Understanding The Web Security Model, Part VI: Browser Architecture
Posted by ekr on 27 Jun 2022
This is part VI of my series on the Web security model (parts I, II, outtake, III, IV, V). I'd been planning to talk about microarchitectural attacks next, but it's pretty hard to understand without some background on overall browser architecture, so I'll be covering that first.
Background: Operating System Processes #
We actually have to start even earlier, with the structure of programs in a computer. In early computers, you would just have one program running at a time and that program had sole control of the processor.
Modern computers can of course run multiple programs at once, but they do that by having them share the processor. The operating system is responsible for managing this. Each program runs in what's called a process. The operating system lets process run for a little while (what's called a time slice), then stops it and hands control to the next process, which gets to run for its own time slice before control is handed to the next process, etc. This is called multitasking and allows multiple programs to share the same computer.[1] In modern computers, time slices are very short and the processor switches between programs very quickly so it gives the illusion that everything is running in parallel.[2]
In a modern OS, programs don't need to do anything special to make this happen; they just act as if they have full control of the processor and the operation system takes care of switching between them. In particular, each process has its own view of the computer's memory and so process A can't just address process B's memory, either by accident or intentionally. This isn't to say that they can't interact at all, but the operating system is responsible for mediating that interaction, allowing some things and forbidding others.
It's also possible for a single program to run multiple processes. One reason to do this is to let two operations run in parallel. Consider a networking process like a Web server. The basic code for something like this might look this might look something like:
loop {
request = read_request();
response = create_response(request);
write_response(response);
}
So what happens if a Web server wants to serve two clients at once? This is fine if the requests come in quickly, but what happens if the request from client A trickles in over a few seconds and then client B sends its request? The server can't process it until its finishing handling client A. If instead the server runs in two processes, however, then process 1 can handle client A and process 2 is available to handle client B when its request comes in. The operating system takes care of making sure that each process gets time to run, so this works fine without any extra effort by the server, as shown below:
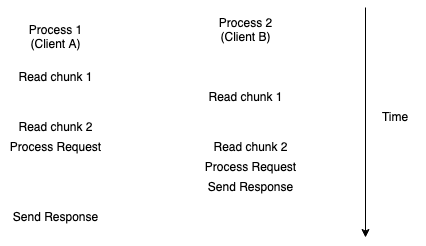
You can also get multitasking inside a single process, using a mechanism called threads. Threads inside a process get scheduled independently, so that you can write the same kind of linear code as above and have it run in parallel, but they aren't isolated like processes are. This means that, for instance, thread 1 can accidentally corrupt thread 2's memory, or, if thread 1 crashes it can crash the whole program. On the other hand, switching between threads tends to be cheaper than switching between processes, so each mechanism has its place. Finally, a process with multiple threads tends to consume less memory than the same number of processes because the threads can share a lot of runtime state.
Single-Process Browsers #
Originally, browsers just had everything in a single process. This included not only the user interface and networking code but also all the code that rendered the Web page and the JavaScript that ran in the page. Moreover, they often ran almost everything in a single thread,[3] with the program being responsible for multiplexing keyboard input, network activity, etc. (see the side bar for more on this). Because each thread can only do one thing at once, this tended to produce a lot of situations where the browser would become temporarily unresponsive (the technical term here is jank) because it was doing something else rather than responding to the user or playing your video, so gradually more and more of the the browser migrated into other threads in order to reduce the impact on the user experience.
Event-Based Programming #
If you don't have threads, it's still possible to multiplex between different tasks. The basic technique is what's called an event loop. The basic idea behind an event-loop is that you have a piece of code that allows you to register event handlers for when certain things happen (e.g., a packet comes in or someone types a key). An event handler is just a function that runs when that event happens.
So, for instance, you might have something like:
function onKeyPressed() {
...
}
function onMouseMovement() {
...
}
register(KEY_PRESSED, onKeyPressed);
register(MOUSE_MOVED, onMouseMovement);
run_event_loop();
The run_event_loop() function just runs forever, waiting
for something interesting to happen—where "interesting"
is defined as "some event that has a handler registered"
and when it does it runs the associated handler function. When
the handler function completes, the event loop resumes
waiting until something else happens.
This works fine and is still common—for instance, the popular Node.js JavaScript runtime works this way—but it's a lot of work to program in. First, because nothing happens while the event handler is running, you constantly have to worry about whether you accidentally are taking up too much time with some operation. For instance, if someone presses a key and then clicks a button and your key press handler takes 500ms, then the button click doesn't get processed for 500ms, which is obviously very unpleasant for users.
This means that you have to break up anything long-running into multiple pieces, but every time you switch from one logical operation to another, you have to arrange to save your state so it's there when you come back to it, which is annoying. By contrast, if you are writing multi-process or multi-threaded code, then the scheduler takes care of pausing one logical operation and letting another run, so you don't need to worry about saving your state and coming back to it. In fact, it's so annoying to program this way that some event-driven systems (in particular JavaScript in both Web browsers and Node.js) have developed mechanisms like async/await that let the programmer write code that appears to be linear but is secretly event-driven.
As an example, until 2016 Firefox had an architecture with a single process containing a number of threads for tasks that could be run asynchronously like networking and media. For instance, the user interface runs on one thread, but what happens if the user asks to do something that takes a long time, like load a Web page? The way this happens is that the UI thread dispatches a request to a different thread which is responsible for networking. The networking thread can then connect to the Web site and download the content in the background. This allows the UI to continue to be responsive to the user while the Web page downloads.
This architecture is straightforward and has a number of advantages. In particular, it is easier to share state between the different threads. For example, consider the case I just gave above in which the UI thread needs to send a request to the network thread, it would assemble a request structure and pass it to the network thread, which could look something like this (this is not real Firefox code):
struct {
enum method;
std::string url;
std::string referer;
} NetworkRequest;
//
NetworkRequest *msg = new NetworkRequest();
msg->method = HTTP_GET;
msg->url = std::string("https://example.com/");
msg->referer = std::string("https:/referer.example/");
networkThread->Dispatch(msg);When this code calls networkRequest->Dispatch() it passes a pointer
to (i.e., the memory address of) the NetworkRequest object to the
networking thread, which then can access the contents of that object.
In C++, the NetworkRequest object does not consist of a contiguous
block of memory. Instead, the url and referer members are likely
to be separate blocks of memory, with the NetworkRequest object just
holding pointers to those objects. This all works because threads
share memory, which means that a memory address that is valid on the
main thread is also valid on the networking thread. Therefore, you
can just pass a pointer to the structure itself and everything works
fine.
By contrast, if there were a separate networking process, then this wouldn't work because the pointer to the structure wouldn't point to a valid memory region in the networking process. Instead you have to serialize the structure by turning it into a single message, e.g., by concatenating the method, the URL, and the referer. You then send that message to the network process which deserializes it back into its original components. Any responses from that process would have to come back the same way.
This is a huge advantage when you have a single threaded program that you want to make multithreaded, because memory sharing makes it comparatively easy to move an operation to another thread. I say "comparatively" because it's still not easy. If you have multiple threads trying to touch the same data at the same time you can get corruption and other horrible problems, so you have to go to a lot of work[4] to make sure that doesn't happen.[5] This kind of problem, called a data race, can be incredibly hard to debug, especially as it often won't happen in your tests but only in some scenario where things are operating in a way you didn't expect; but even uncommon things happen a lot when you have a piece of software used by millions of people.
With processes, by contrast, you mostly get this kind of protection for free, because memory isn't usually shared, but you have to pay the cost upfront of restructuring the code so it doesn't depend on shared memory. This tends to make threads look more attractive than they actually would be if you counted the total cost including diagnosing issues once the software is deployed. In any case, so it's quite common to see big programs with a lot of threads.
Stability and Security Issues #
Because all the threads in the same process share the same execution environment, defects that occur in one thread have a tendency to impact the whole program. For example, consider what happens if part of your program tries to access an invalid region of memory. On UNIX systems this generally results on what's called a segmentation fault, which causes the process to terminate. If your entire program is in a single process, then the user just sees your entire program crash. Web browsers are very complicated systems that therefore have a lot of bugs, and it used to be very common for people to just have the whole browser crash.[6]
Another example is that it's possible for one Web site to starve another Web site. Because the JavaScript engine runs on a single thread, if site A writes some JavaScript that runs for a long time, then site B's JavaScript doesn't get to run. On Firefox, this issue was even worse because the browser UI also ran on the same thread, so it was possible for a Web site to prevent the browser UI from working well. Firefox had some code to detect these cases and alert the user, but it could still cause detectable UI jank.
A single process can also lead to security issues: if an attacker manages to compromise the code running in part of the program, then they can use it to access any memory in the process. For instance, in a Web browser they might steal your cookies and use them to impersonate you to Web sites. In a Web server, they might steal the cryptographic keys that authenticate the server and use that to impersonate the server to other clients. In addition, because any code they manage to execute has the privileges of the whole program, they can do anything the program can do, such as read or write files on your disk, access your camera or microphone, etc.
Process Separation #
As discussed in a previous post, there is a standard approach to dealing with this issue:
- Take the most dangerous/vulnerable code and run it in its own process (process separation).
- Lock down that process so that it has the minimum /privileges needed to do its job (sandboxing). The details of this vary from operating system to operating system but the general idea is that a process can give up its privileges to do things like access the filesystem or the network.
- If the process needs extra privileges have it talk to another process which has more privileges but is (theoretically) less vulnerable.
This strategy was introduced in SSHD and then first shipped in a mainstream browser by Chrome/Chromium. The way that Chromium originally worked was that the HTML/JS renderer ran in a sandbox, but the UI and the network access ran in the "parent" process (what Chromium called the "browser kernel"). The following figure from Barth et al.'s original paper on Chromium shows how this works:
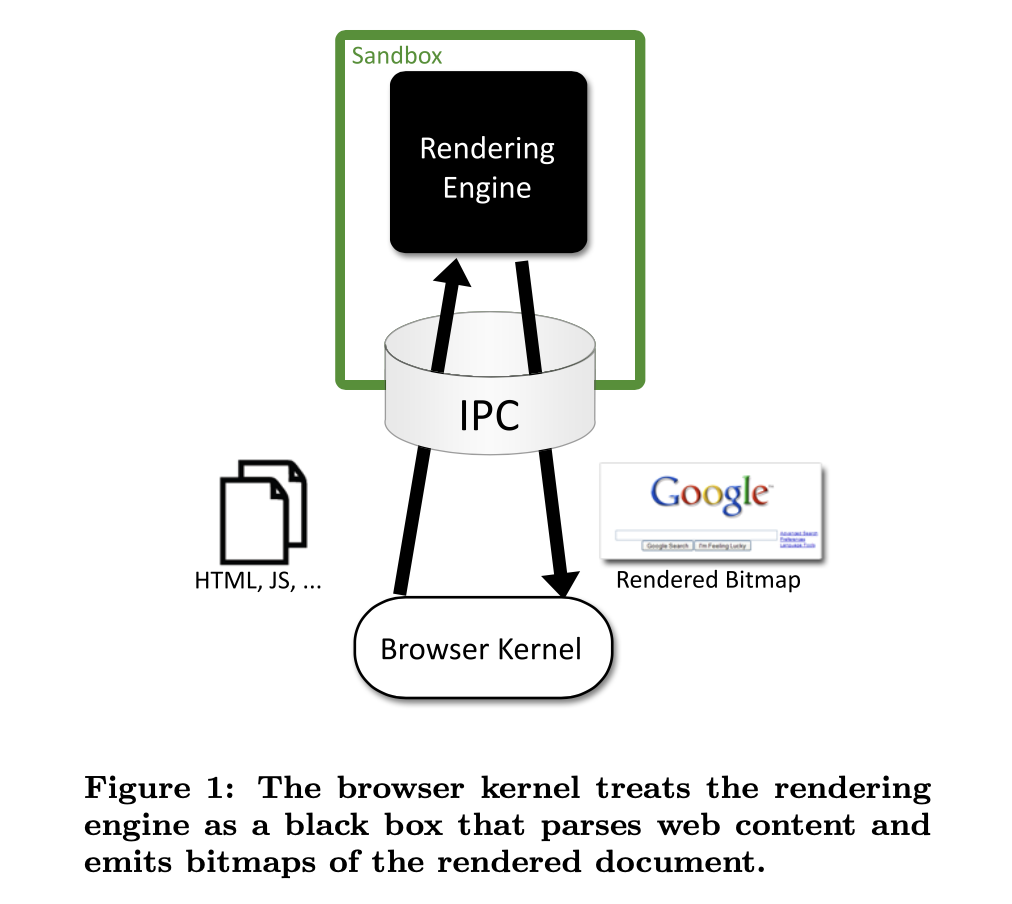
In this figure "IPC" refers to "interprocess communication" which just means a bidirectional channel that the two processes can use to talk to each other. As noted above, that requires serializing the messages for transmission over the wire and decoding them on receipt.
As you would expect, this architecture has a number of stability and security advantages.
Stability #
On the stability side, if the renderer process crashes, the parent process can detect this and restart it. This isn't an entirely glitch-free experience because the site the user is viewing still crashes, but because Chrome can run multiple processes, it doesn't necessarily impact every browser tab. Similarly, because each tab is running in its own process, if tab A has some kind of long-running script it doesn't necessarily impact tab B, and won't impact the main browser UI.
Security #
Because the renderer is sandboxed, compromise of the renderer is less serious. For instance, the renderer would not be able to read files off the filesystem directly but would have to ask the parent to do it. Of course, if the renderer can ask the parent to read any file, then this isn't much of an improvement, so instead the renderer asks the parent to bring up a file picker dialog and then only the selected file will be accessible. This is a specific case of a general pattern, which is that the parent only partly trusts the renderer and has to perform access control checks when the renderer asks for something.
In order to gain full control of the computer, an attacker who compromises the renderer must first escape the sandbox. This tends to happen in one of two ways:
-
The attacker uses a vulnerability in the operating system to elevate its privileges beyond those it is supposed to have.
-
The attacker uses a vulnerability in the parent process to subvert that process or to cause it to do something it shouldn't.
Sandbox escapes do happen with some regularity but you've now raised the bar on the attacker by requiring them to have two vulnerabilities rather than one.
Of course this does not provide perfect security. First, much of the browser runs outside the sandbox, so compromise of these portions can lead directly to compromise of your machine. A good example of this is networking code, which is exposed directly to the attacker and is easy to get wrong.[7]
Second, sites are not protected from each other because the same process may serve multiple sites, either consecutively—for instance if the user navigates between sites—or simultaneously—for instance, if the browser uses the same process for multiple tabs or because a site loads a resource from another site. If a site is able to successfully attack the renderer, it can then access state associated with another site, including cookie state and the like. Thus, the browser protects the user's computer, but not any Web-associated data. As more and more of the work people moved to the Web, this became a more serious threat; if an attacker can't take over your computer but they can read all your banking data and your mail, this represents a serious threat.
Site Isolation #
The natural way to address the problem of sites attacking each other via browser vulnerabilities is to isolate each site[8] in its own process. This is called site isolation, and unfortunately it turns out to be a lot harder than it sounds, for a number of reasons.
First, there are a number of Web APIs that allow for synchronous
access between windows or IFRAMEs. For instance, if site A does
window.open()
then it gets a handle it can use to access the new window, for
instance to navigate it to a different site or—if it's the same
site—to access its data. Similarly, the opened window gets a
window.opener
property that it can use to access the window that opened it. The
APIs that use these values are expected to behave synchronously,
so for instance, if you want to look at some property of
window.opener this has to happen immediately.
If each site is in its own process, then that becomes
tricky, so you have to implement
some way of allowing that. There are a fair number of similar
scenarios and converting a browser to site isolation requires
finding and fixing each of them.
Second, unlike the simpler site isolation design, you need to ensure that each process is constrained to only do the things that are allowed for that site. For instance, the process for site A cannot access the cookies for site B. This means that every single request to access data that isn't local to the processes's memory not only needs to go through the parent—as in process separation—but the parent needs to check that the process that is making it is entitled to do so, first by keeping track of which process goes with which site and second by doing the right permissions checks. Previously, these permissions checks could be in the renderer process, which was a lot easier, especially if, as in Firefox, they had started there in the first place.
Finally, because having a lot of processes consumes a lot more memory, a lot of work was required to try to shrink the overall memory consumption of the system. This also means that is harder to deploy full site isolation on mobile devices which tend to have less memory.
At present, Chrome—and other Chromium derived browsers such as Edge and Brave—and Firefox have full site isolation, but to the best of my knowledge, Safari does not yet have it.
Inside Baseball: Multiprocess Firefox #
Unlike Chrome, which was designed from the beginning as a multiprocess browser, Firefox originally had a more traditional "monolithic" architecture. This made converting to a multiprocess architecture much more painful because it meant unwinding all the assumptions about how things would be mutually accessible. In particular, Firefox had a very extensive "add-on" ecosystem that let add-ons make all sorts of changes to how Firefox operated. In many cases, these add-ons depended on having access to many different parts of the browser and so weren't easily compatible with a multi-process system.
At the same time as Chrome was building a multiprocess architecture, Mozilla was developing a new programming language, Rust, which was specifically designed for the kinds of systems programming that is required to make a browser engine. Rust had two key features:
-
Memory safety so that it was much harder to write memory unsafe code, thus eliminating a broad class of serious vulnerabilities.
-
Thread safety so that it was much easier to write multithreaded code without creating data races that lead to vulnerabilities and unpredictable behavior.
Instead of converting Firefox to a multiprocess architecture, Mozilla focused on the idea of rewriting much of the browser engine in Rust (a project called Servo). If successful, this would have addressed many of the same issues as a multiprocess system: you could easily write multithreaded code and because it was memory safe you wouldn't need to worry as much about compromises of one thread leading to compromises of the process as a whole. If this had worked it would have been very convenient because it would have allowed for a gradual transition without breaking add-ons (which was considered a big deal). It would also have used less memory and quite likely been faster.
The Big Rewrite ultimately didn't work out, for two major reasons. First, it just wasn't practical to rewrite enough of the browser in Rust to make a real difference. Firefox is over 20 million lines of code, a huge fraction of it in C++, reflecting over 20 years of software engineering by a team of hundreds. Even if writing in Rust was dramatically faster it would still be very expensive to replace all that code. Firefox eventually did incorporate several big chunks of new tech from Servo, such as the Stylo Style engine and the WebRender rendering system, and a lot of new Firefox code is written in Rust, but it just wasn't practical to replace everything.
The second reason comes down to JavaScript. A huge fraction of the memory vulnerabilities in browser engines actually isn't due to the memory unsafety of the browser but rather to logic errors in the JavaScript VM that lead to the code it generates being unsafe. Writing in Rust doesn't inherently fix these problems—though of course a rewrite might lead to simpler or easier to verify code.
In any case, Mozilla eventually decided to introduce process separation, in a project called Electrolysis. At first Firefox only had one content process and even later after it added multiple processes, it was far more conservative than Chrome about the number of processes that it started, in an attempt to conserve memory. (see here for some spin on why having 4 processes was perfect rather than just easy). And those add-ons? Eventually Firefox deprecated them, in favor of WebExtensions.
In retrospect, the decision to do Electrolysis was fortunate because, as we'll discuss next time, multithreaded architectures simply can't properly defend against Spectre-type attacks, so Firefox would have had to move to multiprocess in any case and having already done Electrolysis at least got it part of the way there.
Next Up: Microarchitectural Attacks #
Because site isolation was so much work, converting browsers from process separation took a really long time. Chrome was the first browser to start working on site isolation back in 2015 but they were still far from finished in 2018 when an entirely new class of attacks that exploited microarchitectural features of modern processors was discovered. The only known viable long-term defense against these attacks is to move to full site isolation, leading Chrome to increase their level of urgency and Firefox to launch Project Fission to add site isolation to Firefox. I'll be covering these attacks in the next post.
Technically, what I'm describing here is "preemptive multitasking", because the operating system switches programs out without their cooperation. The alternative is "cooperative multitasking", in which programs give up control of the processor. ↩︎
Newer computers also have multiple processors and/or multiple cores and can really do some stuff simultaneously, but that's not that relevant here. ↩︎
As far as I can tell Mosaic actually was completely single-threaded. ↩︎
Much of the machinery of languages like Rust and Erlang is designed to make it possible to safely write multithreaded code without a lot of mental overhead. ↩︎
The Mozilla San Francisco offices used to have a sign set about 8 feet off the floor that read "Must be this tall to write multithreaded code". ↩︎
Technically it's possible to recover from memory violations in the sense that you can just tell the program to ignore the error and keep executing—the Emacs editor used to allow this—but once you've had some kind of memory issue like this, your program is in an uncertain state so all bets are off. ↩︎
Firefox and Chrome are both moving networking into a separate process, and I believe Chrome may have recently completed this on some systems. ↩︎
Perhaps surprisingly, the unit of isolation is not the origin but rather the site, which is to say the registrable domain, aka "eTLD+1". So, for instance,
mail.example.comandweb.example.com. The reason for this is that sites can set thedocument.domainproperty to set their domain to the parent domain, e.g., frommail.example.comtoexample.com. This puts them in the same origin. See the Chromium design document on site isolation for more detail. ↩︎