e.g., Send indication). Then you have the peer address and the data encoded in an inefficient tag-length-value format. None of this overhead really mattered for STUN's original application, where you just sent a few messages, but when you have to absorb it for every packet you're sending (at a rate of maybe 20-50 per second) it adds up quickly. The remote address and port is also sort of redundant because there are only a few addresses in use, so you could compress them by just sending a short address ID.
TURN includes a mechanism called "channels" which does exactly this. The client can send a request to the TURN server to allocate a two-byte channel ID to a given remote address and port (the same information as would be needed for a permission). Once the channel is allocated, packets can then be sent or received by just prefixing them with the channel ID and length,[1] like so:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Channel Number | Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
/ Application Data /
/ /
| |
| +-------------------------------+
| |
+-------------------------------+
If you're a real protocol engineering nerd, you might ask how you distinguish a message containing channel data from a STUN message, as they are carried on the same host/port quartet. The answer is that STUN message types always have the first two bits as zero and channel IDs are required to be between 0x4000 and 0x4fff.
You might also wonder at this point why STUN conveniently has a range of message types which can't be allocated: the reason is that when STUN was designed people wanted to make sure that it could be easily demultiplexed (i.e., distinguished) from RTP and RTCP, which always have the first bit of the first byte set to 1.[2] There has actually been quite a bit of hackery around easily demultiplexing various types of messages in real-time multimedia. Some of this was due to intentional design and some was just fortuitous design choices that people—by which I partly mean me—took advantage of. For instance, DTLS has record types as the first byte, but these are always low numbers and so easy to distinguish from RTP and RTCP. At this point there are actually five separate types of protocol message which can be carried over the same host/port quartet: (1) STUN (2) ZRTP (3) DTLS (4) TURN channels and (5) RTP/RTCP. Someone had to write a whole RFC to systematize how to do it.
No incoming connections? #
One side effect of the requirement to create a permission for a specific peer address is that it is not possible to use TURN to run a generic server behind a NAT or firewall. A typical server, such as for Web or mail has a fixed address and port which anyone can use to connect to it, but because TURN requires that the TURN client create a specific permission for each peer, arbitrary clients on the Internet cannot just connect.
This limitation is not an oversight but rather a deliberate design choice. Recall that it's common for firewalls to enforce an "outgoing connections only" security policy. Without this limitation it would be straightforward for clients to bypass this policy by just connecting to a TURN server on the Internet. The TURN designers were concerned that if TURN enabled this kind of policy bypass enterprise administrators would respond by blocking TURN entirely (recall from the previous section that TURN is trivial to identify.) The idea was that if TURN could only be used for outgoing connections, then administrators would be more likely to allow it through the firewall.
What about when STUN or UDP is blocked? #
Despite the "no-incoming" compromise embodied in the permissions design, it is still sometimes the case that STUN over UDP is blocked. The reasons for this vary, but include:
- Firewalls that block all UDP traffic.
- Firewalls that do so-called "deep packet inspection" and block any packets from protocols they don't recognize
Data from the initial deployments of QUIC suggest that somewhere around 5% of clients can't use an arbitrary new UDP-based protocol, though it's unclear how often this is due to UDP blocking or just to blocking unrecognized protocols. In order to get around this kind of blocking, it is also possible to run TURN over TCP as well as over TLS. If you have a firewall which just blocks UDP, then running TURN over TCP will often work. If you have a firewall which blocks unknown protocols then running TURN over TLS[3] might work.[4] The idea here is that there are other protocols that firewall administrators want to support (e.g., HTTP or HTTPS) that run over TCP and/or TLS and if they haven't configured their firewall rules too strictly, then TURN may also work.
It's important to understand that it's still quite easy to recognize TURN in these situations:
- By default STUN uses a different port number than HTTP
- If TLS isn't used you can just look at the TCP packets to see if something is STUN.
- When TLS is used, the TLS ALPN extension indicates that TURN is in use.
Again, this is by design and reflects an attempt to take a compromise approach to blocking of TURN in which network operators can block TURN if they want to but in cases where they just configured their rules in a way that incidentally blocks TURN (in some cases before TURN was even designed), then TURN should work. The history of new protocol development is full of this sort of uneasy compromise: on the one hand we want to deploy new stuff and there are lots of network elements which are very hostile to that, often unintentionally. On the other hand, a situation in which the applications are just at constant war with the administrators is a recipe for breakage.
With that said, in the past few years attitudes towards network-based blocking have changed a fair bit, including technologies like DNS over HTTPS, QUIC, and TLS Encrypted Client Hello which are intended to make it harder to selectively block traffic unless you have control of one of the endpoints. If TURN were being designed today, I'm not sure the same choices would be made.
Why not TCP #
While it's possible to run TURN over TCP, you really don't want to if you can avoid it because performance will generally be bad. Covering this topic fully is out of scope for this post (though stay tuned for my long-delayed posts about transport protocol performance), but here is a brief sketch to help you build some intuition.
Head-of-line Blocking #
The first problem derives from the fact that TCP delivers packets to applications in order. However, this means that if a packet is dropped, then every packet received after that is held by the receiving TCP implementation until that packet is received, as shown in the following diagram:
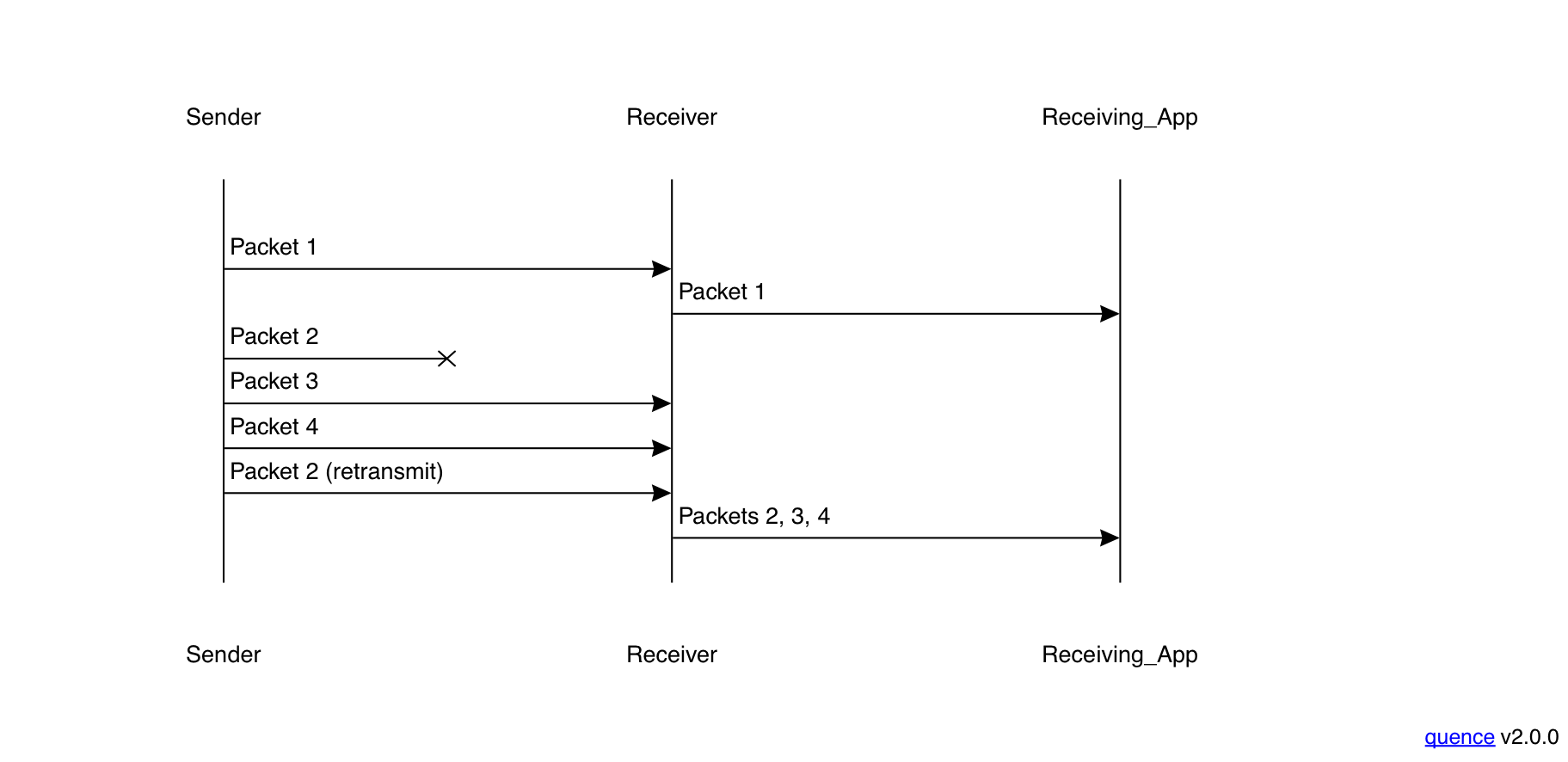
In this case, the sender sends packet 1 which arrives at the receiver and is delivered to the app immediately. However, Packet 2 is dropped and so packets 3 and 4 are just buffered until Packet 2 is retransmitted, at which point all three are delivered. For more on this topic see my introductory post about transport protocols. This phenomenon is called head-of-line blocking (HOLB).
HOLB is fine for applications where everything happens in order but less good for audio and video (A/V). A/V consists of a series of independent pieces of media, short sound snippets of 20-50ms in the case of audio, and frames in the case of video. In order to have a good experience, these need to be played out at regular intervals or the media will look and/or sound choppy. Of course, the network doesn't deliver them at exactly the right time, so the receiving implementation delays them a little bit in what's called a jitter buffer before playing them out.
The key word here is "a little bit": media latency of more than 200 ms or so is intensely undesirable. However, it's not uncommon for TCP implementations to wait far longer than this for retransmission, during which all the media would be delayed. In these cases, it's better to just drop the missing frame and play the next frames at the appropriate times. Fancier implementations use packet loss concealment techniques to fill in the missing data, but even if you just play the next frames it's better than waiting. With UDP, packets are delivered to the application at the time of receipt, but the TCP logic is all in the operating system, so there's no way to get any data until all earlier data is received.
Rate Control #
The second problem is that TCP is designed to adapt its sending rate to match network conditions, in part by buffering data until it thinks it's safe to send. The problem here is that unless the media sender is also adapting its rate to network conditions, then it's sending data to TCP faster than it can be transmitted, which creates buffering and/or packet loss. Rate control for real-time protocols is a complicated topic, but the TL;DR is that you really only want to have one rate control regime, which should be at the media layer, and then the network protocols just transmit whatever they are asked to right away. Sending over TCP prevents that. Obviously sending over TCP is better than not being able to make a call at all, but if at all possible you want to send your media over UDP.
TURN Server Deployment Scenarios #
In ICE, both sides will generally have TURN servers, in which case each side will offer relayed candidates. Depending on the properties of each network, ICE might end up using neither relayed candidates, have one of the sides talk directly to the other side's relayed candidate, or have the traffic go through both relays. In general, because TURN's mapping and filtering model are fairly permissive, it will generally not be necessary to go through both TURN servers unless both sides have really unfortunate networking configurations.
Note that with WebRTC generally both sides will use the same TURN server. When TURN was first designed, real-time communications over IP mostly meant people with softphones or hardware IP phones. Those devices were associated with some provider, whether it was an enterprise system or a consumer VoIP provider. In either case, the provider would supply the TURN server (recall from part III that running TURN servers isn't cheap). If someone from provider A is calling someone from provider B—though SIP federation was never as common as people were hoping—then you might have a situation where each user had a different TURN server. By contrast, most WebRTC deployments are in settings where there is only one provider and so everyone uses the same TURN server.
Note that most conferencing systems are deployed in a star configuration in which each participant sends their media to a central media conferencing unit (MCU) or switched forwarding unit (SFU).[5] Because these servers are both on the open Internet, it's much less likely you will need to use a TURN server. Because you don't need to get through a NAT or firewall on the server side, it should work even if you have a really uncooperative NAT. The main time you would need a TURN server in this environment is if you were behind a firewall which blocked all media (e.g., because it blocked UDP). Note that if the MCU/SFU and TURN server are operated by the same entity, there is an opportunity to integrate them closely, though I don't know if people actually do this.
Final Thoughts #
Out of the whole IETF NAT traversal protocol suite, TURN probably feels the oldest, even though it was designed at about the same time. It's a bespoke application relaying protocol built on top of a protocol which was originally designed for a totally different job, namely discovering your reflexive IP address. In the modern era, we'd probably build something fairly different and more like MASQUE, which is a generic UDP proxying protocol built on top of HTTP/3 and QUIC. On the other hand, STUN and TURN are a lot simpler than QUIC, they get the job done, and they're already built in browsers and softphones, so I imagine we'll be using them for some time.
You could actually omit the length field as well if you restricted yourself to UDP and only sent one packet per UDP datagram. ↩︎
The reason for the magic cookie is to ensure that it could easily be demultiplexed from any protocol, whether it had this distinguishing first byte or not. The cookie is just a fixed 4 byte value that is at the same position in every STUN packet. It's unlikely that it will be in the same position in other protocols and so helps identify STUN. ↩︎
Note that it's not necessary to run TURN over TLS in order to protect the media, which needs to be encrypted anyway. ↩︎
It's also possible to run turn over DTLS, but this isn't much more likely to work than regular TURN. ↩︎
These are different, but the difference doesn't matter for these purposes. ↩︎