How NATs Work, Part III: ICE
Yes, this is actually how things work
Posted by ekr on 02 Jul 2023
The Internet is a mess, and one of the biggest parts of that mess is Network Address Translation (NAT), a technique which allows multiple devices to share the same network address. This is part III in a series on how NATs work and how to work with them. In part I I covered NATs and how they work, and part II covered the basic concepts of NAT traversal. If you haven't read those posts, you'll want to go back and do so before starting this one, which describes the main standardized technique for NAT traversal, Interactive Connectivity Establishment (ICE).
As you may recall from part II, there are many circumstances where two endpoints (clients) want to communicate directly rather than through a server. However, your typical Internet client is also behind a NAT or firewall, which means that you can't just publish your address and have people connect to you as they would with a Web server. Instead, you need some NAT traversal mechanism. When the IETF originally set out to address the problem of NAT traversal, the idea was that you would characterize the NAT (i.e., figure out what its behavior was) and use that information to publish an address that would work via a signaling server. Once each side has the other side's address, it can try to transmit to it, as in the diagram below:
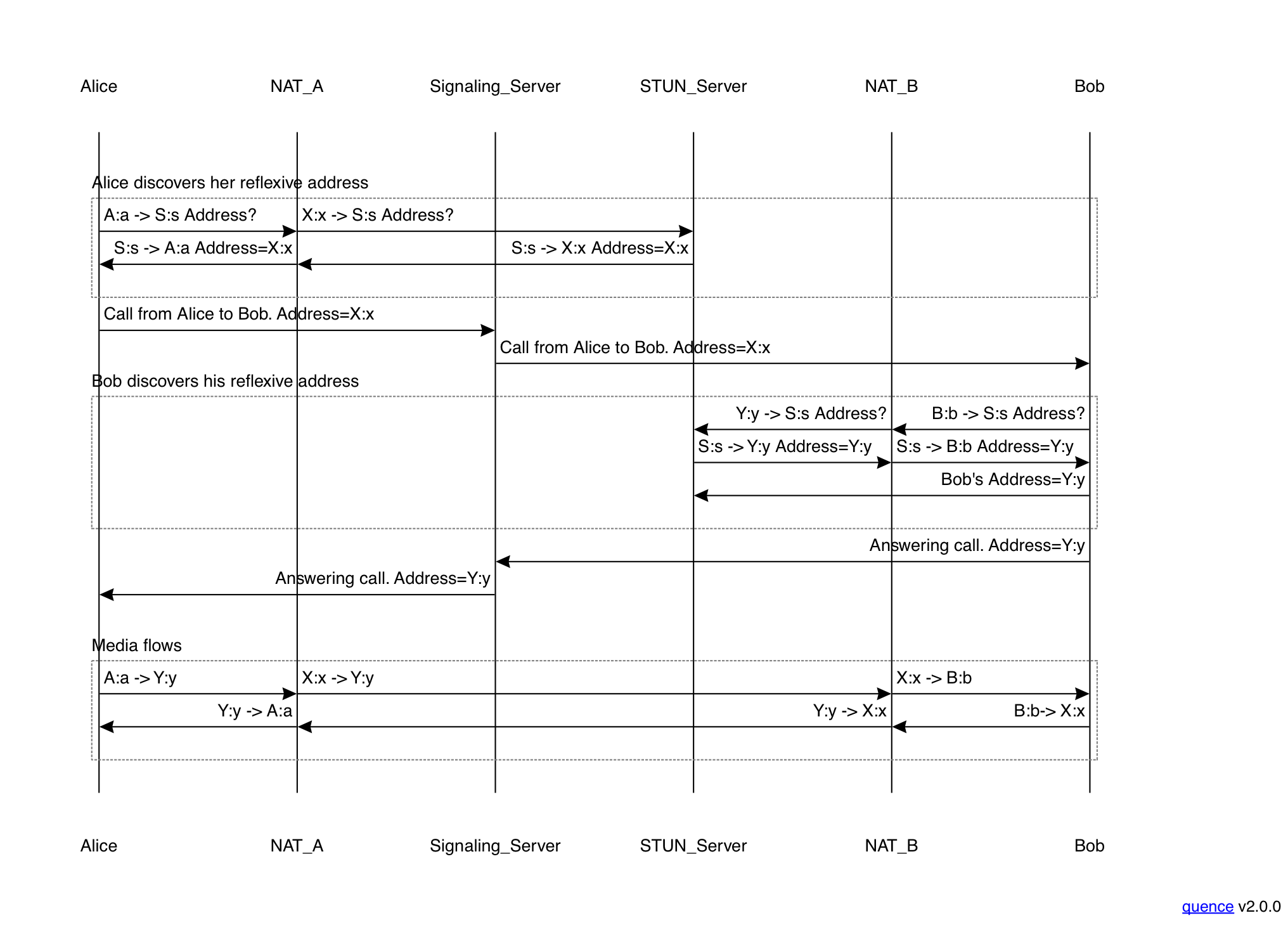
Unfortunately, that there was too much diversity in NAT behavior to make this work reliably, so we needed something else. Enter ICE.
Multiple Addresses #
Recall that the client will generally have multiple addresses, as shown in the diagram below [Updated for clarity 2023-07-02]:
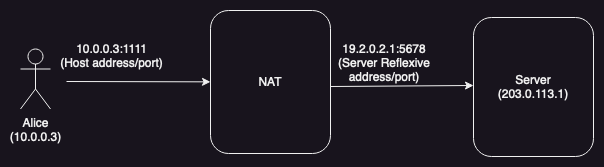
In this case, the client has two addresses:
- The host address (10.0.0.3:1111)
- which is the one assigned to its own network interface and which it is directly aware of.
- The server reflexive (srflx) address (192.0.2.1:5678)
- on the outside of the NAT. The client can typically only learn this by connecting to the STUN server and asking it what address it sees.
Now what happens if two clients with this kind of topology want to talk to each other. There are two main scenarios, as shown in the diagram below.
-
The clients can be on different networks (probably the normal case on the Internet)
-
The clients can be on the same network (as is common in Enterprise or gaming scenarios, for instance if you have multiple players in the same house and hence the same network)
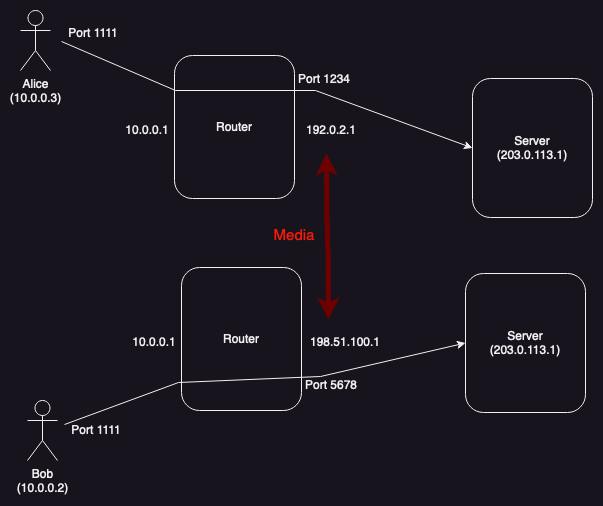
Clients on different networks
Clients on the same network
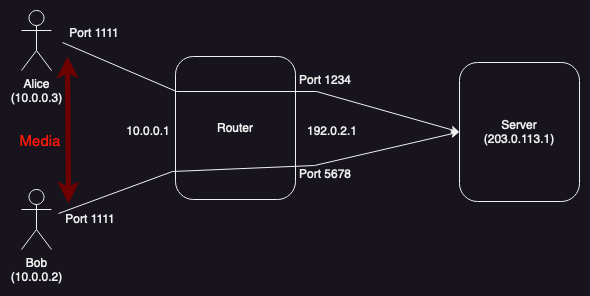
The reason that this matters is that neither the host address nor the server reflexive address will work all the time. For obvious reasons, if Alice and Bob are on different networks and Alice sends Bob her host address, Bob won't be able to address it from his own network (in this case, they actually share the same address range, but those addresses are actually on different networks, so there might be another host with Alice's address on Bob's network). On the other hand if they are on the same network and Alice sends Bob her server reflexive address, this may not work if the NAT doesn't support hairpinning.
What you want is for the media to take different paths (shown in red) depending on the topology: if Alice and Bob are not [corrected, 2023-07-02] on the same network, the media should flow between the server reflexive addresses (on the outside of the NAT) and if they are on the same network it should flow between the host addresses (on the local network interfaces). The problem is determining which of these address pairs to use, because it's not practical to determine which scenario you are in.[1] If neither address is guaranteed to work, the only option is for each side to send both addresses. In this case, Alice would send Bob two addresses (ICE calls these "candidates"):
1.0.0.3:1111(host)192.0.2.1:1234(server reflexive)
Bob would send Alice:
1.0.0.2:1111(host)198.51.100.1:5678(server reflexive)
Once Alice sees Bob's addresses, she tries to transmit to both of them, as shown below:
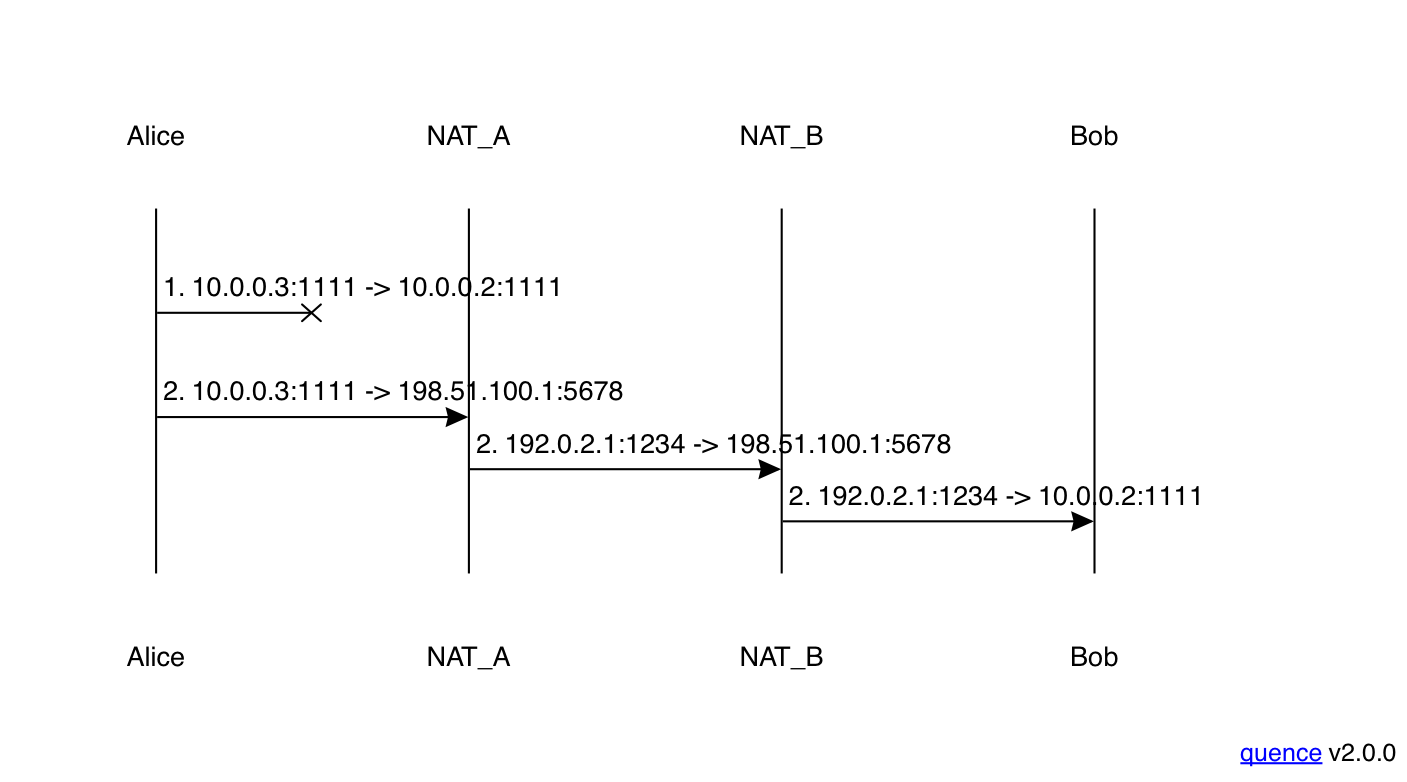
In this case, Alice and Bob are on different networks, so
Alice's attempt to transmit to Bob's host candidate (10.0.0.2:1111)
doesn't work, but her attempt to transmit to his server
reflexive candidate (198.51.100.1:5678) does, though
it goes through two layers of translation along the way.
If we drew Bob's side of the exchange, it would look
similar.
If you look at this diagram closely, you will notice something potentially surprising: Alice only sends two packets, even though their are four pairs of addresses (host/host, host/server reflexive, server reflexive/host, and server reflexive/server reflexive). Why doesn't Alice try to send from her server reflexive address? The answer is that there is no way for her to do so. Alice can only send packets from her host address: if they go through the NAT, it will translate them into the server reflexive (or maybe some other address) and if they don't go through the NAT they won't be translated, but Alice can't control this. In either case, Alice just needs to send one packet to each address from the other side.
Connectivity Checks #
Sending to both of Bob's addresses lets Alice get traffic through, but we obviously don't want to have to send two copies of every packet (or worse, if Bob has more addresses, as discussed below). What we need is a mechanism for Alice to determine which of the packets got through and then she can only send on that address pair. As you might expect if we read my post on reliable transports, we do this by having Bob acknowledge Alice's packet in what's called a connectivity check.
Instead of sending media to Bob, Alice sends a STUN check[2] to Bob (much like she would if she were trying to learn her address from a STUN server) and waits for the response. If Bob doesn't answer, she can infer that that address pair won't work. If he does, then she knows that this is a valid address pair and can then use it to send media (Alice knows which checks worked and which ones didn't because the check and the acknowledgment contain an identifier, which I haven't shown in the diagram to keep things simple).
This process is shown below:
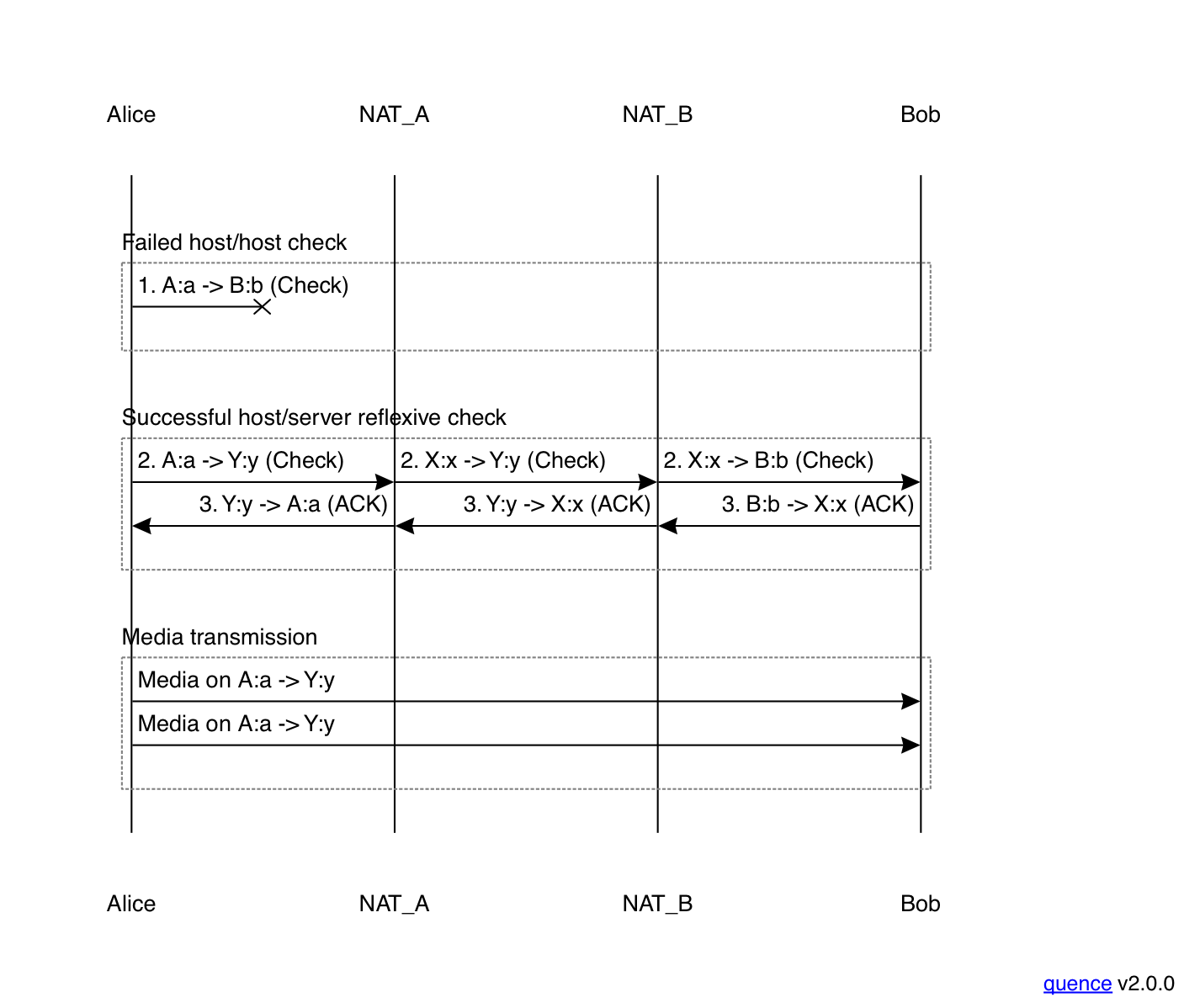
I'm obviously simplifying quite a bit here. In particular, because packets can get lost, Alice has to retransmit her STUN checks for a while; otherwise a single packet on a valid address pair might get lost. For instance, if packet 2 got lost, and Alice didn't retransmit, then Alice would be left with no valid pairs.[3] Moreover, as discussed in the next section, there are reasons besides network failure why one of the packets might be dropped.
Bidirectional checks #
First, as discussed in part II, if Bob doesn't transmit at all but just responds to Alice's checks, then Alice's checks may never get through. If Bob's NAT has address/port-dependent filtering, then it will drop any incoming packets on a given NAT binding until Bob has sent an outgoing packet; this requires Bob to initiate his own checks, as shown below:
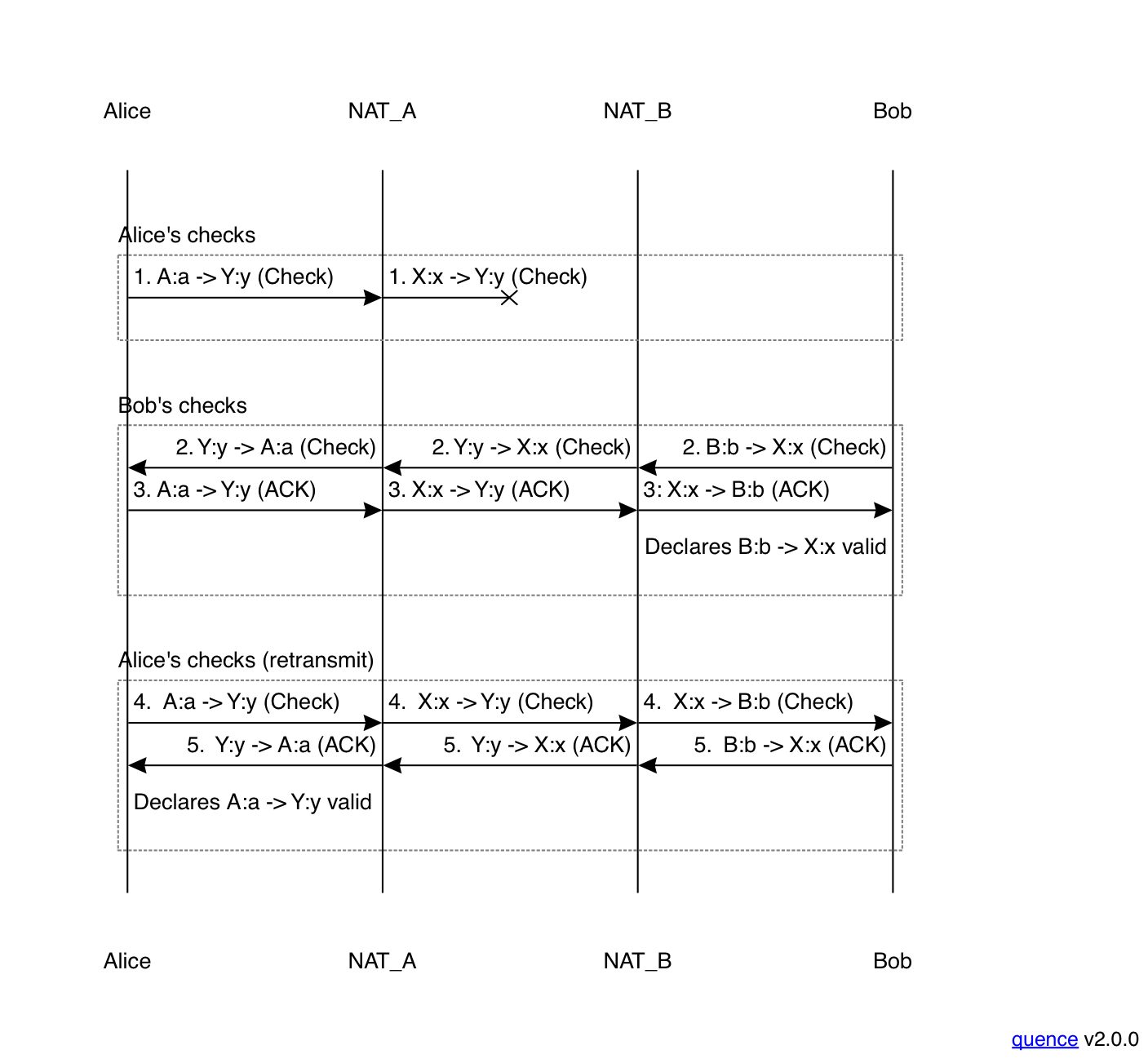
To walk though this a bit, Alice starts by sending a check (msg 1)
but because Bob has address/port filtering NAT, it filters out
the packet. When Bob initiates his own check (msg 2), it creates a binding
on his own NAT on the way out and gets delivered to Alice (this works
even if Alice also has address/port dependent filtering because
her outgoing packet created a binding). Alice receives the packet
and sends an ACK (msg 3) which is able to traverse Bob's NAT because
of the aforementioned binding. At this point, Bob knows that the
pair B:b -> X:x works and that it's safe to transmit on that address pair.
When Alice's client retransmits its check (msg 4) it is able to
get through Bob's NAT (again because of the outgoing binding created
by message 2). Bob receives it and sends an ACK, and at this point
Alice knows that the pair A:a -> Y:y works and it's safe to transmit
on it. Note that this would have worked perfectly well if Bob had
transmitted first (just flip the diagram around), and of course each
side is retransmitting anyway.
At this point you might ask why Alice needs to do a second round of
connectivity checks after receiving; after all, she knows that Bob can
successfully transmit on the Y:y -> X:x path and she can receive it.
However, she does not know that messages on the return path
(X:x -> Y:y) work. For instance, Bob might have a firewall
that blocks all incoming UDP packets, in which case Alice's
ACK would be blocked (which she wouldn't learn about) as well
as her own connectivity checks. If she sends her own checks, then
she will learn that that path doesn't work and can try something
else. In practice, however, this scenario is reasonably uncommon
and it's quite likely that when Alice received Bob's check that her
check in the reverse direction will also work.
Relayed Candidates #
As mentioned in part II, there are situations in which it is not possible for Alice and Bob to directly send traffic to each other, for instance if both of them have NATs with address-dependent mapping. In that case, getting a successful connection requires using a relay, which is just a public server on the Internet that will forward traffic to and from a machine, like so:
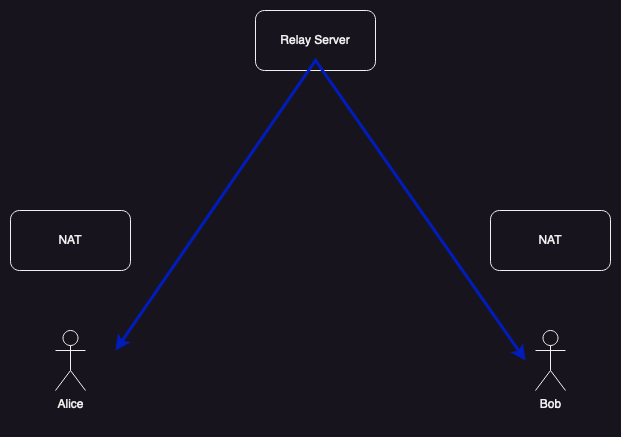
In standard ICE, clients speak to the relay over a protocol called Traversal Using Relays Around NAT (TURN). Because the TURN server is on the public Internet and not behind a firewall or NAT, it will almost always be possible for the client to connect to it—assuming that it's possible for the client to connect to any other network element at all. Note, however, that the client may have to use TCP if the local network blocks UDP.
It's quite cheap to run a STUN server because it just has to respond to a small number of packets per client, and there are a number of free public STUN servers. However, a TURN server has to be able to relay all of the media between the clients, which can be quite a bit of bandwidth. For this reason TURN servers are usually not free but rather are provided by the calling service people are using. Because a modest fraction (single digit percentages) of people cannot connect without a TURN server, this means that there is a certain minimum cost to running a video calling service even if you prioritize peer-to-peer media.
Picking the best path #
At a high level, then, there are (at least) three potential paths data can take between Alice and Bob, as shown below:
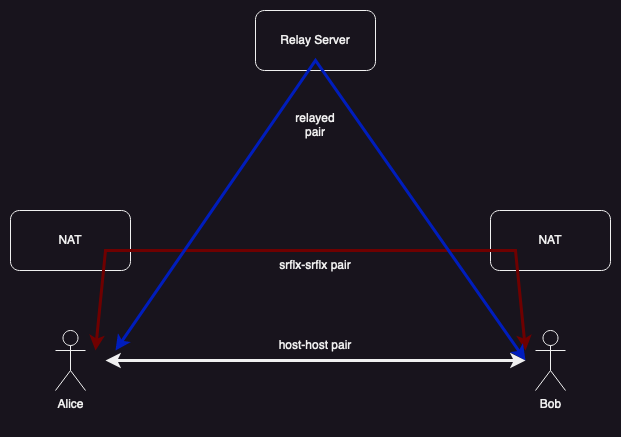
It's also quite possible that there will be multiple viable paths. As noted above, a path through a relay will almost always work, but it's also quite common that it's possible to have a direct path between Alice and Bob.
These paths are not all created equal. Latency is a key performance property for real-time voice and video. If the delay between you speaking and the other side hearing you is too long it creates a really jarring experience. If you've ever been on such a call you may have noticed that you and the other person end up interrupting each other a lot because the pauses in the conversation that leave room for the other person to talk get delayed as well, with the result that both people try to talk at the same time. In general, shorter (fewer hops) network paths will have better latency, both because more hops will often mean more meters of cable/fiber to traverse and because the hops themselves take time.[4] In particular, if you can send media directly rather than going through a relay, you really want to do that, both for performance and cost reasons.
Lots of Candidates #
This is really the simplest possible scenario. In practice the client might have many more addresses. For instance, the client might have:
-
Both a WiFi interface and a mobile phone interface, each of which will have their own address.
-
Both IPv6 and IPv4 addresses.
-
A VPN, which has its own address.
-
Multiple NATs between it and the Internet (e.g., if it is served by a carrier grade NAT), each of which will have its own server reflexive IP addresses.
-
On or more relayed connections through TURN relays.
What ICE does is (approximately) to try the combination (Cartesian product) of all of the candidates from Alice and all of the candidates from Bob until it identifies a set of candidates that work (the "valid set"). Of course, some candidate pairs will not be possible (e.g., mixed IPv4 and IPv6), but it's still possible to have quite a few compatible candidates and hence quite a few candidate pairs. As a concrete example, the machine I am writing this on has two interfaces (wired and wireless), each with local IPv4 and IPv6 addresses, but not IPv6 connectivity, so that gives me 4 host candidates, 2 server reflexive candidates (for v4 only), plus at least one relayed candidate. If I'm connecting to another similar machine, we're potentially looking at something like 15 IPv4 pairs (remember, you don't pair up the server reflexives locally) plus 4 IPv6 pairs. It's a lot!

Peer-Reflexive Candidates #
You may recall from part II that some NATs have address and port-dependent mappings, in which case the candidate gathering process will find a different external mapping (the server reflexive address) for a given internal address/port than is observed by the peer (the peer reflexive address). What this looks like to the peer is that it receives a check from an address that it doesn't have a candidate for. Fortunately, there is enough information in the STUN check to determine what is going on, and the endpoint responds by synthesizing a remote peer reflexive candidate, pairing it to its local candidate, and starting checks to it. The other side doesn't have to do anything special here, because—as with server reflexive candidates—it automatically sends requests from the peer reflexive address just by sending to the peer.
Prioritizing Checks #
A naive implementation of ICE would just send all the connectivity checks at the same time. This turns out not to work well because you can overload the Internet link or the NAT, causing them to drop packets, thus making ICE take longer to converge. Instead, you need to space out the checks over some time. However, you also want ICE to find a viable path as soon as possible because while ICE is running the user is just sitting there waiting—depending on the design maybe listening to ringtone.
In order to optimize the time to convergence, ICE uses a prioritization scheme designed to provide two main properties:
- The most direct candidate pairs are checked first.
- As discussed above, you want media to traverse the most direct path. ICE is designed so that it also checks the most direct paths first. I'm actually not so sure about this design decision—in particular, the host/host paths often will not work—but it's what ICE does.
- Checks are roughly synchronized between both sides.
- Remember that in many cases, in order for Alice's checks on a given candidate pair to succeed, Bob also needs to run a check in order to create a binding in his NAT. If Alice checks that candidate pair first and Bob checks that pair last, then (at best) Alice's check won't succeed till the very end of the ICE process. At worst, by the time Bob's check runs Alice's NAT binding will have timed out and both checks will fail. This isn't that likely in most networks; in practice the ICE process would just be slower than ideal.
Of course, synchronization is only loose. Let's look at the case where both sides run checks again:
Recall that in this scenario Alice runs her checks, which fail but open a binding in her NAT, allowing Bob's check to succeed. Eventually, Alice would retransmit her checks, but this might take some time because retransmits, like the checks themselves, need to be paced to avoid overflowing the network. Because it's very probable that Alice's check will work, ICE includes an optimization called triggered checks in which an endpoint immediately (well, mostly immediately) schedules a check in the reverse direction upon receiving a check. This allows Alice to quickly discover that the path that is likely to work actually does work in the common case where it is valid.
Multiple Media Paths/Frozen #
There's an additional complication. When ICE was first designed it was standard practice to use different address pairs for different streams of media. For instance, if you had an audio and video call, you would use different ports for them. Moreover you needed twice as many ports because the media protocol that is in use here (Real-time Transport Protocol (RTP)), has an associated control protocol that is used for measuring packet delivery and that also used its own ports. In other words, a simple two person A/V call could need as many as four separate address/port pairs, which means that you need four times as many candidate pairs (two each for audio and video), and hence four times as many checks. ICE's term for these flows is "components".
This may be hard to visualize, so imagine a simplistic case in which we only have host and server reflexive candidates and we only want to establish two components. If we go back to our example above, Alice would have the following candidates:
| Type | Address | Usage |
|---|---|---|
| Host | 1.0.0.3:1111 | Audio |
| Server Reflexive | 192.0.2.1:1234 | Audio |
| Host | 1.0.0.3:1112 | Video |
| Server Reflexive | 192.0.2.1:1235 | Video |
And Bob would have:
| Type | Address | Usage |
|---|---|---|
| Host | 1.0.0.2:1111 | Audio |
| Server Reflexive | 198.51.100.1:5678 | Audio |
| Host | 1.0.0.2:1112 | Video |
| Server Reflexive | 198.51.100.1:5679 | Video |
Looking at it from Alice's perspective, she has four candidate pairs to check (recall that Alice doesn't need to pair her srlfx candidates with Bob's candidates).
| Local | Remote | Type | Usage |
|---|---|---|---|
| 10.0.0.3:1111 | 10.0.0.2:1111 | Host ↔ Host | Audio |
| 10.0.0.3:1111 | 198.51.100.1:5678 | Host ↔ Srflx | Audio |
| 10.0.0.3:1112 | 10.0.0.2:1112 | Host ↔ Host | Video |
| 10.0.0.3:1112 | 198.51.100.1:5679 | Host ↔ Srflx | Video |
In order to optimize these checks, ICE takes advantage of the observation that NAT behavior is likely to be consistent, so if a set of candidates works for the audio component then a set of similar candidates (though of course with different addresses) is likely to work for the video component. In order to exploit this, ICE initially only checks one set of candidate pairs for each type and sets the others as frozen. If the first candidate pair succeeds, then ICE unfreezes the others. This avoids doing redundant checks in parallel. In this case, at the start of ICE, we would have a situation like this:
| Local | Remote | Type | Usage | State |
|---|---|---|---|---|
| 10.0.0.3:1111 | 10.0.0.2:1111 | Host ↔ Host | Audio | Checking |
| 10.0.0.3:1111 | 198.51.100.1:5678 | Host ↔ Srflx | Audio | Checking |
| 10.0.0.3:1112 | 10.0.0.2:1112 | Host ↔ Host | Video | Frozen |
| 10.0.0.3:1112 | 198.51.100.1:5679 | Host ↔ Srflx | Video | Frozen |
ICE would first check the pairs listed as "checking"[5] Then if the audio host ↔ host candidate pair works, ICE would unfreeze the corresponding video candidate pair.
| Local | Remote | Type | Usage | State |
|---|---|---|---|---|
| 10.0.0.3:1111 | 10.0.0.2:1111 | Host ↔ Host | Audio | Succeeded |
| 10.0.0.3:1111 | 198.51.100.1:5678 | Host ↔ Srflx | Audio | Checking |
| 10.0.0.3:1112 | 10.0.0.2:1112 | Host ↔ Host | Video | Checking |
| 10.0.0.3:1112 | 198.51.100.1:5679 | Host ↔ Srflx | Video | Frozen |
The result of this is that once you determine that a given type of candidate pair works, you start checking the rest of the pairs of that type; as with triggered checks the idea here is to converge to a working set of candidate pairs as fast as possible.
As I said above, I'm simplifying a bunch and there's more to candidates being "similar" than just the types of the candidates. For instance, if I have both wired and WiFi network interfaces, each of those would have a candidate. If the wired candidate pairs succeed, I would just unfreeze those but not the wireless pairs. The way this is captured in ICE is by assigning each candidate a "foundation" that characterizes the candidate (based on IP address, type, etc.). The foundation of a candidate pair is the pair of local and remote foundations.
This is clearly not a great situation but, remember we're not building from scratch. VoIP systems are built out of technologies designed back in the 1990s when people had different ideas about how to design networking protocols (and in particular when NATs and firewalls were less ubiquitous). Eventually, the IETF worked out how to multiplex multiple flows on the same address/port quartet using a pair of technologies called RTCP-mux and BUNDLE). This actually represents years of engineering work to retrofit the protocol mechanisms without causing backwards compatibility issues, but fortunately it mostly works now, so if you're on a modern system you're back to only needing a lot of checks rather an absurd number.
Selecting Pairs #
OK, we're almost to the end now. Alice and Bob are running checks, some of which succeed and some of which fail. As noted above, it's quite common for more than one candidate pair to succeed for each path because the host ↔ srflx candidate pair will often work and one of the relayed candidate pairs will almost always work. This means you have multiple paths that might work, so now what?
You could just have each side independently pick its favorite candidate pair and send on it, but this turns out to be bad idea. Remember that many NATs time out their bindings after a short period (10-30 seconds) of inactivity and that it's outgoing packets that keep the binding alive. If Alice and Bob use different paths, then Alice may not be sending the packets that keep the binding open for Bob's incoming packets. If Alice and Bob use the same candidate pair, then the path will be symmetrical and the binding will stay alive. This means we need some mechanism for picking which pair the endpoints will use.
In modern ICE, this works by having one endpoint (the "controlling")[6] side pick which pair to use. The controlling endpoint runs checks for each component until one succeeds that it wants to use (the actual logic here is unspecified, but typically you'd do something like wait until one of the direct pairs worked or they had all failed and one of the relayed pairs had succeeded) and then it sends another check on the same pair with the USE-CANDIDATE flag (this is called "nominating" the pair). When the (controlled) peer sees that flag it knows to use that candidate pair going forward. When the controlling side's check succeeds—which should always happen if the pair is already successful—then it knows it is safe to use the pair as well and from here forward both sides will just use that pair.
Of course, it might take some time for the controlling endpoint to run enough checks to feel comfortable picking one, and you want to have media start flowing right away. To accommodate this, ICE allows endpoints to start sending media as soon as they have a valid pair, even before one has been nominated.[7] This shortens setup latency while allowing time for the controlling endpoint to nominate the optimal pair. Usually this will happen quickly enough that you don't need to worry about the bindings timing out. It does mean, however, that the path the media takes may change as the ICE checking process proceeds.
Trickle ICE #
Classic ICE is a sequential process:
- Gather all your candidates and send them to the other side.
- Receive the other side's candidates
- Run checks
This all works fine if candidate gathering is fast, but what if it's not? For instance suppose you are behind a firewall which blocks UDP and you have to use TCP to connect to the relay server? If the firewall just drops the packets without sending you errors, you're waiting for the candidate gathering process to time out. This might take several seconds (potentially more, depending on your timers) to discover. In the meantime, people are just waiting, which isn't ideal.
To deal with this, the Google Hangouts team invented a technique called trickle ICE,[8] in which each side sends candidates as soon as it has them, so that they "trickle" in over time. This creates some additional complexity because you have to incrementally pair new local or remote candidates, but has the potential to significantly decrease the time to connection establishment. This is especially useful in the context of WebRTC, when the Web site doesn't necessarily know in advance which of the various STUN or TURN servers it is offering will actually be reachable by the client.
Backwards Compatibility #
As described above, ICE has been through a number of iterations, and so it's possible that a modern endpoint will end up talking to an older endpoint. For example:
- An endpoint that supports RFC 8445 ICE might need to talk to an endpoint that supports RFC 5245 ICE.
- An endpoint that supports trickle ICE might talk to a non-trickle endpoint.
- An endpoint that supports component multiplexing (BUNDLE) might talk to one that does not.
In the classic SIP softphone setting, there's no real way to know what the peer supports, so you need to send ICE information that is compatible with the other endpoint.[9] For instance, if you support trickle but you don't know what the other side supports, then you need to gather all the candidates you will need anyway, but you can say in your message that you support trickle, and so the other side can use it (this is called "half trickle").
Similarly, if you support component multiplexing, but you don't know if the other side does, then you may need to gather candidates for all the components, even if the other side is going to throw most of them away. This can get quite expensive, however, and the default for WebRTC is what's called "balanced" mode, in which you gather candidates only for the first stream of each type (e.g., the first audio channel). If the other peer supports bundling components, then this works fine, and if it doesn't, then only the first stream connects. Of course, actually designing something that fell back gracefully in this situation instead of just freaking out because there were no candidates available for the later components took some doing.
The situation is a bit better if you know you are doing a call that is WebRTC on both ends—e.g., because both ends are browsers or one end is a modern conference server—for two reasons. First, the WebRTC specifications (specifically JSEP) require support for multiplexing (both BUNDLE and RTP/RTCP) and for trickle ICE, so you know you have a modern endpoint on the other side. Second, the server can use JS APIs to determine the capabilities of each endpoint, so it has a better chance of getting an interoperable configuration.
Security #
The threat model for ICE is confusing for a number of reasons:
-
A full network attacker will generally be able to manipulate packets (e.g., drop them, send them with a bogus IP, etc.) and so you have limited protection against such an attacker.
-
If you use media encryption between the endpoints—as was uncommon back in 2010 when ICE was first designed but is mandatory in WebRTC—then even an attacker who sees all the packets has limited abilities.
-
In the WebRTC case, the Web site actually invoking the APIs may be an attacker, though they probably do not control the network.
In general, then, we have three main objectives:
-
That an attacker who can't see your packets can't interfere with connection formation or reroute traffic to themselves.
-
That an attacker who can see packets can't just forge arbitrary content (more on this below).
-
That a non-network attacker driving the WebRTC API (or a SIP peer, though this is a weaker attacker) can't force you to connect to someone besides themselves by providing their address in a candidate.
Most of these attacks are prevented by two security mechanisms found in STUN:
-
Each STUN message is cryptographically protected (via an authentication tag that prevents tampering with the message) with a username and password exchanged along with the ICE parameters.
-
Each STUN check has a unique 96-bit transaction identifier which must be echoed in the response.
These two mechanisms work together.
Because the credentials are not known to network attackers, they are unable to forge requests or responses. This is not a complete defense because—as noted above—a full network attacker can take a valid packet and send it from a fake IP address, thus causing the receiver to think it came from somewhere else (as in a peer reflexive address) but they can't tamper with the contents, but it prevents a number of attacks. The username mechanism also prevents cases of ambiguity in which a STUN check arrives at another endpoint which just happens to be doing STUN. Because the username will be different, it will not respond to the check.
However, the username and password mechanism does not prevent attacks by a Web site using WebRTC, because that site knows the username and password. However, because the transaction ID is unpredictable—and importantly, not revealed to the site's JavaScript—it can't forge a response to any check it doesn't receive. Thus, ICE establishes that the receiver of the traffic has consented to receive it.
Final Thoughts #
It's important to remember how we got here. In part I I wrote:
NATs provide a particularly good example of the way the Internet evolves, which is to say workaround upon workaround. The reason for this is what Google engineer Adam Langley calls the "Iron law of the Internet", namely that the last person to touch anything gets blamed. The people who first built and deployed NATs had to avoid breaking existing deployed stuff, forcing them to build hacks like ALGs and unpredictable idle timeouts. Now that NATs are widely deployed, new protocols have to work in that environment, which forces them to run over UDP and to conform to the outgoing-only flow dynamics dictated by the NAT translation algorithms.
As we can see with ICE, it's not just a matter of working with existing NATs but of working with all the previously deployed systems that were deployed before ICE was available, as well as working with previous versions of ICE. The result is a system of extreme complexity which almost nobody really understands, which has to run before even the first byte of media is delivered. And yet, it mostly works, as you can see for yourself if you use any WebRTC-based calling system such as Meet or Teams.
The astute reader may have noticed that in the "different network" scenario, Alice and Bob's server reflexive addresses have different IPs whereas in the "same network" scenario they have the same IP address. You might think you could compare the addresses to determine which situation you were in. Unfortunately, this isn't dispositive because Alice and Bob might be behind a carrier grade NAT which had a pool of multiple IP addresses that it assigned from. Because of the way that IP addresses are assigned, it's not generally possible to determine whether two addresses belong to the same network. ↩︎
When all you have is a hammer, everything looks like a nail. ↩︎
Technical note: Bob doesn't retransmit his ACKs; he just responds to Alice's retransmissions. This is a pretty typical reliability design because otherwise you end up worrying about whether ACKs were delivered and having ACKs of ACKs, which is a mess. ↩︎
This is of course not always true, but it's a good rule of thumb. ↩︎
I'm simplifying the algorithm here as they would actually start in Waiting and then move to In-Progress. ↩︎
Don't make me explain how we decide which is which. ↩︎
In the original version of ICE, there was instead something called "aggressive mode" in which the controlling endpoint would send USE-CANDIDATE on multiple pairs and the controlled endpoint would pick the highest priority one, but that was removed in favor of this rule. ↩︎
This idea, documented in XEP-0176 appears to be originally due to Joe Beda. Thanks to Justin Uberti for helping me track this down. ↩︎
You might even be talking to an endpoint that doesn't support ICE, but for all the reasons we've discussed here, that's basically not going to work. ↩︎