Understanding The Web Security Model, Part V: Side Channels
Posted by ekr on 09 May 2022
This is part IV of my series on the Web security model (parts I, II, outtake, III, IV). In this post, I cover data leaks via side channels.
Recall the discussion from part III about the basic guarantee of the Web security model, which is that it is safe to visit even malicious sites. As discussed in that post, the browser enforces a set of rules that are designed to provide that guarantee. It's of course possible to have vulnerabilities in the browser which allow the attacker to bypass those rules; for instance, there might be a memory issue that allows the attacker to subvert the browsers, at which point it can read the data directly. However, there is another important class of issue that has long been a problem in the Web, which is "side channel attacks".
Colloquially a side channel is a mechanism that isn't part of the specified API surface but which can be used to leak information. In a side channel attack, the program can be behaving correctly but there is some unintended observable behavior that allows an attacker to learn secret information it should not have. Historically, side channel attacks in browsers have had two main targets:
- User browsing history (i.e., what sites the user has visited), in violation of the browser's basic privacy guarantees.
- Data from other sites, in violation of the same origin policy.
As we'll see below, side channel attacks can be very hard to find and eliminate.
A Simple Timing Channel #
The general structure of most side channel attacks is that the there is some secret data that the attacker can't see directly but the attacker is able to observe some computation on the secret and use that information to learn about the secret. Consider, for example, the following code to check the correctness of a password.
bool checkPassword(const char *userPassword, const char *actualPassword) {
size_t i = 0;
for (;;) {
// If the ith character doesn't match, then
// return false.
if (userPassword[i] != actualPassword[i]) {
return false;
}
// If the ith character is '\0', then we are at
// the end of the string and they match, so
// return true.
if (actualPassword[i] == '\0') {
// userPassword must also be `\0` or we would
// have returned false above.
return true;
}
i++;
}
}The logic of this code is that you go through the both passwords
one character at a time and if there is a mismatch at any
character, we return false. It takes advantage of the fact
that C strings don't have an attached length but instead
use a character with value \0 to indicate the
end of the string.[1]
The explicit API of this function is that it just tells you whether a given password is valid or not. If you wanted to use this API to guess the user's password, you would in principle just have to check every password one at a time, and you don't learn any information unless you guess exactly the right password. If you assume 8 character passwords with only letters and numbers, then there are 62 possible values for each position and there are 62^8 possible (about 2^{48}) possible passwords. If you just try them one at a time, you'll find the right password about halfway through on average, so that is 2^{47} attempts, which will take quite some time (though is also practical on modern computers, which is why people tell you to use longer passwords).
Unfortunately, this function leaks more information
than just that explicitly provided by the API.
The problem is that this code is not constant time:
because it checks the characters one at a time, the time
to run the function depends on the number of characters
that match. This means that if an attacker can very precisely
measure the running time of the checkPassword() function,
they can learn information not provided by the API, namely
the first character which doesn't match.
Lockpicking #
Lockpicking exploits the same basic intuition about combinatorics. Your typical lock has a set of pins which prevent the lock barrel from turning. When you insert the key into the lock, the key pushes the pins up, as shown in the picture below. If the part of they aligned with given pin is the right height, it will push the pin up the correct amount, so it no longer blocks the lock barrel. If you get all the pins right, you can turn the key and the lock opens.

[Source: Wikipedia]
This would all be fine if the lock were perfect, because you'd have to get the key completely right and so you would have to try every possible combination in sequence, but in practice there's always some individual variation: When you try to turn the lock barrel, one pin will usually be the one that prevents it from turning ("binding"). You can exploit this by apply torque to the lock barrel and then using a tool to push up each pin in sequence. If you push up the pin that is binding the right amount (so that the break in the pin aligns with the lock barrel) the lock barrel will turn slightly until it binds on the next pin. You can repeat this process until you have all the pins and the lock opens.
If you just think naively about this function, you would expect its running time to be proportional to the number of matching characters. For instance, if it takes one nanosecond to check each character, then if the first three characters match, the function will take 4ns (to check the first three and then reject on the fourth). Note that real processors are much more complicated, as we'll see later in this post. You can use this fact to attack passwords very quickly. The basic idea is that you just generate a random candidate password and measure the running time of the function. If, for instance, it is 1ns, then this tells you that the first character is wrong.
You can then just iterate through all of the possible values for character 1 until the function runs in more than 1ns. When that happens, you know you have the first character right. You then keep the first character constant and iterate through the second character, and so on until you have broken the entire password. On average, you'll get the right character for each position about halfway through and so the total attack time is something like 31 * 8 (~250) attempts, which is obviously much faster than 247 attempts!
Of course, the signal here is very small: modern processors are very fast and there are other things happening on the computer besides just your task, so small timing differences can be hard to measure. However, there are now a more or less standard set of techniques for making this kind of attack work better. First, you can run the measurement a lot of times, which helps separate out the signal from the noise. Second, you can find ways to amplify the signal so that the slower operation gets a lot slower. We'll see an example of this below.[2]
Cross-Site State #
The first class of side channel attacks I want to talk about take advantage of browser features which share state across sites. Consider the situation where site A wants to know whether the user has visited site B. For obvious reasons, this is sensitive information: we don't want arbitrary attackers to be able to see your browsing history. Thus, the Web platform doesn't allow sites to ask directly about browsing history, but that doesn't mean it can't get the answer indirectly.
The simplest mechanism is via the browser cache. As I discussed last week, performance is a very high priority for Web sites, and downloading big files from a remote site takes time and bandwidth. One way to address this problem is for the browser to cache data from the server. When the browser first downloads a resource, it stores it locally and can just reuse the local copy rather than the one retrieved from the server.
The actual details of HTTP caching are quite complicated because
sometimes the cached value will be usable, but sometimes the server
will change the resource and the client has to re-retrieve it. Under
some conditions the client has to contact the server and ask if the
resource has changed, e.g., via the
If-Modified-Since
header, and in others the server can just say this resource will
never
change.
The common thread, however, is that getting resources from the local cache
is (hopefully)
faster than retrieving files from the server. That's the point of
caching but when combined with the fact that it's possible to measure
the load time for a cross-site resource, it gives us a timing leak.
The basic idea here is really simple: suppose that attacker.com
wants to know if you have gone to example.com. It adds a large
resource from example.com to its own site and measures how long
it takes to load. If the load is fast, then it is likely that the data
is in cache, which suggests that the user has been to
example.com.[3]
This attack has been known at least since a 2000 paper by Felten and Schneider, and turns out to be part of a giant class of such
issues, with browser state targets including: HTTP connections, DNS caching, TLS session
IDs, HSTS state, etc. The general problem is that any time there
is state that is shared between site A and B, activity on
A can potentially affect behavior on B.
The right
solution
was published by Jackson, Bortz, Boneh, and Mitchell in 2006:
partition client-side state by the top-level origin as well
as by the origin. For instance, in this case resources loaded
from example.com would be in a different cache from
those loaded from attacker.com, which means that when attacker.com
goes to load the test resource it will have to retrieve it
separately, even if example.com has already done so.
At this point you might ask why this hasn't been fixed. As far as I can tell, there are three main reasons: (1) the widespread use of cookie-based tracking made fixing these slower attacks less interesting (2) it's actually fairly complicated to address everything, in part because some of the required changes do change the observable behavior of Web browsers (3) there were concerns about the performance impact of reducing the effectiveness of caching. However, as Web privacy has become a bigger issue, browsers have started making a serious effort to address this class of attack, mostly via work in the W3C Privacy Community Group. This presentation by Anne van Kesteren does a good job of describing the situation.
Computation on Secret Data #
As discussed in part III, the same origin policy allows cross-origin use of data (for instance, embedding an image from another site) but forbids access to the data. In addition, it allows you to operate that data in a variety of ways that are intended to be safe because they don't allow you to see the result. It should surprise nobody to learn that these aren't actually safe.
Link Decoration #
Let's warm up with a simple example: Link coloring. CSS allows Web paged to apply styles (e.g., colors, underlining, etc.) depending on whether they have been visited or not. This helps the user know whether they need to click on a link or not. For instance, this fragment of CSS will turn all links red except those you have visited, which are blue.
a {
color: red;
}
a:visited {
color: blue;
}The Basic Attack #
This would all be fine except that it turns out that the Web also
lets you inspect the color of elements in the DOM using
the getComputedStyle() function. In 2002,
Andrew Clover observed
that this combination of
features creates a trivial
attack in which the attacker puts a bunch of links on their
page to sites they think you might have visited and then inspects
the color to see which ones you actually have visited. Obviously, the
attacker only gets to learn about pages it actually knows about,
so in some ways this isn't as good as cookie-based tracking,
but the attacker can send you a very big page with a lot of links,
so it can extract quite a bit of information.
Moreover, unlike cookie-based tracking, this attack can be used
to learn whether you have visited sites which aren't cooperating
with the attacker, such as their competitors!
This isn't just a theoretical issue. In 2010, Jang, Jhala, Lerner, and Shacham scanned the Alexa top 50,000 sites and discovered a number of sites doing history sniffing including two companies which that provided it as a service. For example, they found that the popular adult site Youporn used history sniffing to discover whether people were visiting their competitor Pornhub and third party ads on a number of sites checked to see if users had gone to various car-related sites.
The basic URL color attack is now fixed, though only as of about 2010. The fixes turn out to be fairly complicated, as described by David Baron in this post describing the fixes deployed in Firefox. The basic defense is to have the browser lie about various CSS selectors that let you query whether links were visited, by acting as if they were limited. However, this isn't enough because there are other CSS mechanisms that would let you (for instance) perturb the layout of the page and thus observe whether it reflowed. The complete fix requires also limiting the style changes that CSS can apply based on whether a link is visited to those which (hopefully) do not leak information. Other browsers have followed suit, in part due to pressure from the US Federal Trade Commission after Jang et al. published their work.
Side Channels #
Arguably this isn't even a side channel attack,
because we're using an official API: the problem is just
an unexpected result of combining two APIs. So, when
we remove those APIs the problem will be solved, right?
Of course not. Even without these APIs, the same data
turns out to be accessible via a number of side channels.
Many of these side channels work by observing that if
you change the appearance of a link, this can cause
the page to be repainted, which can be detected by the
attacker's script.
This means that is you have a link which is unvisited
and then change the URL to be one that is visited, it
causes a repaint, allowing you differentiate visited
from unvisited links.
Initially, the repaint was directly measurable in Firefox
with the mozAfterPaint event, but it was
later
removed
to avoid exactly this kind of link.
However, even without an explicit signal, it's still possible to detect repaints, as described by Paul Stone. Normally repainting is fast, but if you can make the repaint slower, then you can measure it. The trick is to apply some CSS effects to the link (e.g., drop shadows) that take time to compute. These effects aren't conditional on whether the link is visited, so they are allowed, but are slow to compute, thus allowing the attacker to measure the time taken to repaint. You can make things even slower by including multiple copies of the same link, thus making the attack work better even with fast browsers.
The hits just keep coming. In 2019, Smith et al. published three new side channel attacks on browser history via link styling:
- Via the CSS Paint API.
- Via CSS transforms
- Via SVG
For example, the CSS Paint API allows you to register a JavaScript "paintlet" which can draw the background image for a given element, like a link. If you change the foreground element in certain ways—including changing the color—then this requires the paintlet to be re-run. The paintlet runs in a little sandbox that can't talk to the outside world, so you shouldn't be able to directly tell if it ran, but it turns out that you can measure how long it takes to run, using code like the following (adapted from Smith et al.)
const target = document.getElementById("target");
var start = performance.now(); // Get the current time
target.href = "https://example.com/";
var delta = performance.now() - start; // Get the time after the change
if (delta > threshold) {
alert("Victim visited https://example.com/");
}What makes this work is that when you change the DOM using JavaScript,
those changes happen synchronously: the line of code changing the
href field blocks until the DOM has changed, and the next
line only executes after the change has happened. In this case,
if the link has been visited, then the repaint has to happen which
takes more time, and so you can measure it using this code.
Because browsers are quite fast, it would ordinarily be fairly difficult to measure the time difference, but Smith et al. observe that it's possible to deliberately make the paintlet slow by adding a loop in the paintlet code that takes extra time, which makes the difference easier to measure. This is a fairly simple technique for amplifying the size of a timing signal, and in some cases you need something fancier. For instance, later in this paper, Smith et al. describe a technique (due initially to Stone) in which they rapidly change a link back and forth (as above), thus forcing the browser to do a lot of computation, and measure the frame rate of the browser's renderer. Ordinarily the browser would render about 60 frames per second, but if you give it too much work to do, it will fall behind and this is detectable from JS.
Of course browsers fixed these issues (and the CSS paint issue only happened in Chrome because other browsers hadn't implemented CSS Paint, and Chrome eventually disabled CSS Paint for links). However, we still see new attacks on link history, such as CVE-2022-29916, fixed in the recently released Firefox 100, just as I was working on this post.
Pixel Stealing #
Another example of the risks of allowing sites to compute on data from
other origins is what's known as "pixel stealing" attacks. Recall that
it's possible for site A to embed content from site B (e.g., in an IFRAME
or an <img> tag), but it's not allowed to inspect the content.
However, site A is allowed to apply filters to that content
to change its appearance; they just can't see the output of the
filters. If this sounds like bad news, you're developing the right
intuition.
A good example of what can go wrong here is provided by Paul Stone in the same white paper where he disclosed timing-based measurements.[4] The basic idea is that you design an SVG Filter which runs at different speeds on black and white pixels (based on the the feMorphology primitive). You load the target content in an IFRAME[5] and then apply the filter to one pixel at a time, measuring the time it takes to run (as before, we can use a bunch of techniques like running the filter a lot of times and magnifying the image so that each pixel is actually a lot of pixels in order to make the time difference bigger). This lets you extract the contents of the image one pixel at a time. Obviously, this isn't super efficient, but as Stone observes, if you want to read text out of a page, then you don't need that many bits because you only need to read some of the pixels to distinguish characters.
After these reports, browsers responded to these bug reports by rewriting the primitives in question so that they were closer to constant time—or by moving them to the graphics processor, where it was hoped they would be more constant time (though see here)—but it shouldn't surprise you that these are not the only cases where attackers can compute on cross-origin content with data-dependent results. A great example of this is a 2015 paper by Andrysco, Kohlbrenner, Mowery, Jhala, Lerner, and Shacham describing how to resurrect the SVG filter technique using a new timing channel based on floating point numbers.[6] If nothing else, this serves as evidence of how difficult it is to remove this kind of timing channel.
Input #
The final class of attack I want to discuss are on user input. The basic observation here is that when people are typing into the browser or moving the mouse, this takes time to process, which temporarily stalls the processor. If you set up a loop in which you ask the browser to increment a counter very frequently, and measure the actual rate at which the timer increments, you find that it increments slightly more slowly during periods where the user has typed a keystroke, as shown in the following image from a 2017 paper by Lipp et al.
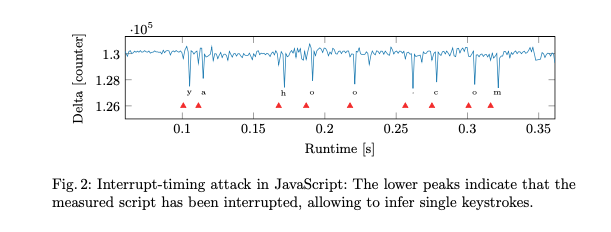
Just knowing when someone is typing doesn't seem that useful, but it turns out that by measuring the time between keystrokes, it is possible to learn a fair amount of information about what people are typing. The basic intuition is that people don't type at a constant rate and that different key combinations take longer time (consider the case where there are two keys typed with the same finger). This kind of problem has received a fair amount of study: in their original paper, Lipp et al. show how to determine with some confidence which URL people are typing; in 2001, Song et al. showed that it was possible to narrow down the range of user passwords in SSH from network traces; and there have been several papers about using accelerometers to measure typing on mobile phones or on adjacent keyboards using a mobile phone.
Because there is a a lot of redundancy in the characters people type (for instance, in English, the "q" is generally followed by "u" and not by "x"), some character combinations are more likely than others. This makes it possible to train a machine learning model that estimates which characters are being typed based on the available timing. The results aren't amazing, with accuracy rates in the 70-80% range, but they're a lot better than chance, and as Bruce Schneier observes, attacks only get better.
One very interesting thing about this class of attacks is that they aren't the result of deliberate browser decisions to mix data across origins. Rather, they're the natural result of some quite reasonable implementation decisions about how to share computing resources between sites. This is bad news because fixing them requires a lot of rethinking of the design of the browser.
The Bigger Picture #
Side channel attacks in browsers are a big topic, but a few common themes recur throughout the discussion.
State needs to be partitioned #
The main source of the various history sniffing attacks is that there is some piece of state (e.g., cached data, history) that is shared between site A and site B. As soon as you are in this state, you're going to have side channels and individually removing them is likely to be very expensive. It's now been recognized that the basic fix is to partition state by the top-level site. Unfortunately, there are a number of cases where this breaks functionality that people are used to, which is part of why it's taken so long to do. Moreover, as is the case with keystroke timing, there turn out to be resources which are unintentionally shared and hard to partition.
Safe computation on secret data is hard #
As I mentioned early on in this series, one of the key properties of the Web is the ability to make mash-ups of content from your site and from other sites, while still having them isolated by the same origin policy. However, the modern Web includes a lot of features that allow you not only to incorporate content from other origins but to compute on it. This is a very powerful mechanism but is also incredibly hard to do safely because that computation has to be done in a way that it is identical no matter what the data being computed on is. The lesson of the subnormal floating point case is that this is extremely tricky to do and depends on having very detailed knowledge of the processor and the operating system, all of which might change in some future version.
High resolution timing is dangerous #
A major building block of all of these attacks is the ability to precisely measure the duration of events. The more precisely you can measure events the smaller signals you can detect and thus the more careful the implementation has to be to suppress every difference between different code paths. You can often improve attacks by amplifying one of the code paths so that the timing difference is bigger and so less precise timing works, but the consequence is that attacks get slower and so it takes the attacker longer to extract a given amount of information.
There have been a number of attempts to provide systematic solutions to the timing side channel problem, such as Fuzzyfox by Kohlbrenner and Shacham. Techniques like this have the potential to really improve resistance to side channel attacks, but at a real performance cost and as far as I know no browser has yet been willing to deploy them in production.
Next Up: systematic solutions and microarchitectural attacks #
The history of side channel attacks in browsers—like many other security stories—is one of repeated cycles of attacks followed by ad hoc fixes for those specific attacks, followed by new techniques that resurrect those attacks, which themselves need to be fixed. The fundamental problem is that the behavior of the browser is simply too complicated a system to analyze with any confidence. The best known techniques for preventing this kind of attack depend on simplifying the problem so that security depends on a relatively small number of assumptions that are easier to verify and enforce. This is where techniques like partitioning come in.
This point was driven home in 2018 when it was discovered that a number of assumptions about the behavior of common processors were wrong, leading to a series of side channel attacks based on exploiting common processor optimizations. Defending against these attacks has forced browsers to make fundamental architectural changes. Those attacks and the changes they required will be the topic of the next post in this series.
Ordinarily, this feature, called "null termination", is considered a misfeature in C but in this case it's a bit convenient. ↩︎
A variant of this particular password checking bug was responsible for one of the very earliest side channel attacks, on the TENEX system. The attack, described in detail by Sjoerd Langkemper, took advantage of the fact that TENEX had virtual memory, in which the operating system could page out some data from memory to the disk and then bring it back in when needed. The attacker can exploit this bug by arranging the password so it crosses a page boundary with the second page having been paged out. The attacker can then learn the first mismatching character by observing whether the password check function tried to touch a page which had been paged out and needed to be paged back in (a "page fault"). ↩︎
Note that this measurement itself loads the data into cache, so repeated measurements will be fast, but the attacker can set a cookie to detect this case or try loading multiple resources. ↩︎
Similar attacks appear to have been discovered contemporaneously by Kotcher, Pei, Jumde, and Jackson, but their paper is behind a paywall, so this discussion focuses on Stone's work. ↩︎
You can also use this for link-based history sniffing, btw. ↩︎
It turns out that some processors have multiple representations for floating point numbers and that computations with one such representation ("subnormal" or "denormal") are slower than those with the regular representation. The attack involves applying a filter that translates black pixels into zero (which is normal) and non-black pixels into a subnormal value. If you then compute with the results, the non-black pixels are slower, which gives you the signal you need. ↩︎